基于多傳感器融合的復雜越野環境人員識別方法
2021-06-16 04:23:52劉英哲范晶晶李志鵬郭建英
汽車工程學報 2021年3期
關鍵詞:融合
劉英哲,范晶晶,李志鵬,郭建英
(1.北方工業大學 城市道路交通智能控制技術北京重點實驗室,北京 100144;2.中國北方發動機研究所,天津 300405;3.順德中專學校,廣東,佛山 528300)
軍用無人車輛的一大應用場景就是班組伴隨、跟隨士兵,減輕班組成員的負荷,可以從整體上提升班組的戰斗能力。實時、準確并且可靠地檢測出車輛周邊的人員,是班組伴隨自動駕駛實現的前提,行之有效的人員檢測技術能夠幫助班組伴隨無人駕駛車輛實現自動跟隨功能。
由于激光雷達和攝像頭原理不同,受環境影響的特點也不盡相同,采用單一傳感器對人員進行檢測,難以適應復雜的環境,所以大都采用多傳感器融合的方式。在激光雷達和攝像頭融合領域,PREMEBIDA等[1-6]通過不同方法配置的圖像數據和激光雷達點云數據訓練得到自適應人員檢測器。PONZ等[7-14]通過聯合概率數據關聯方法對激光雷達、攝像頭以及慣性傳感器等的靜態信息和在線信息進行數據關聯,以達到檢測人員的目的。在毫米波雷達和攝像頭融合領域,徐偉等[15-16]基于圖像的HOG特征和SVM分類方法以及毫米波雷達的快速容差中頻匹配算法,設計了多傳感器融合的行人識別算法,但由于HOG特征本身的局限性,行人識別率相對較低。
本文針對自動駕駛車輛對于復雜環境下人員識別的需求,將攝像頭和激光雷達作為感知設備,針對激光雷達采用基于KDTree加速的歐式聚類方法,針對攝像頭設計改進YOLO v3深度學習網絡架構,最后設計空間融合識別算法,旨在增加人員識別的準確率。通過理論計算和理論分析,結合本文所設計的微型履帶式車輛驗證平臺,在復雜環境下進行多工況實車試驗。試驗結果表明,所設計的多傳感器融合人員識別算法能夠準確識別環境中的人員目標,在復雜環境下識別率良好。
1 系統構成
