基于一維卷積神經網絡的恒星光譜分類研究
2021-06-24 09:07:32艾霖嬪楊錦濤徐權峰張靜敏杜利婷周衛紅
云南民族大學學報(自然科學版) 2021年3期
艾霖嬪,楊錦濤,徐權峰,張靜敏,杜利婷,周衛紅,2
(1.云南民族大學 數學與計算機科學學院,云南 昆明 650500; 2.中國科學院 天體結構與演化重點實驗室,云南 昆明 650011)
研究天體光譜能發現許多對天文研究有重要的意義的信息,其中天體光譜的分類研究是天體光譜研究的重要一環.但目前仍有大量的天體沒有經過光譜觀測,郭守敬望遠鏡(LAMOST)有著極高的光譜獲取率,為我國天文學研究做出了重大貢獻.如今LAMOST光譜發布已進入千萬量級時代,創下多項世界之最.
對于天體光譜的分類研究學者們進行了許多的嘗試.覃冬梅等[1]利用主分量分析法來研究恒星光譜的分類,該方法的實驗結果跟基南系統的恒星分類標準相差無幾,表明了該方法的有效性;張華煜[2]提出的分類模型是基于支持向量機的層次型聚類多類分類器,該模型可以有效提高分類速度;康超[3]針對M矮星的分類研究,提出殘差分布度量的方法,證實了該方法對天體光譜進行分類的可行性;趙旭俊等[4]提出利用分類模式樹提取恒星光譜中屬性的出現頻率,挖掘分類的規則,表明了該方法對恒星光譜分類有較高的準確率;劉忠寶等[5]為了解決數據樣本很大時,支持向量機計算量大速度慢等問題,提出流形模糊雙支持向量機應用于SDSS的恒星光譜數據集,該方法不僅大幅度減少了計算的時間,同時還能有效降低噪聲點以及奇異點的影響,提高分類精度.
隨著LAMOST、SDSS等巡天項目的開展,光譜數據量呈爆炸式的增長,我們必須尋求快速、高效、精確的分類方法來對天體光譜進行分類.由于深度學習在圖像識別領域取得了非凡的成就,學者們也開始將深度學習應用到天體光譜分類領域.石超君等[6]提出基于卷積神經網絡對K型和F型恒星光譜進行分類,結果表明卷積神經網絡能對K型和F型恒星光譜快速的分類篩選,訓練的數據量與模型泛化能力,分類準確率成正比;張靜敏等[7]提出基于深度信念網絡的LAMOST恒星光譜分類研究方法,驗證了該模型對F、G、K這3種恒星光譜分類的有效性;王奇勛等[8]針對LAMOST光譜數據優化了DenseNet網絡,對恒星、星系和類星體3類天體光譜進行分類,該優化后的模型具有可解釋性強、魯棒性強、泛化能力強等優點, 可用于天體光譜的分類研究;許婷婷等[9]利用DBN模型對光譜數據特征的分層學習具有數據降維的特點,基于深度學習訓練了一個深度信念網絡對F、G和K 3種恒星光譜進行分類,沒有對天體光譜進行降維處理,直接訓練DBN模型,最終準確率為0.9303.張靜敏等[10]又提出1種基于2維傅里葉譜圖像的特征提取方法,采用短時傅里葉變換將1維光譜數據變換成2維傅里葉譜圖像,再利用深度卷積網絡模型對得到的2維傅里葉譜圖像進行分類,最終的分類準確率是0.929 0.
1 恒星光譜數據
恒星光譜分類方法有西奇分類、哈佛系統、威爾遜山系統、基南系統等,其中基南系統對于恒星光譜的分類得到了廣泛的應用.它按照恒星的表面溫度從高到低對恒星光譜進行分類,仍然使用哈佛系統對光譜分類的標示,將恒星的光譜分成O、B、A、F、G、K、M 7大類.目前國際上的巡天項目有LAMOST、斯隆數字巡天(Sloan Digital Sky Survey,縮寫為SDSS)等,而LAMOST獲取到的光譜是所有天文望遠鏡中最多的,歷經5年,在LAMOST全體工作人員的共同努力下,LAMOST一期光譜巡天任務圓滿完成,LAMOST DR5數據集也于2017年12月31日正式發布,共發布了901萬條光譜,信噪比大于10,其中高質量光譜數達到了777萬條.
