融合語義和交互關系的多樣性與個性化微博推薦研究
2021-06-07 06:15:05王戰平夏榕
現代情報 2021年5期
王戰平 夏榕

關鍵詞:語義關系;主題一交互關系;微博推薦;多樣性:個性化
web2.0技術的日趨成熟與快速發展,推動著全球互聯網進入網絡交互時代。微博作為web2.0時代的典型代表,它的發展和應用給互聯網信息傳播和社會生產生活方式帶來巨大的影響,逐漸成為社會信息共享和情感表達的交流互動平臺。用戶可以通過微博平臺獲取海量實時信息,滿足信息需求,同時可以拓展社交網絡,擴大人際交往范圍,建立新的社會關系。根據2019年3月15日微博數據中心發布的《2018微博用戶發展報告》顯示,截至2018年12月,微博月活躍用戶已達4.62億,日活躍用戶增至2億。隨著微博用戶和微博信息爆炸性增長,少量有用關鍵信息淹沒在海量信息海洋中,信息過載和知識缺乏現象越加突出,用戶在海量微博信息中找到自己感興趣的內容變得越發困難。如何在海量微博信息中為用戶推薦高質量的信息內容,降低用戶獲取有用信息的時間成本,有效解決“信息迷航”問題,滿足用戶信息需求,提高信息消費和利用效率,成為當前微博平臺運營管理面臨的首要問題。
1相關研究工作概述
推薦系統作為緩解“信息迷航”的有效手段,目前已被廣泛應用于各商業網絡及互聯網相關領域。當前針對微博的個性化推薦方法主要是利用博文內容、或用戶標簽、社交關系等進行用戶興趣偏好挖掘,獲取用戶興趣偏好,進而推薦與用戶興趣偏好最為相關的微博資源集合。姚彬修等提出綜合利用微博內容、交互關系和社交信息等多源信息進行用戶興趣偏好建模和相似度計算,在此基礎上進行微博用戶個性化推薦:Jain A等通過挖掘用戶在Twitter上的社交行為特征進行用戶興趣偏好分析和相似度聚類,在此基礎上進行個性化應用推薦:王剛等通過將基于時間信息的用戶興趣序列引入推薦方法之中進行用戶興趣偏好的動態獲取,結合用戶行為分析,提出了融合用戶行為分析和興趣序列相似性的個性化推薦方法:汪強兵等通過收集用戶手勢行為數據及手勢對應的內容進行用戶興趣挖掘,形成用戶興趣畫像,在此基礎上實現基于用戶興趣畫像的個性化推薦。高明等提出的微博系統上用戶感興趣微博的實時推薦方法,利用LDA主題模型進行微博主題和用戶興趣取向的推斷分析,實現了實時個性化服務。蔡淑琴等針對微博用戶創造內容和社會網絡兩要素,從關鍵詞層面人手,利用VSM模型進行用戶偏好表達,設計社會網絡修訂系數進行用戶相似矩陣修訂,實現了基于社會網絡關系驅動的協同過濾推薦模型。綜合現有研究可知,目前的推薦方法大多以提高推薦準確性為目標,雖然具有較高的推薦準確性.但推薦結果通常比較相似,不具備多樣性.推薦準確性的提高也并不意味著用戶滿意度的提升,實際上用戶更需要推薦與其興趣偏好相關但彼此之間又有一定差異性的推薦結果,即滿足多樣性和個性化要求。
