面向權重可變的存算一體加速器的卷積算子調度
2021-05-28 12:37:36師緊想
現代計算機 2021年10期
關鍵詞:指令
師緊想
(上海交通大學電子信息與電氣工程學院,上海200240)
0 引言
深度卷積神經網絡迎來了巨大的發展,傳統CPU、GPU越來越難以滿足大規模神經網絡對功耗和能效的需要。隨著Dennard定律縮放的失效[1],存算一體加速器以低功耗、高能效的計算特點受到了廣泛關注。以憶阻存儲器(Resistive Random Access Memory,ReRAM)為基礎的存算一體加速器是存算一體一個重要研究方向[11-12]。
存算一體加速器具有存儲單元與計算單元一體的特點,因此給面向存算一體的編程和資源調度帶來了困難,一些存算一體加速器[2-3]仍采用手工映射的方式部署神經網絡模型。本文面向憶阻器存算一體設計了指令生成工具,并設計了算子調度策略,解決面向存算一體神經網絡加速器的編程、編譯問題。
1 憶阻器存算一體架構
憶阻器存算一體加速器的基本單元是憶阻器交叉陣列(crossbar),當前的存算一體加速器普遍采用多個憶阻器交叉陣列組成計算點陣,并將訓練后的卷積神經網絡的參數(權重)一次性映射在陣列上。例如ISAAC[2]采用了12k個crossbar組成一個從chip到tile到crossbar的層次化計算架構,每個crossbar包含128行×128列個憶阻器單元,可以映射48Mb模型參數,足以映射如ResNet-18網絡的所有參數,而不需要考慮crossbar再次映射的情況(后文稱再次映射為權重更新)。
而實際上受限于工藝條件,crossbar很難做到128行×128列的規模[4,5,6],并且從面積和利用率等實際情況考慮:①采用上萬個crossbar占用了很大的面積,增加了功耗;②在映射部分參數規模不大的網絡時,硬件資源利用率不高;③存在神經網絡參數規模可達到億級,對于這些極大規模的網絡,該架構仍然無法一次性映射全部權重。考慮這些情況,本文抽象出來存算一體架構的一些共有特征,提出一個陣列規模小的權重可變的存算一體架構,通過多次映射權重來完成整個網絡的計算,并且通過本文設計的軟件棧完成具有多次權重更新的編譯需求。
