融合FCN和LSTM的視頻異常事件檢測
2021-06-01 06:22:14武光利郭振洲李雷霆王成祥
上海交通大學學報 2021年5期
武光利, 郭振洲, 李雷霆, 王成祥
(1. 甘肅政法大學 網絡空間安全學院,蘭州 730070;2. 西北民族大學 中國民族語言文字信息技術教育部重點實驗室,蘭州 730070)
在大數據時代,智能監控技術在分析與處理視頻數據方面發揮著極其重要的作用.視頻異常事件檢測是智能監控技術的一個重要應用方向[1].人工檢測是傳統的視頻異常檢測方法,但人工檢測方法的缺點顯而易見.一方面,工作人員長時間觀察監控視頻會出現視覺疲勞和注意力不集中等狀況,進而導致錯檢、漏檢[2];另一方面,人工檢測方法較依賴于工作人員的日常經驗和反應能力[3].與深度學習相結合的智能視頻監控技術在一定程度上彌補了傳統檢測方法的不足[4],在節省人力的同時,也更為準確高效.國內外研究人員大致基于兩個研究方向解決視頻異常事件的檢測問題.
(1) 幀級檢測.使用不同的方法提取特征,訓練卷積神經網絡[5]、支持向量機等模型并計算每一個視頻幀是否發生異常事件的概率.何傳陽等[6]針對人群異常行為提出一種改進的Lucas-Kanande光流方法.柳晶晶等[7]提出一種融合光流場和梯度的方法.都桂英等[8]提出一種改進的光流計算方法,在原方法的基礎上融合加權光學能量特征(HOFO).Chen等[9]利用運動能量模型來表示人群中的局部運動模式.Luo等[10]提出一種與時間相關的稀疏編碼(TSC),使用時間相關項保留兩個相鄰幀之間的相似性.雷麗瑩等[11]提出一種基于AlexNet模型的異常檢測模型,其幀級檢測準確率較高,但并不能體現異常事件發生的具體區域和內容.
(2) 像素級檢測.通過改進全卷積神經網絡[12]、生成式對抗網絡(GAN)等模型結構對輸入對象中的每一個元素進行檢測.周培培等[13]利用ViBE算法結合光流強度信息對視頻背景進行建模和提取運動區域.Wang等[14]提出兩個基于局部運動的視頻描述符,分別是SL-HOF(Spatially Localized Histogram of Optical Flow)描述符和ULGP-OF(Uniform Local Gradient Pattern Based Optical Flow)描述符.Ravanbakhsh等[15]利用生成式對抗網絡對視頻異常事件進行檢測和定位.Sabokrou等[16]最先將全卷積神經(FCN)網絡應用于異常檢測,提出一種級聯的方式檢測和定位異常區域.Fan等[17]提出Gaussian混合全卷積變分自編碼器(GMFC-VAE),采用雙流網絡框架對RGB圖像和光流進行特征提取和融合.然而,像素級檢測雖然可以顯示異常區域,但無法體現視頻幀之間的時間相關性.
本文提出一種融合全卷積神經網絡和長短期記憶網絡(FCN-LSTM)的視頻異常事件檢測模型.首先,該模型利用卷積神經網絡提取視頻幀的圖像特征,并輸出3個不同深度的中間層結果,這些中間層結果代表著視頻幀圖像的淺層紋理特征和深層邏輯特征.然后,把中間層結果分別輸入記憶網絡中,以時間為軸線分析前后幀之間語義信息的相關性.最后,利用殘差結構融合不同深度的圖像特征和語義信息,構成不同層級的多模態特征,并通過跳級結構和上采樣把多模態特征擴大成與原視頻幀大小相同的預測圖.
1 算法
1.1 設計原理
全卷積神經網絡語義分割算法是由Shelhamer等[18]在2015年提出的,FCN模型通過將原始卷積神經網絡中的全連接層替換為卷積核為1×1的卷積層來實現全卷積神經網絡結構.由于1×1卷積在FCN網絡模型里的主要作用是降維,融合不同通道上的特征,既可以減少模型參數、減少計算量,也可以對不同特征進行尺寸的歸一化.通過1×1卷積和跳級結構,FCN網絡可以將來自多個不同深度的特征圖通過求和的方式進行融合并進行上采樣,即對圖像中的每個像素點進行預測,最終輸出一個與輸入圖像大小相同的預測圖.FCN網絡結構如圖1所示,其中數字代表每一層卷積核的個數.
