基于元度量學(xué)習(xí)的低資源語(yǔ)音識(shí)別
2021-06-24 09:07:36侯俊龍潘文林
關(guān)鍵詞:模型
侯俊龍, 潘文林
(云南民族大學(xué) 數(shù)學(xué)與計(jì)算機(jī)科學(xué)學(xué)院,云南 昆明 650500)
語(yǔ)音是人類學(xué)習(xí)和生活的重要交流工具,也是各民族文化傳承與發(fā)展的重要載體.隨著近年來(lái)大數(shù)據(jù)及設(shè)備超強(qiáng)運(yùn)算能力的出現(xiàn),各種各樣的人機(jī)交互式智能產(chǎn)品(如智能家居、智能音箱等)逐漸走進(jìn)每個(gè)家庭,給人們的生活帶來(lái)了極大便利.但對(duì)于一款實(shí)用的智能化產(chǎn)品來(lái)說(shuō),便捷高效的人機(jī)交互方式必不可少.語(yǔ)音作為語(yǔ)言的聲學(xué)表現(xiàn)形式,被認(rèn)為是當(dāng)前人類最簡(jiǎn)單、最直接的交流方式,利用語(yǔ)音進(jìn)行人機(jī)交互極有可能成為未來(lái)智能化產(chǎn)品的主要交互方式.
語(yǔ)音識(shí)別(speech recognition)的目標(biāo)是讓機(jī)器理解人類語(yǔ)音信號(hào)并作出相應(yīng)回應(yīng),它是實(shí)現(xiàn)語(yǔ)音交互的關(guān)鍵技術(shù),自20世紀(jì)50年代提出以來(lái)便日益成為人工智能領(lǐng)域的研究熱點(diǎn)[1].經(jīng)典的研究工作有: Graves等[2]在2013年提出使用循環(huán)神經(jīng)網(wǎng)絡(luò)進(jìn)行語(yǔ)音識(shí)別,其模型在TIMIT音素識(shí)別中取得了較好的識(shí)別效果;次年他們又提出了端到端語(yǔ)音識(shí)別系統(tǒng),模型的泛化性能得到了更進(jìn)一步的提升[3];2016年百度提出了端到端的深度學(xué)習(xí)方法,能夠很好的識(shí)別出漢語(yǔ)或英語(yǔ)[4];同年微軟提出結(jié)合使用LSTM和卷積神經(jīng)網(wǎng)絡(luò)來(lái)進(jìn)行語(yǔ)音識(shí)別,其精度達(dá)到了人類識(shí)別效果[5].但從可見文獻(xiàn)看來(lái),現(xiàn)有研究工作大多局限于漢語(yǔ)或英語(yǔ)等國(guó)際主流語(yǔ)言,究其原因是這些語(yǔ)言資源豐富,在語(yǔ)音識(shí)別研究中很容易獲取到大量語(yǔ)料用于模型訓(xùn)練.然而,在當(dāng)前參差不齊的語(yǔ)言環(huán)境下,很多民族語(yǔ)言正處于瀕臨消亡的危險(xiǎn)境地.根據(jù)民族語(yǔ)言網(wǎng)(ethnologue:language of the world)統(tǒng)計(jì),截至2020年10月全球現(xiàn)存7 117種語(yǔ)言,其中約40%語(yǔ)言使用者較少,被稱為低資源語(yǔ)言[6].在語(yǔ)音識(shí)別研究中,低資源語(yǔ)言常因使用人口基數(shù)少、覆蓋范圍小使得語(yǔ)料采集的難度加大、成本升高,很難獲取到足夠語(yǔ)料用于模型訓(xùn)練.在這種數(shù)據(jù)量過(guò)少或不足情況下,選用傳統(tǒng)深度學(xué)習(xí)方法進(jìn)行語(yǔ)音識(shí)別很容易出現(xiàn)模型過(guò)擬合[7].因此,如何進(jìn)行低資源語(yǔ)音識(shí)別逐漸成為了人工智能領(lǐng)域一項(xiàng)亟待解決的問(wèn)題.