復雜環境下融合激光雷達與攝像頭的人員識別系統,如圖1所示。
圖1中,通過以太網接口和激光雷達驅動程序獲得激光雷達三維點云數據,隨后應用基于KDTree的歐式聚類算法對激光雷達三維點云數據進行歐式分割和聚類[17],得到若干個人員候選點云區域。通過像素坐標系到世界坐標系的映射關系和激光雷達坐標系到世界坐標系的映射關系,可得到激光雷達坐標系到像素坐標系的映射關系,結合空間尺度融合算法將若干個人員候選點云區域分別映射到像素坐標系,并通過改進殘差模塊的YOLO v3深度學習網絡架構識別出真正包含人員的區域,并通過矩形框的形式給出各個人員在像素坐標系下的具體坐標位置,最后通過人員身份判別準則判定環境中人員是否存在、數量和位置等相關信息。
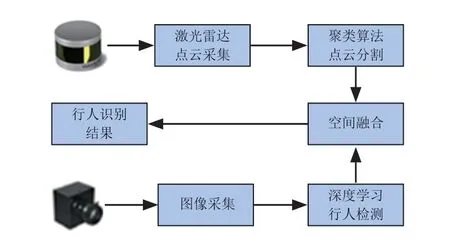
圖1 融合激光雷達與攝像頭的人員識別系統
2 方法設計
2.1 改進殘差模塊的YOLO v3深度學習架構
為了進一步提升YOLO v3深度學習網絡在復雜環境背景下對目標物體的識別性能,結合當前深度學習領域的熱點研究成果,本文提出了一種改進殘差模塊的YOLO v3深度學習網絡結構,如圖2所示。
圖2中,改進殘差模塊的YOLO v3深度學習網絡結構與原始YOLO v3深度學習網絡結構的差別主要體現在殘差模塊Residual Block的設計上。原始YOLO v3深度學習網絡中,殘差模塊RB的輸入經過兩個CBL模塊處理后的信號再與RB模塊的輸入作相加的操作,得到的結果便是RB模塊的輸出。改進殘差模塊的YOLO v3深度學習網絡中,在原始YOLO v3網絡RB輸出的基礎上增加了全局池化層、兩個全連接層、Sigmoid激活函數層和乘法層。具體來說,原始YOLO v3網絡RB輸出,經過全局池化層、全連接層、全連接層和Sigmoid激活函數層操作后,再與原始YOLO v3網絡RB輸出的結果相乘,得到改進后的殘差模塊輸出。圖3中,3個輸出通道y1、y2和y3的深度均為255,這是針對COCO數據集時的結果。