在LAMOST中,天體光譜存儲形式為FITS格式,其包含許多恒星的屬性特征信息,而這些信息在某一具體問題中不一定都能用,因而在恒星光譜分類中選取其中的一個數字矩陣中的流量與波長構成光譜圖,橫坐標為波長,縱坐標為流量.不同類別的恒星光譜,其流量、形狀、峰寬有一定的差異,即使同一波長處的流量也相差很多,不同的恒星光譜波長不同時流量也不同.根據這些特性,我們可以判斷出恒星光譜的類型.由于不同類型的恒星光譜在不同的波長處具有各自的發射線與吸收線,從而不同類型的恒星光譜的光譜圖會有很大的差異,因此可以將恒星光譜看成是一維信號,再利用一維卷積神經網絡中一維卷積計算的特性,實現了對一維恒星光譜的自動分類[11].
2 一維卷積神經網絡
在20世紀80年代就有學者開始研究卷積神經網絡,此后深度學習的理論日趨成熟,以及計算機被日益改進,卷積神經網絡也快速的發展.
卷積神經網絡是1種前饋網絡,是深度學習領域比較典型的算法.卷積神經網絡的特征學習能力可以有效的學習數據中的特征,并學會怎樣提取特征.卷積神經網絡被廣泛應用于分類識別研究,其中一維卷積神經網絡對于時間序列、電信號以及音頻信號等領域的分析有著出色的表現,鑒于此將一維卷積神經網絡應用于天體光譜分類的研究.
2.1 一維卷積運算
卷積是表征函數f(x)或g(x)先進行翻轉,另一個表征函數進行平移,它們重合部分函數值乘積對重合區間長度的積分,即“循環乘積與加和”一維卷積的數學定義公式如下:
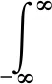
(1)

圖1 一維卷積運算過程
2.2 一維卷積神經網絡結構
卷積神經網絡一般結構包括:
1) 輸入層:通常一維卷積神經網絡處理的數組類型是一維或二維的,在原始數據進入輸入層之前會對其進行歸一化處理;
2) 卷積層:提取輸入數據的局部特征,提取到的特征進入池化層繼續篩選和過濾;
