
為什么這么強?深度觀察蘋果M1 SOC
2021-06-20 01:26:13張平
微型計算機 2021年5期
關鍵詞:設計
張平

蘋果在2020年作出的最重要舉動就是推出了搭載自研M1芯片的全新系列筆記本電腦。相比英特爾的產品,蘋果宣稱這款名為M1的芯片擁有更為出色的效能和更低的電力消耗。隨后的實測結果顯示,蘋果M1的確展示出了卓越的性能,甚至一度超越了英特爾的旗艦產品。那么,蘋果是如何做到這一點的?這款SoC的設計有何獨特之處呢?
蘋果是全球移動產業最強大的企業之一,這一點也反映在蘋果旗下的產品上。雖然在每次發布會上,蘋果都很少從技術層面介紹自家的SoC產品,但是其強悍的性能、極高的性能功耗比往往會在實際產品上市后給用戶和業界帶來震驚,甚至部分性能超過了相近時間發布的其他廠商的SoC的生能的數代之多。
在M1發布后,各大媒體迅速對這款產品進行了測試,測試數據表明,M1的CPU性能在包括CineBenchR23、GeekBench 5、GFXBench等多種、多類型的測試中都取得了卓越的成績。在CineBench R23的單線程性能、GeekBench 5的單線程性能測試中,M1的CPU性能甚至可以和全新的Zen 3架構的銳龍9 5950X以及英特爾第11代酷睿系列處理器打得有來有回,甚至部分性能還能有所超越。
那么,一個值得探討的問題就出現了。蘋果的M1的CPU性能為什么這么出色?它真的超越了目前的桌面頂級產品嗎?對于這一些問題,本文嘗試通過一些探討和數據來予以解釋。需要提前說明的是,由于蘋果在產品細節和技術細節上的缺失,本文的部分內容屬于探討性質,可能和實際情況存在差異,建議大家參考閱讀。
蘋果M1:一顆復雜的SoC產品
首先需要明確的一點是,蘋果M1芯片并不是一個單一的CPU或者GPU,它是一個包含了包含了CPU、GPU、ISP、NPU、DSP、緩存等諸多單元模塊的SoC產品。它采用的是臺積電的5nm工藝,包含了大約160億個晶體管。
在相關組成部分方面,M1包含了4個Firestrom高性能CPU核心和4個Icestrom低功耗CPU核心,以及一個規模較大的、擁有8個核心的GPU(包含了1024個EU單元),此外還有擁有16核心的NPU單元、所有核心共享的系統級別緩存。內存方面支持雙通道64bit LPDDR4X 2133內存,還擁有包括PCle總線控制器和雷電4接口控制器這樣的外部鏈接單元模塊等。
從M1的設計和規模來看,蘋果的目的是要在一個芯片上達成幾乎所有的功能,同時實現性能和功耗的平衡。作為面向性能市場的產品,M1這樣的做法在之前其他廠商那里完全沒有出現。因此,必須很深入地了解蘋果在M1的CPU部分做了什么又做對了什么,才能理解為什么M1的CPU部分為何擁有如此出色的性能表現。但是令人遺憾的是,蘋果現在公布的資料遠遠不足,我們依舊只能通過第三方手段和報道才能管中窺豹了解M1這顆堪稱劃時代產品的一角。
多就是好:Firestrom核心晶體數量巨大
蘋果一直以來幾乎不發布任何有關產品的內部細節設計,尤其是芯片類產品。因此,這部分的分析將從第三方資料入手。可能和實際情況存在差異。
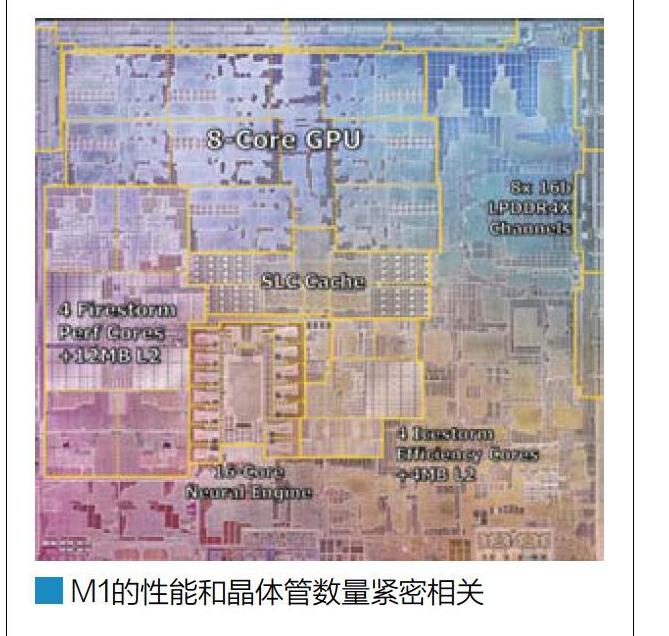