改進殘差模塊的YOLO v3深度學習網絡中,針對每一個網格單元進行預測時都會得到3個矩形框,每個矩形框有左上角橫坐標、左上角縱坐標、寬度、高度和置信度等5個參數,同時由于COCO數據集有80種目標類型,因此,每個矩形框還必須包含這80種目標的概率,因此,輸出通道y1、y2和y3的深度為3×(5+80)=255。對于包含n種目標類型的任意數據集來說,輸出通道y1、y2和y3的深度dep可由式(1)來進行計算。

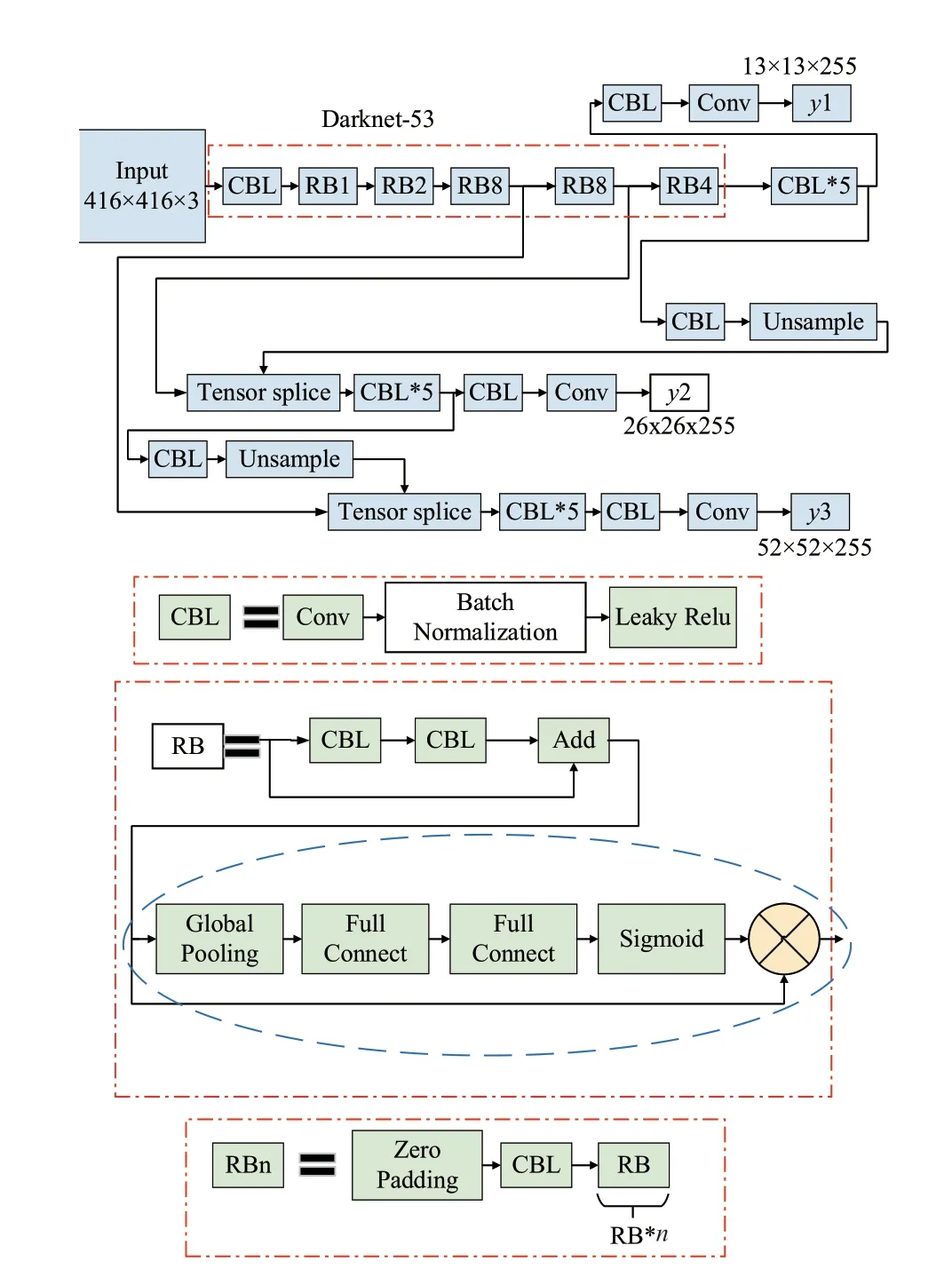
圖2 改進殘差模塊的YOLO v3網絡結構
與原始YOLO v3網絡相比,改進殘差模塊的YOLO v3網絡在深度上明顯更勝一籌,增加了(1+2+8+8+4)=23個全局池化層,增加了2 ×(1+2+8+8+4)=46個全連接層,增加了(1+2+8+8+4)=23個Sigmoid激活函數層,增加了(1+2+8+8+4)=23個乘法層,所有網絡層數等于255+23+46+23+23=370個。相比于原始YOLO v3網絡,網絡層數增加了(370-255)/255=45.1%,網絡層數量提升效果明顯。
改進殘差模塊的YOLO v3網絡層數量分布見表1。
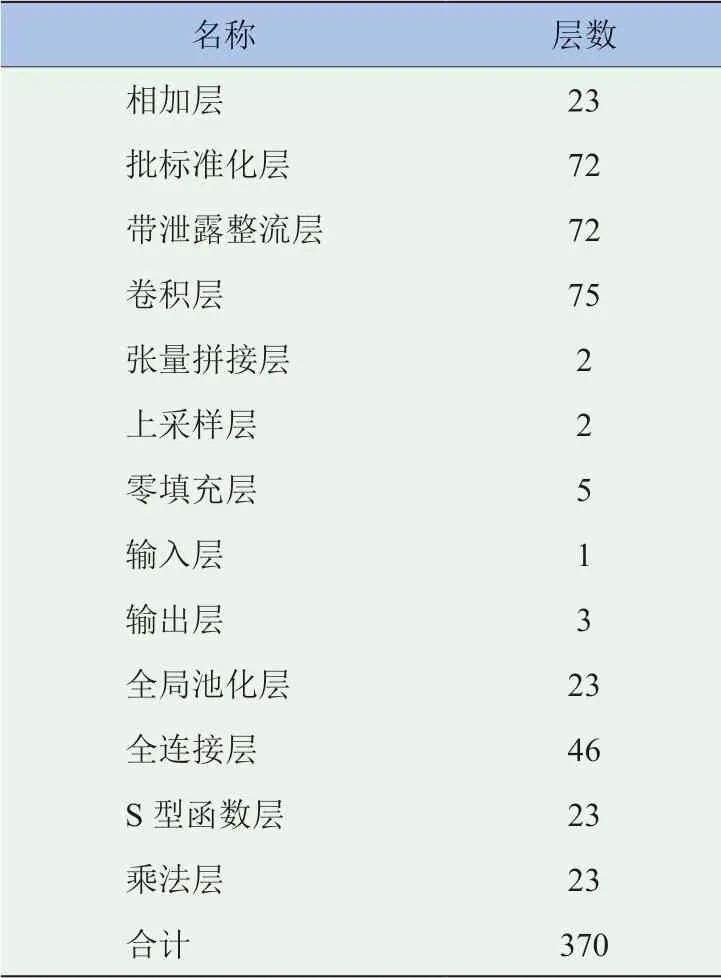
表1 改進殘差模塊的YOLO v3網絡層數量分布
2.2 空間尺度融合
假定激光雷達相對于世界坐標系的俯仰角為θL,激光雷達相對于世界坐標系的方向角為φL,激光雷達相對于世界坐標系的側傾角為ψL,激光雷達相對于世界坐標系原點的高度為hL,激光雷達相對于世界坐標系原點的橫向距離為dL,激光雷達相對于世界坐標系原點的縱向距離為lL。激光雷達坐標系和世界坐標系的位置關系如圖3所示。
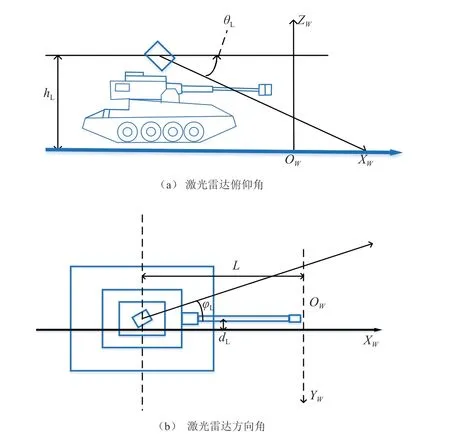
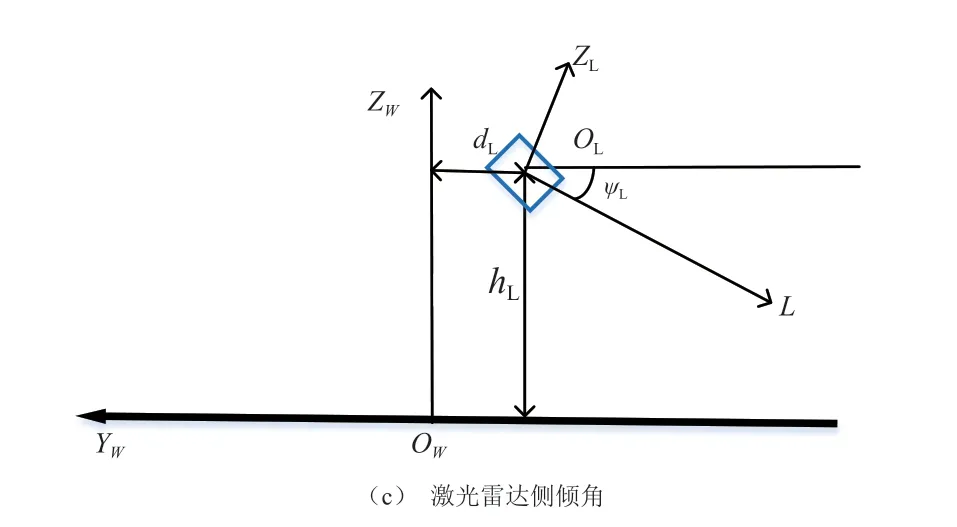