低資源語(yǔ)音識(shí)別研究起步相對(duì)較晚,其中比較有代表性的研究工作有:王俊超等[8]在2018年提出采用遷移學(xué)習(xí)方法進(jìn)行低資源維吾爾語(yǔ)語(yǔ)音識(shí)別,取得了很好的識(shí)別效果;同年12月,孫杰等[9]提出跨語(yǔ)種的CMN聲學(xué)模型來(lái)對(duì)低資源柯爾克孜語(yǔ)進(jìn)行語(yǔ)音識(shí)別,其模型具有比同級(jí)CNN網(wǎng)絡(luò)更好的泛化性能;去年,Xu等人研發(fā)出了一個(gè)能夠用于低資源環(huán)境的語(yǔ)音識(shí)別系統(tǒng),他們先用具有豐富數(shù)據(jù)資源的語(yǔ)言對(duì)模型進(jìn)行預(yù)訓(xùn)練,完成后再在目標(biāo)語(yǔ)言上微調(diào)模型,其實(shí)驗(yàn)結(jié)果表明該方法能夠讓模型在目標(biāo)任務(wù)上取得較為理想的識(shí)別效果[10].采用遷移學(xué)習(xí)方法對(duì)低資源語(yǔ)言語(yǔ)音進(jìn)行識(shí)別雖然能夠讓模型泛化性能得到一定提升,但該方法的使用通常需要提前準(zhǔn)備兩個(gè)甚至更多的大規(guī)模語(yǔ)料庫(kù)用于模型訓(xùn)練,這將帶來(lái)大量的人力、物力及財(cái)力耗費(fèi).隨后,人們還提出采用數(shù)據(jù)增強(qiáng)技術(shù)來(lái)解決低資源環(huán)境下聲學(xué)模型難以訓(xùn)練的問(wèn)題,該技術(shù)旨在通過(guò)某種算法來(lái)擴(kuò)增樣本數(shù)量及其多樣性以使模型能夠得到充分訓(xùn)練.該方法雖然能夠在一定程度上緩解模型的過(guò)擬合問(wèn)題,但卻并未讓小樣本學(xué)習(xí)問(wèn)題得到完全解決[11].最近,學(xué)術(shù)界不少研究學(xué)者受到人類學(xué)習(xí)能力的啟發(fā)提出了一種基于元學(xué)習(xí)的小樣本學(xué)習(xí)方法,該方法能夠讓模型學(xué)會(huì)如何從少量數(shù)據(jù)中快速獲取新知識(shí),現(xiàn)已在圖像處理[12]、文本分類[13]、植物病害識(shí)別[14]等諸多領(lǐng)域得到了成功應(yīng)用.低資源語(yǔ)音識(shí)別由于缺乏足夠的語(yǔ)音語(yǔ)料通常很難讓模型得到充分訓(xùn)練,進(jìn)而導(dǎo)致語(yǔ)音識(shí)別精度較低.為了有效解決低資源語(yǔ)音的難識(shí)別問(wèn)題,很多語(yǔ)音學(xué)研究員也開始嘗試將元學(xué)習(xí)方法用于小樣本語(yǔ)音識(shí)別研究,較為經(jīng)典的研究工作有:王璐等[15]探究表明了元學(xué)習(xí)方法有助于解決小規(guī)模語(yǔ)料的語(yǔ)音識(shí)別問(wèn)題;王翠等[16]提出采用MAML算法對(duì)佤語(yǔ)孤立詞語(yǔ)音進(jìn)行識(shí)別,其模型在小樣本孤立詞語(yǔ)音識(shí)別任務(wù)中取得了較高的識(shí)別精度;2019年10月,國(guó)外學(xué)者Koluguri等[17]將元學(xué)習(xí)方法用于兒童-成人語(yǔ)音分類,其模型在兒童-成人語(yǔ)音數(shù)據(jù)集上取得了比傳統(tǒng)深度學(xué)習(xí)方法更好的分類效果;此外,華為諾亞方舟實(shí)驗(yàn)室研究員Tian等次年8月提出采用Reptile算法對(duì)低資源環(huán)境下的口語(yǔ)語(yǔ)音進(jìn)行識(shí)別,其實(shí)驗(yàn)結(jié)果表明Reptile算法在低資源語(yǔ)音識(shí)別任務(wù)中具有比傳統(tǒng)梯度下降算法更強(qiáng)的泛化能力[18].元學(xué)習(xí)是通過(guò)模擬人類學(xué)習(xí)方式來(lái)處理不同學(xué)習(xí)任務(wù)的一種方法,從日常的學(xué)習(xí)和生活中發(fā)現(xiàn)人類自出生時(shí)起便擁有非常強(qiáng)的比較學(xué)習(xí)能力,人們能夠借助這種能力來(lái)分辨不同物體.受此啟發(fā),本文將在低資源環(huán)境下選取佤語(yǔ)和普米語(yǔ)作為研究對(duì)象,開展基于元度量學(xué)習(xí)的低資源語(yǔ)音識(shí)別研究.
