基于卷積神經網絡的圖像分類及應用*
2021-06-09 09:00:42高嘉平司聳濤
電子與封裝 2021年5期
王 彬,高嘉平,司聳濤
(中科芯集成電路有限公司,江蘇無錫 214072)
1 引言
近年來,深度學習在圖像檢測方面被廣泛應用,但現有的圖像檢測都是對特定識別目標的各種狀態圖像進行大量的深度學習模型訓練,該模型通用性不強[1-2],若更換檢測目標,需要進行新的模型訓練,不僅費時費力,同時上述過程需要對深度學習有一定的了解,這也增加了模型的使用門檻[3-5]。因此本研究將深度學習在圖像檢測的過程進行簡化,只需簡單記錄目標狀態就能使模型微調成該目標的檢測模型。首先利用深度學習對圖像進行分類[6],使用網上圖像分類的數據庫對網絡進行訓練,再運用檢測目標少量的各種狀態目標的數據集去微調生成遷移學習模型,模型就可以對目標進行檢測。遷移學習模型可以在原有模型的誤差和精確度不變的情況下[7]實現對現有目標的檢測,同時目標數據集微調生成學習遷移模型的過程可通過前期軟件編程完成,簡化采集數據集和訓練模型的復雜程度。
本文運用該方法設計一個報警系統,該報警系統只需要通過相機采集目標各種狀態的圖像就能對目標進行檢測,極大地簡化了深度學習在目標檢測中的應用,同時更換檢測目標也較為方便。系統的硬件部分由相機、CNN加速芯片和嵌入式系統組成。為了滿足系統在實際應用場景中的穩定性和準確率,本研究先在Imagenet數據集訓練生成預訓練模型,然后根據實際需求制作了新的數據集,即通過記錄檢測目標的不同應用場景中的各個狀態生成數據集,然后用生成的數據集去微調已經訓練過的圖像分類模型,生成新的針對該目標的圖像分類模型。
2 圖像分類及檢測算法基本原理
2.1 卷積神經網絡模型選擇
選擇基于GoogLeNet模型來搭建本次研究的模型。深度學習GoogLeNet模型采用的是卷積神經網絡框架Inception v1架構[8]。該架構的優勢是當在計算復雜度不高和計算爆炸不受控制時,可以通過增加每個階段的單元數目,增加網絡的寬度和深度;同時Inception v1結構也和圖像在進行多尺度處理之后,將圖像處理結果匯總為下一個階段能同時提取不同圖像尺寸下的特征過程相類似,其框架結構如圖1所示。它由一個1×1卷積層、一個中等大小的3×3卷積層、一個大型的5×5卷積層、一個最大池化層構成。1×1卷積層能夠提取輸入該層圖像的每一個細節中的信息特征,同時5×5的卷積層也能夠覆蓋大部分前面圖像的輸入信息,進而能提取圖像的信息特征。可以進行池化操作來減少輸入圖像映射維度的大小,降低過度擬合情況。此外在每一個卷積層后都添加了一個修正線性單元(ReLU),其作用是改善網絡的非線性特征。
