面向手寫體識別的DCNN抗噪性能研究
2021-05-25 05:26:28蔡際杰陳德旺
軟件導刊 2021年5期
關鍵詞:模型
蔡際杰,陳德旺,張 璜
(1.福州大學數學與計算機科學學院;2.福州大學智慧地鐵福建省高校重點實驗室,福建福州 350108;3.福州理工學院計算與信息科學學院,福建福州 350506)
0 引言
大數據時代數據量越來越大,利用大數據解決實際問題的機會越來越多,深度學習作為處理數據的人工智能技術顯得越來越重要。深度神經網絡(Deep Neural Network,DNN)作為深度學習的重要分支受到青睞。DNN 在并行性計算能力、自學習能力和非線性映射能力上表現突出[1],廣泛應用于計算機視覺、自然語言處理以及語音識別等領域。
自1943 年美國心理學家McCulloch 和數學家Pitts 提出神經元突觸模型中最基本的模型——MP 模型以來[2],神經網絡的發展歷程跌宕起伏,發展至今經歷了三起三落:1986 年,Rumelhart 等[3]共同提出了反向傳播算法,利用梯度下降法不斷更新神經節點參數,大大降低了神經網絡誤差;Hinton 等[4]于2006 年提出了深層次結構的神經網絡,并首次提出深度學習概念,描述了深度學習的整個體系結構。其后人們開始考慮搭建多層神經網絡來解決復雜的大數據問題,自此出現了各種類型的DNN,如深度卷積神經網絡(Deep Convolution Neural Network,DCNN)、深度生成式對抗神經網絡(Deep Generated Adversarial Neural Net?work,DGANN)等。神經網絡的迅速發展得益于計算機性能的提高和Hinton、LeCun、Bengio 等研究者的成果貢獻,Lecun 等[5]三人于2015 年共同在《Nature》上發表《Deep Learing》引起世界關注。如今深度學習研究成果已成功應用在圖像識別、圖像分類、語音識別等領域[6]。
DCNN 具有強大的自學習能力和非線性映射能力,但是其存在一些致命缺點:①過于依賴數據集。訓練集一旦過大會導致生成的模型過擬合,不夠泛化,太過死板;訓練集一旦過小,則會導致生成的模型欠擬合,精度較差;②可解釋性較差。當DCNN 結構變得越來越復雜時,參數會變得非常多,一旦出錯則難以修正,而且難以解釋其結果產生的依據,因此難以運用在諸如自動駕駛、醫療診斷和金融決策等高風險領域[7];③魯棒性較差。一旦給數據集添加一些隨機噪聲將導致模型精度大大降低。
在DCNN 以上缺點中,DCNN 的抗噪性能近年備受關注。從圖像識別到語音識別領域,DCNN 的影子隨處可見,如果DCNN 訓練測試的數據集發生人們無法察覺的微小變化,原本效果特別好的神經網絡就會受到嚴重影響,將其應用在安全領域造成的后果將不堪設想。Eykholt[8]于2018 年發現倘若在一張停止的交通標志圖片上增加4 個小方點,無人駕駛汽車的人工智能系統就會將該標志誤識別為限速45 的標志;Finlayson[9]將像素惡意添加到醫療掃描的圖像可能會使DNN 誤檢癌癥。由此可見DCNN 魯棒性較差,很容易受到噪聲干擾,因此其難以運用在安全領域。
