基于改進的Faster RCNN面部表情檢測算法
2021-07-05 10:53:48伍錫如凌星雨
智能系統學報 2021年2期
伍錫如,凌星雨
(桂林電子科技大學 電子工程與自動化學院,廣西 桂林 541004)
面部表情包含了豐富的信息,直接反映了人 們的心理特征,是表達情感的重要途徑之一。面部表情檢測可應用于人機交互、安防監視、醫療及認知科學等多個領域,是計算機視覺研究熱點之一。面部表情的表達通常分為憤怒、厭惡、恐懼、開心、悲傷和驚訝6類[1-2]。面部表情檢測任務的重點是從面部圖像中提取面部表情特征,并使用經過訓練的分類器識別不同的面部表情。傳統的表情識別依賴手工提取特征,特征提取方法主要分為3類:基于外觀的特征提取、基于幾何的特征提取和基于運動的特征提取。常用的外觀特征提取包括像素強度[3]、Gabor濾波[4]、局部二值模式LBP(local binary patterns)[5]及方向梯度直方圖[6],其中Gabor特征提取計算成本高昂,而LBP具有良好性能,被廣泛用于面部表情識別[7-8]。在基于幾何的特征提取方法中,提取人眼、眉毛、嘴角等面部器官的位置和形狀,形成能夠代表人臉幾何的特征向量[9-10]。基于運動的特征提取方法提取動態圖像序列為運動特征,根據特征部位的運動變化對面部表情進行識別[11-12]。由于光照變化、遮擋等多種因素,表情識別仍具有挑戰性[13],這些因素會影響識別精度,手工提取特征不適用于具有干擾的面部表情檢測任務,深度學習的提出為這些問題提供了解決方案。
深度學習概念由Hinton在2006年提出[14-15],比傳統的網絡具有更強的特征表達能力和泛化能力,近幾年在面部表情檢測中得到大量應用。如Yang等[16]使用VGG16網絡及DNN(deep neural networks)形成雙通道對不同特征進行提取來完成表情識別。Wu等[17]使用遺傳算法優化神經網絡來進行表情識別任務。Salmam等[18]使用CNN(convolutional neural networks)提取外觀特征,使用DNN提取幾何特征點,合并為CNN-DNN模型進行表情識別任務。
