基于卷積神經網絡的圖像中文OCR 識別糾錯方法及系統的研究
2021-05-31 08:29:50杜訓祥
江蘇通信 2021年1期
杜訓祥
中電鴻信信息科技有限公司
0 引言
OCR(Optical Character Recognition)是指對文本資料的圖像文件進行分析識別處理,獲取文字及版面信息的過程。即將圖像中的文字進行識別,并以文本的形式返回。
OCR 技術可應用于財務票據、證件、文字資料、檔案卷宗、文案等的錄入和處理領域。在財務領域,將OCR 識別技術運用在財務系統中,通過OCR 技術自動提取票據要素,如金額、賬號、日期、證件號等,可代替手工完成票據信息的錄入;將通過OCR 技術識別的票據金額與系統中的金額進行比對,從而可替代操作人員完成財務稽核工作,使專職人員從枯燥的重復勞動中釋放出來,投入到更高價值的工作中。借助OCR技術,自動提取票據影像數據,進而推動財務系統智慧化、自動化轉型,從系統優化的角度來看,可有效減少人工核算工作量、減少工作差錯、為系統的數據安全保駕護航;從企業發展的角度來看,可激發員工的創造性、增強企業發展能力。
但由于OCR 的識別率并無法達到百分之百,一些除錯或輔助更正的功能,也成為OCR 系統中必要的一個模塊。
1 傳統OCR 方法存在的問題
OCR 對數字、英文字符的識別效果普遍較好,然而其對中文的識別相對效果較差,這與中文字體的復雜形狀有直接關系。傳統的OCR 方法,針對文字噪聲少,設計高性能的特征向量,使用模版匹配、支持向量機或者淺層神經網絡等得到很高的識別準確度,但當用于大量噪聲或者復雜的中文文字識別時,識別效果較差。
卷積神經網絡(Convolutional Neural Networks,CNN)是一種深度學習網絡,通過卷積運算由淺入深提取圖像不同層次的特征,利用神經網絡的訓練過程讓整個網絡自動調節卷積核的參數,從而無監督地產生最適合的分類特征,對中文這種復雜的文字,具有較好的識別效果。
2 基于VGGNet 的圖像中文OCR 識別糾錯系統設計方案
2.1 VGGNet 網絡結構特點分析
CNN 即卷積神經網絡擅長處理圖像分類的問題,具有參數較少以及平移不變性的優點。VGGNet 是CNN 的一種,其網絡結構如圖1 所示
