基于遷移學習的發票號碼識別研究
2021-06-25 14:17:58黃為新張繼超
軟件導刊 2021年6期
黃為新,陶 楊,張繼超,蘇 笛,牛 硯
(1.吉林大學 計算機科學與技術學院;2.吉林大學 數學學院,吉林 長春 130012)
0 引言
發票數字識別本質上屬于光學字符識別領域中的一個分支——印刷體數字識別。光學字符識別技術被廣泛應用于各方面,如鐵軌路牌識別[1]、快遞單號識別、身份證號碼識別[2]等,對人們的日常生產和生活產生了重要影響。而對印刷體數字識別的研究也有很多,如孟巖等[3]總結了印刷體數字識別基本流程,提出采用攝像頭而非掃描儀并結合數字圖像處理技術和光學字符識別(Optical Character Recognition,OCR)的方法將成為該領域研究的主流方向;卿東升等[4]對通過結構特征識別數字的方法作進一步改進,提出一種基于二進制的算法。近年來的研究主要圍繞神經網絡技術,周澤華等[5]提出設計結構合理、收斂性強的BP 神經網絡,識別率較高。
印刷體數字識別是將圖片中0~9 的數字轉變為計算機可識別的信息,而發票號碼識別要做的工作更加具體。傳統的發票信息獲取絕大多數依靠人力,由于涉及對數字敏感的金融領域,這要求對單個數字的識別率很高。因此,設計出一套可以智能快速準確地識別發票單號的系統尤為必要。
一個完整成熟的數字識別系統包括:圖像獲取、圖像預處理、圖像字符切割、字符識別。本文通過網絡爬蟲技術,從互聯網上獲取發票圖像樣本;通過噪聲處理、圖像二值化等方法對圖像作初步處理;通過投影法進行字符切割,從而獲取獨立的數字;最后是本文的核心工作——發票數字識別。與發票數字識別最接近的是手寫體數字識別。一般而言,手寫數字的處理更加復雜,目前手寫數字識別問題已得到很好地解決。柳回春等[6]分析了手寫數字識別情況,從而給人以啟發——可以將其運用到印刷體數字識別上。這里不得不提及一個有名的數據集——MNIST手寫字符數據集,它由LeCun 等[7]建立,包含10 個阿拉伯數字(0~9)一共60 000 張訓練圖片和10 000 張測試圖片。在通過MNIST 數據集訓練完備的手寫數字神經網絡Lenet上測試的準確率已達0.993 2,但在導入搜集好的印刷體數字圖片并進行測試后,發現準確率僅為0.810 0,沒有達到預期效果。直接將手寫數字網絡用于發票數字識別并不是一種好的解決方案,但這種嘗試給予人一定啟發,即可以對訓練好的手寫數字神經網絡進行調整,例如網絡參數和結構,從而提高印刷體數字識別準確率。