在目標檢測任務中,Girshick[19]提出的RCNN(Region-CNN)方法是目標檢測中重要的參考方法,目標檢測系列算法很多都借鑒了R-CNN的思路。R-CNN模型是將目標區域建議與CNN分類相結合,使用Selective Search算法在輸入圖像中提取2 000個候選區域,經過CNN網絡進行特征提取,通過訓練好的分類器來判斷候選區域中是否含有目標,再使用回歸器對候選框進行調整。Girshick等[20]結合SPP-net網絡的思想對RCNN進行了改進,提出Fast R-CNN模型。相比R-CNN,Fast R-CNN對整幅圖僅進行一次特征提取,再與候選框映射,避免候選框重復提取特征而浪費時間。Fast RCNN采用Softmax分類與邊框回歸一起進行訓練,省去特征存儲,提高空間和時間利用率,同時分類和回歸任務也可以共享卷積特征。Ren等[21]提出用深度學習方法來進行區域建議即區域建議網絡RPN(region proposal network),把RPN與Fast R-CNN結合,形成新的網絡模型Faster RCNN,提高整體檢測性能。
針對多目標復雜場景下的面部表情檢測問題,本文創新性地引入Faster RCNN網絡對面部表情進行識別及定位。根據表情檢測特點在Faster RCNN網絡框架基礎上進行改進,使用密集連接網絡代替原有特征提取模塊,提取融合目標多層次特征,使特征更具表達力。采用Soft-NMS替換原有候選框合并策略,設計衰減函數提高目標框定位精度。采集制作真實環境下的表情數據集,通過訓練最終實現野外環境下各表情的識別與定位,在精度上取得了很好的效果。
1 Faster RCNN網絡結構
Faster RCNN是目前主流的二階段檢測網絡,是由RPN和Fast RCNN合并而來,每一階段的網絡都可以輸出檢測類別與邊框定位,以網絡結構分析,Faster RCNN網絡可以分為3個部分,基礎特征提取網絡、區域建議網絡RPN和Fast RCNN檢測網絡,算法的具體步驟如下,算法框架如圖1所示。
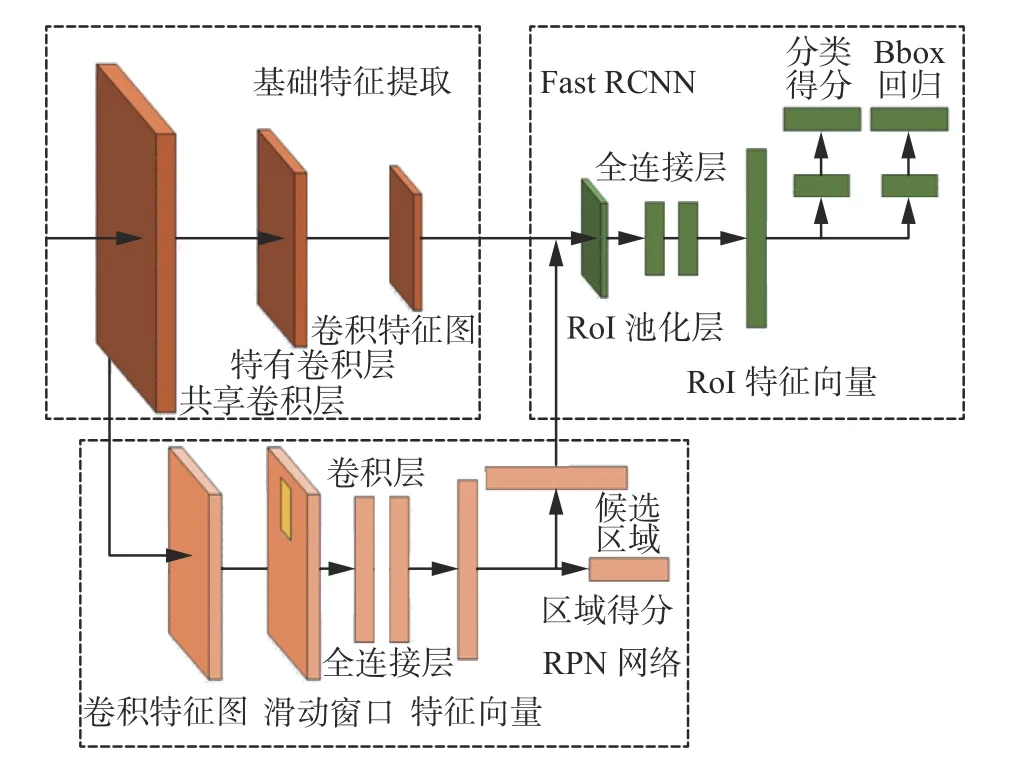
圖 1 Faster RCNN網絡結構Fig. 1 Faster RCNN architectures
1.1 特征提取網絡
特征提取網絡部分由卷積神經網絡CNN構成,CNN基本結構包括卷積層、池化層、全連接層及softmax分類層。使用不同的CNN會對檢測精度、檢測時間等造成不同的影響。
