基于ShuffleNet的人臉圖像質量評估方法
2021-06-16 09:35:48李荔瞿洪桂孫家樂
電子技術與軟件工程 2021年7期
李荔 瞿洪桂 孫家樂
(1.國家信息中心軟件評測中心 北京市 100000 2.北京中電興發科技有限公司 北京市 100095)
人臉識別是公共安全物聯網應用最為廣泛的場景之一,識別效果的好壞取決于待識別人臉圖像質量的高低。即,低質量的人臉圖像會大大降低人臉識別的準確率。在連續視頻幀中,人臉圖像的質量會隨著光照、姿態、表情、運動等因素變化。如何使得圖像傳感器能夠正確評判連續視頻幀中人臉圖像質量的高低,成為很多學者研究的內容。針對姿態和非對稱光照對人臉的干擾,鄒[1]提出基于子區域直方圖距離的人臉對稱度評價,進而評估人臉質量的方法。黃[2]提出基于CNN 的人臉圖像亮度和清晰度的質量評價方法,利用人臉識別匹配器的相似性分數與人類視覺系統清晰度等級分類方法,結合傳統亮度分級方法,將人臉圖像分成9 類并建立相應的數據標簽,基于數據標簽和數據集訓練CNN 模型用于人臉質量評估。在眾多的研究中也有學者探索利用遷移學習基于輕型網絡去實現人臉圖像質量評估,如基于MobileNet 網絡進行遷移學習實現圖像質量分類評估[3]。物聯網信息系統中,數據采集過程中對圖像數據進行過濾,可大大減少網絡傳輸壓力,節省存儲資源。故而,在視頻采集器中實現可靠的人臉圖像質量評價尤為重要。本文致力于利用輕量型網絡ShuffleNet 實現人臉質量評價在視頻采集器中的應用。
1 常用的人臉圖像質量評估方法
由于光照強度、光照方向、目標距離、焦距、采樣率、曝光時間和增益、暗漏電流、分辨率等因素的影響,攝像機采集的圖片質量或高或低。此外,作為一般圖像的特例,人臉圖像質量還會受頭部姿態、面部表情、遮擋、妝容、飾物等因素的影響。
圖像質量評估(Image Quality Assessment, IQA)可分為主觀評估和客觀評估兩種方法。主觀評估就是從人的主觀感知來評價圖像的質量,首先給出原始參考圖像和失真圖像,讓標注者給失真圖像評分,一般采用平均主觀得分(Mean Opinion Score, MOS)或平均主觀得分差異(Differential Mean Opinion Score, DMOS)表示。主觀評估費時費力,且評分受觀看距離、顯示設備、照明條件、觀測者的視覺能力、情緒等諸多因素影響,可操作性差。客觀評估使用數學模型給出量化值,操作簡單,已經成為IQA 研究的重點。
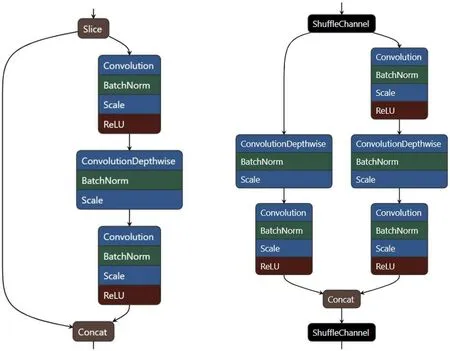
圖1:ShuffleNet 網絡結構的基本單元
