一種基于LSTM 的機器閱讀理解模型
2021-06-11 03:54:00劉鑫
電子設計工程 2021年11期
關鍵詞:模型
劉鑫
(武漢郵電科學研究院,湖北 武漢 430074)
機器閱讀理解(Machine Reading Comprehension,MRC)的研究目標是讓計算機讀懂文章,并像人類一樣回答與文章相關的問題[1],在需要自動處理和分析大量文本內容的場景下,機器閱讀理解都可以節(jié)省大量人力和時間,因此,機器閱讀理解成為當前人工智能研究中最前沿、最熱門的方向之一。該文以百度深度學習研究院(Baidu Research-Institute of Deep Learning,IDL)提出的神經遞歸序列標注(Neural Recurrent Sequence Labeling,NRSL)模型[2]作為基礎模型,對開放域下事實類問答任務進行研究。
原模型通過LSTM+CRF[3]將MRC 轉換為序列標注問題,但是面對一段材料多次出現(xiàn)答案的情況,CRF 的表現(xiàn)并不是很好,而且直接對材料中的詞進行判斷標注,未免對模型太過嚴苛。針對這些問題,文中采用字詞混合Embedding 編碼和半指針半標注解碼的方式來改善、提升機器閱讀理解任務的精度。
1 相關工作
MRC 旨在利用算法使計算機理解文章語義并回答相關問題,當前MRC 主要分成4 個任務:完形填空、單選、跨度提取、自由問答[4],文中研究的是后兩者,即抽取式問答。最近幾年,由于深度學習的興起[5],眾多優(yōu)秀的機器閱讀理解模型脫穎而出,這些模型在網絡架構、模塊設計、訓練方法等方面實現(xiàn)了創(chuàng)新,大大提高了算法理解文本和問題的能力以及預測答案的準確性。
文獻[2]提出的NRSL 模型,文獻[4]提出的雙向注意力流(Bi-Directional Attention Flow,BiDAF)模型[6]算得上中文機器閱讀理解的開山之作,成為了之后眾多MRC 模型參照的典范。之后的模型創(chuàng)新大多集中在網絡結構的創(chuàng)新及優(yōu)化,但是對模型的輸入編碼和輸出解碼模塊優(yōu)化也是有重要意義的,該文就是在研究前人模型的基礎上,重點研究優(yōu)化編碼解碼模塊來提升模型的精度。
2 模型構建
2.1 模型整體架構
整個模型的架構圖如圖1 所示,主要由3 個模塊組成。首先提取問題特征的LSTM 層,然后是三層LSTM,用來分析證據(jù),最后便是用來解碼答案的半指針半標注模塊。
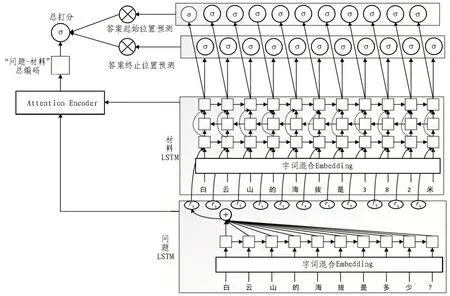
圖1 模型整體架構
2.2 字詞混合Embedding
詞作為最小的能夠獨立活動的有意義的語言成分,在機器閱讀理解模型中被廣泛地作為模型的輸入,單個字雖然沒有具體的語義,但卻十分靈活。比如在標注模型中,為了最大程度上避免邊界標注錯誤,使用以字作為基本單位輸入比以詞作為基本單位輸入要好得多,考慮到這一點,若是能綜合字和詞的各自優(yōu)勢,對模型的提升應該是十分顯著的。
為了讓模型兼顧字的靈活和詞的語義,該文使用字詞混合Embedding 作為模型輸入,其編碼過程如圖2 所示,它的原理很簡單,就是將詞向量通過變換矩陣轉換成和字向量相同的維度,再將轉換結果和字向量相加,從另一個角度看,也可以認為是通過字向量和變換矩陣對Word2Vec[7]的詞向量進行微調。

圖2 字詞混合Embedding原理圖
2.3 LSTM模塊
長短時記憶網絡LSTM 是一種特殊的RNN,是專門設計用來避免長期依賴問題的。LSTM 默認記憶長期信息,而不需要額外的條件。
定義函數(shù)(s′,y′)=LSTM(x,s,y)作為LSTM 層的輸入和輸出的映射,其中,x為經字詞混合Embedding 模塊編碼后的問題向量,s為先前狀態(tài),y為輸出,s′,y′為當前狀態(tài)和當前輸出,它們的計算方式如式(1):