1 相關(guān)理論
1.1 小樣本學(xué)習(xí)
小樣本學(xué)習(xí)本是人類所特有的一種學(xué)習(xí)能力,它是指人類能夠從少量的樣本中快速學(xué)習(xí)新的概念.譬如,人類在只觀察過(guò)較少的貓狗圖片后,當(dāng)新的貓狗圖像出現(xiàn)時(shí),人們就能夠利用從少量數(shù)據(jù)中學(xué)到的經(jīng)驗(yàn)來(lái)對(duì)新樣本進(jìn)行識(shí)別.但對(duì)于機(jī)器而言,要學(xué)習(xí)處理一個(gè)特定的分類或識(shí)別任務(wù)通常需要成千上萬(wàn)條數(shù)據(jù)進(jìn)行反復(fù)訓(xùn)練,如果擁有的數(shù)據(jù)量過(guò)少或不足,其學(xué)習(xí)能力還會(huì)受到嚴(yán)重限制.最近,受到人類小樣本學(xué)習(xí)能力的啟發(fā),人們對(duì)機(jī)器小樣本學(xué)習(xí)的興趣也愈發(fā)濃厚,他們渴望機(jī)器能夠以人類學(xué)習(xí)方式利用有限數(shù)據(jù)資源進(jìn)行學(xué)習(xí),即機(jī)器小樣本學(xué)習(xí)[19].截至目前,深度學(xué)習(xí)領(lǐng)域?qū)π颖緦W(xué)習(xí)問(wèn)題的劃分大致有如下3類:1)零樣本學(xué)習(xí)(zero-shot learning)[20-21];2)單樣本學(xué)習(xí)(one-shot learning)[22-23];3)少樣本學(xué)習(xí)(few-shot learning)[24].
在小樣本學(xué)習(xí)中,人們普遍面臨的問(wèn)題是如何克服模型因數(shù)據(jù)量過(guò)少或不足所帶來(lái)的嚴(yán)重過(guò)擬合問(wèn)題.早期,為了避免模型過(guò)度擬合、提升模型表達(dá)能力,人們提出采用手動(dòng)數(shù)據(jù)增強(qiáng)技術(shù)來(lái)擴(kuò)增樣本數(shù)量及其多樣性[25].這種方式雖然能夠緩解模型過(guò)擬合,但也不可避免的加大了數(shù)據(jù)處理成本,并且很難普適所有數(shù)據(jù).隨后谷歌研究學(xué)者受AutoML啟發(fā)提出了自動(dòng)數(shù)據(jù)增強(qiáng)方法,其模型在不同數(shù)據(jù)集上均表現(xiàn)出了超強(qiáng)的泛化能力[26].使用數(shù)據(jù)增強(qiáng)雖然能擴(kuò)增一定量數(shù)據(jù),但隨著數(shù)據(jù)量的不斷增加,模型對(duì)設(shè)備運(yùn)算能力的要求也越來(lái)越高.此外,在零樣本或單樣本學(xué)習(xí)任務(wù)中,僅僅使用數(shù)據(jù)增強(qiáng)技術(shù)很難完全解決小樣本學(xué)習(xí)問(wèn)題.而后,為了更好的解決小樣本學(xué)習(xí)問(wèn)題,不少研究學(xué)者開始了元學(xué)習(xí)方法的研究,它被認(rèn)為是當(dāng)前解決小樣本學(xué)習(xí)問(wèn)題最為有效的一種方法.