當訓練和測試的樣本域分布不同時,需采用遷移學習相關算法加以實現,本文采用的3 種方法都是建立在前人提出的比較完善的理論體系之上。例如,卷積神經網絡(Convolutional Neural Networks,CNN)用于圖像識別的方法比較常用,是利用數據樣本構造一個“黑盒子”,將待測圖片輸入其中便可以得到它的類別。Li 等[8]提出一種高效卷積神經網絡的前向和后向傳播算法,用于對圖像進行像素級分類并且消除了所有冗余計算;Pan 等[9]系統總結了遷移學習相關理論,與傳統機器學習不同的是,它無需對目標任務進行重新訓練;Ganin 等[10]提出的神經網絡領域對抗訓練理論是在一般神經網絡訓練中加入新的梯度反轉層,自適應地完成深特征提取任務,實現在相似但分布不同數據集之間的訓練與測試;Dan 等[11]提出的Tradaboost是遷移學習的一種算法,它指當源數據集和目標數據集處于不同分布時,同時利用帶有標簽的源數據集和帶有標簽的目標數據集,通過不同分布的訓練數據訓練出一個分類器,用于目標數據分類。上述文獻為本實驗提供了理論依據和指導,本文將幾種遷移學習方法模型綜合運用于發票數字識別,以尋求較優解決辦法。本文結合了MNIST 數據集,通過網絡爬蟲獲取和處理手造發票數字的樣本集,并積極改進Lenet-5 的網絡結構以適應該數據集。實驗結果表明,運用Lenet-5 提取發票數字特征并用支持向量機(Support Vector Machine,SVM)進行訓練的方法,準確率較高,且穩定性較好。
1 發票數字數據集獲取與預處理
實驗所用的發票圖片樣本均采用網絡爬蟲技術從各大搜索引擎網站爬取,類似百度、搜狐。但原始的發票圖片不能直接運用于后續數字識別實驗模塊,要經過一系列處理步驟,如框定發票號碼區域、灰度化和二值化、投影法分割、人工篩選,得到單個數字的圖片用于后續訓練。
