稀疏綜合字典學習的小樣本人臉識別
2021-07-05 10:54:10狄嵐矯慧文梁久禎
智能系統學報 2021年2期
狄嵐,矯慧文,梁久禎
(1. 江南大學 人工智能與計算機學院,江蘇 無錫 214122; 2. 道路交通安全公安部重點實驗室,江蘇 無錫 214151; 3. 常州大學 信息科學與工程學院,江蘇 常州 213164)
近年來,深度學習進入蓬勃發展時代,以深度學習為基礎的圖像識別[1-3]雖然識別準確率高,但往往對硬件設備要求嚴格,具有訓練時間長達數周、樣本量需求過大等不足之處。與之相比,基于稀疏表示的圖像識別訓練簡單、對噪聲有強魯棒性,逐漸應用在社會安全、經濟工程等領域。
字典學習的目的是通過訓練樣本圖片,習得可以表示給定信號的字典和編碼,共分為有監督和無監督兩種情況。經典的無監督字典學習如KSVD[4]算法,可以有效解決高維矩陣求解問題,廣泛應用于圖像重建及圖像壓縮領域。而有監督字典學習多應用于圖像識別領域,如人臉識別、表情識別等。根據字典原子和訓練標簽之間的相關性,有監督字典學習可分為類共享字典學習、類別特色字典學習、混合字典學習3類。
類共享字典學習如文獻[5-7]等,字典和稀疏編碼由所有訓練樣本共同構造,單個字典原子可表示全體數據類別。Zhang等[8]以KSVD算法為基礎,在保證字典識別能力的基礎上引入分類誤差,提高線性分類器的分類能力。Jiang等[9]在其基礎上,增加標簽一致性術語,提出標簽一致性KSVD (LCKSVD)算法。Mairal等[10]提出了任務驅動的字典學習框架。類共享字典在保留表示數據共性的同時丟失字典原子和類標簽之間的關系,忽視了類別之間的差異性。
類別特色字典學習如文獻[11-13]等,每個字典原子對應一類標簽信息,通過類特定誤差進行分類。Wright等[14]提出基于稀疏表示的分類框架(sparse representation based classification,SRC),自此,類別特色字典廣泛應用于人臉分類器設計中。Sprechmann等[15]為每一類分別學習稀疏表示字典,Ramirez等[16]提出了一種結構非相干字典學習模型,通過最小化字典的相干項來提高字典的學習效率。Yang等[17]提出了Fisher判別字典學習(fisher discrimination dictionary learning,FDDL),其中表示殘差和表示系數都實現了判別信息。2018年,Wang等[18]結合字典學習和局部約束思想,提出FDDLLCSRC方法。同年,Li等[19]在FDDL基礎上提出IKCFDDL算法,在字典學習基礎上增添K均值聚類思想,提升算法運行效率。
混合字典即結合類共享字典與類別特色字典。Deng等[20]提出了基于擴展稀疏表示的分類方法(extended SRC: undersampled face recognition via intraclass variant dictionary,ESRC),在學習類別特色字典的同時構造類內差異字典,即共享字典。受ESRC算法啟發,2015年Li等[21]提出SCSDL算法,2017年提出CSICVDL算法[22],提取不同類別樣本中數據共性提升字典辨別力。這些混合字典學習方法在人臉識別方面表現良好,然而,在對于噪聲、異常值和遮擋等干擾情況時處理能力較差。
除上述問題以外,由于樣本數量受限,傳統字典學習習得的字典魯棒性差,不能完全表示數據組成的共性、特殊性、干擾性。針對此種情況,本文提出一種新的稀疏綜合字典學習的小樣本人臉識別模型(SCDL)。SCDL模型包括混合特色字典、擴充干擾字典以及低秩字典3項。將類共享字典與類別特色字典以及Fisher準則整合至混合特色字典模型中,在提取不同數據特殊性的同時捕捉數據之間的共性,利用擴充干擾字典和低秩字典增強模型對異常情況(如遮擋、噪聲等)的處理能力。最后,本文針對模型提出一種新的分類策略,并在受限AR人臉數據庫、YaleB人臉數據庫和非受限LFW人臉數據庫進行實驗,結果表明本文算法不僅可以取得較高分類率,并且在面對遮擋、噪聲等異常情況時較其余算法有更好的識別力和魯棒性。
1 相關工作
設定訓練數據集 A:

測試數據集合 Y :

