基于機器學習的軟件運行缺陷檢測方法研究
2021-06-27 03:25:58呂靜賢吳子辰王晨飛
電子設計工程 2021年12期
呂靜賢,韓 維,吳子辰,王晨飛,徐 胤
(1.國家電網有限公司客戶服務中心信息運維中心,天津 300300;2.國網江蘇省電力有限公司信息通信分公司,江蘇 南京 210009)
針對軟件運行缺陷檢測方法的研究,傳統方法采用一種基于秩和檢驗的算法,該算法首先收集訓練集和檢測樣本集的特征信息,分析出不同特征間的差異,并在開放源碼系統中進行實驗,由分布特征得到的相似性權重與不對稱誤分類的代價密切相關[1]。通過效應值A-統計檢驗來評價檢測程度,評價顯著性檢驗采用Wilcoxon 秩和檢驗方法,由檢驗結果可知,該方法檢測變量在目標工程上的分布差異較大,無法達到較高的檢測精度[2]。使用靜態軟件缺陷檢測方法時,先根據不同實際應用場景設定軟件模塊的粒度,并從已標記的軟件歷史倉庫中提取出相應的實例;其次,基于相關信息提取并分析軟件開發過程和軟件源代碼的特征,設計一種能有效反映軟件缺陷屬性的缺陷測量儀,利用缺陷測量儀設計一組軟件,并構造一組軟件缺陷檢測數據;最后,利用預處理方法構造缺陷檢測數據集,并在應用階段進行測試。
針對不同的應用場景,上述方法受數據集噪聲影響較大,檢測精度較低。為解決傳統方法中存在的問題,提出了一種基于機器學習的軟件運行缺陷檢測方法。
1 軟件運行缺陷聯合表示分類
軟件運行缺陷聯合表示分類需先對無缺陷訓練數據集進行采樣,以構建類別平衡訓練數據[3];然后通過聯合表示法構建基于聯合表示分類的學習器,獲取樣本數據;最后,設計分類流程[4]。
1)采樣
構建不同度量元特征向量最近鄰圖,在兩個度量元特征向量中增加一條結點變換曲線,計算鄰圖中的權重矩陣:

式(1)中,ai、aj分別表示兩個度量元特征向量;λ表示常量[5]。通過權重矩陣可構建一個數據空間局部結構,利用該權重估計無缺陷訓練數據集中候選軟件局部保留能力,只有少量度量元特征選入新構建的平衡訓練集中,使采集樣本平衡化[6]。
2)分類

式(2)中,‖y-Fg‖2表示類殘差[7-8]。令:
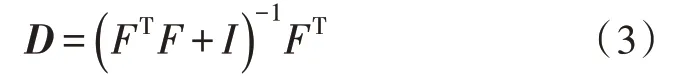
式(3)表示聯合投影矩陣,由于D獨立于y,所以可將其作為一個投影矩陣計算出來[9]。由于類殘差具有一定的鑒別能力,因此可計算每個類的正則化殘差值:

根據不同類的正則化殘差值,可將軟件缺陷樣本分配到最小正則化殘差值所對應的類[10-12]。
2 軟件運行缺陷檢測

采用施瓦茨信息準則:

聚類是在全局范圍內搜索的,具有良好性能,但對數據噪聲較敏感,如果數據存在噪聲,則將導致聚類不合理[16]。
數據集中所有樣本都是0~1 之間的模糊數值,屬于不同聚類形式,最終優化目標函數為:

其賦值計算公式為:

更新計算公式為:

為了消除依賴,將所有有缺陷模塊作為異常情況進行處理,如果所有屬性都小于其相對應的閾值,則該軟件模塊是無缺陷的;反之,如果所有屬性都大于相對應閾值,那么該軟件模塊是有缺陷的[17-18]。
3 實驗分析
為了驗證所提方法的有效性,進行了對比實驗。所研究的基于機器學習的軟件運行缺陷檢測方法使用Python 語言來實現,方法中涉及的來源包括baksmali.jar、androguard。在檢測方法有效性時,對現實軟件中收到的800 個非惡意程序進行檢測。實驗系統主機內存為4 GB,處理器型號為Intel Core i5-2400,開發環境為Ubuntu 15.10。
3.1 評價指標
以表1 所示分類檢測結果作為評價指標。

表1 評價指標
真正例與總例的比值即為查準率,計算公式為:

檢測總例與正例比值為查全率,計算公式為:

3.2 實驗數據集
使用10 個開源數據集,分別為Ar1~5、JEdit4.0、JEdit4.2、JEdit4.3、Ant1.7、Tomcat6.0。這些數據來自于某家白色家電制造商嵌入式軟件,其中包含了30維向量,數據集中的軟件實體是否存在缺陷類別是已知的。在對這些數據集分析的基礎上,降低軟件實體特征集維數,確定相關軟件度量。表2 描述了實驗過程中使用的數據集。

表2 實驗過程中使用的數據集
數據集困難程度是衡量數據集分類任務的一個指標,當缺陷數據集分類難度高時,區分存在缺陷和無缺陷軟件實體更難。由表2 可看出,所有數據集都是不平衡的,存在缺陷實例數量要小于無缺陷實體數量。從缺陷分類角度分析,JEdit4.3 和Tomcat6.0 是分類最難的數據集,由于其難度較高,因此,在數據集中所占比例較小。
3.3 實驗結果與分析
對包含所有數據集的每一對特征進行檢查,檢查結果如圖1 所示。
圖1 AUC曲線
該曲線經過(0,0)、(1,1)這兩個點時,AUC 值是被曲線包圍的下方面積,AUC 值越大,數據屬性就越穩定。由曲線可確定軟件度量之間的依賴關系,得到p-values(1%×1%)都小于0.000 1,從而在顯著性水平為0.01(檢驗要求較高時,要求顯著性水平小于0.01)時,確定不同缺陷特征統計的依賴關系。
對于真正例、假正例、假負例、真負例、查準率、查全率進行分析,結果如表3 所示。

表3 10個數據集檢測
在10 個數據集中,查準率和查全率均高于0.95,這說明基于機器學習的軟件運行缺陷檢測方法性能較好。
4 結束語
基于機器學習的軟件運行缺陷檢測通過分析歷史數據、提取軟件特征建立缺陷檢測模型,進而挖掘軟件中隱藏的缺陷。軟件運行缺陷檢測主要分為兩個部分,首先是數據的處理,該方法主要通過對數據集中影響訓練結果的特征進行提取,去除不相關和冗余特征,減少噪聲數據對訓練結果的影響;其次是模型的訓練,在待測測試數據集上應用訓練好的模型,使模型能夠根據測試數據集檢測軟件系統中的缺陷。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