3) 池化層:首要的作用是降采樣,過濾掉對分類識別影響不大的特征,將數據壓縮,完成特征的降維處理,可實現參數數量的減少,提升網絡模型的計算速度,同時提高模型的容錯性,最終獲得更有代表性的特征;
4) 全連接層:輸入數據經過卷積層,池化層的處理,得到極具代表性的抽象化特征,由全連接層整合起來;
5) 輸出層:給出模型的預測結果,此次分類任務完成.

圖2 卷積神經網絡一般結構
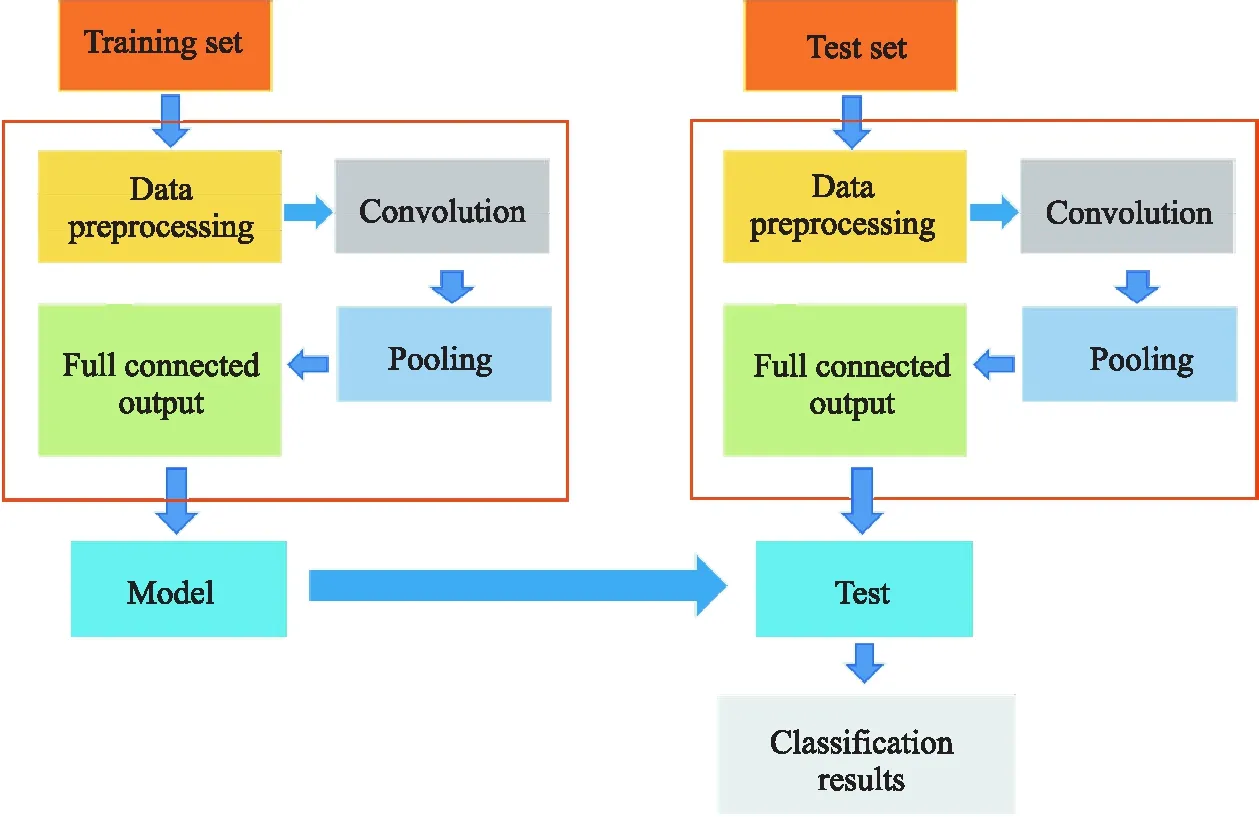
圖3 卷積神經網絡分類簡圖
3 數據預處理及實驗設計
3.1 數據的預處理
由于F、G、K 型恒星光譜由于溫度相近、譜線相似導致分類準確率較低,所以文中選取 LAMOST DR5 中的F、G、K 型恒星光譜各 10 000 條,共 30 000 條,采用一維卷積神經網絡模型對其進行分類,以提升這三類恒星光譜的分類精確率,其中訓練數據集為 27 000 條, 測試數據集為 3 000 條,每條光譜數據的波長范圍是370~910 nm.
為了后續實驗方便,將用于實驗的光譜數據調整為相同的維度,3 909 維.其次光譜原始數據在波長不同時流量會有很大的差異,對數據進行了歸一化處理,使流量值處于同一數量級,這個操作可加快網絡模型的收斂性,有利于數據分析.
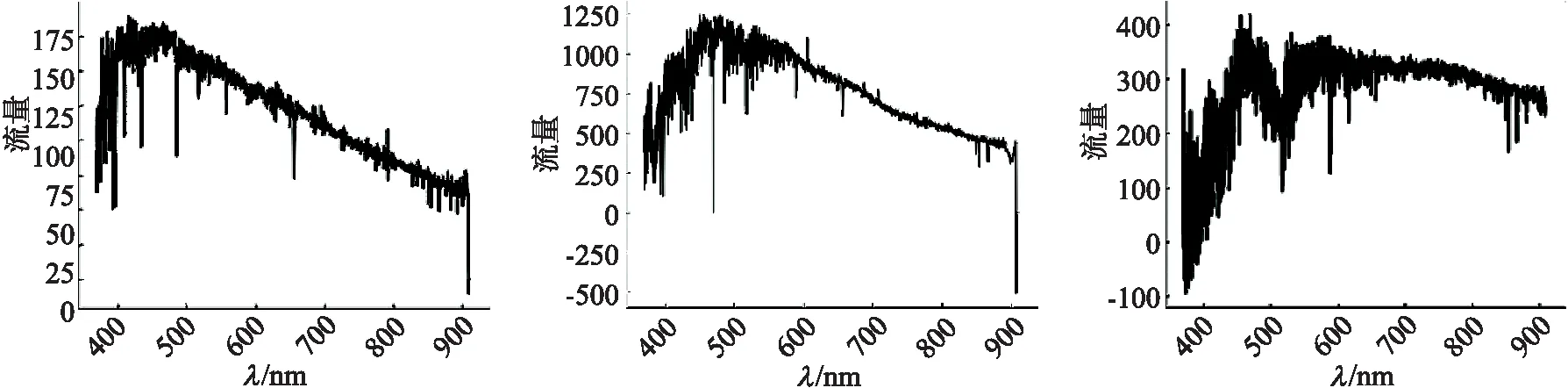
圖4 原始F5型、G5型、K5型光譜數據
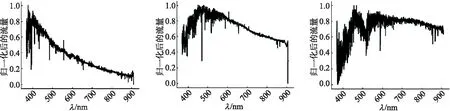
圖5 歸一化后的F5型、G5型、K5型光譜數據
文中使用min-max歸一化, 對原數據進行了等比例縮放, 公式如下:
(2)
其中xnorm表示歸一化后的數據,x為原始的光譜數據,xmax表示每條原始光譜數據的最大流量值,xmin表示每條原始光譜數據的最小流量.