式中:A 的每列表示一個 m 維向量;Ai∈Rm×ni為第i 類訓練數據;為訓練數據集樣本總數;y表 示單個測試樣本。
1.1 擴展稀疏表示
稀疏表示(SRC)針對測試集 Y,以學習合適的字典 D 為手段,尋找能表達 Y 的稀疏編碼 X,ESRC算法在此基礎上另學習一個類內差異字典表示訓練集 A 和測試集 Y 之間的變化,算法模型如下:
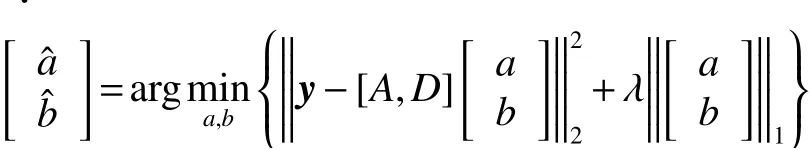
ESRC模型分為重構誤差項與正則項兩部分,正則化參數 λ >0 。稀疏編碼 a ,b 的快速求解可參考貪婪算法(如壓縮感知匹配追蹤[23]、稀疏自適應匹配追蹤[24])或凸松弛算法(如最小絕對值收 縮選擇算法[25]、最小角度回歸算法[26])。
1.2 類別特色字典學習
類別字典學習為每類數據單獨學習一個子字典,即習得的字典 D ={D1,D2,···,DK} 由 K 個子字典組成,算法模型如下:

對于單個測試樣本y,求得的稀疏系數為x={x1,x2,···,xK}。其中,Di表示第i類訓練樣本的子字典,xi由Di重構得到,重構誤差為ei=‖y-Dixi‖2。
1.3 Fisher判別準則
Fisher判別準則以投影思想為核心,目的是使同類樣本盡可能集中的同時,異類樣本盡可能疏散。
假定u0為稀疏編碼X的中心,ui表示各類稀疏編碼均值向量:

可定義類內散度矩陣Sw(X)、類間散度矩陣SB(X):

2 稀疏綜合字典學習的小樣本人臉識別算法
稀疏綜合字典學習分類方法包括訓練和測試兩大步驟,分為擴充干擾字典、混合特色字典、低秩字典三大部分,采用分步優化方法求解,充分提 取數據之間的共性、特殊性、干擾性。
2 .1 擴充干擾特色字典
2.1.1 擴充干擾字典模型
對于一張圖片a,以圖片中線為軸,如圖1所示,分別得出左鏡像圖片a1、右鏡像圖片a2、全鏡像 圖片a3。

圖 1 鏡像圖片Fig. 1 Mirror image
以a為例,對于訓練集A,求出左鏡像集A1,右鏡像集A2, 全鏡像集A3,以Fisher準則為基礎,分別計算出3個集合的類間散布系數與類內散布系數之比作為權重w=[w1,w2,w3]。
集合A′=w1A1+w2A2+w3A3。以A′為訓練集,提出擴充干擾字典模型如下:

模型分為重構誤差項、稀疏保證項和判別系數項3部分,其中,λ1>0 為正則項參數,λ2>0 為判別系數項參數。下面依次論述模型每一項原理。

2.1.2 擴充干擾字典優化
式(1)為非凸函數,其優化過程如下所示:
1) 初始化字典Db。
2) 保證字典Db固定,更新稀疏編碼B。
目標函數轉化為

使用文獻[27]中的方法求解稀疏編碼Bi∈RN×ni,γ =λ1/2。

3) 保證稀疏編碼B固定,更新字典Db。
本文逐個更新Db中的子字典,即當更新第j個子字典時,保證其他子字典Dj(i≠j) 不動,默認更新完成。


4)重復2)和3),直到前后兩次的函數 Q 的值滿足判斷條件為止。
擴充干擾字典算法總體實現步驟如下:
輸入 訓練樣本 A′,規范化參數 γ;
輸出 字典Db和稀疏編碼 B 及相應的標簽。
1)初始化字典Db。
2)固定字典Db,更新稀疏編碼 B。初始化字典后,利用式(2)依次求解。
3)固定稀疏編碼 B,更新字典Db。利用式(3)依次更新。
4)重復2)和3),直到前后兩次的函數的值滿足 判斷條件為止。
2 .2 混合特色字典
2.2.1 混合特色字典模型
對于訓練集 A 和測試集 Y,習得類共享字典Dc和由 K 個子字典組成的類別特色字典 D:D={D1,D2,···,DK}。根據Fisher判別準則,混合特色字典模型如式(4):

2.2.2 混合特色字典優化
式(4)為非凸函數,其優化過程如下所示:
1) 初始化字典D和Dc。
將訓練數據 A={A1,A2,···,AK} 的特征向量初始化為字典的原子,對字典 Dc歸一化,使其 l2范數為1;分別對字典 D 的每一類歸一化,使其 l2范數為1。
2) 保證字典 D 固定,更新稀疏編碼 X;保證字典 Dc固定,更新稀疏編碼 C。