本文面向的架構如圖1所示,其中左側是該架構的tile級結構,包含一個全局共享存儲器和4個core。通過高帶寬的H-tree互聯結構,core可以訪問tile上的全局共享內存,每個core包含9個邏輯crossbar,每個crossbar由64×64個2bits憶阻器單元構成,即本文所基于的架構可同時映射144Kb權重,最小矩陣向量乘執行單元為64×64×8bits。由于架構需要多次更新crossbar上的權重,考慮到crossbar更新權重的代價較高,本文將在后文設計相關的調度策略緩解這個問題。
存算一體加速器具備軟件可編程性,如圖1右側所示,本文架構的Core單元可以執行從/向tile的全局存儲器上讀取/寫入數據的過程,并可以獨立譯碼和執行計算過程。
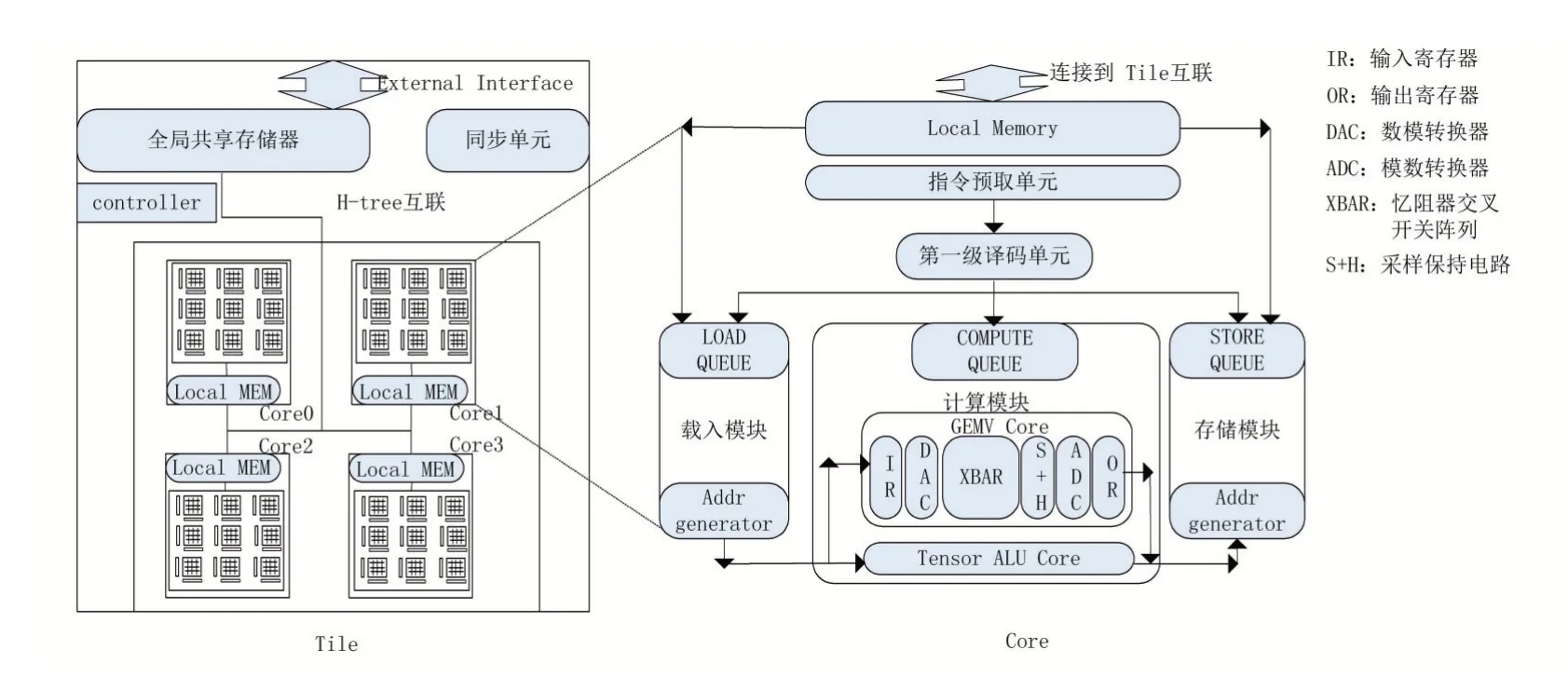
圖1 存算一體層次化架構
2 指令與代碼生成
2.1 流程介紹
當前存算一體加速器上部署神經網絡模型時大多采用手工映射的方法,為了減少開發時間,一些工作[7][8]設計了編譯軟件棧,但是缺乏算子優化且沒有考慮權重更新的情況。Halide[9]是一個解耦計算與調度的代碼生成工具,本文的指令生成工具在算子優化方面結合Halide的思想,提供了優化算子的能力,并且考慮了crossbar的權重更新。
本文指令生成工具的代碼生成流程如圖2所示。
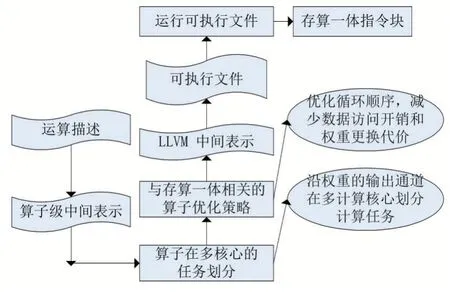
圖2 編譯流程圖示
首先利用Halide描述運算,再將運算描述轉換成Halide算子中間表示,并將循環嵌套表示的算子進行任務劃分、分割成與硬件原語綁定的執行單元,以方便后續代碼生成。最后將算子級中間轉換成LLVM IR,將LLVM IR翻譯成可執行文件后,運行可執行文件,可以生成存算一體指令,最后借助驅動工具將指令加載到Core單元并執行。
2.2 算子任務劃分與并行
考慮到加速器執行的最小運算粒度是矩陣向量乘操作,因此需要將以循環嵌套描述的卷積等運算拆分成硬件可執行的矩陣向量乘操作單元。另外為了讓算子在多個Core上并行執行,采取將以循環嵌套描述的算子的一些計算軸與計算核進行綁定的方法。考慮減少計算依賴等因此,本文將卷積的輸出通道與Core進行綁定。
