基于XGBoost算法的水質CODmn預測模型研究
2021-05-28 12:37:46魏福平方朝陽宗宇
現代計算機 2021年10期
魏福平,方朝陽,2,宗宇
(1.江西師范大學地理與環境學院,南昌330022;2.鄱陽湖濕地與流域教育部重點實驗室,南昌330022)
0 引言
水質是人們十分關注的一個領域,水質的好壞直接影響人們的生產生活。高錳酸鹽指數(Permanganate Index,CODmn)是常用來反映飲用水、水源水和地表水受有機和無機可氧化物質污染的程度的一個指標[1]。傳統化學方法雖然具有精度高穩定性好的優點,然而其操作復雜耗時、易產生二次污染的缺點也不容小覷[2]。采用紫外-可見光譜技術對水樣的光譜進行測定,分析其光譜特征并結合相應數學關系可以快速便捷地獲取CODmn的值[3]。
本文針對國標法檢測水樣的水質CODmn的各種問題,基于極限梯度提升(eXtreme Gradient Boosting,XGBoost)算法,采用實際水樣的紫外-可見光譜數據,構建了預測水質CODmn值的XGBoost的模型。研究表明,XGBoost算法在水質CODmn值的預測中具有模型精度較高、擬合優度好的特點。
1 方法介紹與模型構建
1.1 紫外-可見光譜法
紫外-可見光譜法是通過分析水樣對入射光譜的某些波段吸收形成的光譜特征,從而得到水樣中物質的組分和濃度等信息的方法,如圖1所示。波長在10nm~380nm區間內的為紫外光譜,而在這個區間內又可以細分為遠紫外光譜(10~200nm)和近紫外光譜(200nm~380nm)。波長在380nm~780nm區間內的為可見光譜。
1.2 極限梯度提升(XGBoost)算法
2015年,美國華盛頓大學博士陳天奇等人首次提出XGBoost算法,該算法是在梯度提升樹(Gradient Boosting Decision Tree,GBDT)算法的基礎上進行工程上的優化。XGBoost在原理上與GBDT算法相同,只是在工程上把GBDT的速度和效率發揮得更極致(ex-treme)。XGBoost算法與GBDT算法的主要區別在于:GBDT中梯度下降利用的是一階泰勒公式展開,而XG-Boost采用了二階泰勒公式展開進行梯度下降;此外,為防止出現過擬合的情況,XGBoost加入了GBDT所沒有的正則項。
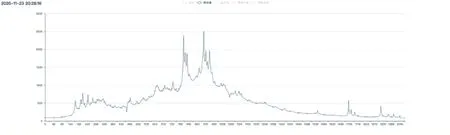
圖1 水質探頭反饋回來的水樣光譜曲線圖
XGBoost是一個樹集成模型,它使用的是K(樹的總數為K)個樹的每棵樹對樣本的預測值的和作為該樣本在XGBoost系統中的預測。現有一個包含了n個樣本的數據集D={(x1,y1),(x2,y2),…,(xj,yj),(xn,yn)},(xj∈R,yj∈R),其中,xj為第n=j個樣本的特征,yj為第n=j個樣本的標簽值(真實值)。XGBoost的預測過程如下:
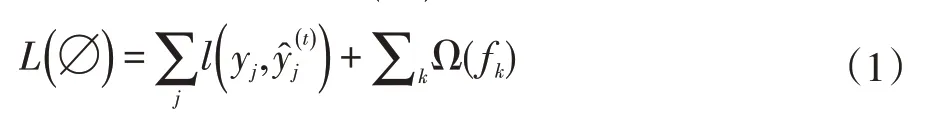

在公式(2)中,K為決策樹輸出葉子節點的個數,為(t-1)次的預測值,ft(xj)為當前時刻誤差預測值。