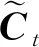
圖1 FCN網絡結構圖Fig.1 Structure diagram of FCN network
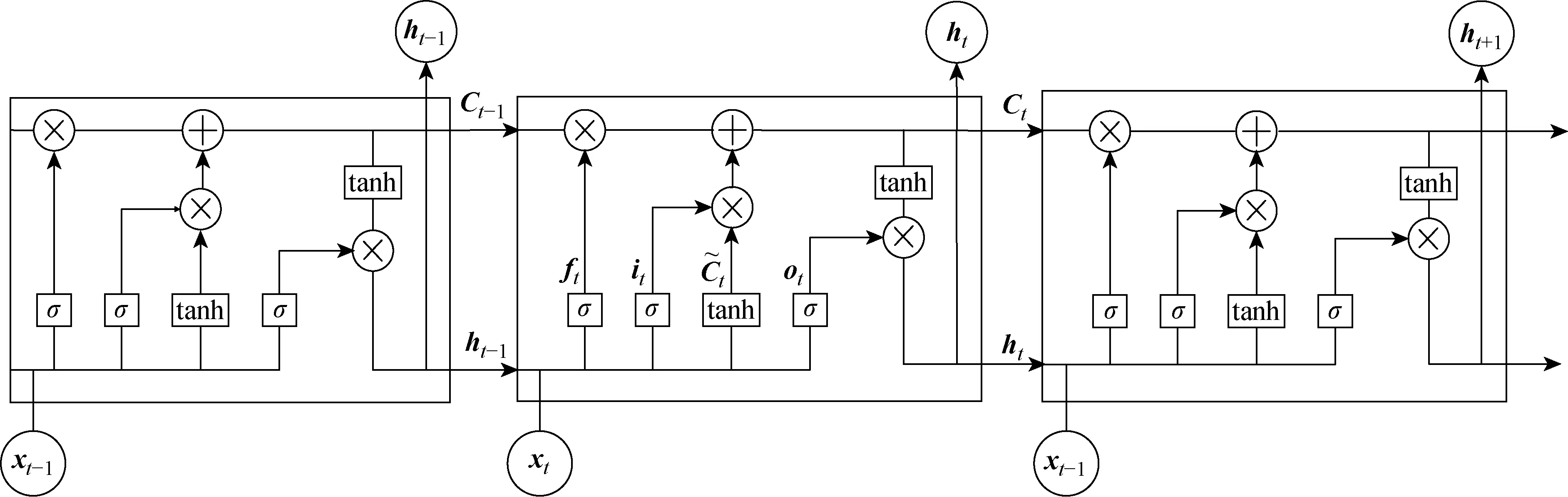
圖2 LSTM網絡細胞結構圖Fig.2 Cell structure diagram of LSTM network
由圖2可知,LSTM網絡的細胞狀態受到3個門的控制,也就是圖2中的σ,σ的本質是Sigmoid激活函數,輸出一個0~1之間的向量.LSTM在訓練時第1步需要判斷是否激活遺忘門,通過上一個時刻的輸出和當前時刻的輸入決定細胞狀態要遺忘前一時刻的哪些數據.當ft=0時,前一時刻的細胞狀態Ct-1被遺忘;當ft=1時,Ct-1被全部保留;當ft=0~1時,Ct-1被部分遺忘.公式表示如下:
ft=σ(Wf×[ht-1,xt]+bf)
(1)
式中:ht-1為前一時刻的輸出;xt為當前時刻的輸入;Wf為遺忘門權重;bf為遺忘門偏置.
it=σ(Wi×[ht-1,xt]+bi)
(2)
(3)
式中:Wi為輸入門權重;bi為輸入門偏置;Wc為新數據權重;bc為新數據偏置.