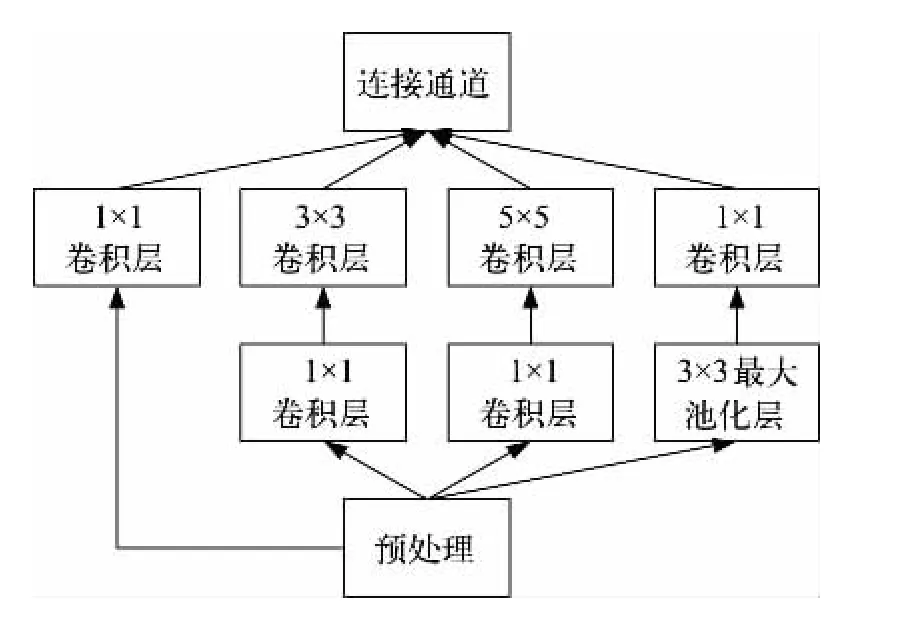
圖1 Inception v1結構
2.2 網絡模型結構
基于卷積神經網絡GoogLeNet模型結構建立本次實驗的圖像分類模型并優化網絡模型結構,如圖2所示。

圖2 卷積神經網絡的整體結構
在訓練模型之前先要確定如下幾個參數。
分類器選擇:Softmax分類器是歸一化概率分類。Softmax分類器可以將模型的結果在(0,1)內反映出來,并且所有結果相加等于1,如式(1)所示。
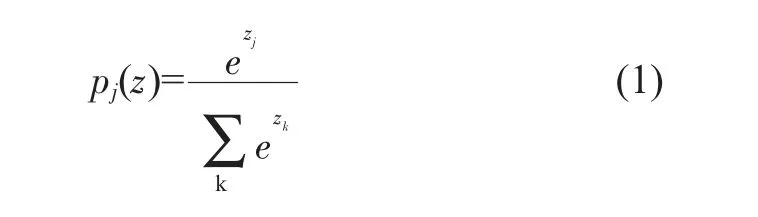
其中Zj為向量Z的第j個元素,Pj為向量Z的第j個元素的Softmax值。
損失函數:用來描述模型的理論值與實際值的差距程度,一般情況下,損失函數值越小說明模型的測試結果更能反映實際值。本文的損失函數選用Softmax loss函數,如式(2)所示。
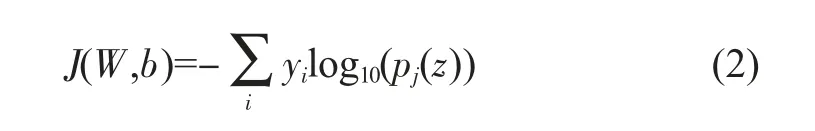
其中,W為網絡的權值矩陣,b為偏移量,y為實際測試結果,pj(z)為分類器輸出結果。
Dropout正則化:主要用于權重衰減,這樣可以解決Softmax分類器帶來的參數冗余的數值問題,同時可以使模型泛化性更強,加入Dropout正則化的網絡計算公式如式(3)~(6)所示。
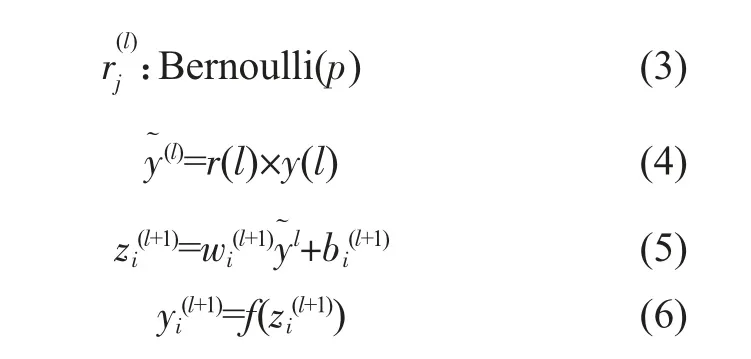
從公式(3)~(6)中可以看出函數隨機生成一個參數為0或1的概率向量,然后再乘入權重參數中,由于公式里的參數是隨機的0或1,所以會有部分的權重失效,從而解決過擬合的問題。
優化算法:為了節省計算資源和計算時間,加入隨機梯度下降法(SGD)[10],該方法用較少的數據即可實現對訓練模型的更新,同時為了使學習速度提升,將引入動量參數,如式(7)、(8)所示。
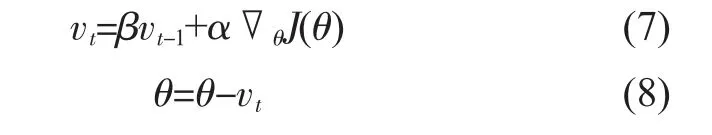
公式(7)、(8)中,vt初始值為0,β一般取值0.9,α為網絡學習率,J(θ)為損失函數。
3 訓練模型設計及分析
根據設定的網絡結構及選用的參數對網絡進行訓練,使用Caffe深度學習庫的函數式模型完成整體網絡結構的搭建,同時將α設置為0.01,選擇SGD來減少計算資源和計算時間。對數據進行近10000次迭代訓練后,通過對網絡參數的不斷調整建立了網絡模型。模型訓練后,得到train loss、test loss和accuracy 3個參數的隨機迭代次數變化曲線,最終得到訓練模型整體網絡性能評估,如圖3所示。