1.2 元學(xué)習(xí)
元學(xué)習(xí)(meta learning),亦稱學(xué)會(huì)學(xué)習(xí)(learning to learn),是近期人工智能領(lǐng)域的一個(gè)新興研究方向[27].它與傳統(tǒng)的深度學(xué)習(xí)方法不同,常規(guī)深度學(xué)習(xí)是利用大量的標(biāo)注數(shù)據(jù)來(lái)對(duì)模型進(jìn)行訓(xùn)練,旨在讓訓(xùn)練好的模型能夠在特定任務(wù)上具有較強(qiáng)的泛化能力.而元學(xué)習(xí)則旨在讓模型從大量任務(wù)中學(xué)習(xí)如何解決問(wèn)題,也就是希望模型能夠從一系列不相交任務(wù)中獲取某種共性知識(shí)來(lái)指導(dǎo)新任務(wù)學(xué)習(xí).因此,在元學(xué)習(xí)中通常需要提前準(zhǔn)備大量類似且不相交任務(wù)用于模型訓(xùn)練,每個(gè)任務(wù)均包含訓(xùn)練集(支持集)和測(cè)試集(查詢集).此外,還需將生成的所有任務(wù)劃分為元訓(xùn)練數(shù)據(jù)(Dτi)和元測(cè)試數(shù)據(jù)(Dτj),其中Dτi∩Dτj=Φ.
1.3 元度量學(xué)習(xí)
元度量學(xué)習(xí)旨讓模型從大量任務(wù)中學(xué)習(xí)如何比較樣本的相似性,它是借助最近鄰算法的思想來(lái)處理不同的學(xué)習(xí)任務(wù).其實(shí)現(xiàn)過(guò)程是先將支持集與查詢集樣本投影至一個(gè)度量空間,隨后選用某個(gè)度量函數(shù)計(jì)算出支持集與查詢集樣本的相似性,最后通過(guò)最近鄰算法來(lái)預(yù)測(cè)未知樣本的類別標(biāo)簽,其定義如(式1)所示.
(1)
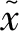
在小樣本物體分類或識(shí)別任務(wù)中,元度量學(xué)習(xí)方法旨在通過(guò)最近鄰思想從大量任務(wù)中訓(xùn)練出一個(gè)具有較強(qiáng)泛化性能的通用神經(jīng)網(wǎng)絡(luò)模型,使其在不同的學(xué)習(xí)任務(wù)中能夠提取出具有較強(qiáng)表征能力的樣本特征,隨后通過(guò)選取某個(gè)度量函數(shù)來(lái)對(duì)樣本特征進(jìn)行比較以完成相應(yīng)的分類或識(shí)別任務(wù).元度量學(xué)習(xí)中選用不同的度量函數(shù)能夠得到不同網(wǎng)絡(luò)模型,其中比較常見的相似性度量函數(shù)有余弦距離[28]、歐式距離[29]或馬氏距離[30].這類距離函數(shù)雖然能夠合理地反映出物體的相似程度,但由于其度量方式過(guò)于單一,通常很難普適所有問(wèn)題.為此,不少研究學(xué)者還提出使用可學(xué)習(xí)的神經(jīng)網(wǎng)絡(luò)來(lái)度量樣本的相似性[31-32].
2 元度量學(xué)習(xí)網(wǎng)絡(luò)
元度量學(xué)習(xí)算法旨在讓模型能夠從大量類似但不相交任務(wù)中學(xué)習(xí)如何比較樣本的相似性,當(dāng)新的學(xué)習(xí)任務(wù)出現(xiàn)時(shí),模型只需通過(guò)對(duì)樣本特征進(jìn)行比較即可完成相應(yīng)的分類或識(shí)別任務(wù).元度量學(xué)習(xí)網(wǎng)絡(luò)通常由嵌入模塊和度量模塊2部分組成,前者主要用于提取輸入數(shù)據(jù)的深層特征,根據(jù)數(shù)據(jù)類型的不同可選用卷積神經(jīng)網(wǎng)絡(luò)或循環(huán)神經(jīng)網(wǎng)絡(luò);而度量模塊則主要用于測(cè)算不同任務(wù)中支持集樣本與查詢集樣本的相似性.其框架結(jié)構(gòu)如圖1所示.