3.2 實驗設計
文中的一維卷積神經網絡的結構包括1個輸入層,7個卷積層和池化層,1個Dropout層,2個Dense層,1個輸出層.其中卷積的步長設置為1,每層濾波器的大小都設置為3,濾波器的個數每層依次遞增10,即第1層卷積濾波器的個數為10,到第7層濾波器的個數為70, 本實驗在每一層卷積層的后面都添加了池化層,采用的是最大池化,窗口為 1×2, 網絡結構如圖6所示.
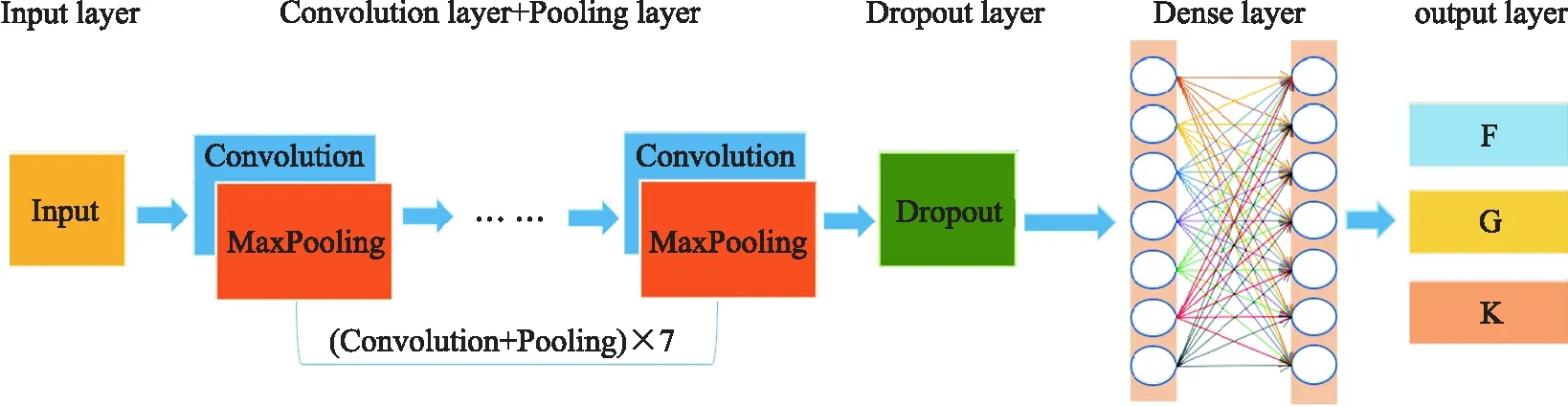
圖6 一維卷積網絡結構
為解決深層神經網絡的梯度爆炸和梯度消失問題,減少輸出的復雜度和防止數據的過擬合,在卷積之后使用修正線性單元ReLU函數,其函數如下:
ReLU(x)=max(0,x)
(3)
其中x為神經元的輸入,當x>0時,梯度為1,解決了梯度消失的問題,加快收斂速度的同時增大了網絡的魯棒性;當x<0 時,該層的輸出為0,當訓練結束時真正對分類效果有影響的神經元越少網絡的稀疏性越大,提取到的特征對于分類效果的影響就越強,優化了計算的過程使得網絡模型的計算代價大大降低.