Faster RCNN常采用的特征提取網絡有3個,分別是ZFNet、VGG-16、ResNet,其中1)ZFNet[22]是在AlexNet的基礎上進行細節改動,減少卷積核數量及步長大小,保留更多的特征,從中也可推理出網絡深度增加,網絡特征提取性能越好,特征提取效果也越優秀;2)VGG-16[23]驗證了卷積神經網絡深度與性能之間的關系,通過反復堆疊3×3的卷積核與2×2的最大池化層而來。VGG-16網絡結構簡單,特征提取效果好,但是參數大,訓練的特征數量多,對硬件要求高;3)ResNet[24]又稱為殘差網絡,設計一種殘差模塊,解決網絡深度增加時帶來的梯度消失問題,實現單位映射之間的連接路線,能夠提取目標更深層次的特征,實現很好的識別效果。
1.2 區域建議網絡RPN
RPN用來提取候選區域,結構如圖2。接收來自基礎特征提取網絡傳入的卷積特征圖,通過卷積核將每一個3×3的滑動窗口(sliding window)卷積成為256維的特征向量。對每一個滑動窗口通過1×1的卷積輸出為兩個全連接層,即邊框分類層cls layer(box-classification layer)和邊框回歸層reg layer(box-regression layer)。cls layer輸出屬于前景和背景的概率,reg layer輸出預測區域的中心點坐標:x,y和長寬:w,h4個參數。滑動窗口中心對應的感受野來判斷是否存在目標,由于目標長寬大小不一,以16為基準窗口大小,通過(8,16,32)3種窗口尺度和(1∶2,1∶1,2∶1)3種長寬比生成k個anchor對特征圖進行多尺度多點位采樣。
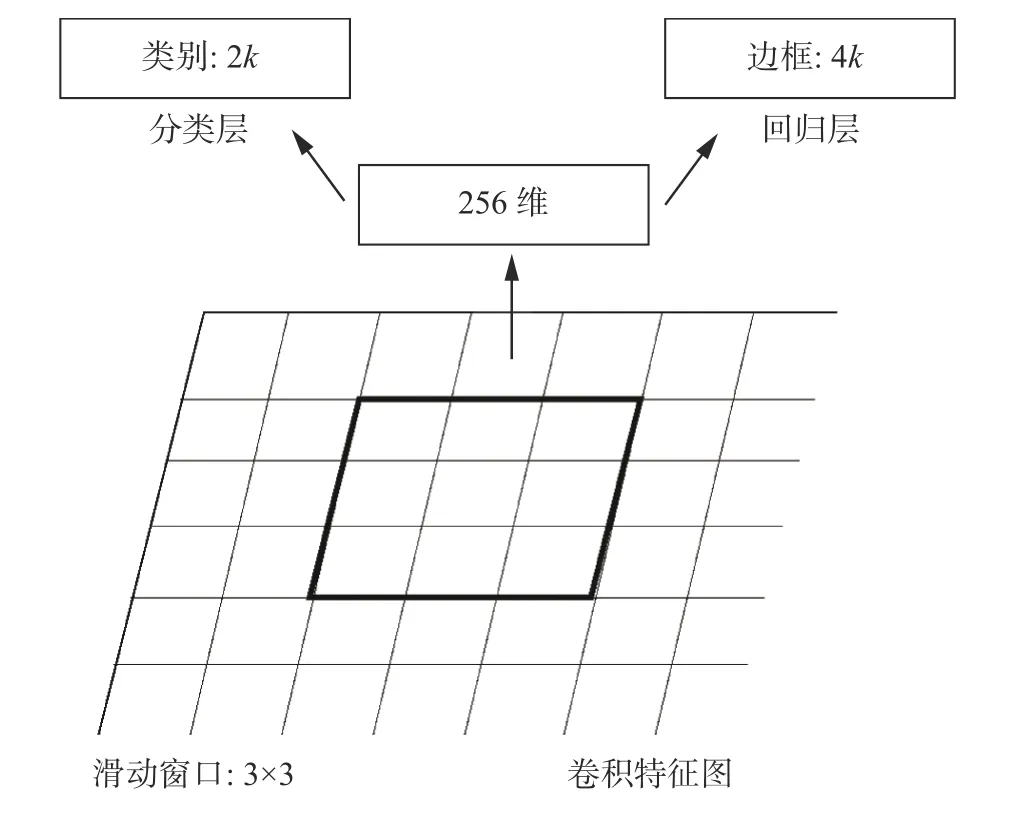
圖 2 RPN結構Fig. 2 Region proposal networks structure
RPN的損失函數定義為
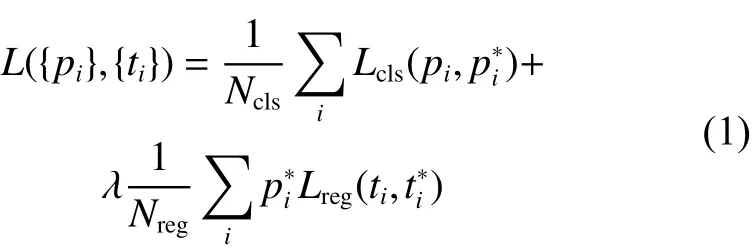
式中:角標i表示anchor的索引;pi表示每一個anchor中對應k+1類(k個類別+1個背景)的概率分布;表示是否含有目標(有目標則為1,反之為0);為mini-batch大小(一般為256);Nreg為anchor數量;λ 為平衡權重,取值為1;ti是建議框坐標 {tx,ty,tw,th};是標記框的坐標,具體參數值如下:

x、xa、x*(y, w, h同理)分別表示建議框、anchor框和標定框的位置參數。
分類損失Lcls是目標和非目標的對數損失:

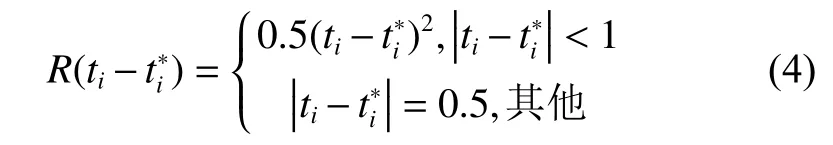
RPN通過損失函數對邊框進行回歸,并對檢測器輸出的預測框進行非極大值抑制方法合并,作為輸入連接到Fast RCNN中。RPN產生的候選區域與特征提取網絡輸出的特征圖相映射,ROI池化層對于不同大小的候選區域輸入都能得到固定維度的輸出,再通過cls layer和reg layer得到最終的結果。
2 改進的Faster RCNN
2.1 密集連接網絡
采用更深的特征提取網絡能夠提取更深層次的語義信息,但是隨著網絡加深,參數不可避免地加大,這給網絡優化和實驗硬件帶來一系列問題,在本文的面部表情檢測算法中,單獨制作出來的數據集樣本數量少,網絡訓練容易造成過擬合,采用DenseNet密集連接網絡作為特征提取網絡可以解決上述問題。
DenseNet借鑒了ResNet的思想,與ResNet網絡不同,是全新的網絡結構。兩種網絡結構最直觀的區別在于每一個網絡模塊的傳遞函數不同。

