一種有效的困難樣本學習策略
2021-07-01 13:21:26蔡曉東
西安電子科技大學學報 2021年3期
關鍵詞:方法
曹 藝,蔡曉東
(桂林電子科技大學 信息與通信學院,廣西壯族自治區 桂林 541004)
哈希學習[1]大致分為非監督哈希和監督哈希。在監督哈希學習中,使用深度神經網絡相對于一些手工設計的哈希算法能獲得更好的效果。大部分深度哈希算法都采用相似性保留算法,該方法包括單對相似性保留、多對相似性保留、隱式相似性保留。基于單對相似性保留的方法[2-6]通過計算兩個樣本的距離來學習樣本的相似性信息。也有一些通過其他方法[7-10]進行哈希特征學習和量化的工作。基于深度神經網絡的單對相似性保留方法在學習過程會產生兩個方面的問題。
一方面,存在一些很難被正確學習的困難樣本導致模型準確性下降,如何有效地學習到困難樣本的特征信息成為一個棘手的問題,在線困難樣本挖掘算法[11]是其中一種簡單有效的方法。它通過找到困難樣本,組成新的訓練批次進行訓練,但延長了訓練時間。相對于文獻[11],文獻[12]提出了Focal Loss損失函數設計機制,通過給困難樣本大權重來控制損失,該機制使用了更少的前向傳播次數并進一步提升了訓練效率。此機制被用到了深度哈希領域[2],但是該機制在處理不同的問題上缺乏泛化能力[13-14]。
另一方面,在訓練樣本數量不平衡的情況下,過量的困難樣本會造成模型收斂偏移,從而降低模型的準確性[15]。在處理訓練樣本不平衡的問題時主要有兩種方法:一種是改變樣本的分布,通過采樣(重采樣或欠采樣)改變訓練樣本數量或通過數據增強如旋轉、鏡像、混合訓練,或者生成對抗網絡等生成偽樣本來提高稀少樣本的多樣性。另一種是修改訓練方法,文獻[4]分別給正負樣本損失函數加權,提高正樣本的收斂速度,降低負樣本對模型的影響,從而達到學習平衡。但是,這些方法都沒有考慮到困難樣本對不平衡訓練造成的影響。進一步地,文獻[16]提出的三元損失函數,每次只選擇一組同類樣本和一組不同類樣本進行訓練,真正達到了嚴格的平衡,算法通過閾值區分困難樣本、半困難樣本和簡單樣本。但是,該方法只選擇困難樣本進行訓練,忽略了不平衡分類中困難樣本過量帶來的噪聲問題。