從現在第三方媒體公布的M1的晶圓照片來看,其中最大部分的面積是GPU,大概占據了整個M1 lg%的面積。接下來則是4個FireStrom大核心和12MB L2緩存,大約占據了13%的芯片面積。
考慮到整個M1 SoC擁有160億晶體管,并假設整個SoC上晶體管密度是均勻分布的。那么,M1的GPU部分大約有30億晶體管,與此類似的是,M1 SoC的4個高性能CPU搭配12MB L2緩存則占據了20億晶體管。
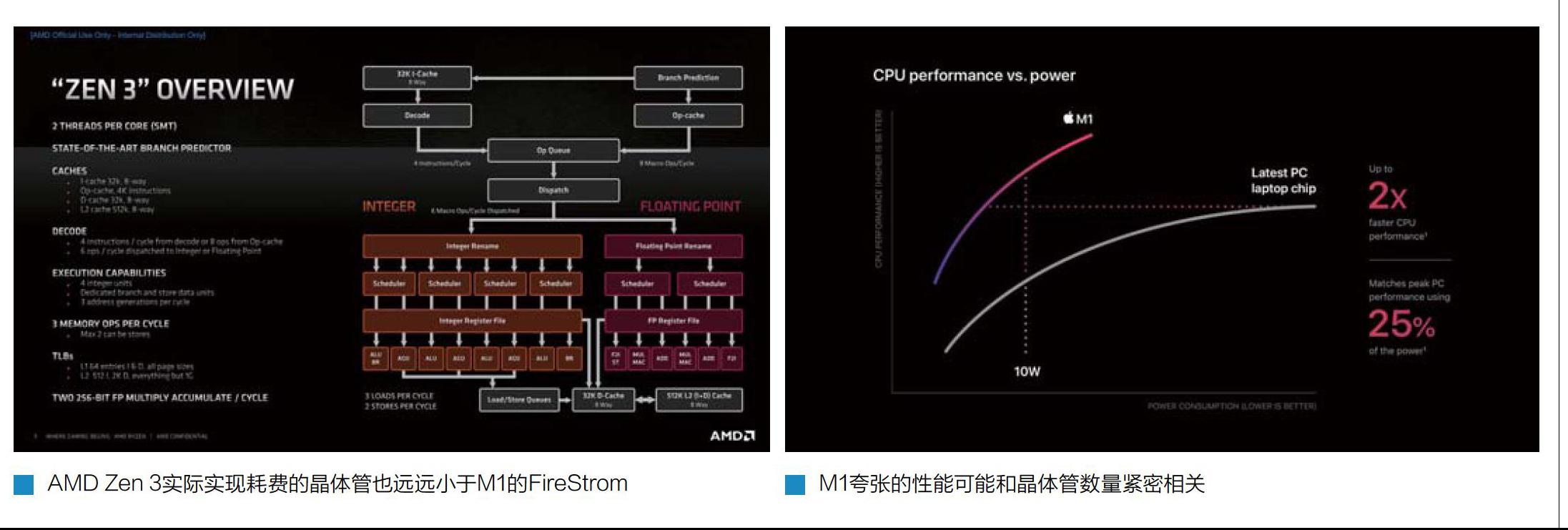
在晶體管數量明確后,我們可以用于對比目前比較主流的處理器了。比如AMD之前公布過Zen 3架構的每個CCD的晶體管數量為41.5億,擁有8個核心和總計約36MB緩存( 12+13)。如果這個數據減半的話,比如4個核心搭配18MB緩存,那么大約占據20.5億晶體管。相比M1 CPU部分的數據,AMD Zen 3在緩存多了6MB的情況下,晶體管數量基本持平,這也意味著蘋果的M1的FireStrom大核心的每一個核心所使用的晶體管數量是顯著大于AMD Zen3的,也就是說M1的CPU架構要比Zen3更為龐大。
從臺積電公開的一些數據來看,臺積電的7nm工藝每平方毫米大約可以容納0.9億個晶體管。對蘋果而言,根據同為5nm工藝的A14芯片的最終效果,臺積電的5nm工藝密度相比7nm提升了49%,為每平方毫米1.34億,每平方毫米約1.34億晶體管。考慮到1MB SRAM在6T的情況下擁有約5000萬個晶體管,但往往SRAM在實際使用中可能會使用8T或者10T的版本,因此綜合來看,1MBSRAM以0.7億晶體管計算,那么可以估計出7nm工藝下1MB SRAM的面積約為0.8平方毫米,5nm工藝下為約為0.5平方毫米。
有了上文的數據,本文再度假設這些數據和AMD、蘋果最終產品呈現出來的實際數據是基本相當的。
這樣一來,Zen 3每個核心除去L2+L3緩存的話,大約擁有(41.5-36x0.7) /8=約2億晶體管,占據核心面積是2.2平方毫米。蘋果的M1的高性能核心每個核心則擁有( 20-12x0.7) /4=2.9億晶體管,每個占據核心面積為2.16平方毫米。在這種粗略的計算下,蘋果的高性能核心每個核心的晶體管數量比AMD的Zen3多出了接近1億。也就是說,蘋果M1 Firestrom核心的晶體管用量,是AMD Zen 3晶體管用量的大約1.5倍左右。當然,這個數據是估計值,極有可能和實際情況差別很大,但無論怎樣,蘋果M1使用的Firestrom核心史無前例地大,那是肯定跑不掉的。
這樣的結果就很有意思了。因為對現代CPU設計來說,其基本的設計理念和道路都是非常明確的,在當前物理條件下,AMD、蘋果乃至英特爾、ARM等廠商在CPU在設計中獲取最大化的性能或者性能功耗比的手段是基本是一樣的,因此很難或者基本不存在某個廠商擁有突破級別的技術。之所以市場上存在各種獨特的CPU產品,那是因為其面向的對象、競爭優勢的區間以及成本衡量存在巨大差異。當然,部分廠商依舊擁有自己獨特的優勢,比如英特爾在分支預測方面一直獨步業界,但是綜合來看,如果約束條件相當的話,這些廠商設計出來的處理器綜合性能應該是基本相同的。唯一能有所突破的地方就是使用更多的晶體管構建更大規模的架構。顯而易見的是,蘋果之前在這樣做,現在也持續在這樣做。