圖3 激光雷達和世界坐標系的位置關系
根據激光雷達坐標系和世界坐標系之間的旋轉和平移關系可得世界坐標系到激光雷達坐標系的映射關系,如式(2)所示。
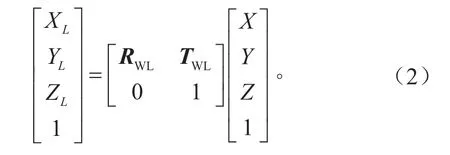
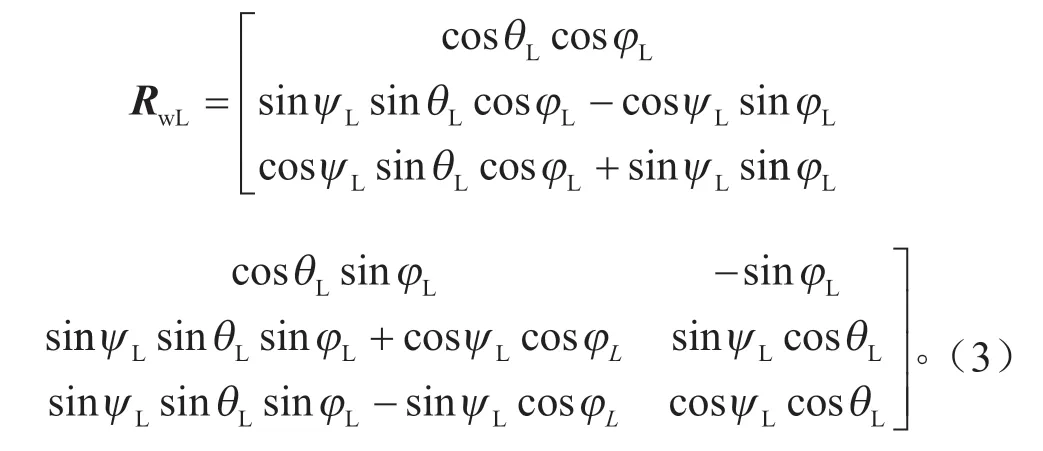
TwL的表達式為:

假定攝像機相對于世界坐標系的俯仰角為θ,攝像機相對于世界坐標系的方向角為φ,攝像機相對于世界坐標系的側傾角為ψ,攝像機相對于世界坐標系原點的高度為h,攝像機相對于世界坐標系原點的橫向距離為d,攝像機相對于世界坐標系原點的縱向距離為l。根據攝像機坐標系和世界坐標系之間的旋轉和平移關系以及像素坐標系與相機坐標系之間的映射關系,可得世界坐標系到像素坐標系的映射關系,如式(5)所示。

式中:Zc為三維坐標系壓縮至二維像素坐標系的變換因子;(u,v)為像素坐標系下的坐標;f為相機的焦距;dx為每個像素在圖像坐標系u坐標軸方向上的尺寸;dy為每個像素在圖像坐標系v坐標軸方向上的尺寸。世界坐標系到相機坐標系的旋轉矩陣Rwc的表達式為:
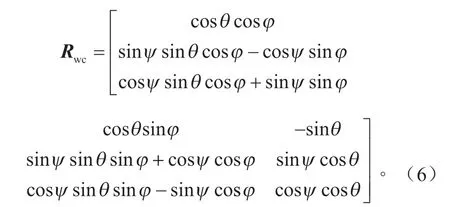
世界坐標系到相機坐標系的平移矩陣Twc的表達式為:
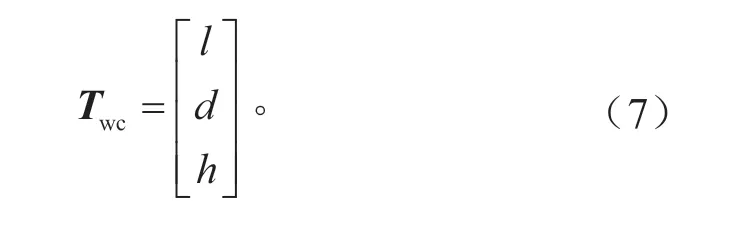
結合上文推導的世界坐標系到像素坐標系的映射關系以及世界坐標系到激光雷達坐標系的映射關系,可得激光雷達坐標系到像素坐標系的轉換關系,如式(8)所示。根據式(8),可以完成激光雷達和攝像頭在空間尺度上的融合。
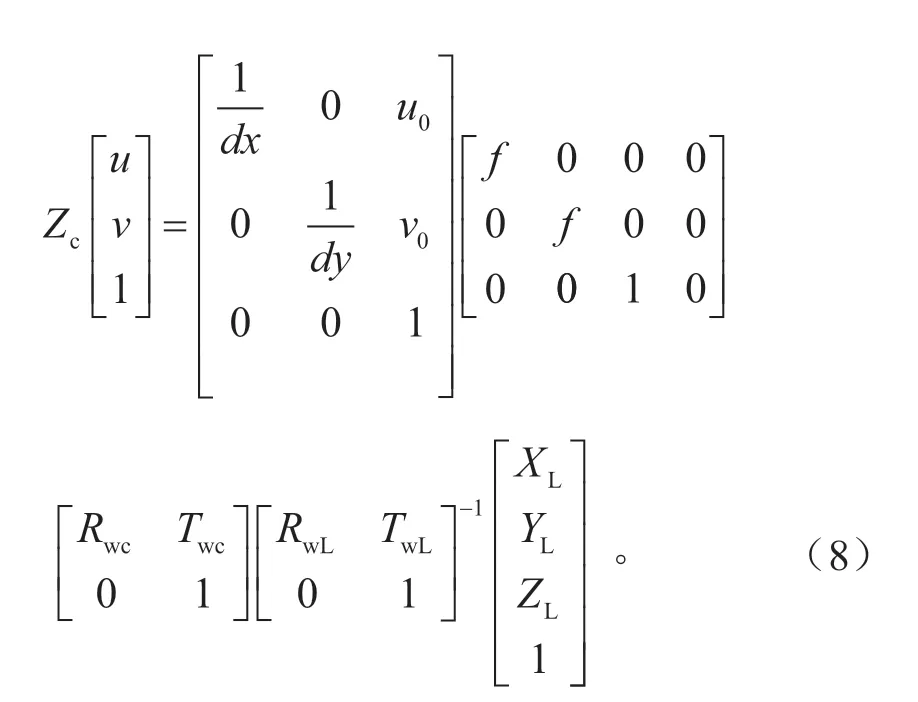
3 試驗驗證
為了驗證所設計的基于攝像頭圖像的深度學習網絡結構以及激光雷達和攝像頭融合算法在復雜環境下對于人員識別的效果,搭建了如圖4所示的履帶式車輛驗證平臺。

圖4 履帶式車輛驗證平臺