第3步更新細胞狀態,通過遺忘門和輸入門分別控制著上一時刻的細胞狀態Ct-1是否被遺忘和更新.符號“○”表示兩個向量對應位置的元素相乘.則
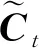
(4)
最后判斷是否激活輸出門,通過上一個時刻的輸出和當前時刻的輸入決定細胞狀態要輸出哪些狀態特征,并利用tanh函數計算出要輸出的狀態特征.當輸出門ot=1時,細胞狀態Ct全部被輸出;當ot=0時,Ct不被輸出;當ot=0~1之間時,Ct部分被輸出.
式中:Wo為輸出門權重;bo為輸出門偏置.
1.2 模型構建
FCN-LSTM模型的網絡結構可以分為3個部分:圖像特征提取部分、語義信息提取部分、特征處理部分.其中,圖像特征提取部分由卷積層、池化層組成;語義信息提取部分由LSTM層組成;特征處理部分由反卷積層、跳級結構、殘差結構組成.模型結構如圖3所示,其中1/8、1/16、1/32為卷積池化后獲得的特征圖與原圖的比例.
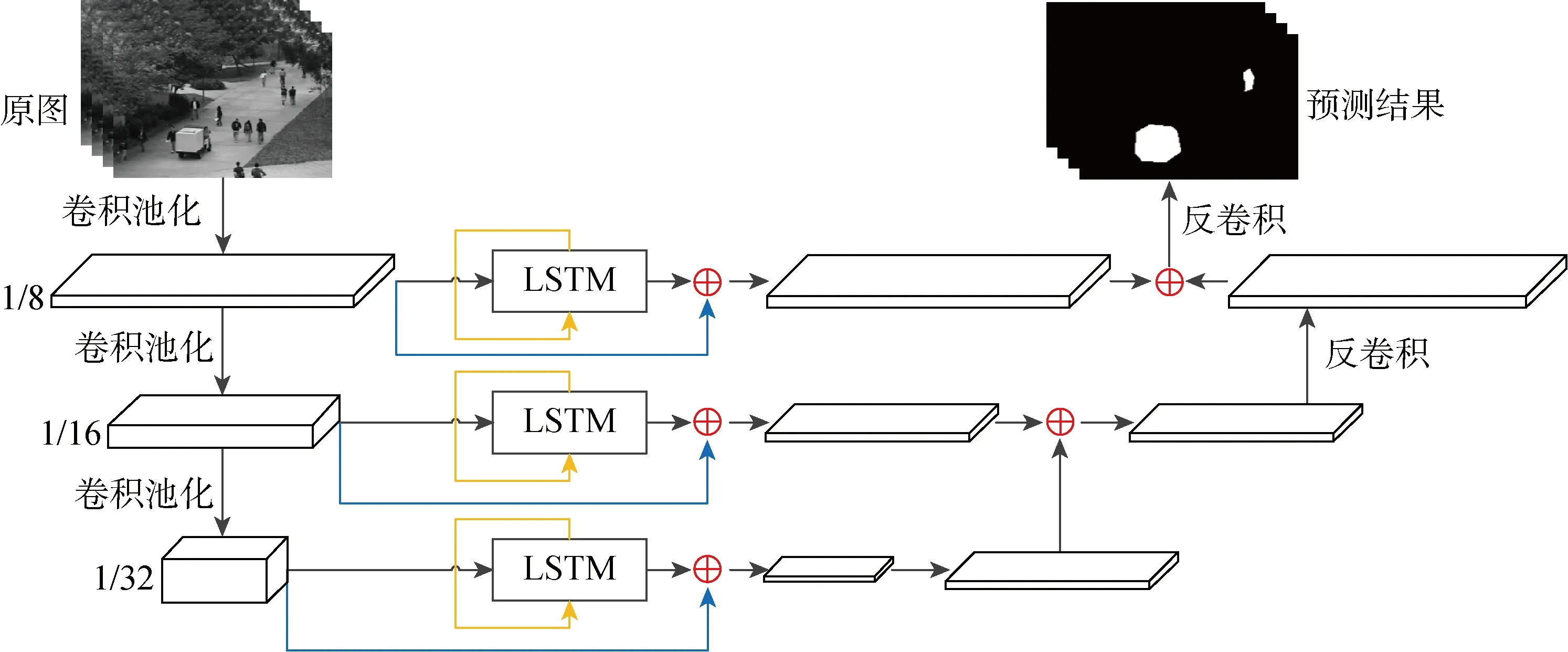
圖3 FCN-LSTM模型結構圖Fig.3 Structure diagram of FCN-LSTM model
1.2.1圖像特征提取部分 圖像特征提取部分使用了5個卷積塊,每個卷積塊由2個卷積層和1個最大池化層組成.每個卷積塊利用卷積層提取視頻幀的圖像特征,利用池化層采樣突出局部特征,進而提取出更有效的特征.使用卷積核為1×1的卷積層分別作用在第3、4、5個卷積塊的輸出結果上,獲得維度相同、不同深度的圖像特征,這些特征圖的大小分別是原圖像的1/8、1/16、1/32,代表原圖像的淺層紋理特征和深層邏輯特征.