為進一步證明DCNN 抗噪性能較差的缺點,本文通過給手寫體數據集DigitDataset 的測試集添加4 種不同幅度噪聲,深入研究DCNN 在手寫體識別問題上的抗噪性能。研究結果對DCNN 的改進和高魯棒性的深度學習系統(如深度模糊系統等)研究具有一定的參考意義。
1 卷積神經網絡
1.1 研究背景
近年來,DNN 憑借其強大的學習能力和并行性計算能力,使其在非線性問題建模上比一般淺層模型表現更好,具有一定優勢。隨著深度學習研究的深入,出現了一種具有強大特征提取能力的神經網絡——卷積神經網絡(Con?volution Neural Network,CNN)。CNN 能夠實現端到端學習,通過大量的訓練后,CNN 模型可以在不進行額外處理的情況下學習到圖像中的特征,完成對圖像特征的提取和分類工作[10]。CNN 中的局部連接、權值共享以及池化操作特性能夠快速有效地降低網絡復雜性[11],因此比其他神經網絡方法更適合應用在圖像特征學習問題上。CNN 的種種優勢使其應用領域不斷擴大,早期利用CNN 識別手寫體字符,后來將其應用在語音識別、目標檢測以及圖像語義分割等領域。
早期CNN 停留在理論研究階段,1998 年Lecun 等[12]為解決手寫體識別問題提出LeNet-5;2012 年Krizhevsky等[13]根據CNN 存在的過擬合缺陷引入dropout 機制,并增加非線性激活函數來增強模型的非線性表達能力,他們提出的Alex-Net 在ImageNet 競賽中獲得了冠軍;而后Zeiler等[14]根據AlexNet 存在的不足進行改進,從可視化角度解釋了CNN 具有較好性能的原因,并于2013 年提出具有特征可視化的ZFNet。目前CNN 種類繁多,如VGGNet[15]、GoogleNet[16]、ResNet[17]以及近幾年迅速發展的輕量級卷積神經網絡[18],每次更新的模型都有很大改進。隨著CNN 模型的不斷創新,CNN 研究成果層出不窮,成為目前最受關注的研究熱點之一。
1.2 基本原理
普通的前饋神經網絡由輸入層、隱含層、輸出層組成,而CNN 是一種特殊的前饋神經網絡,它建立在前饋神經網絡基礎上,然后將隱含層延伸為卷積層、池化層和全連接層。CNN 基本結構由輸入層、卷積層、池化層、全連接層以及輸出層組成,如圖1 所示[10]。一般CNN 會交替設置多個卷積層和池化層,即一個卷積層連接一個池化層,池化層后再連接一個卷積層[11],從而形成DCNN,如LeNet-5 結構就是交替設置卷積層和池化層的標準案例。
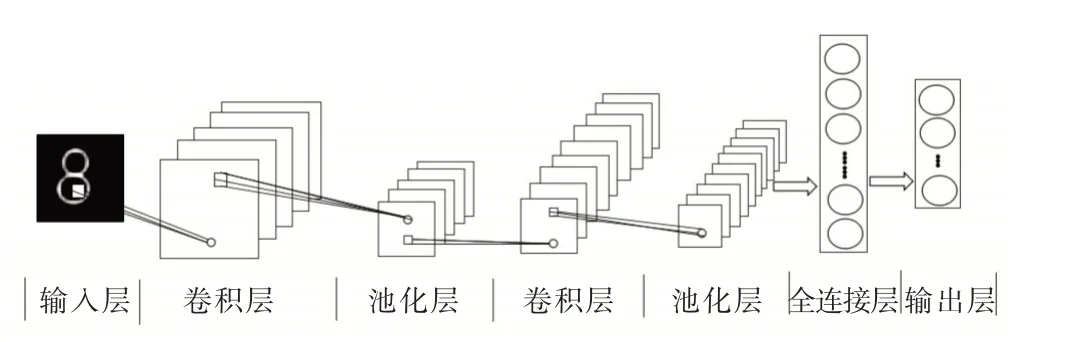
