深度遷移主動學習研究綜述
2021-05-28 12:38:00劉大鵬曹永鋒張倫
現代計算機 2021年10期
劉大鵬,曹永鋒,張倫
(1.貴州師范大學數學科學學院,貴陽550025;2.貴州師范大學大數據與計算機科學學院,貴陽550025)
0 引言
近些年來深度學習在很多領域中都取得了十分顯著的成效[1-3]。其取得顯著效果的前提條件是需要數以萬計的帶有標簽的樣本,而獲取這些標簽(標注)需要消耗大量的金錢、時間和精力,成本十分昂貴。如何利用很少量的標注樣本達到目標任務高性能是急迫解決的難題。
深度遷移學習和深度主動學習是應用于深度領域中解決標注樣本不足的兩類主流方法。深度遷移學習降低了訓練樣本必須與測試樣本獨立同分布的要求,嘗試將知識從源域遷移到目標域,以提高深度模型的性能[4-5]。從空白開始訓練一個目標任務模型需要大量目標域標注樣本。而從一個與目標任務相關卻不同的源任務模型開始訓練目標任務模型,所需目標域標注樣本將會大大減少[6]。此外,源域標注樣本還可以直接為目標任務免費使用[7-8]。盡管如此,在多數情況下,將源任務模型調整到適應目標任務仍然需要較大數量的目標域標注樣本。并且從源域中遷移的標注樣本的分布可能與目標域分布差異很大,造成“負遷移”,使得模型的性能降低。
深度主動學習旨在對未標注樣本集進行選擇性采樣并標注,通過使用最少量代表性的樣本來最大化深度模型的性能,以此減少訓練深度模型所需的標注數量[9]。雖然深度主動學習可以在一定程度上降低訓練深度模型需要的標注成本,但是想要訓練一個高性能的深度模型仍然需要大量的標注樣本。
在解決訓練樣本缺乏的問題上,深度遷移學習和深度主動學習各有擅長與不足。為了更好地解決訓練樣本不足的問題,近些年來,有研究者開始將兩種方法進行結合產生了深度遷移主動的學習方法。一來可以結合深度主動學習的思想,解決“負遷移”的問題;二來也利用了深度遷移學習降低深度主動學習中獲得訓練樣本的代價。本文首先對深度遷移學習和深度主動學習進行歸納,然后總結最新的深度遷移主動學習工作,并指出了可行的研究方向。
1 研究現狀
1.1 深度遷移學習
在深度遷移學習中,訓練數據和測試數據不需要服從獨立同分布,并且目標任務模型不需要從零開始訓練,這顯著降低了深度模型在目標域內對訓練樣本量和訓練時間的需求[10]。基于遷移的目標形態,可將深度遷移學習分為:基于實例的深度遷移學習[5,11-12]和基于映射的深度遷移學習[13]。對深度遷移學習的一種稍復雜的不同形式分類可參考文獻[14]。
(1)基于實例的深度遷移學習
基于實例的深度遷移學習是將源域中與目標域相似的樣本遷移到目標域中并賦予權重以輔助目標任務模型訓練,越相似的樣本,賦予的權重就越大。這樣訓練出來的模型會很好地適應到目標域中。
Wenyuan Dai等人[5]提出了一種集成遷移學習框架TrAdaBoost,他們利用了AdaBoost的技術調整源域樣本的權重,來減弱源域中與目標域差異性大的樣本對目標任務模型的影響。在每一個迭代中,使用重新加權的源域樣本和有標注的目標樣本訓練模型。實驗證明,即使在目標域樣本稀少的情況下,也能借助加權后的源域樣本構建高性能模型。
Xiaobo Liu等人[7]在Wenyuan Dai等人[5]的基礎上進行了改進,增加了重采樣算法——Weighted-Resam-pling。在每次迭代中只從源域挑選權重值最大的樣本遷移到目標域中,并結合目標域中的原始樣本來重構訓練集。