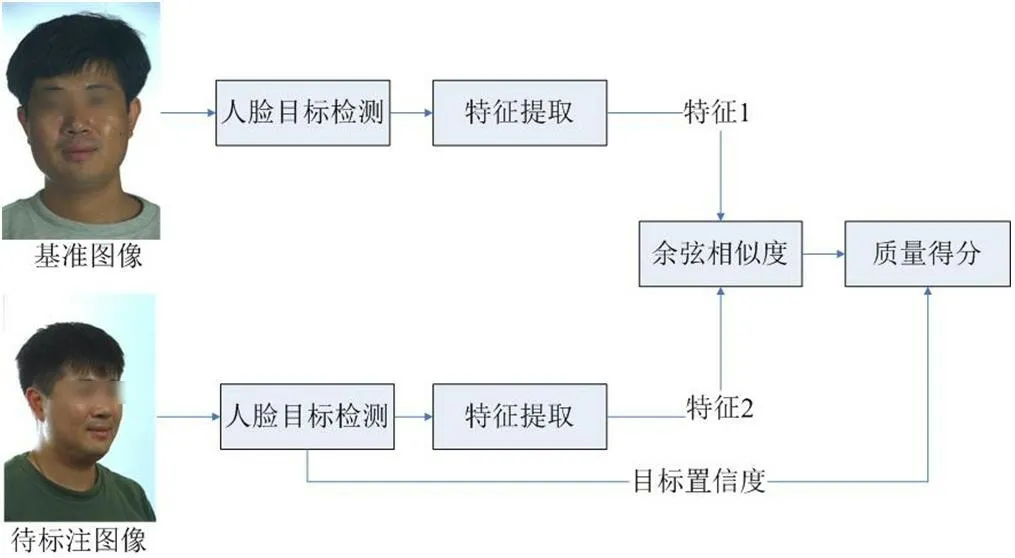
圖2:樣本標注流程圖

圖3:fa 子集圖像置信度

圖4:數據集中不同光照,姿態的人臉圖像標注結果樣例

圖5:數據增強后標注結果樣例
人臉圖像質量評估作為圖像質量評估的一個分支,既要考慮傳統圖像質量評估中關注的因素,又要考慮人臉特有的因素。2009年,國際標準化組織制定了關于人臉圖像質量的ISO/IEC 標準,對多種參數做出了規定[4]。基于該標準,出現了很多質量評估方法。有基于多因素的人臉圖像質量評估方法[5],該類方法對人臉圖像大小、位置、角度、對比度、明亮度、清晰度等分別進行評價,再對每個評價結果選擇合適的權重,進而得到整體質量得分。該類方法中,如何確定每個評價結果的權重是一個難題。不同方法中選擇的評價因素也不同[6],各種影響因素很難全面考慮到。有學者提出基于全局特征人臉特征聚類對人臉質量進行標注,并使用深度學習網絡對人臉圖像質量進行回歸的方法[7],也有學者提出基于特征聚類的分類方法[8]。這類方法考慮人臉圖像的全局質量,能兼顧不同因素對人臉圖片質量的影響。在評估測度上,除上述的分類輸出、回歸輸出,還有基于秩的評估方法[9]。
2 基于ShuffleNet的人臉圖像質量評估方法
在基于深度學習的人臉質量評估算法中,不同的網絡結構被提出以應用于人臉質量評估[10]。但是大多網絡結構復雜,性能有限。自ShuffleNet 提出以來,基于ShuffleNet 的網絡結構被廣泛的應用于人臉識別系統中[11-12]。
2.1 基于ShuffleNet的網絡結構
ShuffleNet 是曠視科技最近提出的一種計算高效的CNN 模型,ShuffleNet 的核心是采用了兩種操作:pointwise group convolution和channel shuffle,這兩種操作在保持精度的同時大大降低了模型的計算量。目前最優的網絡結構是ShuffleNetV2。本文基于ShuffleNetV2 實現人臉圖像質量分數的回歸。
ShuffleNetV2 網絡的基本結構是基于殘差網絡的殘差結構。如圖1 所示。
網絡采用3 個基本單元構成網絡結構主體,兩個全連接層FC1 輸出維度為200,FC2 輸出1 維質量分數,loss 層選用EuclideanLoss 對人臉圖像質量分數進行回歸。
2.2 樣本質量分數標注