Fig.1 Typical structure of convolutional neural network圖1 卷積神經網絡典型結構
簡單的DCNN 工作流程如下:將圖片轉為輸入矩陣,經過輸入層后進入卷積層,每一個卷積核滑遍整個輸入矩陣,得到特征矩陣。卷積層提取輸入矩陣的局部特征,然后再進入池化層進行降維和防止過擬合處理;接著進入全連接層進行特征組合完成目標建模。如圖2 所示的前饋神經網絡全連接層工作過程與BP 網絡類似,利用梯度下降法進行誤差反向傳播,最后進入輸出層輸出結果。
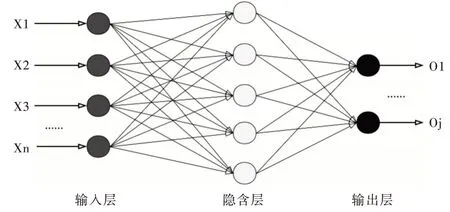
Fig.2 Full connection layer of feedforward neural network圖2 前饋神經網絡全連接層
2 噪聲類型及實現
噪聲可以理解為妨礙人類理解信息的干擾因素。微小的噪聲可能不會妨礙人類判斷結果,但對于機器而言其影響可能較大,微小的干擾會嚴重影響機器的人工智能算法,嚴重的會導致其癱瘓,最后結果本末倒置。噪聲是一種隨機過程,所以它的分量灰度值是一個隨機變量,其統計特性一般由概率密度函數表示[19]。一般使用均值、方差或某些函數來描述噪聲特征。噪聲在數字圖像中十分常見,在進行圖像處理實驗時,實驗圖片在傳輸、存儲過程中往往不可避免地受到各種噪聲干擾。而DCNN 是一種依賴數據集的模型,倘若其測試集或整個數據集受到噪聲干擾,其模型精度有可能大幅下降。實驗中數據集的噪聲通常都是理想化的,一般是疊加性的椒鹽噪聲、伽馬噪聲等,但在實際應用中圖像受到的噪聲情況更為復雜,對于DCNN 的影響更加嚴重,因此去噪方法研究尤為重要。
許多學者在圖像去噪方面做了大量工作并取得突破。王小鵬等[20]在保證原始圖像完整度基礎上提出一種基于形態學多尺度的圖像噪聲去除方法;Song 等[21]為解決超聲圖像斑點噪聲問題提出一種去除該類型噪聲和突出缺陷特征的形態學方法;Umoh 等[22]對一種基于超混沌的數字圖像加密算法在噪聲攻擊下進行大量的魯棒性分析,以此分析噪聲對該加密算法的影響;Semenishchev 等[23]提出一種保留目標邊界的圖像濾波方法并將其成功應用在醫療圖像領域。由于噪聲對算法的影響較大,所以未來圖像去噪研究將是熱點。
本文實驗選取圖像處理中常見的4 種噪聲給數據集加噪,并通過調整噪聲公式中的2 個參數來加大噪聲對數據集的干擾,以此觀察DCNN 精度變化情況。
2.1 高斯白噪聲
高斯白噪聲一般指該噪聲的幅度分布服從高斯分布,功率譜密度服從均勻分布,通俗指在一般范圍內噪聲的統計特性符合高斯分布,且其熱噪聲部分在工作范圍內均勻分布[24]。高斯白噪聲在MATLAB 下的實現公式如下:
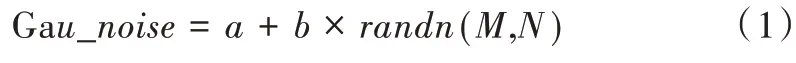