很多實例遷移的研究[5,7]都是通過歐氏距離來衡量實例之間的差異。但是在很多實際應用中歐氏距離并不能很好地表達實例之間的相似或差異性,Yonghui Xu等人[12]提出了一種可以很好彌補這一缺陷的度量算法——MIFT。MIFT是一個多目標學習框架,可以同時學習源域數據的實例權值、目標域的馬氏距離度量以及目標域的最終預測模型。
(2)基于映射的深度遷移學習
一般地,任意深度神經網絡可以看成是將特定輸入(樣本,樣本對,多源樣本對,…)和特定輸出(預測概率,距離測度值,…)建立的一個映射。基于映射的深度遷移學習是指利用源域樣本(或者源域和目標域的樣本聯合)訓練一個網絡模型,并使用該網絡模型服務于目標任務(通常會嵌入到目標任務初始模型內部)。根據訓練樣本所用域的個數,基于映射的深度遷移學習再分為:基于單域映射的深度遷移學習和基于聯域映射的深度遷移學習。
1)基于單域映射的深度遷移學習
基于單域映射的深度遷移學習是指對僅經過源域樣本訓練的局部網絡(包括其網絡結構和連接參數)進行重用,將其轉變為目標任務模型的一部分。
Yong Xu等人[4]在語音識別的任務中設計出了一種深度遷移學習方法。該方法將DNN神經網絡的隱藏層作為語音識別的特征提取層,認為特征提取層是可以在多種語音之間相互遷移的;最后一層為語音識別的分類層。其將一個在樣本豐富的語音樣本集中預訓練的DNN網絡遷移到樣本稀缺的語音數據集上,通過凍結預訓練模型的特征提取層僅微調分類器層的方式再訓練模型。實驗證明僅使用少量的目標樣本就能顯著提高DNN的性能。
Jason Yosinski等人[15]通過實驗量化了深度卷積神經網絡各層神經元的一般性與特異性,指出神經網絡中各層神經元的可遷移性會受到兩個負面問題的影響:①源任務模型高層神經元學習到的是針對源任務的特征表示,并不適用于目標任務;②凍結過多的前層微調后層會導致網絡參數優化困難。對在ImageNet[16]上訓練的示例網絡的遷移實驗結果表明,他們證明了這兩個問題都可能占主導地位,這取決于是否從網絡的底部、中間或頂部遷移特征。除此之外,實驗結果還表明即使從很不相似任務遷移來的網絡參數也要比隨機生成的參數更好。
Maxime Oquab等人[17]重用了在ImageNet上訓練的特征提取層并在后面新添了兩個全連接層。在微調模型以適應目標任務時,凍結了在ImageNet上訓練的層,只在PASCAL VOC數據集中學習模型最后兩層參數。最終研究表明遷移學習顯著提高了物體和動作的分類結果。
2)基于聯域映射的深度遷移學習
基于聯域映射的深度遷移學習是指在預訓練中聯合使用源域和目標域的樣本訓練網絡模型,使得網絡能夠學習到使得兩域分布盡可能相近的表示。這樣訓練出來的網絡模型能夠更好地適用于目標任務。
Eric Tzeng等人[18]提出了一個新的CNN遷移學習框架,它引入了適應層和域距離損失。在適應層中通過MMD[19]的方法計算兩域的分布距離,通過最小化分類損失和域距離損失以學習語義上有意義且域不變的表示形式。
Mingsheng Long等人[20]在Eric Tzeng[18]的基礎上有了改進:①使用多核變體MMD(MK-MMD[21])距離替換MMD距離;②將在一個適應層中計算域距離損失替換為在三個全連接層中計算域距離損失。