樣本的損失表示該樣本被網絡模型正確識別的程度,可以很好地區分出困難樣本,從而調整網絡模型的反饋梯度,對困難樣本進行深度學習。根據這種思路,筆者提出一種通用的困難樣本特征學習策略——損失到梯度,包括兩種具體方法:① 一般情況下,提出一種非均勻梯度歸一化方法,依據困難與整體樣本損失的比例,對整體樣本反向傳播梯度進行加權計算,提高模型對困難樣本的深度學習能力;② 對存在過量困難樣本的情況,設計了一種加權隨機采樣方法,根據損失值對樣本排序后進行加權欠采樣,對被采樣的樣本保持原有的梯度,其余樣本的梯度置零,從而既可以降低噪聲干擾,又可以保留少量的困難樣本,提高了模型的準確性。
1 損失決定梯度策略
在處理哈希特征學習問題時,文中采用與文獻[6]方法相同的網絡框架,包括5個卷積層和3個全鏈接層,全鏈接層輸出后連接tanh激活函數,將神經元的值域映射到(-1,1),經過激活的特征稱為哈希特征,公式表達為U={u1,u2,…,uk},k表示特征序列的維數。通過成對損失函數和量化損失函數進行特征學習。然而,在原框架中這兩個損失函數導致模型對困難樣本的學習能力不足,其中成對損失函數還存在訓練樣本數量不平衡的問題。
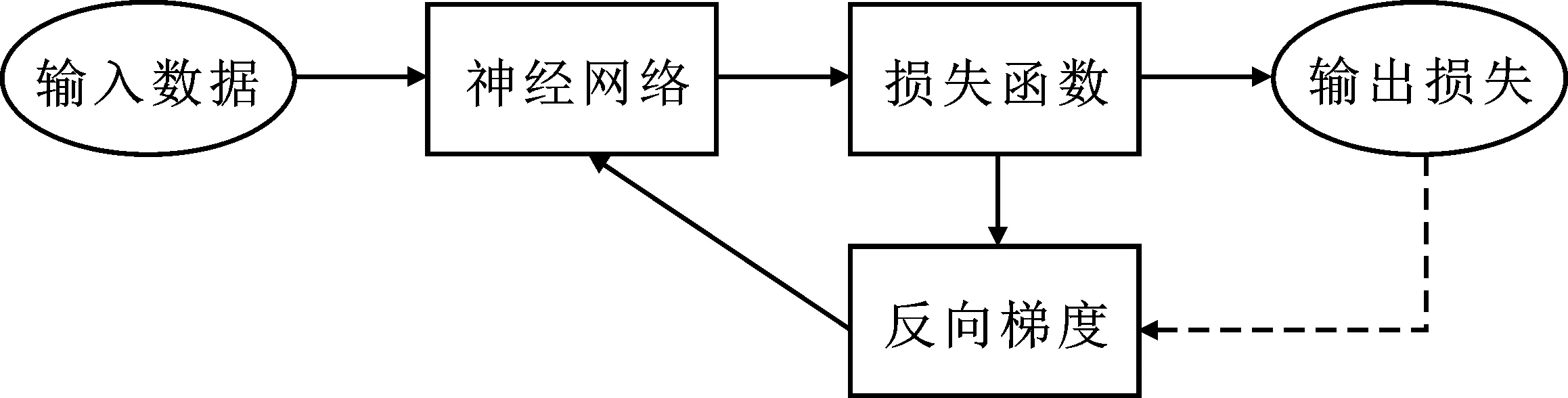
圖1 損失決定梯度策略示意圖:由虛線表示
傳統神經網絡使用梯度下降法將訓練樣本的損失最小化,這是一種梯度到損失的過程;然而這個過程只對整個網絡進行優化,無法對個別困難樣本進行優化。為了通過對困難樣本特征的學習提升網絡的性能,基于困難樣本的損失值較大的特點,筆者提出一種通用的特征學習策略,稱為損失決定梯度策略,如圖1所示。它與傳統的梯度到損失的策略相反,通過損失進行動態的梯度調整,實現對困難樣本的學習。將該思想應用于文獻[6]方法中的這兩個損失函數的優化。
1.1 非均勻梯度歸一化
為了讓網絡更加容易收斂,損失函數在計算每個樣本反向梯度時,通常會對梯度進行歸一化處理。定義損失函數為
Li=L(Xi),
(1)
(2)
其中,Xi表示輸入神經元的值,Yi表示神經元Xi的反饋梯度值,Li表示神經元Xi損失值,ω表示該損失函數在網絡該損失函數訓練時的權重,1/B表示歸一化項,B表示當前批次的大小。
由于歸一化項的存在,在網絡收斂之后,簡單樣本雖然可以被很好地量化,損失值接近于0。但是每個批次都會或多或少地存在一些沒有被很好量化的困難樣本,它們的損失值依舊很大,梯度也被當前批次里面的大多數簡單樣本稀釋,導致模型錯誤地認為當前批次的所有樣本都得到了良好的處理。文中提出一種改進的非均勻化梯度歸一化方法,具體方法如下:
(1) 計算每個樣本損失值在整體損失中的占比,得到樣本m的損失率
(3)
其中,Xim表示第m個樣本的第i個神經元的值,m∈[1,B],i∈[1,K],K表示哈希特征的位數。
(2) 定義樣本的權重項公式為
(4)
其中,γ>1,表示網絡對樣本m的關注程度,γ越大,該樣本被反饋的梯度越多。困難樣本在訓練過程中有較大的Lim,對應的W(Xm)也較大。
(3) 使用權重項W(Xm)替換梯度歸一化項1/B,得到新的梯度計算公式為
(5)
根據上述方法,對簡單樣本和困難樣本的權重W(Xm)進行非均衡增加處理,這使得網絡模型減弱了對簡單樣本的學習,增強了對困難樣本的學習能力。
1.2 加權隨機采樣
在訓練樣本數量不平衡的情況下,負樣本中大量的困難樣本給訓練帶來了噪聲,影響分類效果;如圖2所示,三角形和圓形代表兩類樣本。決策線隨著噪聲樣本的增加產生偏移,最終產生了與平衡分類情況下不一樣的決策結果。
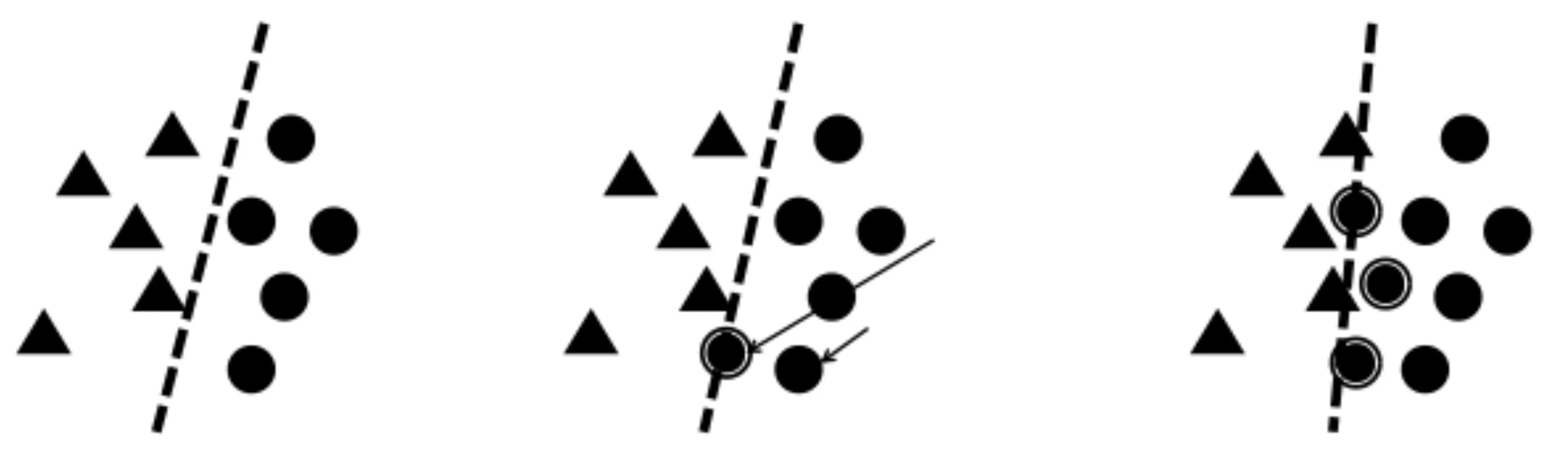
(a) 平衡分類情況 (b) 困難樣本增加 (c) 過量的困難樣本
為了排除不平衡分類中噪聲樣本對模型的干擾,筆者提出一種加權隨機采樣的方法,分別降低和提高負樣本中噪聲樣本和正常樣本的采樣比例,同時保留少許困難樣本,避免簡單樣本過擬合,提高模型的準確性。具體方法如下。
(1) 假設存在樣本集合Ω,可表示為
(6)
Ω表示成對損失函數中產生的異類樣本集。式中,nb表示樣本集數量,nb=(B2-na),B表示一次迭代的訓練樣本數量,na表示同類樣本數量,na遠遠小于nb。
(2) 通過成對損失函數計算Ω中所有樣本的損失值,并對計算結果進行從小到大排序。在這里,一個樣本表示兩張圖片p與圖片q的哈希特征Up與Uq的點積。
(3) 定義采樣函數為
(7)
其中,δ為狄拉克函數。在文中,定義采樣函數的目的是從nb個負樣本中挑選na個樣本作為正常的訓練負樣本,將其余負樣本的損失與反向梯度置零。
(4) 定義隨機采樣函數為
(8)
其中,rand(0,1)表示隨機生成一個0到1的浮點型小數,int表示向上取整操作。隨機采樣函數能等比例地在Ω內進行均勻采樣,但這會帶來噪聲樣本的干擾。
(5) 定義加權隨機采樣函數為
(9)