式(6)為ResNet網絡傳遞函數,可以看出該網絡第l層的輸出是l-1層輸出的非線性變化加l-1層的輸出。而DenseNet一個網絡模塊第l層的輸出是前面所有層輸出的非線性變換集合,網絡模塊(Dense Block)如圖3所示。
每一個Dense Block內的卷積都互相連接,H表示對每個輸入使用Batch Norm、ReLU,用k維的3×3卷積核進行卷積,保證每個節點輸出同樣維度的特征圖。k表示每一層卷積輸出特征圖的厚度,相比其他網絡輸出特征圖厚度能夠達到幾百甚至上千,DenseNet整體厚度僅為32。因為網絡中每個模塊的密集連接能夠有效利用淺層與深層特征,能夠使網絡高效而狹窄,并且大幅度減少網絡復雜程度與計算量,連接節點Hl的參數如圖4。

圖 3 Dense Block結構Fig. 3 Dense Block architectures

圖 4 節點 Hl 參數Fig. 4 Node Hl parameter
本文采用4個Dense Block網絡121層作為特征提取網絡,去除全連接層和分類層,再連接RPN及RoI池化層,完成目標識別與定位。4層D ense Block結構參數如表1所示。

表 1 DenseNet結構參數Table 1 DenseNet structure parameters
2.2 非極大值抑制
非極大值抑制NMS(non-maximum suppression)是檢測流程中重要的組成部分,本質是搜索局部極大值,抑制非極大值元素。Faster RCNN會在圖片中生成一系列檢測框B={b1,b2,···,bN} 和對應的檢測框得分集合Si,NMS算法將選出最大得分前的物體檢測流程中的檢測框M,與其余的檢測框進行重疊度IoU(Intersection over Union)計算,如果計算結果大于設定閾值Nt則此檢測框將被抑制。NMS算法公式如下:
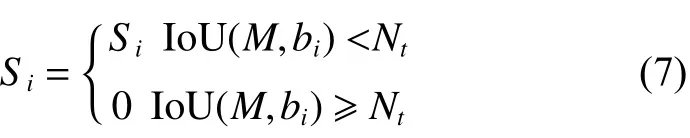
式中IoU計算公式如下:
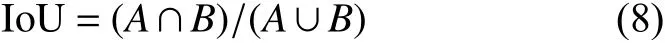
其中A、B為兩個重疊的檢測框:
從式(7)中可以看出NMS算法會將與檢測框M相鄰并大于閾值的檢測框歸零,如果一個待檢測目標在重疊區域出現,NMS算法則會導致該目標檢測失敗,降低檢測模型的準確率。
針對這個問題,本文使用Soft-NMS算法替代傳統的NMS算法。在該算法中,相鄰檢測框基于重疊部分的大小設置一個衰減函數而非將其分數置為零,保證相鄰目標能夠準確識別。Soft-NMS公示表示如下:
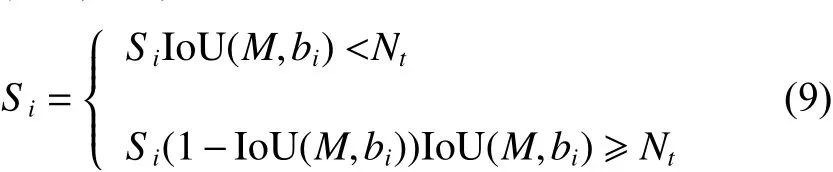
本文改進Faster RCNN檢測算法的前端特征提取網絡及末端回歸器,用于完成真實環境下面部表情檢測,算法流程如下所示:
算法 改進Faster RCNN流程
1)輸入圖像A,調整圖像尺寸,輸出為規定尺寸M×N的圖B;
2)B作為特征提取模塊的輸入,通過DenseNet得到多層次融合特征圖C;
3)C作為區域建議(RPN)的輸入,采用滑動窗口的方法得到300個proposals:D。RPN使用邊框回歸改變生成的anchors,使之更加接近標記框;
4)C與D作為感興區域(RoI)的輸入,得到建議框與特征圖之間的映射圖E。
5)把E分別輸出到分類器與回歸器兩個分支中。分類器采用Softmax對E進行分類識別,回歸器采用邊框回歸Soft-NMS進一步糾正邊框,最終 分類目標并定位。
3 實驗
3.1 數據集制作及處理
為驗證所提出Faster RCNN面部表情檢測算法的有效性,本文獨自采集憤怒、厭惡、恐懼、開心、悲傷和驚訝6類表情數據集,共4 152張圖片。
為保證檢測模型能夠完成日常生活情況下的面部表情檢測,數據具有不同的光照強度、不同的人物位姿、復雜的背景及多個目標,包含不同膚色、年齡、種族等,并對數據中50%的數據集采取鏡像擴充,50%數據集采取平移擴充,通過LabelImg軟件對數據進行標注,如圖5所示。擴充后的數據集為8 304張圖片,其中90%作為訓練集,10%作為測試集,數據集數量分布如表2所示。

圖 5 數據擴充及標注Fig. 5 Data expansion and labeling

表 2 數據參數Table 2 Data parameters
從測試數據集中挑選出困難樣本用于對比改進算法在復雜背景下的準確率。其中困難樣本的選取范圍為圖片中檢測目標多于4個,面部有光照影響,面部遮擋及側面情況。困難樣本測試數據如表3所示。在困難樣本中,部分圖像具備多個困難屬性,下文介紹。圖像存在多個人物表情且存在屬于黑夜拍攝,該圖像既屬于多目標類別樣本也屬于光照影響樣本。
考慮算法在不同環境下的有效性,本文添加日本女性面部表情JAFFE(Japanese Female Facial Expressions)數據集[25]進行對照實驗。JAFFE數據由10名女性的7種表情構成,包括6種基本情緒和一種中性情緒,總共213副圖像,原始圖像為256像素×256像素大小,數據都已經進行過裁剪和調整,人物面部居中,僅有少量光照差別,是一個質量較高的面部表情數據集。試驗選取數據集 中6類相關表情進行驗證。
3.2 實驗參數及評價指標
由于DenseNet在傳輸過程中需要融合當前階段所有特征圖,對顯存要求巨大,因此采用密集連接網絡的高效內存實現方法。提出兩個預先分配的共享內存存儲位置,存放用來連接的共享特征圖。在正向傳遞期間,將所有中間輸出分配給這些存儲器塊;在反向傳遞期間,根據需要即時重新計算更新傳遞函數。采用這種策略使得DenseNet在增加較少的計算開銷下能夠在單塊顯卡中工作。
實驗基于Tensorflow框架,采用I76 700處理器,內存為32G,顯卡GeForce RTX2080Ti,顯存為11G進行訓練。實驗數據由個人采集,有生活照、劇照等不同場景下的人物表情,并由LabelImg軟件進行人工標注。
總數據訓練迭代10萬次,批大小Batchs為64,初始學習率設置為0.001,并且在訓練時期總數的75%后設置為0.000 1。
評價指標為平均精度AP(Average-Precision),是Precision-recall(P-R)曲線所圍成的面積。在PR曲線中,P表示精確率,R表示召回率,計算如下式:

式中:TP(True positives)為正確樣本被識別為正樣本的數量;FP(False positives)為負樣本被錯誤識別為正樣本的數量;FN為正樣本被錯誤識別為負樣本的數量。AP值表示單個類別的識別準確率,越高表示網絡模型性能越好。mAP(mean Average-Preision)表示所有類別總體識別準確率,與AP值之間的關系如式(12)所示。
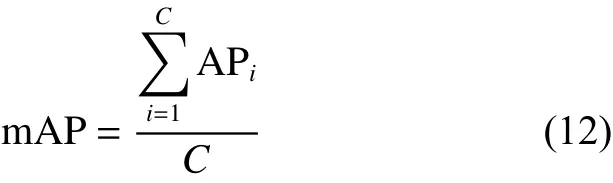
3.3 結果比較及分析
分別用ResNet和DenseNet作為特征提取網絡進行訓練,使用測試集對網絡模型進行測試,得到每類表情的AP值如表4所示,困難樣本的檢測對比結果如表5所示。
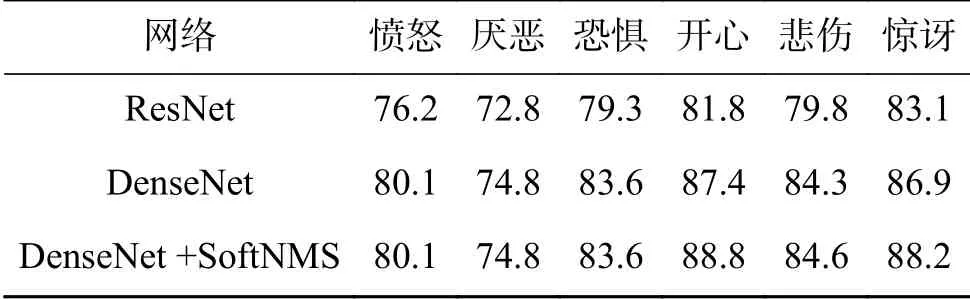
表 4 不同網絡模型的測試結果Table 4 Test results of different network models
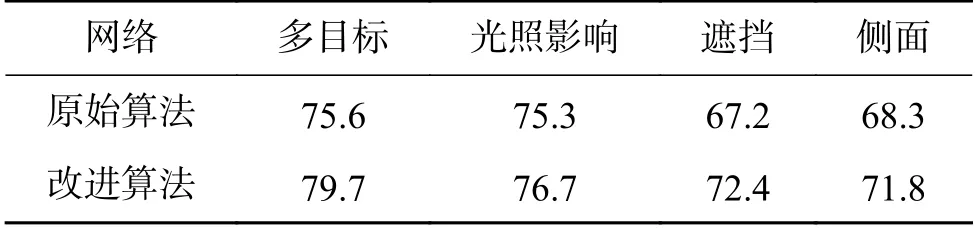
表 5 困難樣本測試結果Table 5 Test results of difficult sample
從檢測結果可以看出,采用ResNet的Faster RCNN在各類表情檢測中mAP達到78%以上,部分檢測結果如圖6所示。圖6(a)中目標特征明顯,光照充足,模型能夠達到很好的檢測結果,圖6(b)中臉部特征有部分遮擋,且含有不同表情類型,檢測效果令人滿意,而圖6(c)中存在漏檢情況,可以看出使用ResNet具有一定的檢測能力,但依舊存在一些漏檢和誤檢情況。這是因為數據量過小,ResNet無法充分訓練,在復雜情況下魯棒性不高。