式(1)中,randn(M,N)為MATLAB 下自帶的函數,該函數可以自動產生出均值為0、方差為1、尺寸為M×N 像素的高斯噪聲矩陣,參數a 為均值,參數b 為方差。加噪前后對比如圖3 所示,其中a=0,b=0.05。

Fig.3 Comparison of Gaussian white noise before and after adding noise圖3 高斯白噪聲加噪前后對比
2.2 伽馬噪聲
伽馬噪聲指一種概率密度函數服從伽馬曲線分布的噪聲。伽馬噪聲可通過疊加x 個服從指數分布的噪聲得到[25]。伽馬噪聲在MATLAB 下實現公式如下:
Gama_noise=a+b×gamrnd(A,B,[M,N]) (2)
式(2)中,gamrnd(A,B,[M,N])為MATLAB 自帶的函數,該函數可自動產生參數為A、B,尺寸為M×N 像素服從伽馬分布的噪聲矩陣。為消除將伽馬噪聲疊加到圖像產生的變形影響,給公式添加參數a 和b。加噪前后對比如圖4 所示,其中a=0,b=0.05,A=1,B=1。

Fig.4 Comparison of Gamma noise before and after adding noise圖4 伽馬噪聲加噪前后對比
2.3 瑞利噪聲
瑞利噪聲是圖像處理中常見的噪聲,該噪聲的統計特性服從瑞利分布,即當由噪聲組成的隨機二維向量的兩個分量呈獨立、有著相同方差的正態分布時,這個向量的模呈瑞利分布[23]。瑞利噪聲在MATLAB 下實現公式如下:

式(3)中,raylrnd(B,[M,N])為MATLAB 的自帶函數,該函數可自動產生出服從瑞利分布,參數為B、尺寸為M×N像素的瑞利噪聲矩陣。為消除瑞利噪聲疊加到圖像產生的變形影響,給公式添加了參數a 和b。加噪前后對比如圖5 所示,其中a=0,b=0.05,B=1。

Fig.5 Comparison of Rayleigh noise before and after noise addition圖5 瑞利噪聲加噪前后對比
2.4 指數噪聲
指數噪聲,顧名思義就是統計特性服從指數分布的噪聲。指數分布是伽馬分布的一種特殊情況[26],因此指數噪聲與伽馬噪聲有部分相似之處。指數噪聲在MATLAB 下的實現公式如下:

式(4)中,exprnd(mu,[M,N])為MATLAB 下自帶的函數,該函數可自動產生期望值為mu、尺寸為M×N 像素的指數噪聲矩陣,服從指數分布。為消除將指數噪聲疊加到圖像中產生的變形影響,給公式添加參數a 和b。加噪前后對比如圖6 所示,其中a=0,b=0.05,mu=1。

Fig.6 Comparison of exponential noise before and after noise addition圖6 指數噪聲加噪前后對比
3 實驗內容
3.1 實驗準備工作