圖3 權重函數中參數a的圖示
其中,w(x)稱為權重函數,w(x)=xa,a稱為稀疏度。通過調整a的大小,可以控制算法對Ω特定區域的采樣比例。如圖3所示是a=2時的情況。以x∈(0,0.5)為例,函數y=x對應的值域為(0,0.5),而函數y=x2對應的值域為(0,0.25),這意味著對(0,1)的范圍進行隨機采樣時,函數y=x有50%的概率采樣到前50%的樣本,而函數y=x2有50%的概率采樣到前25%的樣本,y=x2相比于函數y=x采樣比例更向前集中。通過這個特性,算法可以減少對噪聲樣本的采樣比例。噪聲樣本通常具有較大的損失值,所以噪聲樣本排在樣本序列的尾端,當a∈(1,+∞)時,算法有大概率采樣到樣本序列的前面部分,減少對末端的采樣,從而達到減少噪聲樣本干擾的目的。
2 實驗結果與分析
實驗使用的深度學習框架為Caffe,操作系統是Ubuntu16.04 LTS,硬件配置為Intel?CoreTMi5-6400 CPU @ 2.70GHz×4,GeForce GTX 1070/PCIe/SSE2,測試代碼編譯環境為Qt creator。
2.1 數據庫
文中使用CIFAR10和SVHN圖像數據庫進行實驗,并使用ImageNet數據庫進行預訓練。樣本圖像訓練時被縮放到256×256像素,并隨機裁取227×227像素大小的圖像進行訓練,每個訓練周期需要對訓練樣本進行亂序。
CIFAR10數據庫共60 000張圖片,圖片大小為32×32像素,共10個屬性。筆者在每類屬性中隨機選取100張圖片作為檢索圖片,共1 000張,再選取500張圖片作為訓練樣本,共5 000張,剩下的54 000張圖片作為被檢索的數據庫。
SVHN數據庫共分成3個部分:訓練庫、測試庫、額外庫,共640 440張圖片,圖片大小為32×32像素,共10個屬性。文中只使用訓練庫和測試庫,共105 289張圖片;每類屬性隨機選取100張圖片作為檢索圖片,共1 000張;角類屬性再選取500張圖片作為訓練樣本,共5 000張;剩下的99 289張圖片作為被檢索的數據庫。
2.2 測試結果與分析
筆者通過計算哈希特征值的漢明距離來評價圖片之間的相似度。為了保證算法評價的客觀性,實驗采用與文獻[6]相同的評價標準,包括平均精度均值(Mean Average Precision,MAP),精度召回曲線(Precision-Recall curves,PR),漢明距離為2的精度曲線(Precision curves within Hamming distance 2,P@H<=2),以及不同頂部召回樣本數的精度曲線(Precision curves with respect to different Number of top returned samples,P@N)。筆者將提出的新策略應用在文獻[6]框架上,并將最終結果與文獻[2]、文獻[4]、文獻[5]、文獻[6]等目前流行的深度哈希方法進行比較。
如表1所示的是不同哈希特征長度在CIFAR10與SVHN數據庫上的平均精度值對比。可以看到,在CIFAR10上,筆者提出的方法在文獻[6]框架的基礎上,分別約提高了2.2%、4.7%、4.6%、4.8%,在SVHN上,筆者提出的方法在文獻[6]框架的基礎上,分別約提高0.1%、0.3%、1.8%、3.4%。
如圖4、5所示是另外3種評價標準在3個數據庫上的測試結果。可以看到,在P@H<=2的評價標準中,筆者提出的方法都處于較高水平。在PR標準中,各種方法的差距不是太大,但不同數據庫下不同方法的效果也不同,筆者提出的方法處于中間水平。在P@N標準中,筆者提出的方法在CIFAR10上與文獻[2]方法相似,在SVHN上處于較高水平。
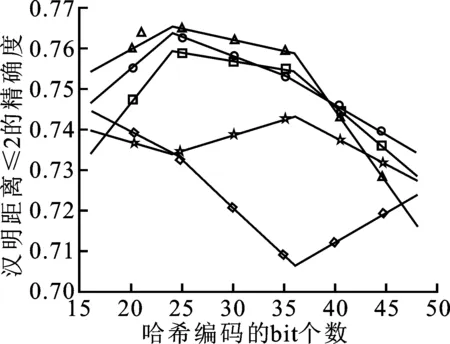
(a) P@H≤2