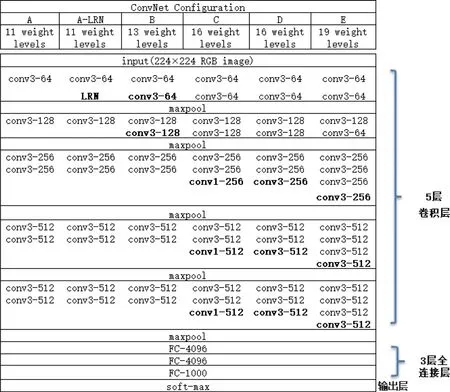
圖1 VGGNet 各級網絡結構
在池化核的選擇方面,VGGNet 全部采用2x2 的池化核,池化層用于降維,使得VGGNet 網絡模型在架構上更深更寬的同時,控制了計算量的增加規模。
VGGNet 共包含A、A-LRN、B、C、D、E 六種網絡結構,因為VGG16 全程使用3x3 卷積核與2x2 池化核,其網絡結構統一、簡潔優美,所以本文在模型選擇上選擇VGG16網絡模型。如圖2 所示。
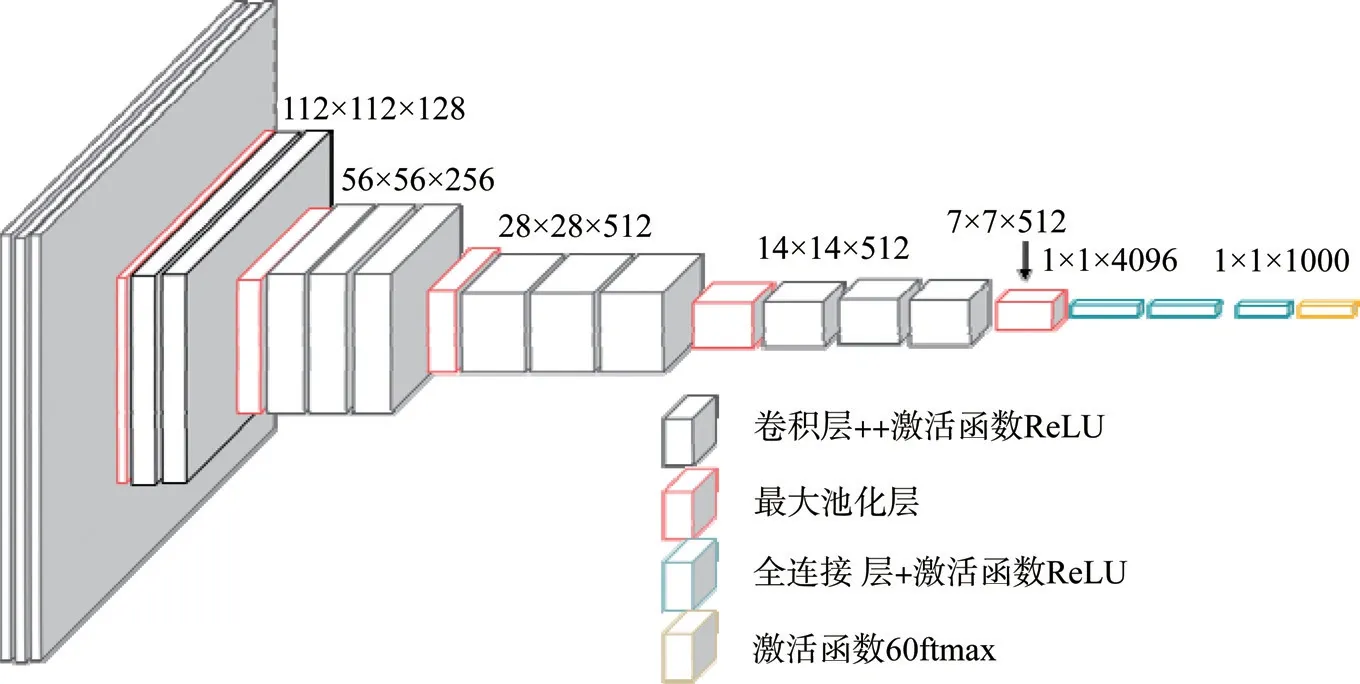
圖2 VGG16 網絡結構
2.2 系統整體設計思路
基于VGGNet 的圖像中文OCR 識別糾錯系統,首先對OCR 分析業務平臺生產中間數據進行預處理,然后對預處理后的數據進行數據清洗、接著基于Tensorflow 深度學習框架,訓練VGG 網絡模型,最后對OCR 結果進行分析,智能糾正錯誤結果。
在數據清洗方面,本文設計了三步數據處理法,包括采用OCR 識別結果做初步過濾匯總、采用驗證碼服務進行數據清洗和通過人工核驗方式進行數據清洗三個環節。
在模型訓練方面,基于Tensorflow 深度學習框架,訓練VGG 網絡模型,建立字分類器、詞分類器。
在對OCR 的識別結果進行錯誤分析時,對于不在正樣本清單中的詞語,查詢詞語映射表,若在映射表中查到該詞語則通過映射表優化OCR 的識別結果,若其不存在詞語映射表中則通過字、詞分類器對OCR 的識別結果進行優化。
壓實膨潤土混合物自由膨脹-收縮、限制膨脹-收縮過程的特征點見表4和表5。其中, 收縮量是指膨脹穩定與收縮穩定之間體積的變化率差值。
3 中文OCR 識別糾錯系統運行設計
系統運行以數據采集開始,經過數據預處理、數據清洗、模型訓練等過程,最終輸出模型,以來優化OCR 識別結果。系統主要提供預處理、數據清洗、模型訓練和OCR 識別結果優化四個功能。
3.1 預處理
基于OCR 分析業務平臺生產中間數據,對圖像中識別的字、詞進行積累,并建立字圖像庫、詞語圖像庫。具體步驟如下