3) 以章節2.1.2為例,固定稀疏編碼 X,更新字典 D;固定稀疏編碼 C ,更新字典 Dc。
4) 重復2)和3),直到前后兩次的函數 Q 的值滿足判斷條件為止。
混合特色字典算法總體實現步驟如下:
輸入 訓練樣本 A,規范化參數 γ;
輸出 字典D和稀疏編碼 X,字典 Dc和稀疏編碼 C 及相應的標簽。
1)初始化字典D和Dc。
2)固定字典D,更新稀疏編碼 X;固定字典Dc,更新稀疏編碼 C;初始化字典后,利用式(5)、(6)依次求解。
3)固定稀疏編碼 X,更新字典 D;固定稀疏編碼 C,更新字典 Dc。
4)重復2)和3),直到前后兩次的函數的值滿足 判斷條件為止。
2 .3 低秩字典
2.3.1 低秩字典模型
在人臉識別中,假設擾動分量只占圖像特征的一小部分,即圖像的稀疏分量,使用矩陣低秩分解[28]方法從圖像中提取干擾成分(如噪聲、孤立點和遮擋)。

以如圖2所示,取圖片低秩分量 Ej作為訓練集。其中,λ1>0 為正則項參數,提出低秩字典模型如下:

2.3.2 低秩字典優化


圖 2 原圖及低秩分量Fig. 2 Original graph and low rank components

3)以章節2.1.2為例,固定稀疏編碼P,更新字典Dp。
4)重復2)和3),直到前后兩次的函數的值滿足判斷條件為止。
低秩字典優化算法總體實現步驟如下:
輸入 訓練樣本E,規范化參數 γ;
輸出 字典和稀疏系數P,及相應的標簽。
1)初始化字典Dp;
2)固定字典Dp,更新稀疏編碼P;
3)固定稀疏編碼P,更新字典Dp;
4)重復2)和3),直到前后兩次的函數的值滿足 判斷條件為止。
2.4 分類策略

2.5 本文整體算法步驟及流程
稀疏綜合字典學習的小樣本人臉識別算法分為3個子算法,利用訓練數據A、輔助數據C構造擴充干擾字典、混合特色字典、低秩字典。算法流 程圖如圖3所示。

圖 3 算法流程Fig. 3 Algorithm flowchart
稀疏綜合字典學習的小樣本人臉識別算法總體實現步驟如下:
輸入 訓練樣本A,輔助數據C,測試數據Y,參數λ1,λ2。
輸出 分類標簽。
1)利用訓練數據A構造數據集A′,算法1習得擴充干擾字典Db;
2)利用訓練數據A及算法2習得混合特色字典D,Dc;
3)利用輔助數據C及算法3習得混合特色字典Dp;
4)利用式(8)、(9)得到樣本標簽。
3 實驗結果及分析
3.1 實驗平臺和參數設置
本文實驗環境為64位Window 10操作系統,內存32 GB,Intel(R) Xeon(R) CPU E5-2 620 v4 @2.10 GHz,并用MatlabR2016b軟件編程實現。
實驗選取AR人臉數據庫、YaleB人臉數據庫、LFW人臉數據庫進行實驗,多次實驗取平均值。圖像都經過標準化處理,比較算法包括SRC、FDDL、CRC、ESRC、SVGDL和CSICVDL、SCSDL、FDDLLCSRC、LKCFDDL。
3.2 AR數據庫實驗
本文在AR人臉數據庫上設計兩個實驗方案,實驗1隨機選取100人,每人26張圖片分為5個集合,訓練集合選取兩張標準人臉,其余按特點分為4個集合,作為不同的測試集。如圖4所示,集合S1為樣本內所有表情變化圖片;集合S2為所有光照變化圖片;集合S3為所有眼鏡遮擋圖片;集合S4為所有圍巾遮擋圖片。

圖 4 AR人臉數據庫樣本(1)Fig. 4 Cropped face samples of AR database (1)
在具體實現過程中,隨機選取80人用于訓練擴充干擾字典和混合特色字典,其余20個人用于訓練低秩字典。首先將數據集下采樣為 6 0×80,并采用PCA降至100維。各算法在AR數據庫的識 別率如表1所示。