發票單號識別系統具有交互性,可以人為框定發票號碼區域,通過鼠標按下、拖動、松開以確定框選區域,同時計算機追蹤鼠標按下和松開位置,再截出對應的發票單號區域,也稱為“感興趣”區域。灰度化和二值化可以簡化處理,提高算法分割效率。灰度化使用Python-opencv 包自帶函數,而二值化方法有自適應閾值二值化、均值二值化、最大類間方差法等。通過多次試驗和比較,分割算法中最大類間方差法效率最高、準確率最好。二值化后,采用投影法進行分割,數字的圖片是白底黑字,只有兩種像素,從垂直和水平方向分別得到像素分布,黑色像素個數發生較大變化說明接近有數字的區域,如此可以大致確定數字位置。結合兩個方向黑色像素分布的直方圖就可以給該數字框定一個矩形并截取出來。雖然得到的數字圖片大小不一,但可以在周圍填充空白,并使用雙線性差值形成預期大小為28×28 PX 的數字圖片,用來形成樣本集。發票圖片預處理過程如圖1 所示。
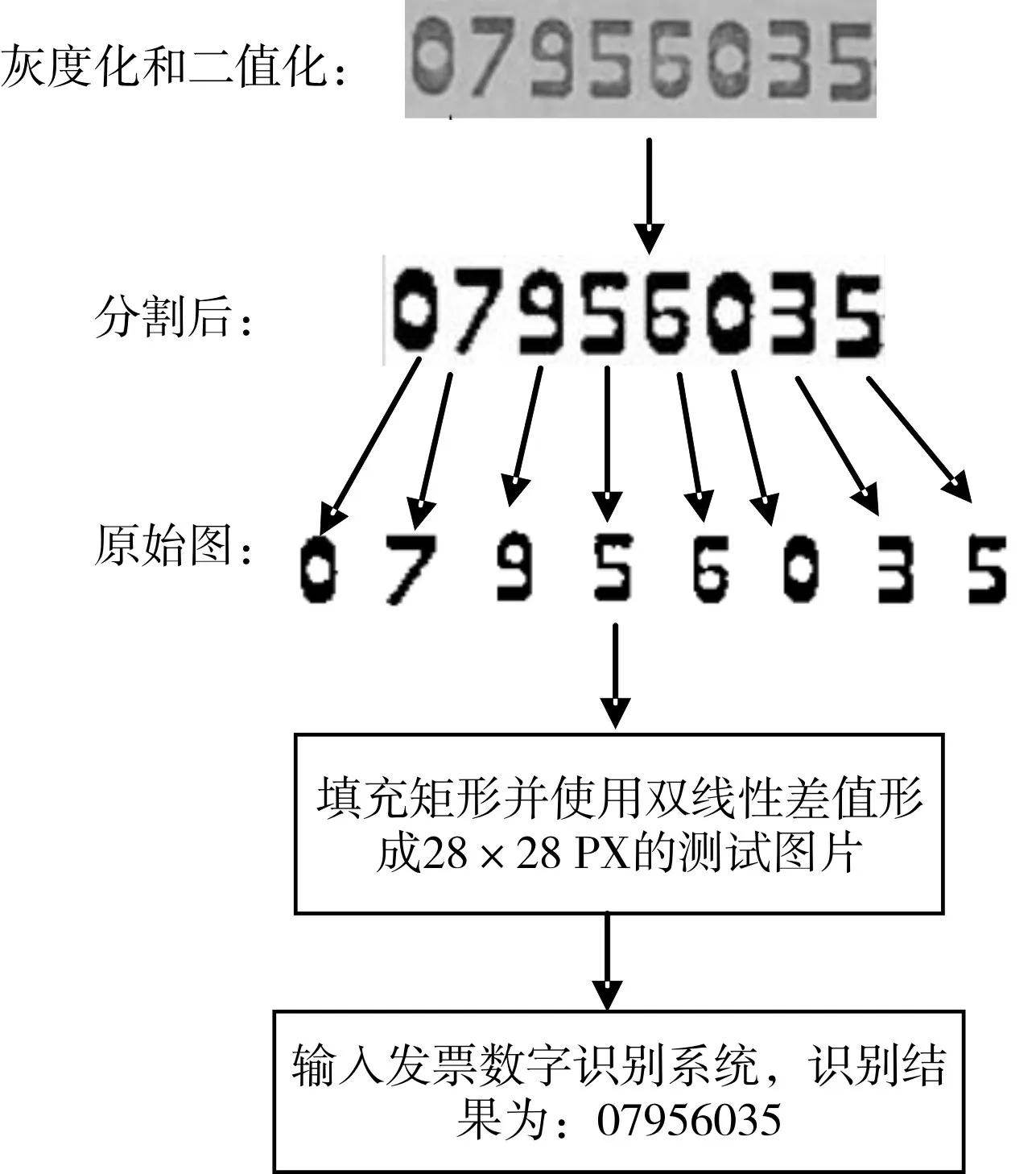
Fig.1 The preprocessing process of invoice pictures圖1 發票圖片預處理過程演示
為了形成統一的發票印刷體數字圖片數據集,需進行一定的人工篩選。保證數據集要具有以下特點:各類樣本比例平衡,數字要清晰得足以用肉眼分辨,數字標簽要準確。最終形成的數據集一共2 000 張圖片,包括0~9,大小為28×28 PX。發票數字數據集示例如圖2 所示。

Fig.2 An example of the invoice number dataset圖2 發票數字數據集示例
2 數字識別模塊實現
本文采用上述發票數字數據集進行實驗,選取測試時間、識別時間和準確率作為評價標準。測試平臺配置如下:操作系統:Windows 10;使用語言:Python 3.6;深度學習框架:Tensorflow(1.14.0);硬件環境:CPU Intel i5-7200U 2.50GHz,內存8GB。實驗結果表明,3 種方法均可用于發票印刷體數字識別,但準確度有差異,穩定性有高低。研究發現,通過CNN 提取特征并用于SVM 的方法準確率較高、識別時間較短,能夠很好地滿足發票數字識別要求,具有很好的通用性和魯棒性。
2.1 Tradaboost 算法實現
印刷體數字識別訓練是多分類學習過程,本文采用一對一(One-Versus-One,OVO)的算法,將印刷體數字0~9一共10 個類別兩兩配對,產生10*9/2=45 個分類器,最后由每個分類器分類結果投票產生。在算法中,弱分類器選擇二分類的SVM,迭代次數設為5,采用3 次多項式核,最終分類器為每次迭代中分類器的加權和。算法的核心在于每個弱分類器都會分配一個初始權重并隨著迭代和計算誤差進行調整。