實驗數據來自MATLAB 自帶工具箱的DigitDataset 數據集,其中包含10 000 張數字手寫體圖片,每個類別分別1 000 張。數據集劃分比例為3∶1,劃分方式有順序劃分和隨機劃分兩種。DCNN 模型結構為輸入層→卷積層→批量歸一化層→Relu 層→最大池化層→卷積層→批量歸一化層→Relu 層→最大池化層→卷積層→批量歸一化層→Relu層→全連接層→Softmax 層→分類層,其中學習率為0.1,最大訓練輪次為5 輪,每輪訓練迭代58 次。
為深入研究DCNN 在手寫體識別問題上的抗噪性能,本文采用不同方式對DCNN 模型進行大量測試。本文嘗試兩種數據集劃分方式,但由于在順序劃分方式下無噪聲數據集測試準確率只有77%左右,不夠直觀,而在隨機劃分方式下無噪聲數據測試準確率達到99%,在測試模型抗噪性能變化時更加直觀,所以記錄隨機劃分方式下的測試結果。通過實驗分析可以發現,參數a、b 與噪聲強度有密切關系,因此實驗的主要思路是通過調節4 類噪聲的參數a 和b 來加大噪聲對數據集的影響,進而觀察模型精度變化。在對數據集加噪的同時考慮加噪后的圖片識別情況,從而發現參數變化至何值時DCNN 開始失靈。
3.2 實驗結果與分析
本實驗采用DCNN 模型對未加噪手寫體數據集進行識別,測試準確率達到99.56%,其對應的訓練過程如圖7所示。
通過調節高斯白噪聲、伽馬噪聲、瑞利噪聲、指數噪聲的參數a 和參數b 增強這4 類噪聲對測試集的干擾,進而觀察DCNN 精度變化。將參數a 的范圍設定為[0,1],將參數b 的范圍設定為[0,0.1],其他參數設置如下:伽馬噪聲參數A=1,B=1,瑞利噪聲參數B=1,指數噪聲參數mu=1。實驗過程中測試集準確率變化如表1-表4 所示。
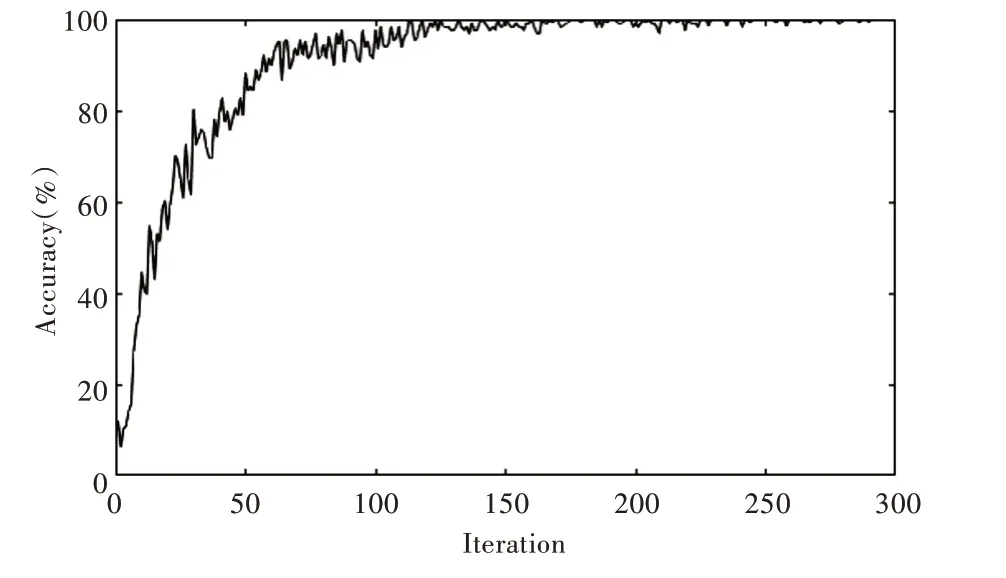
Fig.7 Change curve of accuracy of training set during DCNN training圖7 DCNN 訓練過程中訓練集準確率變化曲線
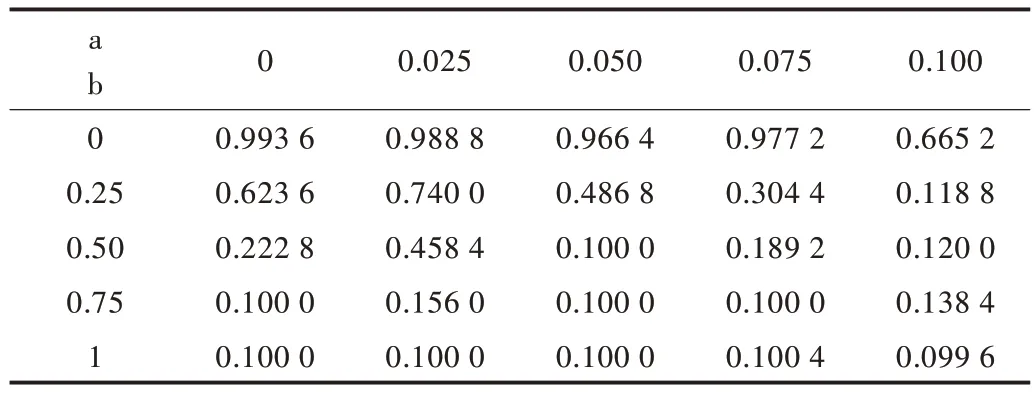
Table 1 Change of gaussian white noise parameters and accuracy of DCNN test set表1 高斯白噪聲參數與DCNN 測試集準確率變化數據
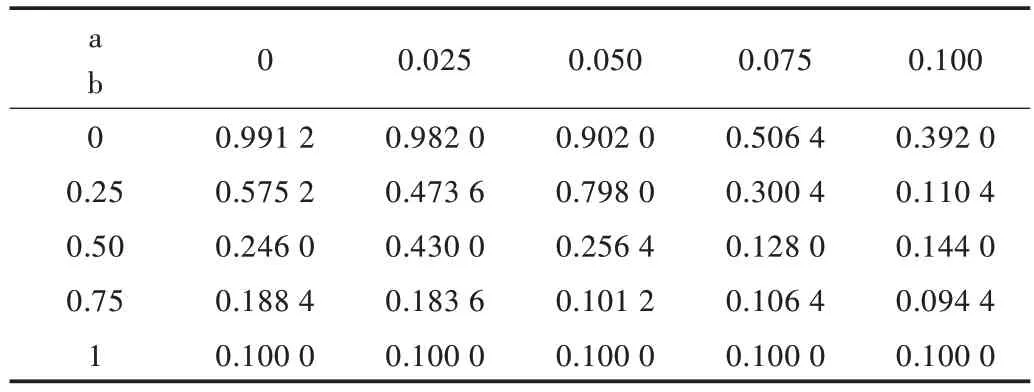
Table 2 Change of Gamma noise parameters and accuracy of DCNN test set表2 伽馬噪聲參數與DCNN 測試集準確率變化數據
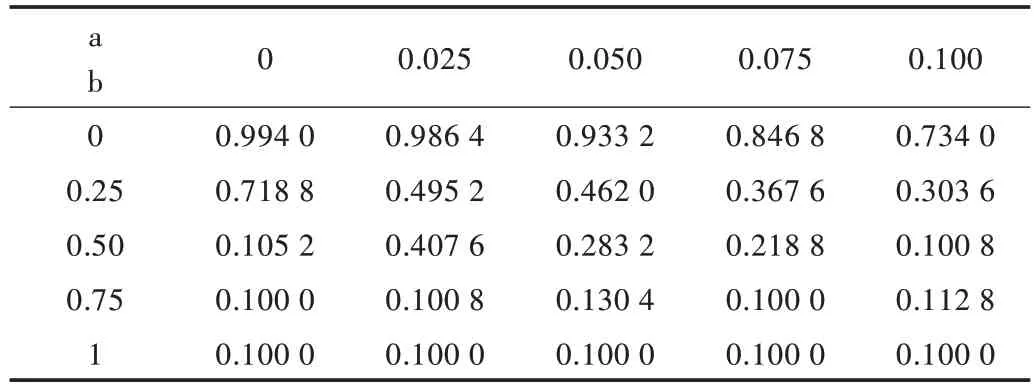