1.2.2語義信息提取部分 語義信息提取部分的主體是3個獨立的LSTM層.為了能對不同的中間層結果提取語義信息,隱藏狀態的大小分別被設置為3個中間層輸出結果的特征圖大小,這樣就能夠以特征平面為信息、以維度為序列,由淺到深地提取3個層次的語義相關性.
1.2.3特征處理部分 特征處理部分是整個模型的核心,采用了多種特征處理方式,充分利用每個特征的優勢,使輸出結果更為精確.首先引用殘差結構,分別將3個層次的圖像特征和語義信息融合在一起,融合后的特征呈多元化,既保留了各方面的重要特征,又衍生出新特征.然后,利用跳級結構集成不同層次的融合特征,多模態特征可以充分體現出不同深度的特點,集成在一起不僅可以使不同特征之間粗細結合、優勢互補,還可以使特征更完整、攜帶信息更準確.最后,利用反卷積將特征擴大,獲得與原圖像大小相同的預測圖.
結合以上3個部分,本文提出了融合FCN和LSTM的視頻異常事件檢測模型.該模型把輸入的視頻逐幀分割,并通過圖像特征提取部分對視頻幀進行提取,獲得視頻幀大小為1/8、1/16、1/32不同深度的圖像特征.然后,通過語義信息提取部分對3個圖像特征進行分析,獲得深淺不同的3個層次的語義信息.最后,通過特征處理部分將相同深度的圖像特征和語義信息相融合,將不同深度的特征集成,再利用反卷積獲得與原圖像大小相同的預測圖.
1.2.4模型的詳細配置 圖像特征提取部分由14個卷積層、5個最大池化層和Relu激活函數組成.14個卷積層的輸出維度依次為32、32、64、64、128、256、512、512、256、128、64、2、2、2,卷積核大小均為3×3,步長均為1,填充均為1.池化層的核大小均為2,步長均為2.
語義信息提取部分是由3個LSTM層組成,其輸入維度依次為49、196、784,隱藏狀態大小依次為98、392、1568,均為單層單向.
特征處理部分是由3個反卷積層和歸一化函數組成.3個反卷積層的輸出大小依次為14×14×2、28×28×2、224×224×2,步長依次為2、2、8,卷積核大小依次為4、4、16.
1.3 模型訓練與異常檢測
所提FCN-LSTM模型分別在加州大學圣地亞哥分校(UCSD)異常檢測數據集的ped 2子集和明尼蘇達大學(UMN)人群活動數據集上進行訓練,以80%作為訓練集,以20%作為測試集.訓練時使用交叉熵損失函數和Adam優化器,且學習率為0.001,通過不斷迭代求得最優解或局部最優解.異常檢測是通過模型的輸出結果獲得的,模型的輸出結果是與輸入圖像大小相同的預測圖,空間形狀為224×224×2.第0維表示每個像素是正常的概率,第1維表示每個像素屬于異常的概率,由此可以準確定位圖像中的異常區域.