本實驗在全連接層中加入了Dropout層,目的是防止出現過擬合,減少計算時間.交叉驗證表明,Dropout率為0.5的時候,能隨機生成最多的網絡結構,網絡模型效果最佳[12].
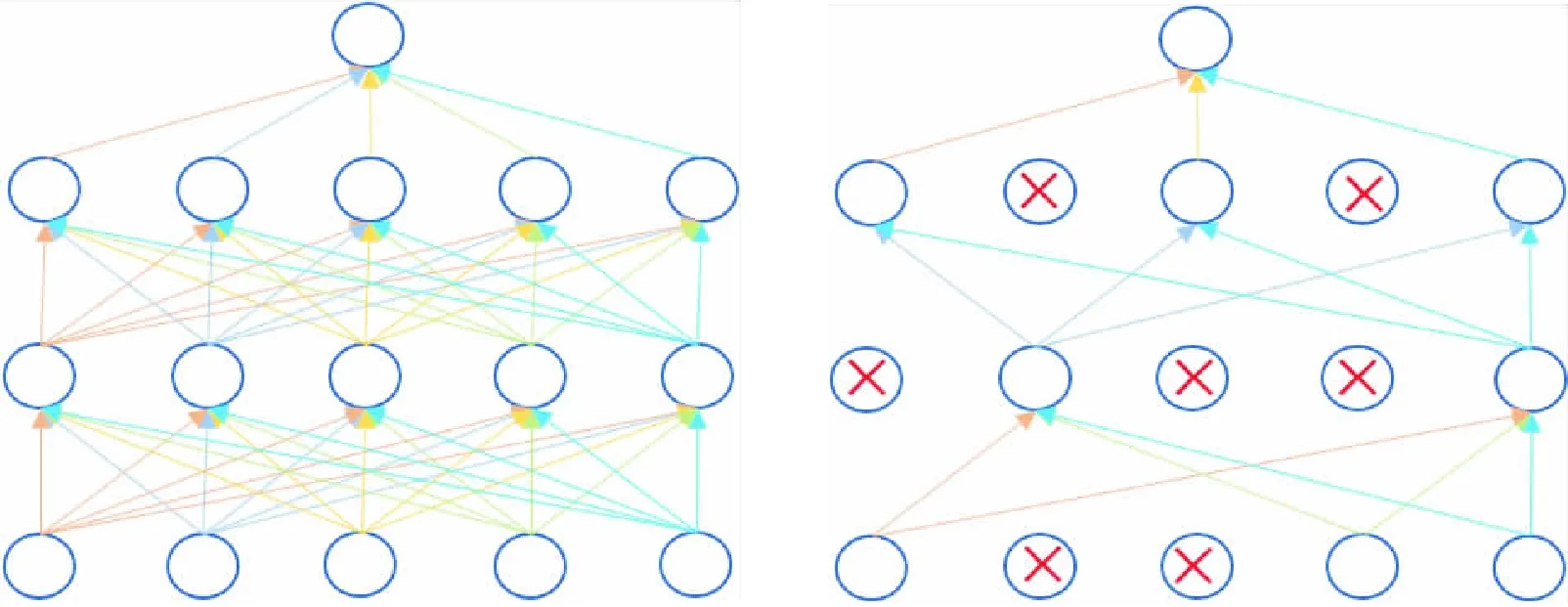
圖7 標準神經網絡、應用Dropout層后的神經網絡
按照Dropout率隨機令一定比例的神經元暫時等于零,這樣能實現神經元的總個數不會減少的同時,增加網絡的魯棒性.參數被傳遞到下一次迭代中,進行新一輪的隨機丟棄,一直到訓練完成為止.