僅僅從晶體管數量來看的話,蘋果M1的Firestrom核心強悍不是沒有理由的,肆無忌憚堆資源,不強悍也難。那么,蘋果將這些晶體管資源用在了哪里呢?
大就是好:來自蘋果8寬度CPU構架
蘋果在CPU架構設計方面擁有接近十年的歷史。蘋果首個定制化的SoC是2012年發布的A6,隨后的每一年,蘋果都會推出一個全新的CPU微架構。早在2013年,蘋果便推出了一個名為Cyclone的微架構并宣稱其為“桌面級別”微架構,這也是業界史上首個在移動設備上實現64bit計算的CPU架構,ARM和安卓世界要在一年以后才能趕上蘋果的步伐。最新的蘋果處理器是2020年發布的iPhone 12系列手機的A14 SoC中使用的名為Firestrom的大核心架構,和M1芯片中使用的Firestrom架構基本一致。
還是那個原因,蘋果不發布所有有關處理器架構的信息,因此外界一般無從得知蘋果對CPU微架構都干了些什么。好在作為業內老牌技術網站的anandtech通過深入測試和合理推測,給出了有關Firestrom核心架構的簡圖。
根據anandtech的資料顯示,蘋果Firestrom核心是一個8寬度的超寬、超標量、亂序的核心。相比之下,X86處理器比如AMD Zen 3依1日只有4寬度,英特爾的產品也只有4+1寬度設計,和其他ARM處理器相比的話,ARM出品的最新Cortex-X1擁有5寬度,其余都采用4寬度,三星M3雖然是6寬度,但是實際表現并不出色。
在亂序執行能力方面,通過測試可以看出,蘋果的ROB單元能夠允許的指令排序容量大約是630條目左右,雖然并不是很確定蘋果在這部分是否采用了和其他處理器類似的設計,否則如此巨大的容量,顯示蘋果Firestrom擁有龐大的亂序執行排序能力和調度能力,當然這也對應著后端龐大的執行單元部分。作為對比的是,英特爾的Sunny Cove和Willow Cove的ROB容量僅僅352,這已經是目前除了Firestrom外我們知道的處理器中最大的了,AMD的Zen3僅為256條目,ARM的Cortex-X1僅為224條目。
在后端來看的話,整數執行部分,有關重命名寄存器的容量估計為354條目,這也是非常巨大的容量,此外還擁有至少7個執行端口用于計算相應的算術計算,包括4個具有ADD執行能力的ALU,2個可以執行MUL的復雜計算單元和可能存在的專用整數除法單元。
在浮點和矢量部分,Firestrom帶來了全新的第四條執行管道,進一步提升了浮點計算的理論性能。浮點重命名寄存器容量約為384條目,還包含4個128b.t的NEON浮點流水線。此外,Firestrom每周期還可以執行4個FADD和4個FMUL,延遲分別是3個和4個周期。這樣龐大的浮點計算規模是AMD Zen 3的2倍、是英特爾和AMD之前架構每周期吞吐量的大約4倍。
在加載存儲方面,目前的測試顯示Firestrom可能會有4個執行端口,1個加載存儲單元、1個專用存儲單元和2個專用家在單元。每個周期可以執行3個負載任務,每個周期最多可以執行2個存儲,但是最多只能同時執行2個負載和2個存儲。
在TLB方面,L1的TLB從1 28頁增加了一倍至256頁,L2 TLB從2048頁增加到了3072頁。由于每個TLB頁面大小為16KB,因此3072的TLB可以覆蓋48MB的緩存,這實際上是超過了現在的M1 SoC或者之前的A14的緩存容量的。因此這部分的設計具體如何實現還有待進一步探查。