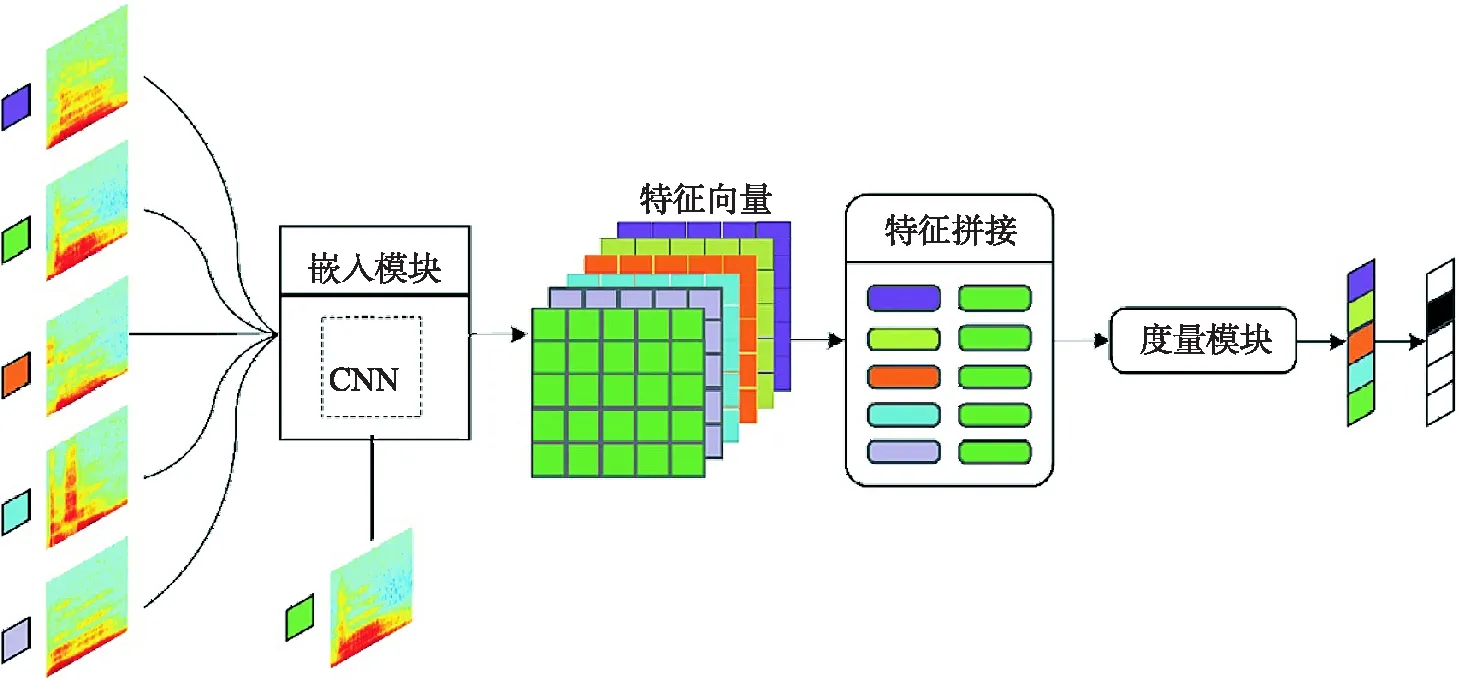
圖1 元度量學(xué)習(xí)網(wǎng)絡(luò)框架結(jié)構(gòu)
當(dāng)前極具代表性的元度量學(xué)習(xí)網(wǎng)絡(luò)主要包括原型網(wǎng)絡(luò)(prototypical network,P-Net)、關(guān)系網(wǎng)絡(luò)(relation network, R-Net)及其變體.P-Net與R-Net的組成結(jié)構(gòu)如圖2所示,圖中S表示支持集,Q為查詢集,μ為支持集中各類樣本的特征均值,即類原型.