2 實驗結果與分析
2.1 數據集介紹
UCSD數據集是由加利福尼亞大學圣地亞哥分校創建,通過對準人行橫道的攝像機采集,主要的異常行為是其他實體通過人行道.異常種類包括在行人乘坐輪椅、行人踩滑板滑行、機動車通過人行道、行人騎自行車等,數據集一共有98個視頻,單獨一個視頻可以分為200幀,每幀圖像大小為238像素×158像素.4張UCSD數據集中異常事件的圖片如圖4所示.
UMN數據集是由明尼蘇達州大學創建,通過攝像機拍攝不同場景下的人群,并人為安排了一些異常行為.人群的異常行為有:人群的驟聚和驟散、人群的單向跑動.數據集一共有11個場景,每個場景都是先正常再異常.4張UMN數據集中異常事件的圖片如圖5所示.

圖4 UCSD數據集中的部分異常事件Fig.4 Some abnormal events in UCSD dataset

圖5 UMN數據集中的部分異常事件Fig.5 Some abnormal events in UMN dataset
2.2 評價指標
所提FCN-LSTM模型以F1分數、等錯誤率(EER)e和曲線下面積(AUC)S作為評價指標,并在像素級下使用3種評價指標與其他方法進行比較.
2.2.1F1分數 在介紹F1分數之前,簡要描述一下混淆矩陣.混淆矩陣也稱誤差矩陣,以類別個數n構造n×n的矩陣來表示精度,主要用于對分類任務的預測結果統計.
在二分類的混淆矩陣中,分為真實標簽:真、假,預測標簽:陽、陰,如表1所示.其中:真陽例(TP)代表真例的數據被標記為正例;偽陽例(FP)代表假例的數據被標記為正例;真陰例(TN)代表假例的數據被標記為負例;偽陰例(FN)代表真例的數據被標記為負例.

表1 二分類混淆矩陣Tab.1 Binary confusion matrix
單一的精準率p和召回率r只能表征模型某方面,F1分數可看作為精準率和召回率的一種調和平均,可以較全面地評價模型.三者的計算公式為
(7)
(8)
(9)