Table 3 Change of rayleigh noise parameters and accuracy of DCNN test set表3 瑞利噪聲參數與DCNN 測試集準確率變化數據
從表1-表4 可以清楚發現噪聲對DCNN 性能有很大影響。隨著4 類噪聲的參數a 和b 增大,DCNN 識別精度呈大幅度下降趨勢。因為隨著參數a 和b 的上升,噪聲幅度增大,測試集受干擾較強,導致模型識別效果下降,因此精度逐漸降低。另外,通過圖8-圖10 可以發現指數噪聲對模型精度影響最大,伽馬噪聲、瑞利噪聲次之,高斯白噪聲影響最小。由于噪聲疊加具有隨機性,因此部分結果有所波動。從表1-表4 和圖8-圖10 所示的實驗結果可知,當給測試集添加各類噪聲時,在人類依然可以識別測試集圖片的情況下,DCNN 識別準確率卻下降至50%以下,模型基本失靈,已無法正常識別手寫體。

Table 4 Change data of exponential noise parameters and accuracy of DCNN test set表4 指數噪聲參數與DCNN 測試集準確率變化數據
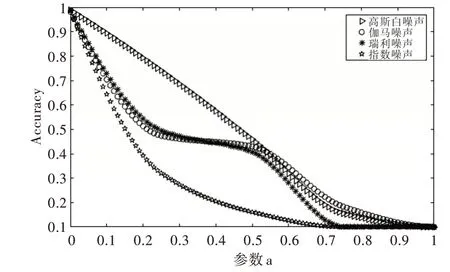
Fig.8 Curve of noise parameter a and accuracy of test set(b=0.025)圖8 噪聲參數a 與測試集準確率變化曲線(b=0.025)

Fig.9 Curve of noise parameter b and accuracy of test set(a=0)圖9 噪聲參數b 與測試集準確率變化曲線(a=0)
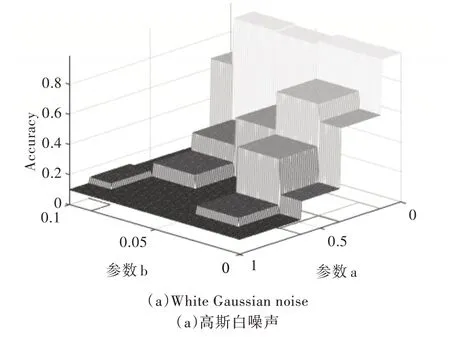

Fig.10 Curved surface of noise parameters and accuracy of test set圖10 噪聲參數與測試集準確率變化曲面
4 結語
根據大量的測試分析與比較研究發現,給數據集添加的噪聲幅度越大,DCNN 在手寫體識別上的準確率越低。不管是給整個數據集添加噪聲,還是只給測試集添加噪聲,DCNN 的識別精度都受到很大影響。因此,根據實驗結果,本文進一步證明了DCNN 抗噪性能較差的結論。不僅在手寫體識別問題上,在圖像分類、語音識別等問題上,若數據集受到噪聲干擾,其精度同樣會大幅度下降。
針對DCNN 魯棒性較差問題,一方面應提出新方法改善DCNN 的抗噪性能,另一方面應探索深度學習下的其他分支技術,相信存在一種潛在的AI 技術在魯棒性、可解釋性等性能上會優于DCNN,如目前正在研究的深度模糊系統(Deep Fuzzy System,DFS)。發現具有強可解釋性與高魯棒性的AI 技術以更好地解決新時代下日益復雜的實際問題是后續研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