Eric Tzeng等人[22]提出了一種域適應的廣義遷移學習框架,可以將最近的域適應的方法[13,18,20]作為特殊情況包含進去。此外,他們還提出了一種新的對抗判別域適應方法AMMD:考慮源域分類損失的同時,通過引入GAN[23]來對抗學習域不變的特征表示,這樣在學習域不變表示的同時能夠對源域樣本較好的分類。
1.2 深度主動學習
深度主動學習選擇最有價值的樣本來查詢其標簽,旨在使用少量的樣本訓練模型以達到使用全部樣本訓練的效果。一般地,設計一個深度主動學習框架需考慮三個主要部分[9,24]:①構建初始訓練集;②設置主動查詢函數;③迭代訓練。對一般主動學習(沒有使用深度模型)的詳細總結可參考文獻[25]。
(1)構建初始訓練集
構建初始樣本集是深度主動學習框架的起始階段。根據初始樣本集可訓練得到一個具備一定分類能力的初始模型,為主動挑選樣本做準備。
構建初始樣本集的方法主要有兩種。一種比較常見的是從所有未標注樣本的集合中,按照一定的比例隨機抽取出來并標注;Asim Smailagic等人[9]提出一個新的構建方法,他們采用ORB算法構造初始樣本集,是為了找到彼此最不相似的圖像,從而覆蓋更大的搜索區域。
(2)設置主動查詢函數
設置主動查詢函數是深度主動學習框架的核心。主動查詢函數可大致分為以下幾類:基于度量不確定的主動查詢函數、基于度量多樣性的主動查詢函數[26]和基于度量差異性的主動查詢函數[9]。
常見的基于度量不確定的主動查詢函數有:LC[25]、MS[27]、EN[28]。LC是根據模型對樣本預測的最大概率值對所有未標注樣本進行排序;MS是根據最優標號和次優標號對應預測概率的差值對所有未標注樣本進行排序;EN是根據模型對樣本預測概率的熵值對所有未標注樣本進行排序;Keze Wang等人[24]提出了一個與半監督方法相結合的深度主動學習方法,其在主動查詢時挑選兩種互補性樣本:高置信度樣本和低置信度樣本,來訓練當前深度模型。其中當未標記樣本的預測概率高于某個閾值時被認定為高置信度樣本,低置信度樣本是根據EN挑選得到的。
Asim Smailagic等人[9]設計出了一個用于醫學圖像分割的深度主動學習方法MedAL,其主動查詢函數基于樣本之間的差異性度量。每次主動學習迭代都挑選與已有樣本差異最大的樣本來標注學習。
Zongwei Zhou等人[26]提出了一個基于度量樣本多樣性的主動學習方法,其將樣本的多樣性定義為樣本增廣圖片預測的一致性。使用自定義的多樣性函數首先計算兩個增廣圖片之間多樣性,然后將樣本所有增廣圖片之間的多樣性指標相加得到該樣本的多樣性。
(3)迭代訓練
迭代訓練是深度主動學習框架的運行環節,它規定了如何使用不斷累積的標注數據訓練模型。
在每次主動學習迭代中,大部分研究都選擇將新標注的樣本放回已標記樣本池中,然后使用已標記池的全部樣本訓練分類器[9,26];另一種方式是使用新標注樣本和先前可用訓練樣本的特定子集[24]。Keze Wang等人[24]用新標注的樣本和由模型自動偽標注的樣本訓練模型。自動偽標注樣本每一輪都會重新更新,這樣做可以減少錯誤的偽標記樣本混亂模型。Zongwei Zhou等人[29]在每次迭代中剔除掉在已標注池中模型預測確置信度的樣本。這樣可以使得模型不再專注學習預測高的樣本而偏向學習那些難以預測的樣本。
1.3 深度遷移主動學習