實際上,針對推薦結果的多樣性與個性化問題.國內外學者已開始考慮通過犧牲較小程度的推薦準確性為代價進行推薦結果多樣性的提升,例如,JingD等提出的兼顧多樣性與個性化的搜索引擎查詢推薦方法,通過在查詢條件中嵌入多樣性要求進行推薦結果的多樣性與準確性調節:Adomavicius G等提出的基于重排序的多樣性推薦方法,利用項目預測平均值與項目流行度對推薦列表進行重排序,實現推薦結果的多樣性;張國富等提出的融合信任機制的推薦多樣性算法.通過在候選集中選擇多樣性較好的信任鄰居作為推薦代表,實現推薦結果的多樣性與準確性的調節:杜巍等提出的基于新鮮度度量的多樣性推薦模型,通過在候選推薦項目集合中增加新鮮度參數進行長尾項目所占比例的調節,實現推薦結果的多樣性。
本文在上述研究的基礎上,針對當前微博推薦結果缺乏多樣性與個性化的問題.提出了綜合考慮博文間語義關系和瀏覽博文的用戶間交互關系的多樣性與個性化推薦方法。首先,根據博文之間的語義關系和瀏覽博文的用戶之間的交互關系,構建博文主題一交互關系相關度矩陣,實現博文語義與用戶間交互關系的融合.使得用戶興趣偏好得到準確表達;其次,在博文主題一交互關系相關度矩陣的基礎上,利用k-means聚類方法進行博文多樣性劃分.使得不同主題的博文之間具有較遠的主題一交互關系距離;最后,利用矩陣分解類算法中的概率因子模型對每個聚類簇中的博文進行用戶滿意度評分,選出每個聚類簇中用戶滿意度最高的博文并降序排序,從而形成多樣性與個性化推薦列表。其中.博文語義是指博文內容之間的語義相似度,主要是針對目前博文相似度計算僅僅考慮了關鍵詞之間的語法關系,忽視了關鍵詞之間的語義關系而提出的,目的是提取更能反映用戶興趣偏好的特征概念。交互關系是指用戶瀏覽博文時的多種且重復的交互行為所形成的關系,例如評論、轉發、點贊和@某條微博等。
2融合語義和交互關系的多樣性與個性化推薦
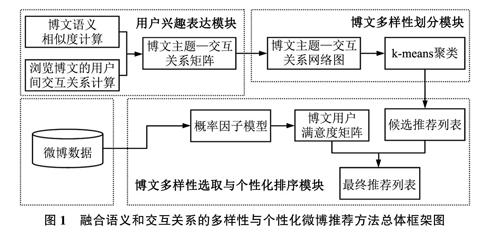
融合語義和交互關系的多樣性與個性化微博推薦方法(Diversified and Personalized Microblog Rec.ommendation Method Combining Semantic and Interac。tion Relationship.DPMRM-CSIR)總體架構如圖1所示,主要分為3個模塊:融合語義和交互關系的用戶興趣表達模塊、基于k-means的博文多樣性劃分模塊、基于概率因子模型的博文多樣性選取與個性化排序模塊。
1)融合語義和交互關系的用戶興趣表達模塊。實現多樣性與個性化的微博推薦,準確把握和理解用戶興趣偏好是關鍵。已有的微博用戶興趣挖掘方法主要是基于用戶背景信息或微博內容,由于很多情況下用戶背景信息不完善且難以全面反映用戶興趣,致使基于用戶背景信息的用戶興趣偏好挖掘的效果很不理想;而微博內容形式多樣,隨立性和碎片化嚴重,使得僅依靠微博內容進行用戶興趣偏好挖掘的實際效果也不理想,主要不足在于深層次的用戶興趣偏好難以被表達,同時忽略了交互關系對用戶興趣偏好的影響。基于上述不足,本文提出了融合博文語義和瀏覽博文的用戶間交互關系的用戶興趣表達方法,通過計算博文之間的語義相似度和瀏覽博文的用戶之間的交互關系強度,綜合加權得到博文主題一交互關系距離,形成博文主題一交互關系相關度矩陣進行用戶興趣偏好的表達。該過程主要分為3步:
Step1:計算博文之間的語義相似度。首先,采用NLPIR分詞軟件對微博內容進行分詞和詞性標注,提取關鍵詞;再利用哈爾濱工業大學實驗室提出的停用詞表和新浪微博提供的1 208個停用詞對微博內容中的“&”“@”“*”“#”等特殊符號和“啊”“哦”“哎”等語氣詞進行去除,并過濾掉“可以”“有”“等于”等意義表達不明確、不能表達用戶興趣的詞。其次,利用Mihalcea R等2004年提出TextRank排序算法進行微博內容的特征概念提取。由于利用TextRank排序算法進行特征概念抽取時,僅僅考慮了關鍵詞之間的語法關系,忽視了關鍵詞之間的語義關系,為提取更能反映用戶興趣偏好的特征概念,再利用Word2vec詞向量工具中的Skip-gram模型進行特征關鍵詞之間的語義關系計算.即將每個用戶的博文作為Skip-gram模型的訓練集,形成訓練結果,通過計算訓練結果與利用TextRank排序算法得到的特征概念之間的相似度,取相似度最高的前Ⅳ個特征概念作為博文的主題特征概念。最后,利用余弦相似度計算公式計算博文之間的語義相似度,假設用戶u的博文算方法可表示為:
Step2:計算瀏覽博文的用戶間交互關系距離。不同用戶在相同時間段瀏覽過的博文集合越相同,瀏覽博文時的交互行為越頻繁,表明這些用戶的興趣偏好越相似,他們之間的社交關系強度也就越緊密。因此,可以通過計算瀏覽博文的用戶間交互關系強度進行用戶間交互關系距離的評估。用戶瀏覽博文時可以有多種且重復的交互行為,例如評論、轉發、點贊和@某條微博(at)等,這些行為動作在一定程度上表明用戶對該博文的興趣偏好程度,因此可以根據用戶瀏覽博文時的行為動作計算用戶對該博文的興趣度,再依據不同用戶對博文的興趣度計算用戶之間的交互關系強度,從而得到瀏覽博文的用戶間交互關系距離,計算方法為:
2)基于k-means的博文多樣性劃分模塊。根據融合語義和交互關系的用戶興趣表達模塊得到的博文主題一交互關系矩陣.可形成博文主題一交互關系網絡圖,其中圖中頂點表示博文,邊表示主題一交互關系,邊的權重表示主題一交互關系相關度。基于k-means的博文多樣性劃分模塊的主要功能是利用k-means算法對博文主題一交互關系網絡圖進行聚類,使得主題一交互關系相關度較高的博文聚成一類且不同聚類之間具有較低的相關度。本文采用k-means聚類算法,即圖中每個頂點只能歸于一個類簇中。由于k-means聚類算法需要預先設置簇數K值,但由于個人微博內容分散程度不同,K值難以預先準確確定,因此本文采取自動確定K值方法進行聚類,即隨機選擇一個頂點作為第1個初始類簇中心點,然后選擇距離該點最遠的一個頂點作為第2個初始類簇中心點,然后再選擇距離前兩個頂點的最近距離最大的點作為第3個初始類簇的中心點,以此類推,直至選出K個初始類簇中心點。該過程主要分為4步:
3)基于概率因子模型的博文多樣性選取與個性化排序模塊。根據基于k-means的博文多樣性劃分模塊得到的聚類結果.博文被劃分為多個具有差異性的博文集合。基于概率因子模型的博文多樣性選取與個性化排序模塊的主要功能是利用概率因子模型預測微博用戶瀏覽博文的次數,以此評估該用戶對各博文的興趣偏好程度,形成用戶滿意度矩陣.再從博文聚類簇中分別選取一個當前用戶滿意度最高的博文,形成博文推薦列表并按用戶滿意度降序排列,實現兼顧多樣性與個性化的博文推薦。該過程主要分為兩步:
Step1:預測微博用戶瀏覽博文的次數。預測微博用戶的興趣偏好的基本思想是:如果用戶對某個博文的瀏覽次數越多,表明該用戶對該博文的興趣偏好程度越高,則將該博文推薦給用戶的價值也越高。由于用戶瀏覽博文的行為動作在很大程度上符合隨機且獨立出現的特點,因此.本文采取矩陣分解類算法中的概率因子模型進行用戶瀏覽博文的次數預測。假設F(mXn)表示用戶瀏覽博文的
再采用隨機梯度下降法進行迭代,最終得到擬合矩陣y用來預測用戶瀏覽博文的次數。
Step2:根據上述擬合矩陣y預測給定用戶瀏覽博文的次數,獲取其興趣偏好,進而從各博文聚類簇中分別選取一個用戶瀏覽次數最多的博文.并根據瀏覽次數進行降序排序.形成多樣性與個性化推薦列表。
3實驗結果與分析
3.1實驗數據
本文采用的數據集為新浪微博數據集。從新浪用戶u推薦結果中所覆蓋的主題數。
3.3實驗結果與分析
將微博數據集按照9:1劃分為訓練集和測試微博的最近更新列表中下載15 432位用戶2017年6月1日-8月30日發布的微博,存儲到數據庫中作為數據集。采集到的數據包括用戶ID、用戶名、性別、賬號等級、地點信息、標簽、博文內容、關注用戶數、轉發數、點贊數、評論數、@用戶名等信息。
實驗數據預處理主要分為3步:首先,過濾微博文本中的地址鏈接、其他無意義字符等噪聲信息后,利用NLPIR分詞軟件進行分詞和詞性標注,根據哈爾濱工業大學實驗室提出的停用詞表和新浪微博提供的1208個停用詞進行停用詞去除;其次,隨機選擇10000名用戶,從中選擇微博超過50篇和微博詞匯超過5個的用戶.最終得到8743名用戶,微博內容549834條,實驗數據描述如表1所示。
3.2實驗環境與評測指標
實驗環境為Windows 10操作系統,Intel Core(TM)2 Duo CPU 2.66GHz,4GB內存。測評指標選擇信息檢索和推薦領域常用的準確率(P)、召回率(R)、F1值進行評測,同時,增加平均主題覆蓋數進行推薦結果的多樣性測評。由于用戶更關注博文推薦的前K個結果,因此,本文采用前K條結果的準確率(P@K)、前K條結果的召回率、前K條結果的F1值(F1@K)、前K條結果的平均主題覆數(AvgD@K)進行博文推薦結果的評價.相關計算方法為:
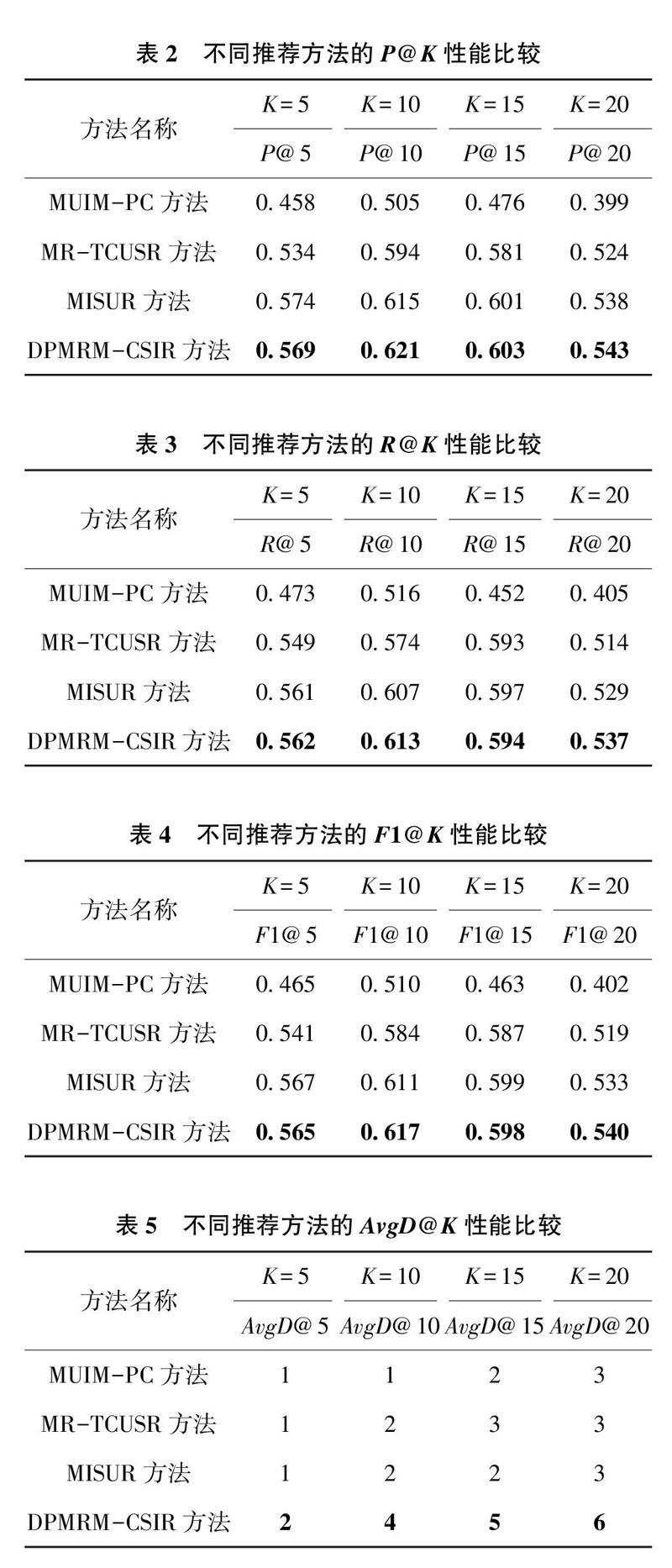
根據表2~表5可知,無論是最好情況(K=10)還是最壞情況(K=20),本文提出的DPMRM-CSIR方法的P@K、R@K、F1@K性能明顯優于MUIM-PC方法和MR-TCUSR方法,略好于MISUR方法;AvgD@K明顯優于MUIM-PC方法、MR-TCUSR方法和MISUR方法。這是因為本文提出的DPMRM-CSIR方法不僅融合博文語義內容和瀏覽博文的用戶間交互關系進行用戶興趣偏好表達,使得深層次的用戶興趣偏好得到表達,同時還利用k-means聚類方法進行博文多樣性劃分,利用矩陣分解類算法進行博文選取與個性化排序,因此能夠更加體現用戶興趣偏好.