不難看出,迭代次數越多,模型的準確度accuracy越高,trainloss和test loss越低。在迭代5000次左右后準確度就趨近于1,train loss和test loss也不斷趨近于0。該結果表明,模型的穩健性較好,并且其性能滿足應用需求。
為了檢驗CNN模型對檢測目標狀態圖像分類的遷移學習效果,將采用分類的準確率對模型進行評估,準確率(A)由分類準確目標狀態次數和測試目標狀態總次數之比得出,如式(9)所示。

圖3 訓練模型整體網絡性能評估
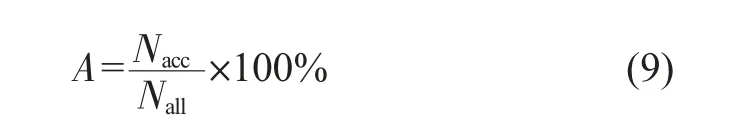
其中,Nacc為分類準確目標狀態的次數,Nall為測試目標狀態的總次數。
將訓練好的模型轉換后放入CNN加速芯片中,然后對目標各種狀態進行圖像采集,經過裁剪旋轉等方法后得到檢測目標每個狀態1000張圖像。將圖像大小統一處理成224×224×3分辨率的圖像并進行狀態標記得到數據集,將得到的數據集去更新生成新模型后,測試模型的準確率。實驗測試是檢測小燈亮滅的兩個不同狀態,經處理后得到兩個狀態各1000張標記好的圖片。然后從兩個不同狀態的圖片中隨機抽取數量相同的圖片作為數據集,最后在200、300、400、500、600、900張圖片數量的數據集下測試檢測目標狀態的準確率。表1顯示該模型在不同數量數據集下測試目標狀態的準確率。
從表1數據可以看出,隨著檢測目標數據集的數量逐漸增大,該模型檢測目標的準確率大大改善,同時數據集的數量達到900時,模型的準確率接近99.9%,表明該模型有著較高的準確度。在制作數據集時,本研究已經盡可能多地考慮到了使用場景的多樣性和復雜性,所以只需根據具體的應用場景對模型進行微調即可。

表1 不同數量數據集的檢測準確率
4 嵌入式報警系統設計
4.1 網絡模型結構
我們設計了一個基于深度學習卷積神經網絡的圖像檢測報警系統。系統整體框架如圖4所示。其中CNN加速芯片采用的是Xilinx公司的XCKU115板卡,嵌入式系統以CKS32F103作為主控芯片。

圖4 嵌入式報警系統框架
相機先采集目標各個狀態的圖像,進行標記分類后生成數據集儲存到嵌入式系統的存儲器中,在嵌入式系統中設置報警圖像類型,然后將分類好的數據集去微調已經訓練好的深度學習卷積神經網絡圖像分類模型,生成新的圖像分類模型;完成系統的初步設置后就能進行檢測目標的實時圖像檢測,相機實時檢測目標狀態,把實時影像傳輸到新生成的模型中,完成影像的分類,并把結果實時返回到嵌入式系統中;當嵌入式系統讀取到目標圖像類型后,對比設置報警圖像類型,如果圖像類型一致,嵌入式系統啟動蜂鳴器程序開始報警。