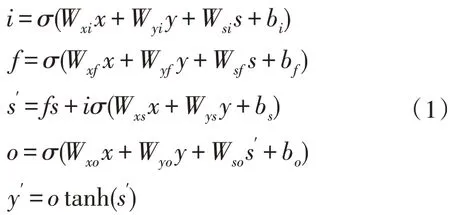
其中,W*∈RH×H為參數(shù)矩陣,b*∈RH為偏移量,H為LSTM 層的寬度,σ為sigmoid 函數(shù),i、f、o依次為輸入門、遺忘門和輸出門,LSTM的原理圖如圖3所示。
文中模型的問題和證據(jù)均用LSTM 進行分析,問題采用一層單向LSTM 分析,然后通過簡單的加性注意力[8-9]和材料向量融合作為材料LSTM 分析模塊輸入,該模塊由三層LSTM 組成,第二層LSTM 為反向LSTM,第三層LSTM 接收前兩層的輸出。
用xq=表示問題向量輸入,表示證據(jù)向量輸入。問題LSTM 為單層LSTM,對xq經LSTM 分析后,生成向量序列q1,q2,…,qN,其映射關系如式(2):
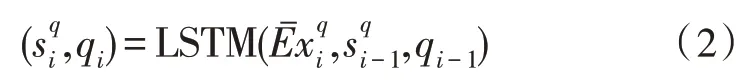
材料LSTM 由三層LSTM 構成,第一層LSTM 的輸入為rq和材料的字詞混合Embedding 通過加性注意力機制融合的定長向量,第二層LSTM 堆疊于第一層之上,但是以相反的順序處理它的輸入,第三層LSTM 將第一層和第二層的輸出作為輸入,它的輸出將作為答案解碼模塊的輸入,具體的計算方法如式(3)所示:
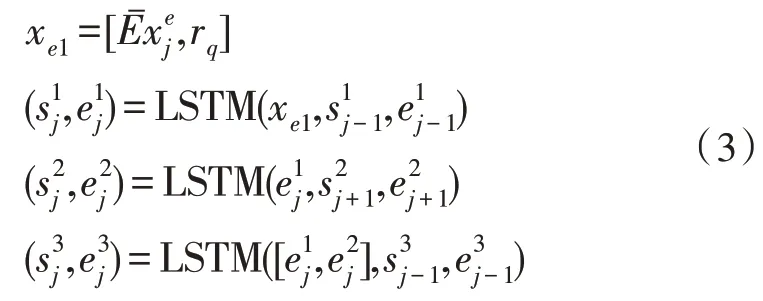
2.4 半指針-半標注解碼
答案解碼模塊對整個模型精度的影響也是十分大的,文中將原模型中的CRF 替換為半指針-半標注的模式。
既然用到標注,那么理論上最簡單的方案是輸出一個0/1 序列:直接標注出材料中的每個詞是答案(1)或不是答案(0)。然而,這樣的效果并不好,因為一個答案可能由連續(xù)多個不同的詞組成,要讓模型將這些不同的詞都標上同樣的標注結果,還是十分困難的。所以用兩次標注的方式,來分別標注答案的開始位置和終止位置,其計算方式如式(4):
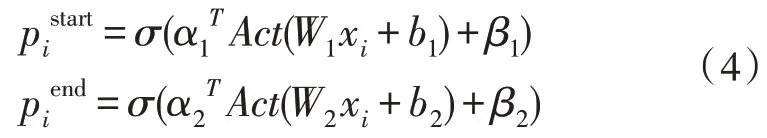
其中,Act為激活函數(shù),這里取sigmoid 函數(shù)。為了應對材料中無答案的情況,引入pglobal對整個問題和文檔信息編碼[10],得到一個全局打分,并把這個打分的結果乘到前面的標注中,即變成式(5):

這里的o即為問題和材料的整體向量,當材料中無答案時,即可直接使pglobal=0,不用讓每個詞的標注都為0。
pstart、pend分別代表了答案起始位置和終止位置的概率,但問題是,用什么指標確定答案區(qū)間呢?文中的做法是確定答案的最大長度M,然后遍歷材料所有長度不超過M的區(qū)間,計算它們起始位置和終止位置的打分的積,然后取最大值。對每段材料都得到了自己的答案的情形,又怎么把這么多段材料的答案投票出最終的答案?比如有5 段材料,每段材料得出的答案和分數(shù)依次是(A,0.7)、(B,0.2)、(B,0.2)、(B,0.2)、(B,0.2),那么最終應該輸出A還是B呢?
為了綜合考慮權重大和答案多的情況,這里將采用取“平方和”的思想,因為“平方”會把高分的樣本權重放大,而對小樣本將其加一置于分母位置,這樣其得分就會降低,其計算方式如式(6):
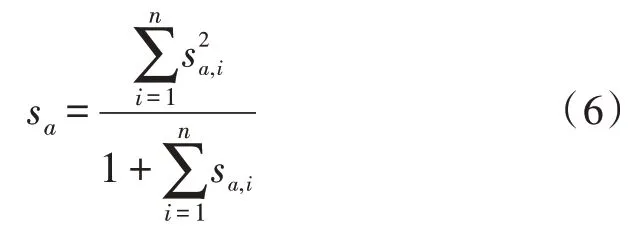
3 實 驗
3.1 數(shù)據(jù)集簡介
該文數(shù)據(jù)集采用WebQA(百度問答數(shù)據(jù)集現(xiàn)在已更新為DuReader[11]),WebQA 和DuReader 的實體類問答很類似,答案包含在材料中,該文正是對這類問答進行抽取式閱讀理解[12]任務研究。
WebQA 包含42k 個問題,566k 個材料片段,一個數(shù)據(jù)由問題、證據(jù)、答案構成,材料樣例如下:
問題:多瑙河注入哪個海?