最后來看緩存體系結構。之前A13的設計的有關推測中,蘋果就設計了高達128KB的L1指令緩存和128KB L1數據緩存,從處理器設計角度來看這是極為不可思議的,因為一般處理器的L1緩存不會超過32KB(新的Sunny Cove是48KB),甚至部分處理器只使用16KB。當然,更大的緩存能顯著幫助處理器內核快速獲取指令,不過成本代價和晶體管數量代價非常高昂。在新的Firestrom上,可能這個容量已經進一步提升至192KB,這可以解釋為什么蘋果的處理器在高指令壓力工作負載中表現出色。
在高速緩存的速度方面,Firestrom的L1數據緩存可以以3個周期的延遲載入,對于如此巨大的緩存架構而言這是非常難得的數據。相比之下,英特爾Sunny Cove只是增加至48KB,就需要5個周期載入,AMD 32KB的L1緩存則需要4個周期,相比蘋果的設計還是存在一定的差異。L2方面,蘋果一直以來都直接選擇一個容量較大且快速的L2緩存設計,比如2個內核共享8MB緩存。在早前的A14芯片上,L2的延遲為16個周期。
另外值得注意的是,蘋果在M1設計中還設計了一個SLC緩存,這個緩存位于整個芯片的中央部位,考慮到M1的內存帶寬較小,因此這個SLC緩存可能是用于暫存部分數據信息,充當整個M1芯片的緩存使用。不過蘋果沒有公布SLC的使用方法和容量,一些測試顯示,SLC的緩存容量可能為32MB,延遲可能為40ns,這個數據如果屬實的話,那么M1 SoC在緩存設計上應該還有更多的信息可供挖掘。
最后則是Firestrom架構的有關時鐘頻率方面的內容。對Firestrom這種比較寬大的體系架構來說,一般認為其頻率難以達到比較高的水平。不過在蘋果的A14上,Firestrom的頻率可以達到最高3GHz,2個Firestrom核心啟用的時候頻率會降低至2.89GHz。在M1處理器商,Firestrom能達到的最高頻率為3.2GHz,也沒有太大的提升。
總的來看,蘋果在A14和M1處理器上實現了一個寬度高達8,并且緩存、執行資源非常充裕的超大核心,這也是前文提及的Firestrom核心可能單核心的晶體管數量就要比包括Zen 3、Sunny Cove、Zen 2等架構高出許多的原因。從蘋果在架構方面的努力來看,蘋果致力于“頻率不夠、規模來湊”,并且較低的頻率能夠帶來較低的功耗和極高的性能功耗比。這也是蘋果一貫以來的操作策略了。
蘋果在M1的Firestrom設計中采用了高達8解碼的前端,那么為什么X86處理器難以做到這一點呢?實際上,這里很可能是由于CISC指令集天生的痼疾導致這個問題的出現,現在難以解決。
對Firestrom架構來說,采用的是RISC精簡指令集,所有的指令都是等長的,因此可以將整個指令序列按照一定的等長規則進行分割再交由解碼器解碼,就可以實現同時并發多個指令。不過這一點對CISC復雜指令集來說卻很困難,X86使用的CISC指令集是不等長的,在前一個指令沒有讀完之前不知道后部的指令頭位置在哪里,難以并行解碼。當然,現代X86 CPU往往通過各種手段繞開CSIC指令集的不等長缺陷,比如通過經驗來猜測指令的結尾,或者對指令可能存在的起點都進行一次解碼并拋棄完全錯誤的部分。由于CSIC不等長指令集的問題,X86目前可以做到4個解碼器或者4+1解碼器已經是極限了。不僅如此,這種不等長的復雜指令還影響到了CPU亂序執行和的部分,因為不等長和不可預測性,亂序執行變得很困難。鑒于此,在現代X86 CPU的內部,所有的CSIC指令集都會被翻譯為成為uOP也就是“微指令”或者“微碼”( Micro Operations),通過規整的微碼來統-CPU內部的流程。也正是由于uOP的出現,X86處理器才有可能在效率和性能上趕上RISC架構。