如圖3所示,本文首先在卷積算子的7層循環中將輸出通道C表示的循環軸分割成兩個子循環軸C_o與C_i,分割的因子為64,以便匹配硬件最小執行單元,進一步以因子4分割C_o通道,以綁定4個計算核心。最終形成從外到內為C_o_outer、C_o_inner、C_i的循環順序,并在算子IR上的C_o_inner軸上利用語法標記為并行,以便在代碼生成時將該變量與計算核心綁定。
3 算子優化與調度空間探索
考慮到存算一體的輸入數據訪問以及crossbar權重更新代價,本文主要研究了兩個算子優化的技術:①連續內存訪問優化:在片上輸入緩沖區資源足夠的情況下,讀取輸入數據時,應盡量選擇讀取連續內存排列的數據,以提高DMA訪問的效率;②權重更新次數優化:在中間結果緩沖區足夠的情況下,盡量復用當前權重,減少權重更新次數。
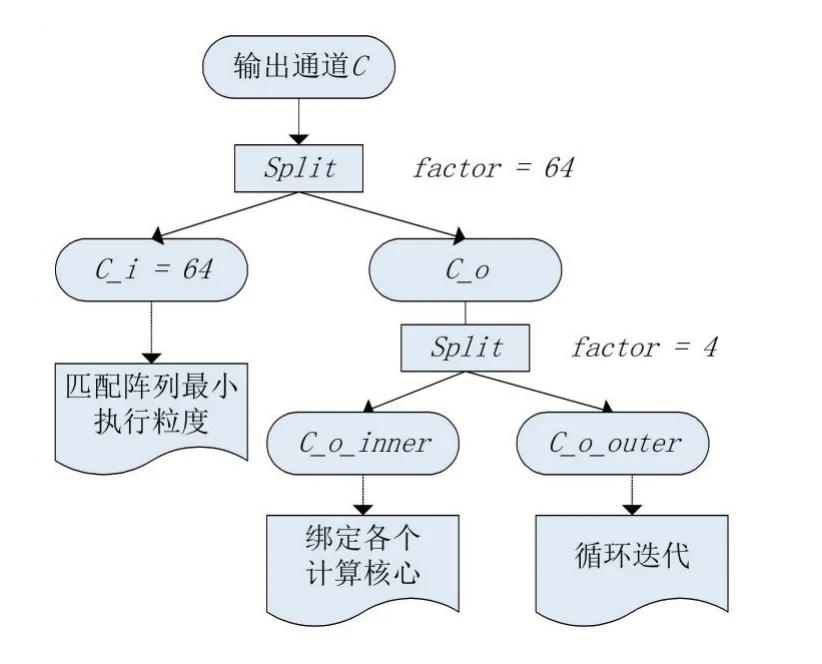
圖3 卷積運算在多核之間的任務劃分
3.1 優化連續內存訪問
考慮圖4所示的兩種讀取輸入的方式,當讀取的輸入張量是張量A表示的張量窗口時,由于第一行數據和后行的數據在內存的存放存在間隔,因此需要使用至少三次內存訪問操作(或者啟動三次DMA操作)才能將完整輸入讀入到數據緩沖區。
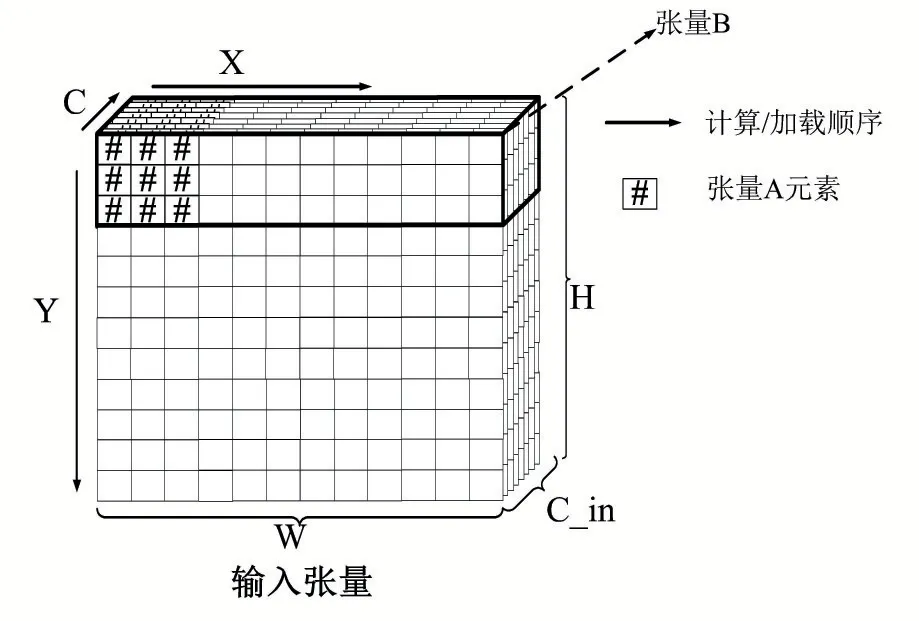
圖4 從內存中讀取輸入張量數據的兩種訪問形式
當輸入緩沖區還存在余量時,考慮張量B表示的讀取方式,由于第一行數據和第二行數據在內存中是連續存放的,因此只需要一次內存訪問指令。顯然第二種讀取方式減少讀取次數,提高了訪問效率。本文通過在編譯時檢測讀取的目標張量數據是否連續存放,如公式1所示。

并利用存儲感知輸入緩沖區的余量決定讀取張量的大小,最后決定每次讀取張量塊的大小。
3.2 優化權重更新次數與調度空間探索
前文敘述了本文架構在映射神經網絡模型時權重無法一次性映射到crossbar上,因此在計算中需要多次更新權重。因此在編譯階段本文需要解決兩個問題,一是在算子循環嵌套的何處進行權重更新,二是如何調度算子使得權重更新次數減少。