經CT診斷有49例為陽性,53例為陰性,eFAST檢查方式的特異性為96.23%,敏感性為89.80%,詳情見表。
(2)整合目標函數L(?):
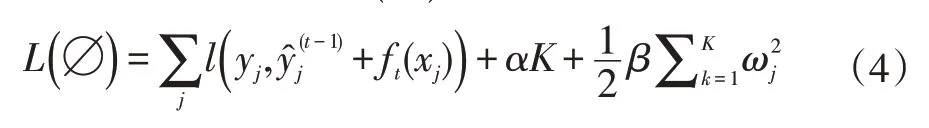
(3)對目標函數L(?)使用二階泰勒公式展開,得:
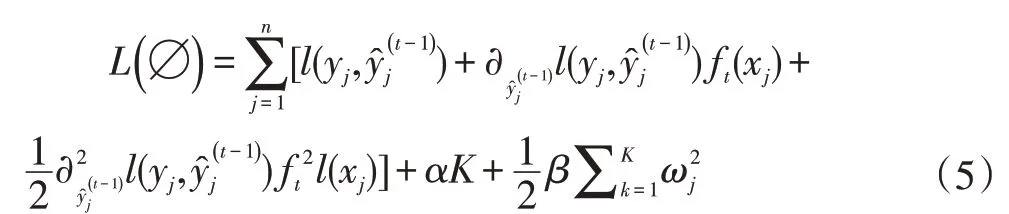

綜上,公式(6)即為所求。
1.3 預測水質CODmn值的XGBoost模型構建
本文提出的XGBoost預測模型基本流程為:在獲取所需數據并進行數據預處理后,對實驗數據進行異常值分析與處理,剔除其中的異常值,并對數據進行歸一化處理,再將數據轉化為模型所需的數據。然后將模型所需數據劃分為訓練集、驗證集和測試集三部分。將數據導入XGBoost模型,通過采用訓練集訓練模型、測試集測試模型的方式,多次重復模型訓練與模型參數調整這一過程,最終得到較為理性的模型,并以驗證集驗證模型的泛化能力。
2 數據處理和評價函數選取
本文實驗數據維度為29×2048。第1列至第2047列為水樣的全波段吸收光譜數據,第2048列為國標法(錳法)測得的水樣CODmn值(單位:mg/L)。水樣吸收光譜數據采用成都益清源科技公司生產的D73-10A型水質紫外-可見光譜探頭測得,該設備可發射在155nm~925nm波長范圍內若干組平行光束。水樣為連續三天同一時刻在兩處不同的水樣采集點采集的水樣。實驗數據如表1所示。
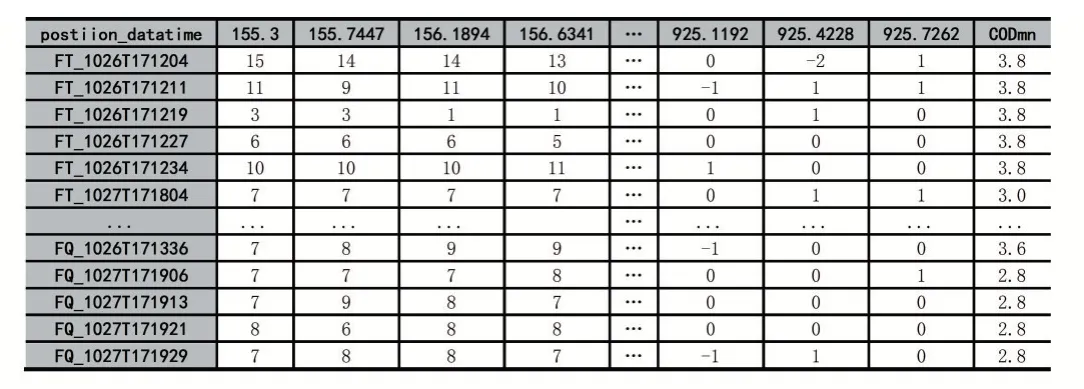
表1 水樣光譜數據和CODmn實測數據
2.1 數據預處理
由于儀器中搭載的光譜探頭會受到各種因素影響,導致某些波段下的吸收光譜出現了不合常理的值,為保證數據具有較好的連續性和模型具有較好的穩定性,需要對這類異常值進行處理。此外,由于數據中各特征的量綱都不一致,為提高模型的穩定性和精度,需要對特征屬性值進行歸一化處理。
(1)異常值處理
觀察表1可知,小于0的光譜吸收光譜值為異常值,全部集中分布在916~925nm處,而780nm以外的光譜波段已經不屬于紫外可見光譜范圍了,這一區間對測定CODmn已無影響[2]。因此,可以從實驗數據中直接去除這一區間的值。
(2)數據歸一化
由于光譜吸收值和CODmn各自的量綱不統一,其值的取值范圍差別很大,為了消除量綱在數據分析中的影響,提高模型的預測能力,需要對數據進行歸一化處理,使得各屬性下的數據取值范圍在[0,1]之間。本文采用離差標準化(Min-Max Normalization)函數,其轉換函數如下:

其中,x'為歸一化后的樣本數據,xi為某時刻某個屬性的樣本數據,xmax、xmin依次為某屬性下樣本數據的最大值、最小值。
2.2 評價函數選取
本文采用決定系數(R2)、平均絕對誤差(Mean Ab-solute Error,MAE)、均方差(Mean Square Error,MSE)來評價模型。
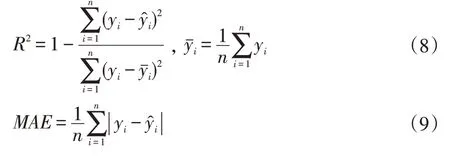