首先在OCR 識別引擎模塊中,對要識別的字的局部圖像進行保存,并以時間+識別結果的方式進行命名,從而建立字圖像庫;在OCR 字段定位模塊中,對要識別的字段的詞圖像進行保存,并以時間+識別結果的方式進行命名,從而建立詞圖像庫。接著開發“字詞圖像庫匯總工具”,建立字典數據庫,開發匯總服務、字典與本地庫同步功能。最后開啟字、詞匯總服務,將識別結果相同的圖匯總在同一文件夾中,如果本地庫數據有所變化,點擊同步按鈕實現字典與本地庫同步。
3.2 數據清理
使用三步數據處理法,對字、詞庫進行數據清洗,清除錯誤的數據,合并相同類別的數據。
第一步數據清洗,是針對預處理后的數據采用OCR 識別結果做第一步過濾匯總。基于現有數據量,使用字典數據庫,查詢樣本數據量>N 的類別,做相應篩選或者增加,建立正樣本類別清單,確定全部的正樣本類別、建立負樣本文件夾。
第二步數據清洗,是基于圖像驗證碼服務做初步數據清洗,清除正樣本中的錯誤數據。首先建立圖像驗證碼服務器,服務器接受請求后輸出驗證碼圖像,并等待接受用戶的驗證值。設定清洗時間周期,如將時間周期設置為月,則每個月根據驗證數據表或者本地日志文件,來初步清洗數據。
第三步數據清洗,是通過人工核驗,完成最終的數據清洗。清洗文件夾,將不屬于正樣本類別的數據,移到負樣本文件夾;把不屬于該類別的正樣本數據,移到相應類別對應的正樣本文件夾,同時將字詞的OCR 識別錯位值與字詞的真實值對應,建立常錯字詞映射表。通過詞庫更新程序,使本地圖像庫與字典數據庫保持一致,將類型名從0 開始標注,生成標簽文件。如圖3 所示。
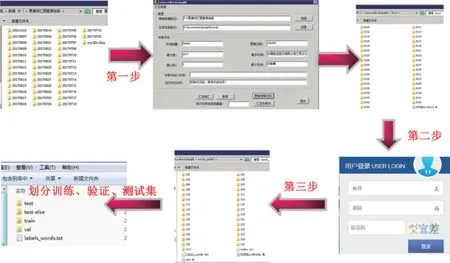
圖3 三步數據處理法示意圖
3.3 神經網絡模型訓練
基于Tensorflow 深度學習框架,訓練VGGNet 網絡模型,建立字分類器和詞分類器。
3.4 OCR 識別結果優化
對OCR 的識別結果進行錯誤分析,在正樣本清單中查詢該識別結果字符串,如果在正樣本清單中可查詢到該結果字符串,則直接輸出此結果;若在正樣本清單中查詢不到該結果字符串,則通過查詢映射表的方式進行結果優化,若映射表中存在該字符串則通過映射表中對應的字符串替換該結果;若映射表中不存在該字符串,則使用字、詞分類器對結果進行分類,將分類預測值和分類器設定的閾值進行比較,當預測值大于或者等于分類閾值時,使用分類結果替換原始結果,否則不做處理。如圖4 所示。