得到用戶較滿意的推薦結果:MUIM-PC方法結合用戶背景和內容進行用戶興趣偏好挖掘,對用戶間的社交關系利用不夠.故而得到的推薦結果較差:MR-TCUSR方法利用標簽關聯關系和社交關系進行用戶興趣偏好建模,針對用戶標簽缺乏問題,采用微博內容進行填充,能夠較好地表達用戶興趣偏好.故而得到的推薦結果優于MUIM-PC方法:MISUR方法綜合利用微博內容、交互關系和社交信息進行用戶興趣偏好挖掘,并引入時間權重和豐富度權重進行多源信息的權重調節,故而得到的推薦結果在P@K、R@K、F1@K性能上和本文提出的DPMRM—CSIR方法相當,明顯優于MUIM-PC方法和MR-TCUSR方法。由于該方法未考慮推薦結果的多樣性問題,因此在AvgD@K性能上明顯低于本文提出的DPMRM-CSIR方法。
為進一步驗證博文語義和交互關系對實驗結果的貢獻,分別進行僅利用博文語義進行推薦和僅基于交互關系進行推薦,實驗結果如表6~表8所示。
根據表6~表8可知.無論是最好情況(K=10)還是最壞情況(K=20),僅利用博文語義的推薦方法的P@K、R@K、F1@K性能明確優于僅利用交互關系的推薦方法,說明博文語義在反映深層次的用戶興趣偏好方面優于交互關系,交互關系對用戶興趣偏好的影響弱于博文語義,綜合博文語義和交互關系的推薦方法更能精準表達用戶興趣偏好。
由于k-means聚類方法本身存在聚類結果不確定的特征,為進一步增強論文說服力,本文選擇LDA主題模型進行聚類方法對比實驗。實驗結果如表9~表11所示。
根據表9~表11可知,無論是最好情況(K=10)還是最壞情況(K=20),利用k means方法的P@K、R@K、F1@K性能略優于基于LDA主題模型的聚類方法。這是因為本文的主要亮點是融合語義和交互關系的用戶興趣表達,既考慮博文之間的語義關系.又考慮交互關系對用戶興趣偏好的影響.因此,采用k-means聚類或采用LDA主題模型方法進行聚類的效果差別不大。
4總結與展望
隨著移動互聯網的快速發展和微博用戶群體規模的不斷增大,微博推薦受到越來越多的關注和青睞。面對海量復雜的微博信息,針對當前推薦結果缺乏多樣性與個性化的問題.提出了綜合考慮博文間語義關系和瀏覽博文的用戶間交互關系的多樣性與個性化推薦方法。首先,根據博文之間的語義關系和瀏覽博文的用戶之間的交互關系,構建博文主題一交互關系相關度矩陣,實現博文語義與用戶間交互關系的融合.使得用戶興趣偏好得到準確表達;其次,在博文主題一交互關系相關度矩陣的基礎上,利用k-means聚類方法進行博文多樣性劃分.使得不同主題的博文之間具有較遠的主題一交互關系距離;最后,利用矩陣分解類算法中的概率因子模型對每個聚類簇中的博文進行用戶滿意度評分.選出每個聚類簇中用戶滿意度最高的博文并降序排序,從而形成多樣性與個性化推薦列表。實驗結果表明.本文方法不僅使得博文推薦列表具有多樣性,同時也具有更高的推薦準確性,實現了博文多樣性與個性化推薦的有機融合。后續將重點研究用戶間社交關系對微博推薦的影響,探索融合用戶社交關系的微博推薦方法,實現更加精準的推薦。