當然,CISC也不是沒有優點,那就是一個指令可以執行更多的操作,整體效率相對較高,占用內存較少。RISC需要多條指令完成的任務,CSIC可能只用一條指令就可以實現,這也是CSIC相對RISC的優勢所在。
統一內存架構的實現:蘋果的全新創舉
上文我們提到了蘋果在CPU設計上的一些獨特之處。在這一部分,我們將從更為宏觀的角度來審視蘋果M1處理器的設計。
正如前文所說,蘋果M1處理器內部包含了大量的不同單元,除了CPU、GPU、NPU等外,還有最重要的,就是統一內存架構。
在M1處理器中,CPU、GPU、NPU和所有的單元都使用了一個統一的、和芯片緊密靠近的統一內存架構。這個架構的好處在于,CPU和GPU之間可以互相訪問數據,這樣可以大大降低數據搬運和復制的時間,也能夠縮減各個不同的處理模塊之間等待數據準備的時間。M1在硬件和軟件上首次統一,完成了迄今為止首個真正進入商業化和民用市場的統一內存架構。
對傳統PC而言,CPU的數據存放在內存中,GPU的數據存放在本地存儲(顯存)中。當GPU需要做什么事情的時候,或者說CPU需要讓GPU去做什么事情的時候,數據會從內存中經過總線拷貝至GPU的顯存中,這個拷貝的過程帶來了比較明顯的延遲和功耗的提升。反過來,GPU在計算完成后,需要將數據放置在CPU的內存中,再告訴CPU數據的位置,這個過程也存在延遲和功耗提升。不過,現在存在一些技術可以讓CPU讀取GPU顯存中的數據,或者反過來GPU也可以訪問CPU的數據,但受制于兼容性和各個廠商之間的協調以及操作系統、軟件適配、軟件生態等原因,這樣的技術并不成熟。
在M1上,由于CPU、GPU、NPU等等計算核心包括操作系統、軟件等都來自蘋果公司自己,因此這樣的問題可以在一個體系下進行協調,最終我們看到的是一個完整的、基于統一內存架構的SoC-M1。整個M1內部所有的硬件模塊都擁有統一的內存地址,數據不再需要額外轉移,這在很大程度上提升了整個系統的效率。
另外,在內存的部署中,M1芯片采用的是目前移動SoC慣用的“Package-on-Package”的方法,也就是讓內存芯片盡可能靠近應用處理器,讓他們之間的距離盡可能縮小。這樣的優勢在于,—方面盡可能地降低了內存傳輸的能耗,另一方面可以降低內存傳輸的延遲。M1的內存理論帶寬為68.2GB/s,從這個數據來看,和目前桌面主流的比如AMD Zen 2、英特爾十代酷睿,是顯著更低的,比如AMD Zen 2的內存帶寬可達100G B/s以上。但是,考慮到蘋果在統一內存架構、內存POP封裝上以及本身處理器內部超大緩存的設計等,因此整體性能表現還是非常出色的。
異構計算的上馬:專業的人做專業的事情