對于第一個問題,結合上文中的算子任務劃分策略,對于輸入layout為[N,K,H,W](batch_size、輸入通道數、長、寬),卷積核layout為[C,K,m,m](輸出通道數、輸入通道數、卷積核大小)的卷積運算,可以得到,在卷積運算循環嵌套的輸出通道C_o與輸入通道K_o所表示的循環變量改變時,權重需要進行更新。因此本文在C_o和K_o軸設置了一個語法標記,如圖5所示,這個標記通過調用一個接口函數將Invalid標記傳送到代碼生成模塊,代碼生成模塊根據Invalid標記來判斷是否將接下來的LoadWeight指令插入到指令流中。對于第二個問題,結合圖5所示描述,通過Halide提供的循環重排方法,盡量將h_o、w_o軸排到c_o_outer與k_outer之后,減少了權重更新的次數。
本文在算子優化上借鑒了Halide解耦計算描述與計算調度的思想。首先對算子如卷積運算設置一個默認的調度模板,然后在此模板的基礎上利用reorder、split、tiling等方法對默認的循環嵌套進行循環重排、分塊等操作,以探索在指定硬件資源上的最佳計算方案。
為了探索最佳調度方案,本文首先基于調度模板和輸入負載的大小生成調度空間,在調度空間中通過遍歷并評估各個點以找到最佳調度方案,并將最佳調度生成到記錄文件,在遇到相同計算負載時可以直接從記錄文件中提取相應的調度方案,減少不必要的調度空間探索時間。
如圖5所示,本文首先將卷積的循環軸如C軸、K軸進行第一步拆分,如公式(2)、(3)所示,其中C_i與K_i用以匹配硬件最小執行單元,再進一步對C_o、K_o以及H,W,N軸采取類似的分割策略,可以生成一個由C_o_outer,C_o_inner,H_o,H_i,W_o,W_i,N_o,N_i組成的一個與變量順序和幅度有關的調度空間。

圖5 卷積循環分塊與調度(分塊因子由調度空間中所選的調度方案決定)
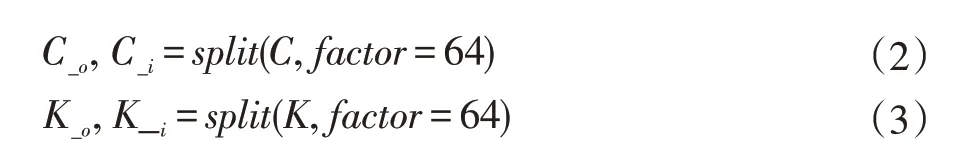
由于不同的排列組合下的申請buffer空間、中間結果所占的空間、內存訪問次數以及權重更新次數都有所不同,因此可以尋優一個最佳調度。
4 實驗結果與分析
4.1 實驗方法