圖4中,攝像頭遵循標準UVC協議(USB Video Class Protocol),其技術參數見表2。
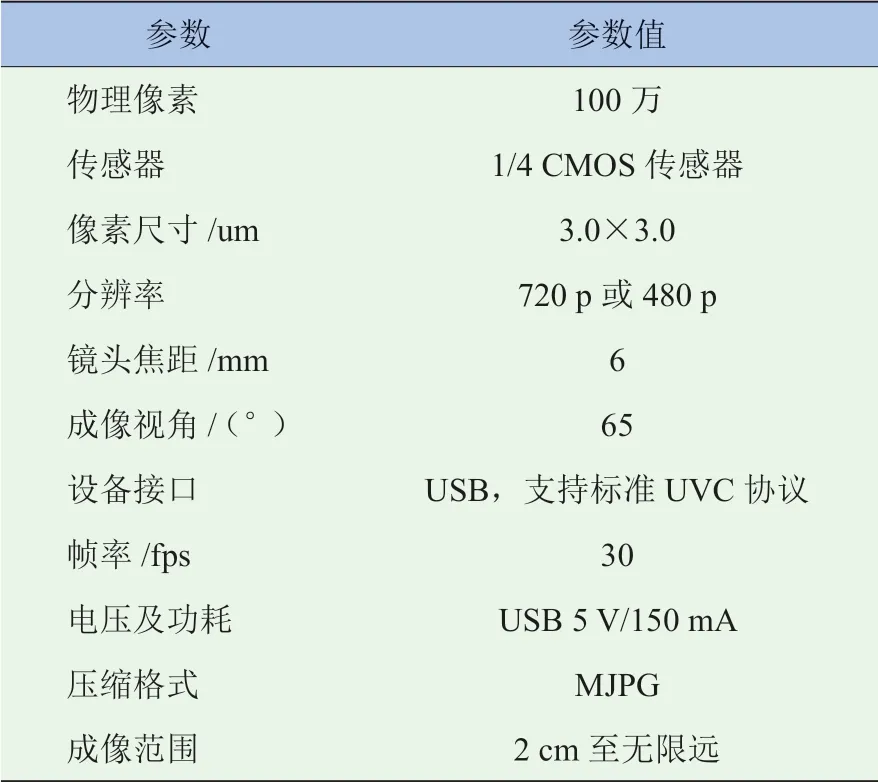
表2 攝像頭技術參數
試驗環境選擇為非結構化道路的復雜野外環境,該環境中包含有凹凸不平的草地、數目眾多且與人員高度相近的樹木、高壓線塔以及高度不等的建筑物等,將試驗工況劃分為單人工況和雙人工況。針對所設計的單人工況和雙人工況分別進行實車試驗,可以得到各種工況下傳感器融合的識別結果。
3.1 單人識別工況
單人工況融合識別結果如圖5所示。由圖5可知,攝像頭的圖像標注結果中,紅色矩形框除了標注了目標的類型為person,目標類型為person的概率為1.00,目標與試驗車輛前部的距離為10.3 m以外,還有一個LC的標簽。LC是LiDAR Confirmed的縮寫,代表紅色矩形框內的人員目標已經得到了激光雷達的確認,說明激光雷達和攝像頭的融合是有效果的。具體融合準則的運行和判斷是在后臺的終端中完成的,具體計算過程如下:
(1)激光雷達測量距離與攝像頭測量距離之間的誤差為:|9.88-10.3|/9.88=4.25%,在誤差容許范圍之內。(2)攝像頭給出目標為person的置信度為1.00,該置信度已經達到最大值,符合設計要求。(3)激光雷達三維點云數據中人員目標的高寬比計算值為1.21,攝像頭識別到的人員目標矩形框的高寬比為(384-154)/(319-237)=2.8,二者的計算值均在合理范圍之內,符合設計要求。(4)激光雷達識別到的人員點云映射到像素坐標系后,得到的矩形框與攝像頭識別到的人員矩形框交并比的計算值為95.4%,達到了95%以上,符合設計要求。

圖5 單人工況融合識別結果
3.2 雙人識別工況