作為一個擁有1 60億晶體管的龐大SoC,M1內部包含的各個功能模塊是非常多而且復雜的。除了前文深入分析的CPU外,還包括進行3D圖像計算的GPU、進行神經網絡計算的NPU、視頻編解碼器、音頻處理單元、HDR視頻處理單元、HDR圖像處理單元、常開處理器、矩陣協處理器等。在M1的設計中,蘋果貫徹了能用專業單元就不用通用單元的思想,“讓專業的人做專業的事情”,這會讓性能表現更加高效。
在蘋果對M1相關產品的宣傳中,有針對M1在視頻處理計算上優勢的專門介紹。實際上,由于蘋果在M1內部專門設置了HDR視頻處理單元和視頻編解碼單元,在經過操作系統和專業軟件的調用后,就能夠地輕松發揮出這些專用單元的效能,從而獲得極為優秀的性能表現。另外值得一提的是蘋果的矩陣協處理器,它可以用于執行一些常規代碼加速而不是專門調用GPU或者NPU。換句話說,蘋果通過這樣的設置,帶來了非常出色的性能功耗比表現。
對M1采用大量專用單元進行針對性加速的方法,業內往往以異構計算對其進行歸類和稱呼。一般來說,異構計算是指擁有多種不同類型計算能力和優勢的模塊在統一調度下進行計算的方式。對于M1來說,蘋果的軟件和M1的硬件,以及其他相關軟件配合,實現了迄今為止業內面向消費者最為出色的異構計算架構。
不過,雖然M1在異構計算上做得非常出色,但是異構計算還存在一個致命的問題,那就是由于硬件固定了計算路徑,未來如果算法和應用升級的話,那么相關的異構計算單元可能就無法發揮作用。考慮到蘋果同時控制了操作系統和軟件開發環境,這樣的問題可能短時間內不會出現,但依舊需要進一步觀察。
開辟一條全新的道路?
到這里,本文對M1處理器的分析就基本告一段落了。從蘋果在M1處理器中的設計來看,依托于5nm的強大優勢,蘋果通過集成高達160億個晶體管資源,超大規模的CPU核心、大量專用的模塊以及緩存設計,在較低的功耗下取得了相對于現有高端X86處理器部分相當的性能,甚至在部分測試中還有所超出,這是非常了不起的成績,凸顯了蘋果強大的軟硬件技術實力。
從M1以及蘋果在軟件、系統上的努力可以看出,似乎蘋果正在開辟一條全新的道路來挑戰X86在個人電腦中的領導地位。之前RISC陣營也曾經挑戰過X86在PC上的領導地位,但是顯然失敗了。蘋果則借由移動計算開始,現在通過統一移動和桌面端的架構,模糊移動設備和個人電腦之間的界限,并借由M1這樣性能卓越、功能強勁的產品來吸引消費者關注,這不得不說是一招秒棋。從技術角度來看,M1充分發揮了RISC CPU架構的優勢,再加上蘋果不惜工本地投入大量晶體管資源、統一內存架構、異構計算、定制各種不同功能的計算單元以及全新的操作系統、軟件生態,都給人帶來了耳目一新的感覺。接下來,蘋果要怎么走呢?是推出更強大的M2、M3以及更加緊密的生態系統?還是進一步統一移動端和桌面端呢?這都讓人相當期待。
猜你喜歡
河北畫報(2020年8期)2020-10-27 02:54:06
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
電子制作(2019年19期)2019-11-23 08:41:36
電子制作(2019年15期)2019-08-27 01:11:50
電子制作(2019年7期)2019-04-25 13:18:16
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
商周刊(2017年26期)2017-04-25 08:13:04