由于卷積神經網絡模型對輸入圖片的格式有嚴格要求,因此需要對相機輸入的圖片進行預處理,主要對圖片的3個參數進行調整:IMAGE_DIM、IMAGE_STDDEV和IMAGE_MEAN。見表2。由于本次算法對預處理要求較高,故采用python工具包處理。

表2 輸入圖像參數
4.2 系統響應設計
嵌入式系統的主要工作是設置需要報警的圖像類型,同時與網絡模型反饋的圖像類型分別進行對比,當二者一致時,它將驅動報警系統進行報警,驅動流程如圖5所示。為了降低因圖像類型誤判引起錯誤報警的概率,系統做了如下處理:當返回的檢測結果概率不低于0.7,并且處于報警圖像類型連續大于20幀時才會啟動警報程序,以減少錯誤警報的概率。
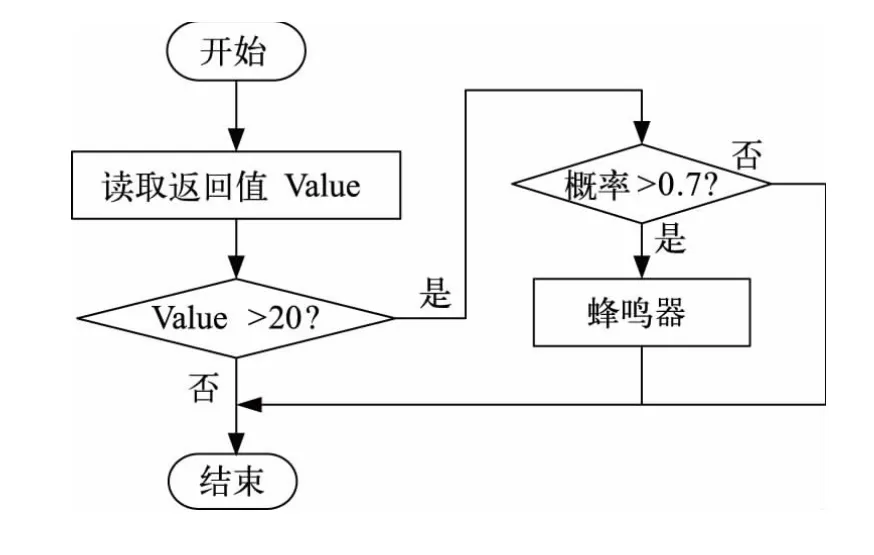
圖5 嵌入式系統報警流程
4.3 系統測試分析
本文以LED燈為檢測目標,檢測LED燈的亮滅狀態。LED燈亮表示報警狀態圖像類型1,LED燈熄滅表示正常狀態圖像類型2。搭建好測試平臺后,相機對LED燈兩個狀態進行記錄,記錄完成后生成數據集,更新生成圖像分類模型,然后再用相機去拍攝LED燈,可以看到如圖6所示的畫面,整個系統一直在實時檢測LED燈狀態。
從圖6可知,系統實時地將每幀圖像的LED燈是亮還是滅的概率呈現于顯示器中,取出現概率最大的狀態為當前LED燈所處狀態,并在每幀圖像上顯示出圖像類型。亮燈時顯示的是1,滅燈時顯示為2。然后將顯示的類型及對應的概率發送到嵌入式系統中,連續20幀且概率不低于0.7后,若反饋的信號是類型1,蜂鳴器就開始鳴響。經多次試驗測試,本系統能夠實時、準確地完成對圖像數據的獲取、檢測、分類和響應。
5 結論
本研究能快速且簡單地完成對檢測目標模型的生成和檢測,同時所設計的報警系統只需較少的檢測目標數據就能生成新的模型。最終結果表明,在簡單場景下,該系統對圖像檢測的準確度可以達到99.9%。同時在更換檢測目標時,只需要簡單使用相機記錄檢測目標各個狀態圖片,自動形成新數據集然后生成新的模型,即可實現對檢測目標的圖像分類。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
鐵道通信信號(2018年2期)2018-04-18 12:18:23
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電鍍與環保(2016年3期)2017-01-20 08:15:32
海峽科技與產業(2016年3期)2016-05-17 04:32:12