公式(8)-(10)中n為樣本數據的數量,yi為樣本數據中CODmn的實際值,?代表模型預測出的COD-mn值,為測試數據集中實際CODmn的均值。對于R2而言,其取值范圍為[0,1]:R2越接近0,說明模型的擬合效果越差,即擬合優度越低;R2越接近1,說明模型擬合效果越好,即擬合優度越高。對于MAE和MSE而言,其取值范圍為[0,+∞),值越接近0說明模型越完美,模型的精度越高。
3 模型訓練與結果
按訓練集占總數據的80%、測試集占總數據的20%比例將數據集劃分好。在Windows10系統下的Anaconda3實驗環境中,采用Python語言編寫好XG-Boost水質預測模型,反復訓練模型,并根據模型的結果反饋及時調整模型的參數使之獲得最佳預測效果。經調試,模型的最佳參數分別是:'objective':'reg:linear','booster':'gbtree','eta':0.03,'max_depth':10,'subsample':0.9,'colsample_bytree':0.7,'silent':1,'seed':10。
為驗證XGBoost模型在預測水質CODmn過程中的有效性,另使用Python語言構建了以RBF做核函數的支持向量回歸(Support Vector Regression,SVR)模型作為對比。
兩種模型的擬合圖如圖1所示。
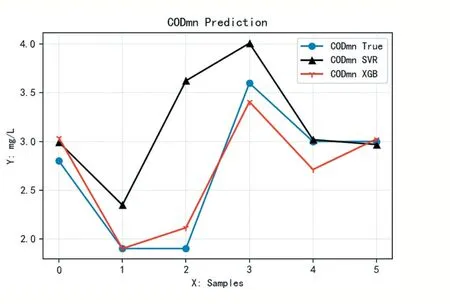
圖2 SVR模型和XGBoost模型的擬合圖
分別對SVR模型和XGBoost模型進行評價,其評價表如表2所示。其中,R2xgb=0.9021,R2svr=0.4814,XGBoost相較于SVR更接近1,說明XGBoost模型的擬合優度比SVR模型的擬合優度更好;MAExgb=0.1597 表2 SVR模型和XGBoost模型評價結果 本文采用實際水樣的實測紫外-可見光譜吸收光譜數據及國標法(錳法)測定的CODmn數據,構建了吸收紫外-可見光譜的CODmn訓練和測試數據集,并用經典的機器學習算法SVR和當今數據科學領域較為流行的XGBoost算法分別建立了CODmn預測模型。實驗結果表明,針對本文的實驗數據,XGBoost模型在水質CODmn的預測上具有更好的擬合優度和模型精度,為利用機器學習方法構建模型預測水質CODmn提供了新思路。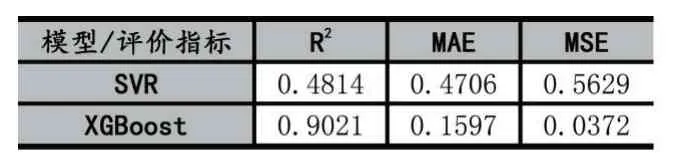
4 結語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環境(2023年5期)2023-06-30 01:20:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
當代水產(2019年1期)2019-05-16 02:42:04
當代水產(2019年3期)2019-05-14 05:42:48
電子制作(2018年14期)2018-08-21 01:38:16
光學精密工程(2016年6期)2016-11-07 09:07:19
水利規劃與設計(2016年7期)2016-02-28 15:06:27
核科學與工程(2015年4期)2015-09-26 11:59:03