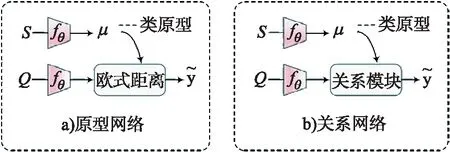
圖2 P-Net 與R-Net 框架組成
圖2中關(guān)系網(wǎng)絡(luò)是在原型網(wǎng)絡(luò)基礎(chǔ)上進(jìn)行改進(jìn)所得,其框架結(jié)構(gòu)非常相似.P-Net與R-Net的嵌入模塊選用同一深度神經(jīng)網(wǎng)絡(luò)fθ來(lái)對(duì)輸入數(shù)據(jù)進(jìn)行特征提取,二者均選擇將提取出的支持集樣本特征按類求取平均值并將其表示為類原型μ.二者的不同之處在于原型網(wǎng)絡(luò)是選用單一且固定的歐式距離函數(shù)作為分類器,而關(guān)系網(wǎng)則改用一個(gè)可學(xué)習(xí)的淺層神經(jīng)網(wǎng)絡(luò)(關(guān)系模塊)來(lái)度量樣本的相似性.
2.1 元度量學(xué)習(xí)網(wǎng)絡(luò)優(yōu)化過(guò)程
在小樣本學(xué)習(xí)任務(wù)中,不同的元度量學(xué)習(xí)算法其實(shí)現(xiàn)過(guò)程大致相同,本文將以關(guān)系網(wǎng)絡(luò)為例詳細(xì)介紹元度量學(xué)習(xí)網(wǎng)絡(luò)的優(yōu)化過(guò)程,其實(shí)現(xiàn)過(guò)程描述如下:
1) 先從大量任務(wù)中隨機(jī)采樣一批任務(wù)輸入到嵌入模塊提取出支持集樣本與查詢集樣本的特征fθ(xi)和fθ(xj).
2) 隨后對(duì)支持集樣本特征按類求取平均值得到各類原型μi,計(jì)算過(guò)程如式(2)所示.
(2)
3) 接著將各類原型分別與查詢集樣本進(jìn)行特征拼接形成組合特征如式(3)所示.
Z=μi⊕fθ(xj).
(3)
4) 最后再將拼接而成的組合特征輸入到關(guān)系模塊Rφ,該模塊通過(guò)一個(gè)可學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)來(lái)計(jì)算支持集與查詢集樣本的相似度ri,j,計(jì)算過(guò)程如式(4)所示.
ri,j=Rφ(Z)=Rφ(μi+fθ(xj)).
(4)
5) 在關(guān)系網(wǎng)絡(luò)訓(xùn)練過(guò)程中,通過(guò)不斷最小化均方誤差損失(Mean Square Error,MSE)函數(shù)來(lái)對(duì)模型進(jìn)行優(yōu)化,其優(yōu)化目標(biāo)如式(5)所示.
(5)
其中,I為指示函數(shù),當(dāng)yi=yj時(shí),其值為1;否則為0.
3 實(shí)驗(yàn)
3.1 實(shí)驗(yàn)數(shù)據(jù)集
實(shí)驗(yàn)所用語(yǔ)料均是在錄音棚環(huán)境下采錄所得,每種語(yǔ)料包含 1 500 類孤立詞.其中,佤語(yǔ)語(yǔ)料由4個(gè)發(fā)音人(2男2女)分別錄制每詞5遍所得,共計(jì) 30 000 條孤立詞語(yǔ)音;而普米語(yǔ)語(yǔ)料則是由3個(gè)發(fā)音人(2男1女)分別錄制每詞8遍所得,共采錄得到 36 000 條語(yǔ)音語(yǔ)料,所有語(yǔ)料經(jīng)標(biāo)注整理后均采用傅里葉變換將其轉(zhuǎn)換為聲譜圖.
由于元學(xué)習(xí)是從大量任務(wù)中學(xué)習(xí)可遷移知識(shí),因此在模型訓(xùn)練前需先對(duì)聲譜圖進(jìn)行必要處理以生成具有大量任務(wù)的小規(guī)模語(yǔ)料庫(kù).元學(xué)習(xí)數(shù)據(jù)集一般由元訓(xùn)練數(shù)據(jù)及元測(cè)試數(shù)據(jù)組成,本文實(shí)驗(yàn)分別將每種語(yǔ)料的70%用于元訓(xùn)練,其余樣本用作元測(cè)試.元學(xué)習(xí)的數(shù)據(jù)集分布如圖3所示,其中τj為隨機(jī)采樣所得任務(wù),每個(gè)任務(wù)均由支持集和查詢集組成.