2.2.2曲線下面積 曲線下面積是指接收者操作特征曲線(ROC)與橫軸之間所圍成的面積.AUC是一種評價二分類模型好壞的指標,其取值范圍為0.5~1,數值越大說明模型性能越好.
ROC曲線是以偽陽例率(Pfp)為橫軸,真陽例率(Ptp)為縱軸得到的圖像,可以直觀地反映出偽陽例率和真陽例率的關系,進而判斷模型的優劣.
根據表1計算偽陽例率和真陽例率,可表示為
(10)
(11)
2.2.3等錯誤率 等錯誤率是指錯誤接受率(FAR)和錯誤拒絕率(FRR)相等時的值.ROC曲線(像素級)如圖6所示.由圖6可知,EER的值為ROC曲線與(0,1)(1,0)所在直線交點的橫坐標,即交點對應的偽陽例率.
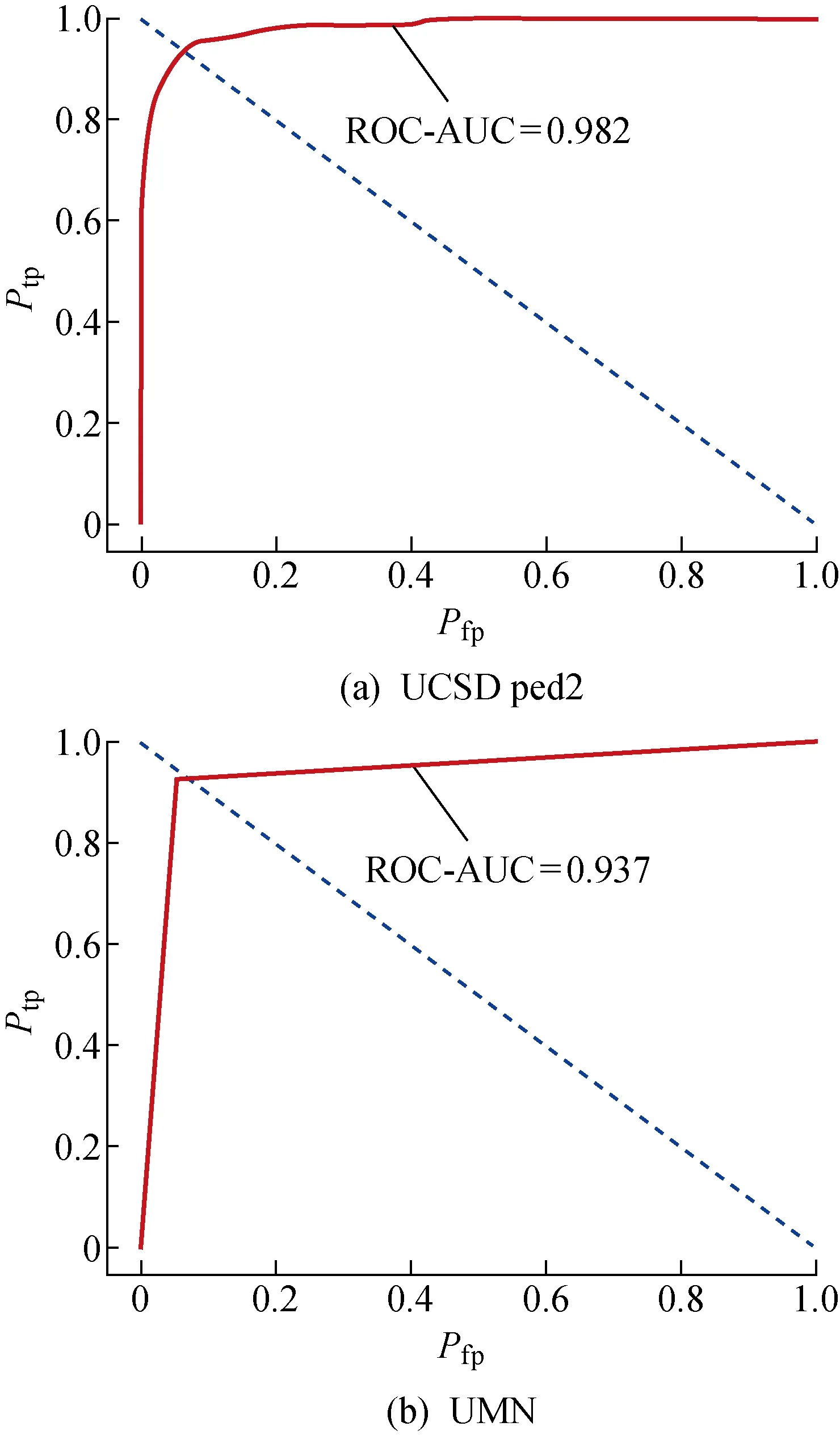
圖6 ROC曲線(像素級)Fig.6 ROC curve (pixel-level)
2.3 實驗結果
所提FCN-LSTM模型分別在UCSD和UMN數據集上進行訓練,以80%作為訓練集,以20%作為測試集.在訓練集上,通過迭代不斷更新參數,尋求最優解;在測試集上,通過訓練好的模型對數據進行預測,并根據預測結果計算3種評價指標的值.為了減小計算的開銷成本,在計算評價指標時利用隨機抽樣的方法在每個視頻幀中抽取500個符合均勻分布的像素點作為樣本.由于樣本符合均勻分布,這就使得每個像素點被抽到的概率是相同的,被抽取的樣本可以代表整個數據空間的特征.通過式(7)~(9)計算模型的F1分數,通過式(10)~(11)計算樣本的偽陽例率和真陽例率并畫出樣本的ROC曲線.通過ROC曲線獲得e和S.實驗結果如表2所示,ROC曲線見圖6.
由表2可知,FCN-LSTM模型在兩個數據集上均表現出較好的性能,獲得了較高的S和F1,說明模型具有泛化能力.其中,在UCSD數據集上,e低至6.6%,S達到了98.2%,F1達到了94.96%;在UMN數據集上e低至7.1%,S達到了93.7%,F1達到了94.46%.由圖6可知,兩個數據集的ROC曲線在交點之前的部分均陡直上升,交點之后的部分都保持較高的值,說明偽陽例率的值對真陽例率的值影響較小,模型有較好的預測能力.