(b) PR

(c) P@N

(a) P@H≤2

(b) PR

(c) P@N
2.2.1 非均勻梯度歸一化方法擴展實驗
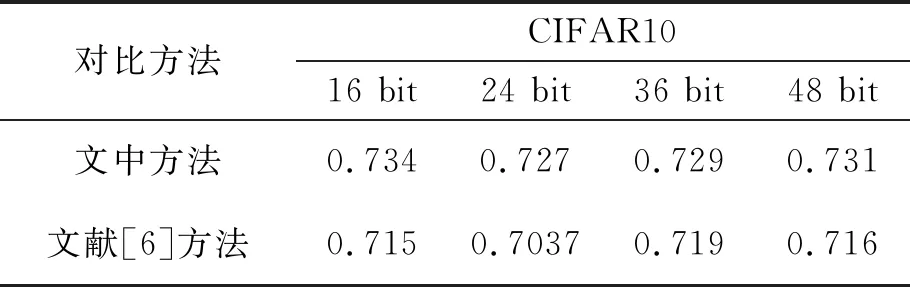
表2 非均勻梯度歸一化對哈希特征學習的影響
為了證明非均勻梯度歸一化方法的有效性,單獨測試了該方法對實驗結果的影響,如表2所示是在文獻[6]框架的基礎上只增加該方法,對應不同哈希特征長度在CIFAR10數據庫的平均精度值。實驗表明,該方法能給文獻[6]框架帶來約1.9%,2.3%,1.0%,1.5%的平均精度值提高,說明該方法在處理困難數據學習問題是有效的。

表3 非均勻梯度歸一化對分類學習的影響
同時,為了證明非均勻梯度歸一化的通用性,文中將該方法應用在圖像分類問題上。使用文獻[6]的網絡模型,使用Softmax損失函數學習圖像特征。在CIFAR10和MNIST數據庫中隨機選取5 000張訓練集樣本和1 000張驗證集樣本。如表3所示,可以看到,增加該方法后,網絡的驗證平均精度在CIFAR10和MNIST上分別約提高了1.9%和0.6%。將MNIST特征數據映射到二維平面,10個數字的分布如圖6所示。可以看到,普通的Softmax損失函數,類內距離比較大。在Softmax損失函數中應用該方法后,類內特征分布更加密集,說明該方法在常用損失函數中也能起到提升作用。

(a) 基于傳統Softmax的手寫字體分類

(b) 文中改進后的手寫字體分類
2.2.2 加權隨機采樣方法擴展實驗

表4 加權隨機采樣對哈希特征學習的影響 (平均精度)
為了證明加權隨機采樣方法的有效性,文中單獨測試了該方法的效果,并對比該方法與其他幾種采樣方法在處理不平衡數據采樣時的效果。如表4所示,在文獻[6]框架的基礎上增加了該方法后,不同哈希特征長度在CIFAR10數據庫的平均精度。結果顯示,該方法在文獻[6]效果的基礎上,分別提高了1.9%,4.8%,2.9%,3.6%,說明它在處理不平衡數據問題上的有效性。文獻[4]方法是僅保留不平衡數據處理機制的方法。文中方法比文獻[4]方法的AP分別高出0.6%,2.0%,1.2%,0.6%,說明有針對性地減少豐富類困難樣本數量,比降低整體豐富類樣本權重更有效。

表5 不同采樣方法對檢索效果的影響
為了證明加權隨機采樣中“加權”的必要性,文中對幾種不同采樣方法進行測試。這些方法分別是:在不平衡訓練樣本集中,對豐富類樣本進行全為簡單樣本采樣、全為困難樣本采樣、隨機采樣、加權隨機采樣。表5所示是CIFAR10數據庫上特征長度為48 bit的哈希特征檢索平均精確度。實驗表明,僅使用困難樣本訓練,模型平均精度會維持原來的。相反,僅使用簡單樣本訓練,模型不會收斂,平均精度很低。使用隨機采樣樣本訓練,正負樣本數據平衡,能得到比原始模型更好的效果;在此之上,使用加權隨機采樣,減少對困難樣本的采樣,能進一步提升模型準確率。
3 結束語
針對深度哈希算法中困難樣本不收斂、產生噪聲干擾等問題,筆者提出了基于損失決定梯度的困難樣本學習策略。通過計算樣本的損失值控制困難樣本的反饋梯度,提高模型對困難樣本的學習能力。同時,通過損失值排序對不平衡數據中的樣本進行加權采樣,構造均衡的訓練數據集。實驗表明,相比于目前流行的深度哈希算法,筆者提出的改進算法在圖像檢索效果上有明顯的提高,為困難樣本學習問題提供了新的思路。如何自適應地選取困難樣本與簡單樣本的訓練比例,達到最佳的模型效果,將成為下一步的研究目標。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