印刷體數字圖片大小為28×28 PX,輸入SVM 的向量大小即為784×1。訓練圖片數量為61 200 個,其中60 000個來自于MNIST 手寫數字集,1 200 個為0~9 的帶有標簽的印刷體數字訓練數據。經過測試,準確率達0.967 5,訓練和測試時間共為8 244.866 7s。
2.2 Lenet-5 微調方法
相比于MNIST 手寫數字集,印刷體數字樣本數量較少。但兩種數據集是相似的,具有共同特征。Lenet-5 采用MNIST 這種大型的數據集進行訓練,本身就具備了提取事物基礎特征和整體抽象特征的能力。鑒于此,考慮采用微調辦法,可以減少訓練時間和資源,有效地提高準確率,降低出現模型過擬合、不收斂風險。
Lenet-5 是用于手寫字符識別的卷積神經網絡,準確率高、效果好。由于搜集的印刷體數字圖片大小為28×28 PX,卷積神經網絡的結構層次需要隨之改變。本實驗中Lenet-5 的網絡結構如圖3 所示。
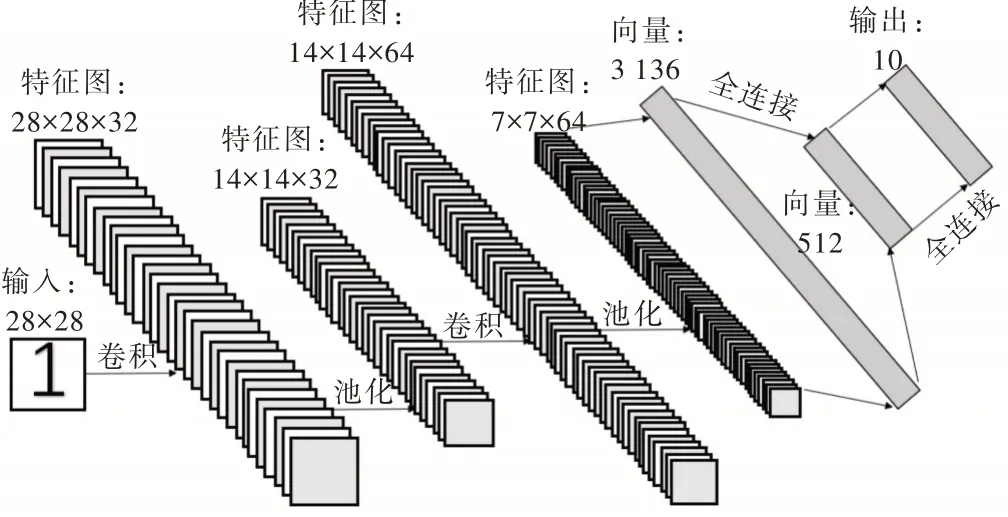
Fig.3 Lenet-5 network structure in this experiment圖3 本實驗中Lenet-5 網絡結構
第一層卷積層輸入的是原始圖像,大小為28×28×1;其輸出是第二層輸入,是一個28×28×32 的節點矩陣;第三層卷積層的輸入矩陣大小為14×14×32,第四層池化層輸入矩陣大小為14×14×64,第五層全連接層在Lenet-5 相關文獻中被稱為卷積層,但實質上與全連接層并無區別,如果將輸入矩陣中的7×7×64 的節點拉成一個向量,則輸入節點變為3 136 個,輸出節點為512 個;第六層全連接層輸出節點個數為10 個。每一層的參數個數可以用式(1)計算。

在微調中,所有層的參數都參與訓練,以達到更好的訓練效果。準備好的印刷體數字訓練集用來訓練60 次,而每一次訓練中大小設為50,通過損失函數與學習率之間的函數關系圖,學習率確定最優為5e-5。該實驗準確率經過反復測試,為0.997 5,整個實驗訓練時間達165.807 6s,測試400 個樣本的時間為0.531 1s,模型可準確且實時地給出發票單號識別結果。
2.3 卷積神經網絡提取特征并用于SVM