為了驗證本文指令生成工具編譯流程的正確性和調度策略的有效性,本文基于PUMA[10]仿真器進行修改以支持本文所提出的存算一體指令,并對生成的指令塊進行仿真驗證,結合生成的各級中間表示進行分析以驗證編譯流程的正確性。最后通過與默認調度方案對比,驗證本文優化方案的有效性。
4.2 實驗結果
以batch_size=1,height=28,width=28,in_filter=128,out_filter=256,wkernel=3,padding=[1,1],stride=[1,1]的卷積運算為例,本文指令生成工具生成的含有硬件信息的算子級中間表示如圖6所示,本文在基于PUMA[10]的仿真器上對生成的指令流進行了仿真,驗證了生成結果的正確性。圖7顯示在本文的減少權重更新策略調度下,部分神經網絡的權重更新次數相比與默認模板減少了90%以上。

圖6 生成的Conv2d-ReLU算子描述
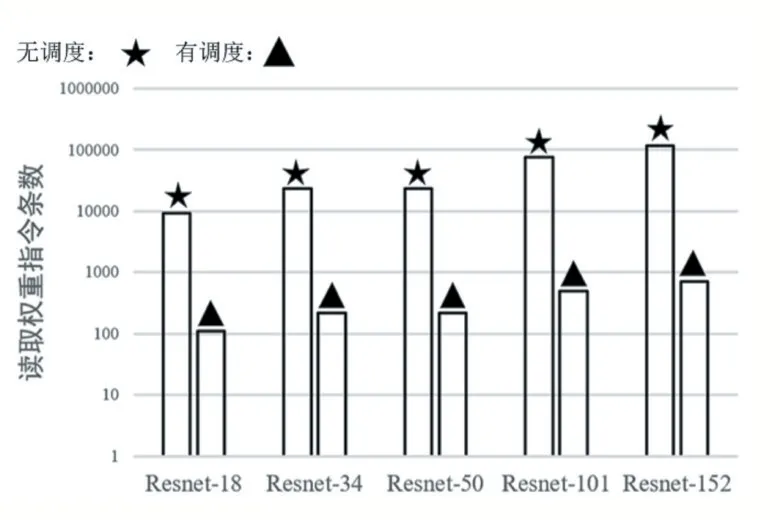
圖7 算子優化前后的映射權重的次數對比
4.3 結果分析
圖6中間表示表明了本文指令生成工具生成代碼的正確性,另外之所以本文的調度方案相比與沒有調度的方案有很大提升,是因為默認計算方案趨向于產生完成計算結果,因此產生大量權重更新,在調度之后,趨向于在中間結果緩沖區有余量的情況下優先產生中間結果,因此產生大量權重復用的情景,從而減少了權重更新次數。
5 結語
針對憶阻器存算一體加速器的代碼生成與優化問題,本文設計了一套自動指令生成的流程,在算子級中間表示上利用Halide解耦計算與調度,在生成的調度空間上探索映射卷積運算的最佳調度方案,最后相比于默認計算規則,本文減少了85%~96%的權重更新次數,大大減少了權重更新的開銷。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
時代農機(2015年3期)2015-11-14 01:14:29
科技傳播(2015年20期)2015-03-25 08:20:30
信息安全研究(2015年3期)2015-02-28 20:18:12
西安航空學院學報(2014年5期)2014-07-13 01:27:52
家電科技(2014年5期)2014-04-16 03:11:28
汽車零部件(2014年2期)2014-03-11 17:46:27