基于人工進行人臉圖像質量標注, 不僅工作量巨大,還易受主觀因素影響。標注結果與人的視覺感受一致,但未必符合人臉識別系統的需要。本文使用基于人臉識別算法的樣本標注方法,為人臉識別算法量身定做質量評估方法。人臉檢測目標分類置信度體現了目標分類的正確概率,也是衡量人臉圖像質量的一個參考指標。本文采人臉檢測置信度對人臉圖像質量分數進行微調。首先選定一張人臉位置合適,光照合適,正臉,無遮擋等質量優的圖片作為基準圖像,圖片質量分數標注為1,其他人臉圖像通過人臉識別算法提取特征,計算圖像特征與基準圖像特征的余弦相似度作為圖像質量分數,再利用人臉檢測置信度對最終質量分數進行微調。

圖6:模型在監控場景中的應用效果
余弦相似度通過計算兩個向量的夾角的余弦值來度量它們之間的相似性。向量A,B 的余弦相似度similarity 的計算公式為:

similarity 取值為-1 到1:-1 意味著兩個向量指向的方向正好截然相反,1 表示它們的指向是完全相同的,0 通常表示它們之間是獨立的,而在這之間的值則表示中間的相似性或相異性。
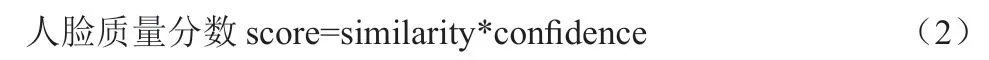
其中confidence 是人臉目標檢測的置信度。
樣本質量分數標注流程如圖2 所示。
3 實驗與分析
3.1 訓練樣本標注
本文使用Color FERET 和CAS_PEAL_R1 數據集進行實驗。Color FERET 數據集是由美國Feret 項目組收集的人臉數據庫,包含994 個類別共11338 張圖像,其中每個類別中的fa 子集是統一光照的正臉圖像,fb 子集是與fa 表情不同的統一光照正臉圖像,其它為包含15,22.5,45,67.5 頭部姿態水平旋轉的人臉圖像。CAS_PEAL_R1 是由中科院技術研究所收集的人臉數據庫,包含姿態變化,飾物變化,光照變化,背景變化,距離變化,時間跨度變化等7 種變化模式子庫。

表1:模型在數據集合上的表現
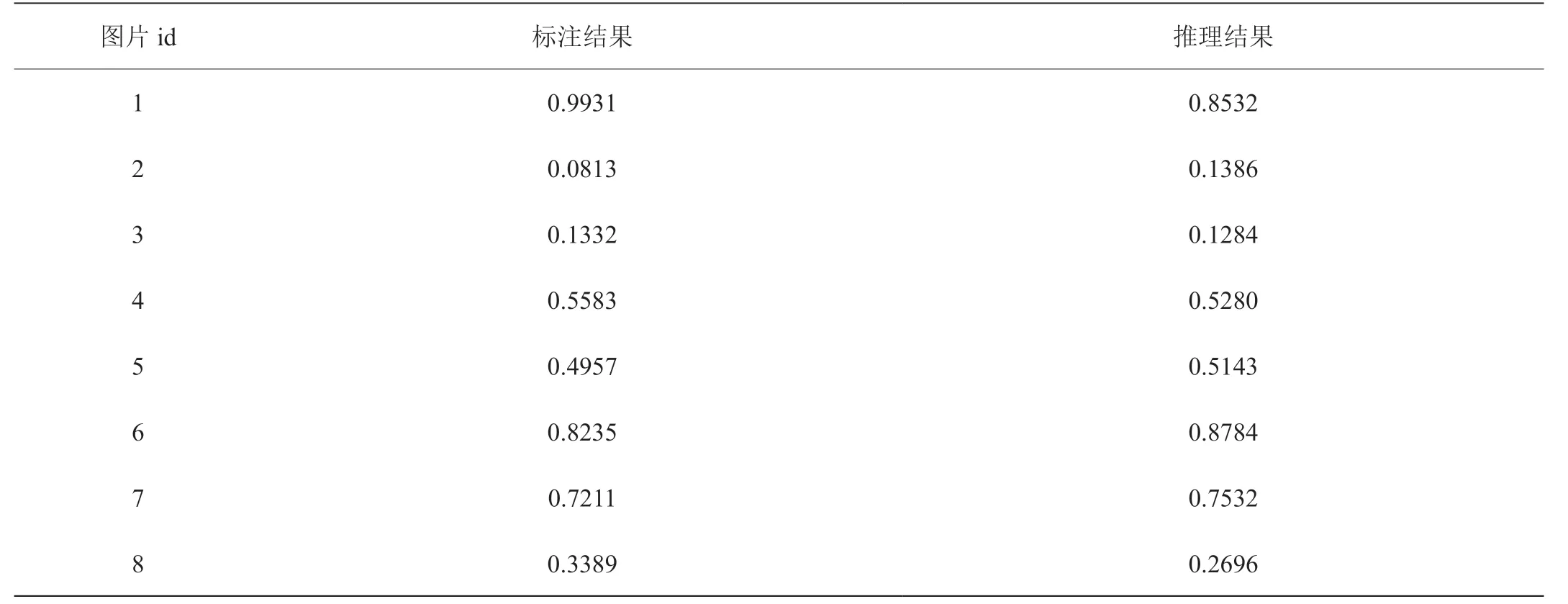
表2:測試集上模型標注結果和推理結果對比
基準圖片的選擇是訓練樣本標注的關鍵,Color FERET 數據集中fa 為正常表情,正常光照的人臉圖像,但部分目標fa 子集包含多張圖片,為了更好的選擇基準圖片,我們對每張人臉圖像進行人臉檢測得到人臉目標置信度,選擇fa 子集中人臉目標置信度最高的圖像作為該目標的基準圖像。如圖3 所示。
本文所述實驗使用了基于Resnet 網絡的SSH 人臉檢測算法和基于Mobilefacenet 網絡的Arcface 深度特征提取算法。標注結果樣例如圖4 所示。
3.2 數據增強
人臉圖像質量受多種因素的影響,但實驗所用數據集包含的情況遠遠不足,需要對樣本進行擴充,以增加樣本的多樣性。擴充方式包括:
(1)人臉檢測框水平和垂直方向偏移±2、±4、±8;
(2)圖像左右旋轉±10°、±20°、±30°;
(3)角度為45°的運動模糊;