雙人工況融合識別結果如圖6所示。由圖6可知,攝像頭的圖像識別結果中,紅色矩形框除了標注了兩個目標的類型均為person,兩個目標為person的概率均為1.00,左側人員目標與試驗車輛前部的距離為8.3 m,右側人員目標與試驗車輛前部的距離為8.5 m以外,在兩個人員目標上均有LC的標簽,代表兩個紅色矩形框內的人員目標都已經得到了激光雷達的確認,說明激光雷達和攝像頭的融合是有效果的。具體融合準則的運行和判斷是在后臺的終端中完成的,過程如下:
(1)激光雷達測量距離與攝像頭測量距離之間的誤差為:左側人員目標|7.89-8.3|/7.89=5.20%,右側人員目標|8.07-8.5|/8.07=5.33%,兩個誤差均在容許的范圍之內,符合設計要求。
(2)攝像頭給出兩個人員目標為person的置信度均為1.00,該置信度已經達到最大值,符合設計要求。
(3)激光雷達三維點云數據中左側人員目標的高寬比計算值為1.48,攝像頭識別到的左側人員目標矩形框的高寬比為(447-123)/(268-147)=2.68,二者的計算值均在合理范圍之內;激光雷達三維點云數據中右側人員目標的高寬比計算值為1.78,攝像頭識別到的右側人員目標矩形框的高寬比為(400-118)/(587-482)=2.69,二者的計算值均在合理范圍之內。總之,兩個人員目標在激光雷達和攝像頭下的高寬比均符合設計要求。
(4)激光雷達識別到的左側人員點云映射到像素坐標系后,得到的矩形框與攝像頭識別到的左側人員矩形框交并比的計算值為95.6%,激光雷達識別到的右側人員點云映射到像素坐標系后,得到的矩形框與攝像頭識別到的右側人員矩形框交并比的計算值為96.3%,均達到了95%以上,符合設計要求。
綜上所述,雙人工況下,激光雷達和攝像頭識別到的兩個人員目標均通過了所設計的空間融合準則,可以認定攝像頭和激光雷達識別到的左側人員是同一個人員目標,攝像頭和激光雷達識別到的右側人員是同一個人員目標。

圖6 雙人工況融合識別結果
3.3 單人跟隨識別工況
在上述野外環境中,跟隨單人行駛,車輛和引導員之間的距離控制在5~10 m,車輛行駛約50 m,平均行駛速度約4 km/h,得到跟隨工況識別的統計結果見表3。