4 實驗結果與分析
將 3 000 條測試數據,用于訓練好的一維卷積神經網絡模型進行測試,得到F型、G型、K型光譜在測試集上的混淆矩陣.可以看出在對F型光譜進行分類預測時,有5條被分類為G型光譜,有一條被分類為K型光譜; 在對G型光譜進行分類預測時,有10條被分類為F型光譜,有2條被分類為K型光譜; 在對K型光譜進行分類預測時,沒有光譜被分類為F型光譜,有35條被分類為G型光譜.在這3類恒星光譜中F型光譜和G型光譜相似性更高,混淆矩陣如表1:

表1 混淆矩陣
根據混淆矩陣可得到F型、G型、K型光譜的分類精確率、準確率、召回率以及F1分數,如表2所示:

表2 各類分類效果及平均分類效果
由表2可以看出一維卷積神經網絡對恒星光譜進行分類預測時有著極強的泛化能力和魯棒性,平均分類精確率為 0.982 2,準確率為 0.988 2,召回率為 0.982 4,F1分數為 0.982 1.其中F型恒星光譜特征最明顯分類效果最好,精確率、準確率、召回率以及F1分數都在0.99以上.
鑒于本文使用的數據集來源以及實驗數據大小與文獻[9]~[10]相同,將本文方法所獲得的結果與DBN和Inception v3方法獲得的結果做對比,如表3所示:

表3 DBN、Inception v3與本文使用方法的對比
由表3可以看出,采用3種不同的方法對恒星光譜進行分類研究,本文使用的方法效果更好,花費時間更少.表明了一維卷積神經網絡對于恒星光譜分類的泛化能力強,分類準確率高,計算成本更小. DBN、Inception v3方法對于恒星光譜的分類可能存在以下問題:
1) 許婷婷等[9]利用DBN模型對光譜數據特征的分層學習具有數據降維的特點,基于深度學習訓練了一個深度信念網絡對F、G和K 3種恒星光譜進行分類,沒有對恒星光譜進行降維處理,直接訓練DBN模型.但該分類模型可能不能很好的找出數據的聯合概率分布, 未能獲取潛藏在數據中的高層信息導致分類精度不高,且該模型的時間復雜度明顯增加.
2) 張靜敏等[10]采用短時傅里葉變換將1維光譜數據變換成2維傅里葉譜圖像,再利用Inception v3網絡模型對得到的2維傅里葉譜圖像進行分類.但將1維光譜數據變換成2維傅里葉譜圖像的過程中可能造成原始光譜特征信息的丟失;其次新生成的2維傅里葉譜圖像特征分布并不明顯,深度卷積網絡模型可能不能很好的對新生成的圖像進行分類;最后將1維光譜數據變換成2維傅里葉譜圖像,導致分類模型的時間復雜度也明顯增加.
本文鑒于一維卷積神經網絡可以很好地分析具有固定長度周期的信號數據,將其應用于F5、G5、K5型恒星光譜的分類研究,通過實驗可以看出:
1) 一維卷積神經網絡有很強的泛化能力以及魯棒性,能有效應用于恒星光譜的分類研究中;
2) 一維卷積神經網絡用于恒星光譜的分類研究能有效降低計算代價;
3) 直接對光譜數據進行一維卷積處理,有效降低了將光譜數據進行變換處理,再應用于傳統二維卷積神經網絡的特征損失,進而提高分類準確率.
5 結語
為了提高F、G、K型恒星光譜的分類可信度,本文將一維卷積神經網絡應用于這3種恒星光譜的分類識別研究中,平均精確率達到 0.982 2,平均準確率達到 0.988 2,平均召回率達到 0.982 4,平均F1分數達到 0.982 1,相對于其他的方法有了較大的提升.表明了一維卷積神經網絡模型對于恒星光譜數據分類具有很強的泛化能力.將本文方法與DBN以及Inception v3方法的實驗結果對比發現一維卷積神經網絡模型對恒星光譜分類的效果更好.但用于實驗的數據量較少,在接下來的工作中,會選取更多的光譜數據來進行實驗,與本文實驗以及其他方法進行對比分析,希望進一步提高F、G、K型恒星光譜的分類可信度.并且也會繼續將一維卷積神經網絡應用于分類精度較低的光譜,以驗證一維卷積神經網絡對于低精度恒星光譜分類的有效性,為人類探索宇宙的奧秘盡一份綿薄之力.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