圖 6 ResNet-Faster RCNN檢測效果Fig. 6 ResNet-Faster RCNN detection result
從表4可以看出采用DenseNet-121作為特征提取網絡mAP能夠達到83%,相比ResNet提高5%。其中在開心、悲傷、驚訝這3類表情中,模型檢測結果提高較多,因為這3類表情的測試集存在多目標、有遮擋及復雜背景的樣本,DenseNet能夠提取目標更多的特征,達到更好的效果。采用Soft-NMS對檢測框進行改進,準確率分別在開心、悲傷、驚訝3類存在多目標樣本的數據集中提高了一個百分點,說明Soft-NMS在多目標及目標重疊情況下能夠避免檢測框重復度高于閾值導致的候選框歸零的錯誤,達到更好的檢測效果。通過表5則可以看出,改進的檢測網絡在困難樣本中相比原版具有更高的魯棒性,其中在多目標、遮擋及側面3類樣本中提高較為明顯。采用改進Faster RCNN算法與原始Faster RCNN在多目標復雜背景下的效果對比如圖7。

圖 7 原始網絡與改進網絡對比Fig. 7 Comparison of accuracy with different backbone
圖7中選取多目標、多位姿及黑夜情況下的樣本進行檢測,第1行為原始網絡檢測結果,第2行為改進網絡的檢測結果。結果表明,原始網絡在復雜情況下普遍存在漏檢情況。圖7(b)中原始網絡出現錯誤檢測,表情類型應為悲傷,而檢測結果為恐懼。圖7(c)中出現漏檢,并且檢測框并未準確包含面部目標。對比可以看出采用DenseNet及Soft-NMS改進的Faster RCNN在檢測結果上優于原始的Faster RCNN,能夠檢測到更多的目標表情,并在相鄰目標距離過近的情況下準確地框選出獨立個體。在背景復雜及多目標情況下改進的Faster RCNN性能提高更為明顯。
考慮制作的數據集具有相似的環境特性,試驗加入JAFFE數據集來驗證網絡模型在不同環境下的檢測性能。試驗將已訓練好的網絡模型在JAFFE數據中測試,用來比較原版網絡與改進網絡在新數據集中的泛化性。將JAFFE數據的50%納入訓練集作為第3組對照實驗,對比數據集對實驗結果造成的影響,對比結果如圖8所示。

圖 8 原始網絡與改進網絡對比Fig. 8 Comparison of test results
由于JAFFE數據集為單目標高質量數據集,光照影響小、背景單一,與原數據集差異較大,因此算法的提高不如在原數據集中明顯,但依舊可以看出改進算法較原始算法具有一定優勢。將50%數據集加入訓練集后,算法模型在JAFFE數據集中性能有明顯提高,部分檢測結果如圖9所示,可以看出數據集對算法具有較大影響。如果進一步擴充數據集的多樣性,算法的魯棒性將進一步提高。

圖 9 JAFFE數據集檢測結果Fig. 9 Test results of JAFFE dataset
通過一系列實驗對比,可以看出改進的Faster RCNN算法在面部表情檢測任務中具有較高的檢測精度,同時在不同環境中具備良好的魯棒性,提高了算法的應用范圍,更有實際應用價值。
4 結束語
針對傳統表情檢測算法對于環境光線不同、背景多樣及位姿角度變化等情況下無法發揮有效作用的問題,提出深度學習表情檢測算法,以Faster RCNN為基礎改進,使用密集連接網絡作為特征提取模塊,每個模塊的密集連接能夠有效利用淺層與深層特征,提高網絡對面部表情檢測的準確率,采用Soft-NMS替換原有的NMS算法,優化候選框合并策略,使候選框更加精確。制作真實環境下的表情數據集,并進行擴充,提高訓練模型的魯棒性。本文提出的檢測算法能夠實現日常生活中的多目標面部表情檢測,在黑夜、部分遮擋、佩戴飾品等復雜情況下取得較好的精度,達到了良好的檢測效果。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