表3 單人跟隨工況識別統計結果
在該工況下,人員沒有出現未識別情況,在統計結果中,攝像頭和激光雷達識別距離平均誤差為8.2%,高寬比平均誤差為5%,交并比的統計平均值為93.2%,該結果能夠滿足人員跟隨系統的設計要求。
4 結論
本文針對復雜環境下人員識別系統開發中所存在的一些難以解決的問題,首先建立了多傳感器融合體系架構,重點研究了基于圖像的深度學習人員識別方法以及激光雷達和視覺融合算法等方法,并在搭建履帶式越野車輛試驗平臺的基礎上,選擇合適的試驗環境并設計合理的試驗工況進行試驗驗證,驗證了所設計的算法在復雜環境下的有效性,并得到以下結論:
(1)設計的改進殘差模塊的YOLO v3深度學習網絡架構可以在越野環境中識別人員,對人員的識別效果達到了設計的要求。
(2)激光雷達和攝像頭融合算法實現了在空間尺度上的融合,融合效果達到了設計要求。
本研究僅融合了激光雷達與攝像頭,隨著車載傳感器數量的逐漸增加,后期有關多傳感器融合的研究會逐步擴展到毫米波雷達、紅外相機以及慣性導航系統等,試驗環境的復雜度以及試驗工況的種類也有待進一步擴展和加強,自適應閾值算法對于識別效果的提升也有待進一步驗證。
猜你喜歡
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
數學年刊A輯(中文版)(2022年4期)2022-02-16 08:17:34
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
無線電通信技術(2021年4期)2021-07-13 08:58:28
無線電通信技術(2021年3期)2021-06-08 03:33:48
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
福利中國(2015年4期)2015-01-03 08:03:38