表2 實驗結果(像素級)Tab.2 Experiment results (pixel-level)
2.4 與其他方法對比
FCN-LSTM模型與其他幾種達到像素級預測的先進方法在UCSD數據集上進行比較,分別為周培培等[13]提出的HOF-HOG模型、Wang等[14]提出的OCELM模型、Sabokrou等[16]提出的FCN模型、Fan等[17]提出的GM-FCN模型、Hinami等[19]提出的MT-FRCN模型,對比結果如表3所示.由表3可知,FCN-LSTM的e小于其他模型(降低了8.4%),并且S大于其他模型(提高了8.0%),說明FCN-LSTM比其他模型擁有更好的預測能力.
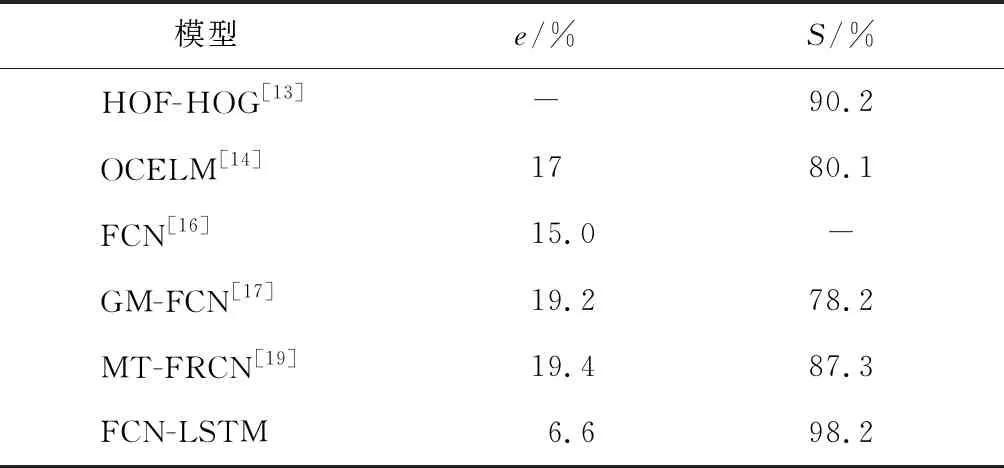
表3 各模型對比分析(像素級)Tab.3 Comparative analysis of different models (pixel-level)
2.5 模型預測
在訓練階段保存訓練好的模型及模型參數,在預測階段只需把全新數據(訓練集和測試集之外的數據)傳入模型就可以獲得預測結果,如圖7所示.
圖7(a)為UCSD ped1數據集中的4張視頻幀圖像和模型的預測結果.視頻幀中異常事件依次是一個人在玩滑板,一輛汽車在人行道上駛過,一個人推著手推車,一個人在騎自行車,預測圖中白色部分標示異常事件輪的廓和位置.
圖7(b)為UMN數據集中的4張視頻幀圖像和模型的預測結果.視頻幀中異常行為依次是人群聚散、人群單向跑動、人群聚散、人群單向跑動,預測圖中的白色部分為跑動的人的輪廓和位置.

圖7 兩個數據集中的部分預測結果Fig.7 Partial prediction results in two datasets
3 結語
本文提出融合FCN和LSTM的視頻異常事件檢測模型FCN-LSTM.該模型不僅繼承了全卷積神經網絡的像素級精度,還體現了記憶網絡的長期依賴關系,故該模型擁有多角度的處理視頻數據的能力.在UCSD數據集上e低至6.6%、S達到98.2%、F1達到94.96%;在UMN數據集上e低至7.1%、S達到93.7%、F1達到了94.46%.
在未來的工作中,將嘗試不同的方法提取不同的特征來完善所提模型FCN-LSTM,使模型預測的輪廓和位置更精準,如加入條件隨機場、加入注意力機制等方法.另外,還將嘗試不同的數據集以及自己學校的監控視頻,不斷完善本模型,使其更泛化、性能更好.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
海峽科技與產業(2016年3期)2016-05-17 04:32:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