材料1:多瑙河注入黑海,頓河注入亞速海,萊茵河注入北海
答案:黑海
材料2:泰晤士、萊茵河、易北河注入北海,萊茵河、多瑙河流入黑海,都屬于大西洋水系。
答案:黑海
材料3:多瑙河發(fā)源于德國西南部山地,向東流經9 個國家,最后在羅馬尼亞注入黑海。
答案:黑海
每個問題對應多段材料,每段材料對應一個答案,這個答案可能為空。這些問題均是由真實生活中的用戶在日常生活中提出的,因此很有代表性。該文將數(shù)據(jù)隨機均分成8 份,6 份作為訓練集,一份作為驗證集,一份作為測試集。
該文所用的詞向量由WebQA 語料、50 萬百度百科條目、100 萬百科知道問題用Word2Vec 預訓練而成[13]。
3.2 模型訓練
模型訓練采用交叉驗證[14],評估參數(shù)為查準率P(Precision)、查全率R(Recall)和P、R的調和平均值F1。
模型的預測值有兩個,為答案的起、止位置,該模型使用的損失函數(shù)源于交叉熵的思想,其計算方式如式(7):
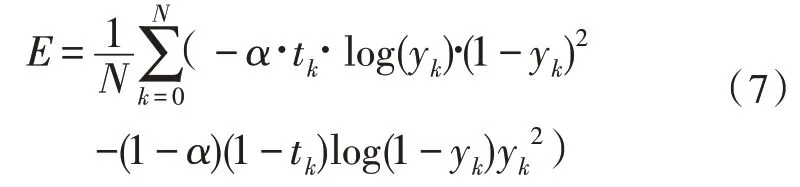
其中,tk為真實值,yk為預測值,模型的整體損失函數(shù)取兩者之和,即為式(8):

為了降低周期性干擾,訓練過程中對權重進行了指數(shù)滑動平均,優(yōu)化器采用了RAdam(Rectified Adam)[15]。此外,模型輸入詞向量維度為128,材料限制最大輸入長度為256,答案最大長度限制為10,模型訓練120 epoch。
4 實驗結果及分析
使用的評測標準有P、R、F1,該文優(yōu)化后的模型與原模型及一些經典的模型對比數(shù)據(jù)如表1 所示。
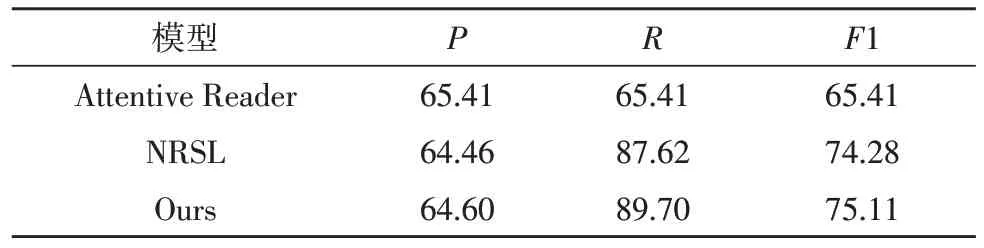
表1 模型實驗結果
從表1 可以看出,文中模型相對于原基礎模型在準確率和召回率上都有了一定的提升,尤其是召回率R的提升比較明顯。
通過字向量對輸入的詞向量進行微調,兼顧字向量的靈活和詞向量的語義,再加上半指針-半標注答案解碼模型的引入,在面對答案由多個詞組成以及一段材料中多次出現(xiàn)答案的情況,模型對答案起止位置標注的準確率有所提升,最終再通過半指針-半標注及投票的方式抽取出答案,從而提升了模型的精度。
5 結論
該文采用字詞混合Embedding 作為MRC 模型的輸入編碼,參考NRSL 模型結構,使用單層LSTM 對問題進行分析,三層LSTM 對材料進行分析,將CRF標注改進為半指針-半標注的答案解碼模塊,最終使模型的準確率和召回率都有了一定的提升。雖然該文的改進對模型性能的提升有限,但是也不可忽略對模型的輸入編碼和輸出解碼模塊進行優(yōu)化帶來的收益,針對不同的網絡結構,對編碼解碼模塊進行對應的優(yōu)化,能最大程度提升模型的整體性能。
隨著信息時代的到來,文中的規(guī)模呈爆炸式增長[16]。因此,機器閱讀理解帶來的自動化和智能化恰逢其時,在工業(yè)領域和人們生活的方方面面都有著廣闊的應用空間。因此深入研究機器閱讀理解的原理,從各方面改進模型、提升模型的精度和性能,有著十分重要的價值和意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