主動遷移學習是將主動學習和遷移學習相結合的方法。如前文所述,遷移學習和主動學習各自包含很多類型的子方法,將這些子方法進行結合會產生更多變化。本文將主動遷移學習的方法歸納為強結合和弱結合兩種類別(參見圖1)。弱結合的方法是指:雖然其包含了遷移學習和主動學習,但是兩者在發揮作用時沒有關聯性,其中一種方法作用時并不需要另一種方法的支撐。相比之下,強結合的方法是指:主動學習和遷移學習緊密地結合在一起,彼此在發揮作用的時候有著關聯性。
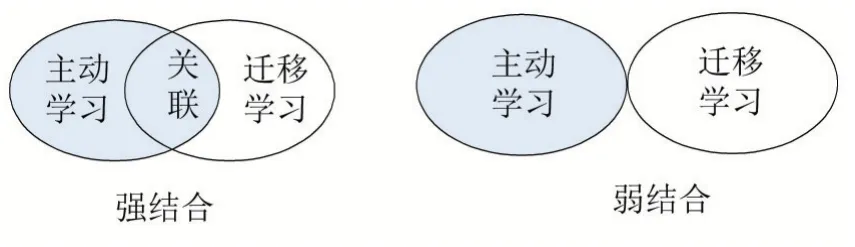
圖1 兩種類別的主動遷移學習方法
有一些研究[30-31]將主動學習、遷移學習與淺層模型進行了結合。Cheng Deng等人[30]通過MS的主動學習方法從目標域未標記數據集中挑選最具信息量的樣本進行標注,再結合源域樣本來訓練模型,并且在優化函數中添加MMD正則化項來解決兩域樣本之間存在的域適應問題。因為其主動學習部分與遷移學習所用的方法沒有聯系點、均獨立發揮作用,所以屬于弱結合的方法。
Sheng-Jun Huang等人[31]設計出一種強結合的遷移主動學習方法。此方法主動從加權后的源域樣本中挑選最不確定性以及與目標域分布匹配的樣本,其中源域樣本的權值和主動挑選的樣本是在一個基于分布匹配框架下交替優化得到。該方法為“實例遷移”和“主動學習”的強結合。
近些年,開始有少量研究將深度主動學習和深度遷移學習進行結合。Zongwei Zhou等人[26]提出了AIFT深度遷移主動學習方法。其使用了AlexNet[32]網絡模型并且遷移了在ImageNet數據集中訓練的網絡參數,同時使用了多樣性與不確定性結合的主動學習方法在目標域未標記池中挑選最具信息量的樣本訓練模型。其遷移學習部分只是簡單的“單域映射遷移”,主動學習部分采用的方法也沒有與遷移學習有聯系點,因此是一種典型的弱結合方法。
Sheng-Jun Huang等人[6]同樣采用了在ImageNet數據集預訓練的深度網絡模型,并且設計了動態權衡獨特性和不確定的主動學習方法從目標域中挑選樣本。其主動學習部分需要利用源域樣本在特征層空間的投影點計算獨特性指標,此處加強了主動學習和遷移學習的聯系,因此該方法屬于強結合類別。
Cheng Deng等人[8]使用了源域的部分樣本和通過MS主動學習函數從目標域中挑選得到的最具信息量的樣本聯合訓練在源域中預訓練過的深度模型。其將遷移來的源域樣本與主動從目標域挑選的樣本組合訓練模型,同時采用主動學習方法從源域樣本中剔除那些會影響目標模型性能的樣本。這是一種強結合的深度主動遷移學習的方法。
2 結語
本綜述主要對深度遷移學習、深度主動學習、深度主動遷移學習三個領域進行了總結和概述。
深度遷移學習和深度主動學習都可以一定程度上解決標注樣本不足的問題,而將深度主動學習和深度遷移學習結合能夠進一步降低標注成本。然而,當前對兩者的結合,即深度遷移主動學習的研究工作還不多,研究工作的深度和廣度都不夠。例如,多數工作停留在了“弱”結合的范疇,而不是“強”結合范疇;多數是兩種方法的結合:如“單域映射遷移”+“主動學習”[6,26],而很少進行三者結合:如“實例遷移”+“單域映射遷移”+“主動學習”[8];稍復雜的“聯域映射遷移”還未見與“主動學習”的結合。因此,深度遷移主動學習領域仍存在巨大的探索空間,對其的研究探索才剛剛開始。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