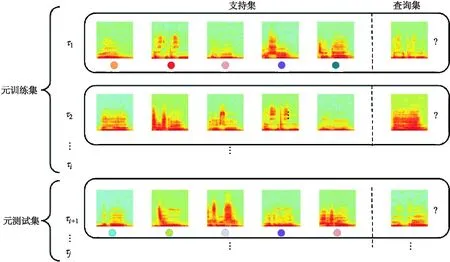
圖3 元學(xué)習(xí)數(shù)據(jù)集分布示意圖
3.2 實(shí)驗(yàn)環(huán)境及超參數(shù)
為了比較不同元度量學(xué)習(xí)網(wǎng)絡(luò)在低資源語(yǔ)音識(shí)別中的性能,本文所有實(shí)驗(yàn)均在同一開發(fā)環(huán)境(Python)中使用相同的深度學(xué)習(xí)框架(Pytorch)來(lái)完成,系統(tǒng)選用Windows 10.0,實(shí)驗(yàn)還使用GPU對(duì)模型進(jìn)行加速.P-Net與R-Net中相同的超參數(shù)設(shè)置如下:所有模型均使用初始學(xué)習(xí)率為0.001的Adam優(yōu)化器;訓(xùn)練輪數(shù)epochs=200,每輪包含25個(gè)小樣本學(xué)習(xí)任務(wù);在五類單樣本語(yǔ)音識(shí)別任務(wù)中,組成每個(gè)任務(wù)的樣本類別數(shù)n=5,支持集與查詢集的類內(nèi)樣本數(shù)分別為k=1和q=10;在5類5樣本語(yǔ)音識(shí)別任務(wù)中,上述參數(shù)則分別設(shè)置為n=5,k=5,q=10.
3.3 模型結(jié)構(gòu)
P-Net與R-Net的嵌入模塊使用同一個(gè)淺層卷積神經(jīng)網(wǎng)絡(luò)來(lái)提取語(yǔ)音信號(hào)特征,二者的度量模塊則選用不同的度量函數(shù)來(lái)測(cè)算樣本的相似性,P-Net使用歐式距離函數(shù)來(lái)計(jì)算樣本的相似性,而R-Net則選用一個(gè)可學(xué)習(xí)卷積神經(jīng)網(wǎng)絡(luò)作為分類器.R-Net中各模塊組成結(jié)構(gòu)及參數(shù)如表1所示,其中stride表示步長(zhǎng),padding表示零填充方式,使用ReLU激活函數(shù),特征采樣選用最大池化(MaxPool)函數(shù).

表1 關(guān)系網(wǎng)絡(luò)各模塊組成結(jié)構(gòu)及參數(shù)
3.3 實(shí)驗(yàn)結(jié)果分析
實(shí)驗(yàn)選用準(zhǔn)確率來(lái)評(píng)估聲學(xué)模型的泛化能力,假設(shè)存在一個(gè)樣本總數(shù)為N的數(shù)據(jù)集,在模型訓(xùn)練過(guò)程中每次選取Q個(gè)樣本進(jìn)行標(biāo)簽預(yù)測(cè),若預(yù)測(cè)正確的樣本數(shù)為T(T≤Q),則該模型在這次訓(xùn)練任務(wù)中的準(zhǔn)確率就表示為
(6)
其中P值越大,說(shuō)明模型的泛化能力越強(qiáng).
3.3.1 佤語(yǔ)孤立詞語(yǔ)音識(shí)別性能
本文先在佤語(yǔ)數(shù)據(jù)集上分別探究了原型網(wǎng)絡(luò)與關(guān)系網(wǎng)絡(luò)的泛化能力,二者在不同的佤語(yǔ)孤立詞語(yǔ)音識(shí)別任務(wù)中的識(shí)別精度如表2所示.