實驗中采取第3 種方法即在Lenet-5 提取特征后,用SVM 預測獲得結果。在構造的Lenet-5 卷積神經網絡結構中,兩層全連接層的輸入都是一個向量。向量是由Lenet-5 的特征提取器所提取到的特征,相比而言對樣本的其它變換方法更加科學,因而更不容易出現過擬合,還可以降低訓練維數。使用SVM 的優勢在于能夠解決小樣本、高維度以及卷積神經網絡容易出現局部極小值的問題。兩者優勢互補,有效減少計算復雜性,加快訓練[12]。本文選取第一層全連接輸出、長度為512 的特征向量,而原來的樣本維數是28×28=784,起到減少訓練時間的作用。對于印刷體數字識別十分類問題,SVM 依舊采取一對一策略,以二分類器的結果集成獲得最終多分類結果,核函數采用線性核。具體訓練步驟如圖4 所示。
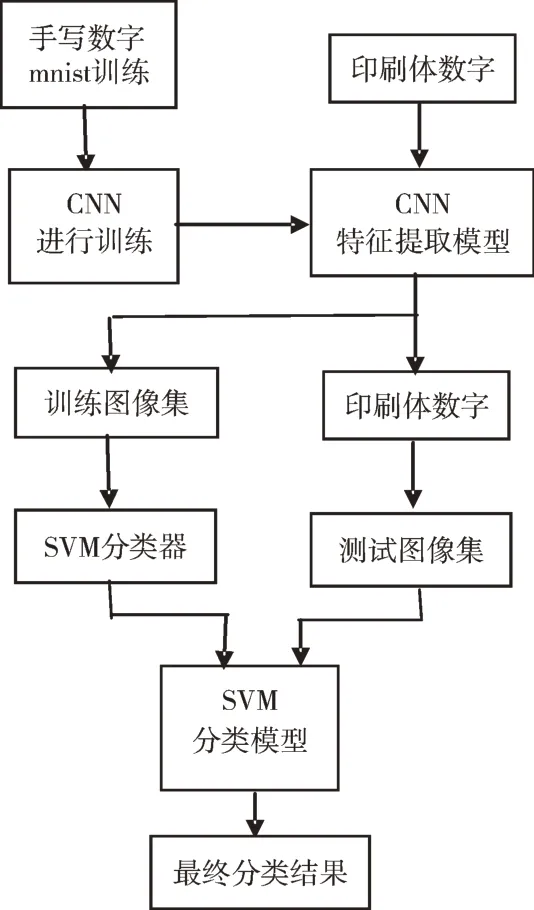
Fig.4 The specific steps of CNN feature extraction and SVM training圖4 CNN 特征提取并用SVM 訓練具體步驟
該方法達到的平均準確率為99.75%,與第二種方法微調的準確率幾近相同,但不同的是其平均訓練時間為0.900 2s,遠遠小于后者,當輸入測試樣本時,測試時間也僅為0.303 3s。這樣的反應速度能夠決定發票識別系統的實時性,再結合其準確度高、魯棒性好的優勢,符合系統既定目標。經過分析發現,在小樣本訓練集的情況下,這種方法優勢更加明顯,且特征提取更加科學,能在SVM 中發揮重要作用。
3 結語
本文主要實現并比較了3 種運用在發票數字識別上的遷移學習算法。在工作前期搜集發票圖片,進行一系列預處理步驟,獲取到用于訓練的發票數字數據集,高可靠度在一定程度上提高了數字識別效率。此外,經過大量測試發現,Tradaboost 算法準確率略低于其它方法;Lenet-5的微調算法準確率高,但訓練時間和識別時間較長。而運用卷積神經網絡Lenet-5 提取發票數字的特征并用于SVM進行訓練的方法,其準確度高、穩定性和實時性好,具有良好識別效果,這種算法適合用來構建一套完整可靠的發票數字識別系統。本實驗靈活運用了各種適用于小樣本數據集的遷移學習方法,在訓練集樣本數量較小的情況下,結果已經較優。下一步將擴大訓練集,使模型具有較好穩定性和更高準確率。