(4)高斯模糊;
(5)人臉完整程度0.7、0.9、1.1 的裁剪。
在樣本擴充中考慮到實際的監控場景中,運動模糊是常見的一種影響因素[13],樣本中的圖像盡可能的貼近實際場景中可能出現的情況,能提高模型在實際應用中的效果。如圖5 所示。
3.3 模型訓練
將數據集分為訓練、驗證、測試三個數據集,圖像歸一化到112*112 與模型的輸入一致。選用ShufflenetV2_0.5x,初始學習率設置為0.01,學習率更新策略為poly,power 設置為0.9,momentum 設置為0.9,迭代了30000 次,大約3 個epoch,模型達到收斂。
3.4 結果展示及評價
訓練好的模型在劃分的測試集上進行評測,評測指標選用LCC (線性相關系數)和MSE(均方誤差),既評測標注質量分數與預測質量分數兩者的相關性又度量兩者的絕對差異。如表1 所示。
表2 列舉了測試集部分樣本標注質量分數和預測質量分數的差異,通過對比可以看到兩者差異較小,模型很好的實現了質量分數的回歸。
模型在實際監控場景中的效果圖如圖6 所示。
4 結論
本文提出了一種基于輕量級網絡ShuffleNet 人臉圖像質量評估方法。主要有兩點:
(1)基于ShuffleNetV2 網絡結構實現質量分數回歸網絡,對標準的ShuffleNetV2 網絡進行了剪裁,并使用ShufflenetV2_0.5x,減少了網絡推理階段的資源消耗,使網絡能夠部署在智能前端采集設備中,數據在前端被過濾,節省了物聯網平臺的網絡和存儲資源;
(2)提出了一種基于人臉目標檢測置信度與人臉特征提取算法相結合的人臉圖像質量樣本標注方法,減少了因人工標注樣本帶來的巨大工作量,提高了標注精度,這種標注方法兼顧不同因素對人臉圖像的影響,評價結果更全面,更貼合人臉識別系統最終的需求。
實驗證明,本文方法能夠針對不同因素引起的圖像質量變化給予準確的評估, 篩選出高質量的人臉圖像。
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
學生天地(2020年31期)2020-06-01 02:32:06
中國生殖健康(2019年2期)2019-08-23 08:12:08
Coco薇(2016年2期)2016-03-22 02:42:52
汽車觀察(2016年3期)2016-02-28 13:16:26
Coco薇(2015年1期)2015-08-13 02:47:34
計算機工程(2015年8期)2015-07-03 12:19:07
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