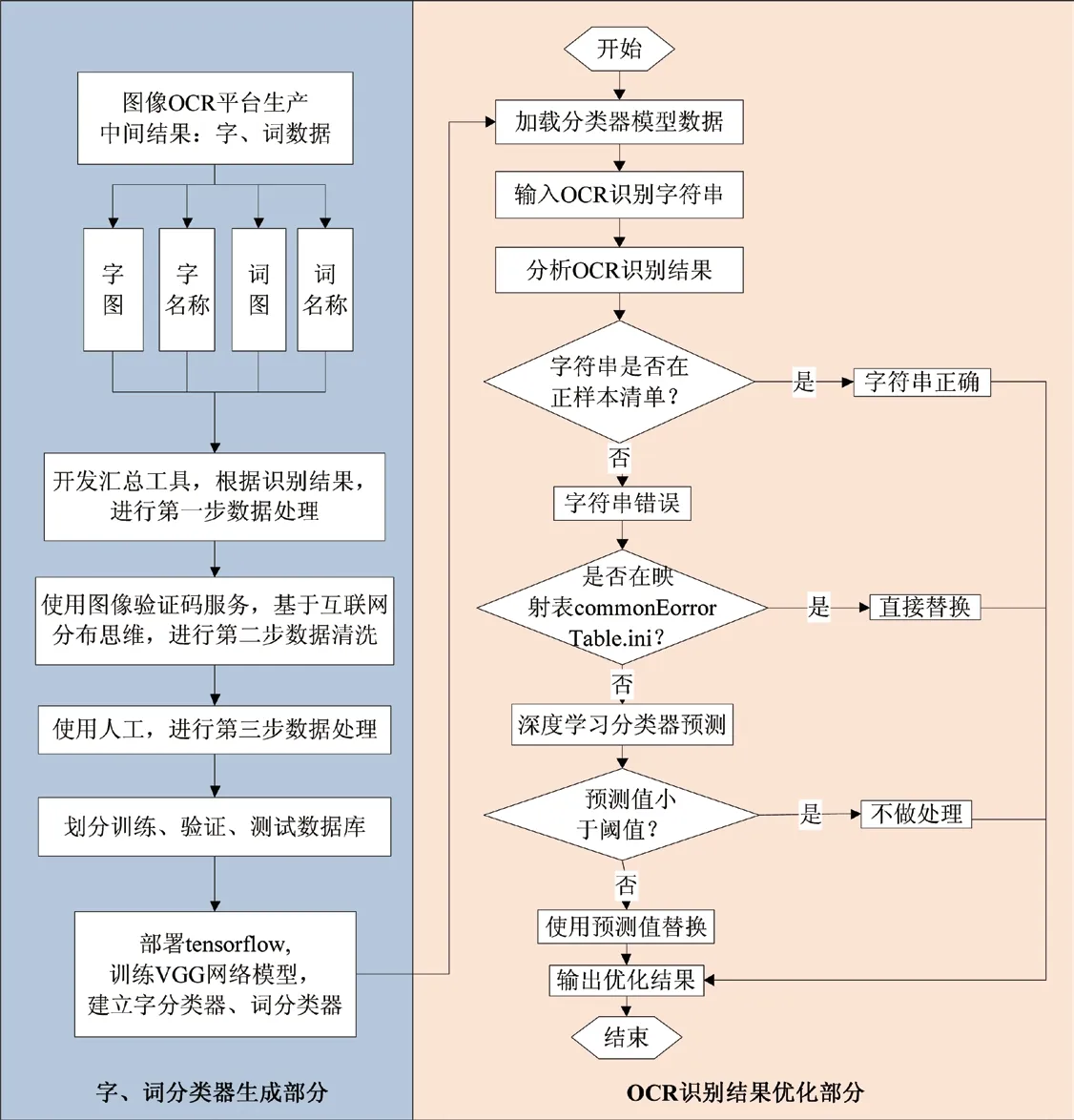
圖4 OCR 識別結果智能優化流程圖
4 初步成效
拿增值稅發票識別結果舉例,OCR 分析業務系統在改進前,由于受到票據質量影響,項目名稱和購買方服務名稱等容易出現識別出錯情況,而其中哪怕一個文字識別出錯,都將導致整個識別結果不可用。系統運行后,OCR 分析業務系統對中文詞語識別準確度,在原來的基礎上提高了10 個百分點,大部分識別錯誤的結果被糾正。對錯誤情況進行智能糾正,保證了OCR 識別結果的有效性,提升了數據的可用性,為后續的票據智能稽核打下堅實的數據基礎。
財務部門每天有大量的票據影像,多崗位員工需對同一張票據重復稽核,不僅耗費人力,且降低了報賬效率。通過圖像OCR 技術實現票面信息的提取,將提取的票面信息與報賬信息進行對比,可實現財務稽核工作的自動化。
此外,OCR 技術可應用于證件、文字資料、檔案卷宗、文案等的錄入和處理領域,如進行證件OCR,實現對身份證、駕駛證、名片等的關鍵信息的識別和提取。
5 結束語
本文在傳統中文OCR 識別的基礎上,結合深度學習方法來提高中文識別的準確度,所研究方法充分發揮了中文OCR 識別引擎的速度優勢與深度學習分類器的高準確度優勢,使得中文OCR 的準確度在原來的基礎上提高了10 個百分點。
深度學習分類器,對數據要求很高,因此數據處理工作至關重要。對于字詞數據來說,其總體數據量可以達到上億級別,本文在數據處理方面設計了三步數據處理法,首先采用OCR 識別結果做第一步過濾匯總,然后采用驗證碼服務進行第二步清洗數據,最后通過人工核驗完成數據清洗,本文設計的三步數據處理法使數據清洗工作量減少了50%,降低了數據清洗的成本。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
光學精密工程(2016年6期)2016-11-07 09:07:19