通過(guò)縱向比較表2中數(shù)據(jù)能夠發(fā)現(xiàn),關(guān)系網(wǎng)絡(luò)具有比原型網(wǎng)絡(luò)更強(qiáng)的泛化能力,其在五類單樣本(5-way 1-shot)識(shí)別任務(wù)中的精度達(dá)到了98.51%,而在5類5樣本(5-way 5-shot)識(shí)別任務(wù)中的精度更是高達(dá)99.56%.據(jù)此我們能夠分析得出:元度量學(xué)習(xí)網(wǎng)絡(luò)中使用可學(xué)習(xí)深度神經(jīng)網(wǎng)絡(luò)來(lái)度量樣本相似性能夠有效提升模型的泛化性能,具有比使用單一且固定的線性距離函數(shù)更好的識(shí)別效果.

表2 不同元度量學(xué)習(xí)網(wǎng)絡(luò)在佤語(yǔ)數(shù)據(jù)集上的性能比較 %
此外,通過(guò)橫向觀察表中數(shù)據(jù)還能夠發(fā)現(xiàn),當(dāng)佤語(yǔ)孤立詞語(yǔ)音識(shí)別任務(wù)中樣本類別數(shù)恒定時(shí),元度量學(xué)習(xí)網(wǎng)絡(luò)的泛化性能會(huì)隨著類內(nèi)樣本數(shù)目的增加而不斷提升;而當(dāng)類內(nèi)樣本數(shù)目恒定不變時(shí),其泛化能力則會(huì)隨著樣本類別數(shù)的增加而逐漸下降.與5類單樣本和5類5樣本佤語(yǔ)孤立詞語(yǔ)音識(shí)別任務(wù)相比,關(guān)系網(wǎng)絡(luò)在10-way 1-shot和10-way 5-shot任務(wù)中的識(shí)別精度分別下降了0.89%和0.35%.
3.3.2 普米語(yǔ)孤立詞語(yǔ)音識(shí)別性能
此外,本文還在普米語(yǔ)數(shù)據(jù)集上驗(yàn)證了不同元度量學(xué)習(xí)網(wǎng)絡(luò)的泛化性能,其在不同的普米語(yǔ)孤立詞語(yǔ)音識(shí)別任務(wù)中的識(shí)別精度如表3所示.
通過(guò)縱向比較表中數(shù)據(jù)同樣能夠發(fā)現(xiàn),在學(xué)習(xí)任務(wù)相同的情況下,關(guān)系網(wǎng)絡(luò)的泛化性能顯著優(yōu)于原型網(wǎng)絡(luò).并且通過(guò)橫向觀察表3中數(shù)據(jù)仍然能夠得出,當(dāng)普米語(yǔ)孤立詞語(yǔ)音識(shí)別任務(wù)中的樣本類比數(shù)恒定不變時(shí),元度量學(xué)習(xí)網(wǎng)絡(luò)的泛化性能與類內(nèi)樣本數(shù)呈正比;而當(dāng)類內(nèi)樣本數(shù)目固定不變時(shí),其泛化性能會(huì)隨著樣本類別數(shù)的增加而出現(xiàn)下降趨勢(shì).

表3 不同元度量學(xué)習(xí)網(wǎng)絡(luò)在普米語(yǔ)數(shù)據(jù)集上的性能比較 %
4 結(jié)語(yǔ)
本文探究了不同元度量學(xué)習(xí)網(wǎng)絡(luò)在低資源語(yǔ)音識(shí)別中的性能,所用模型在佤語(yǔ)和普米語(yǔ)孤立詞語(yǔ)音識(shí)別任務(wù)中均取得了很好的識(shí)別效果.此外,本文還通過(guò)實(shí)驗(yàn)驗(yàn)證了元度量學(xué)習(xí)網(wǎng)絡(luò)中選用可學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)來(lái)度量樣本相似性比使用單一且固定的線性距離函數(shù)效果更佳,并且本文還分析了樣本量變化對(duì)模型泛化性能的影響.在后續(xù)的研究工作中,我們將繼續(xù)針對(duì)低資源語(yǔ)音的難識(shí)別問(wèn)題探索性能更優(yōu)的元度量學(xué)習(xí)方法.
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