表 1 算法在AR 庫上的實驗結果 Table 1 Accuracy of different methods on Experiment1 of AR database
從表1可知,FDDL算法識別率高于SRC、CRC算法,說明提取數據特殊性的重要性,FDDLLCSRC、IKCFDDL算法在面對光照、表情變化時實驗效果良好,然而對數據存在遮擋異常時處理效果欠缺。而CSICVDL、SCSDL、本文算法識別率高于FDDL、LKCFDDL等,說明了在提取特殊性之外,捕捉數據共性的必要性。本文算法性能較穩定,混合特色字典提取了數據共性和特殊性,低秩字典、擴充干擾字典增強算法魯棒性和容錯能力,在所有集合都能達到最高識別率。
為探究本文算法對遮擋、光照、異常等情況的綜合處理能力,如圖5所示,實驗2選取每人兩張正常狀態下的人臉圖片作為訓練集,將圍巾遮擋、墨鏡遮擋作為測試集合。

圖 5 AR人臉數據庫樣本(2)Fig. 5 Cropped face samples of AR database(2)
將數據集下采樣為 6 0×80,采用PCA將數據降為 {50,150,250,350,450} 維。如圖6所示,本文算法在不同維度下皆取得最高識別率,在面對遮擋 等異常情況時表現最佳。

圖 6 AR人臉數據庫識別率Fig. 6 Accuracy of different methods on Experiment1 of AR database
3.3 YaleB數據庫實驗
本文在The extended Yale B 人臉數據庫上設計兩個實驗。實驗1中,每人隨機選取5圖片訓練,其余圖片進行測試。圖7表示其中一個訓練樣本和部分測試樣本。

圖 7 YaleB人臉數據庫樣本Fig. 7 Cropped face samples of YaleB database
在具體實驗時,選取30個人訓練擴充干擾字典和混合特色字典,其余8個人用于訓練低秩字典。將數據分別降維至 { 150,250,350,450,550} 維,各 算法在各維度上的識別率如表2所示。

表 2 算法在Yale B database庫上的實驗結果Table 2 Accuracy of different methods on Experiment1 of Yale B database %
從表2可以看出,本文算法識別率高于其他算法,并隨著維數增多而增高。
為探究各算法魯棒性,實驗2賦予算法不同的參數值,參數1與參數2 分別取值{0.001, 0.005,0.01, 0.05},參數1限制正則化項對識別率的影響,參數2限制稀疏編碼對識別率的影響,實驗結果如圖8所示,本文算法與FDDL算法識別率隨參數1、2的取值增大而增大,并最終達到穩定,本文算法識別率隨參數改變的波動小,趨于平緩,魯棒性強。
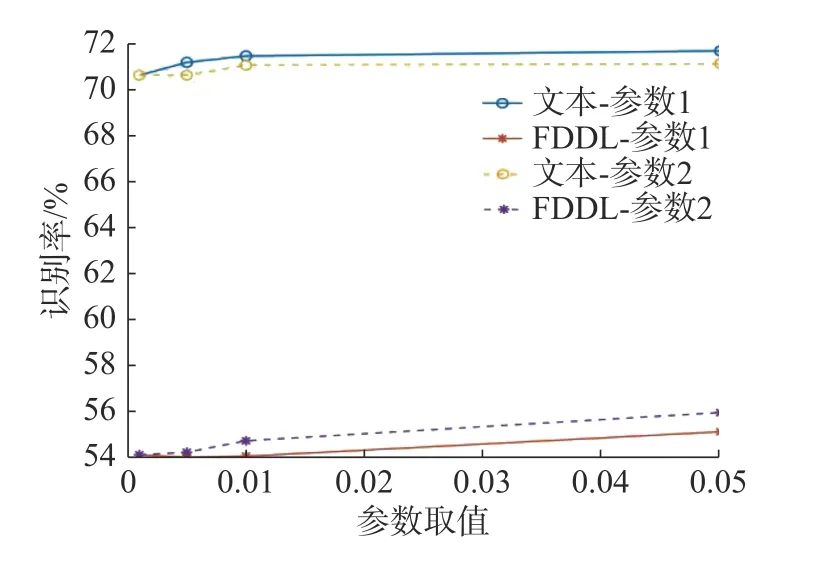
圖 8 參數對YaleB人臉數據庫識別率的影響Fig. 8 The parameter analysis on the YaleB database
3.4 LFW數據庫實驗
本文在非受限人臉數據庫LFW設計兩次實驗,如圖9所示,利用3d校正補齊因轉向、遮擋而缺失的特征信息。
實驗一,選取單人圖片數量大于10張的158人作為實驗數據。在具體實驗時,選取148個人訓練擴充干擾字典和混合特色字典,其余10個人用于訓練低秩字典。如圖10所示,隨機選取每人10張圖片,5張圖片作為訓練集,其余為測試集。將數據分別將至{50, 100, 150, 200,250}維,各算法在各維度上的識別率如表3所示。

圖 9 校正 LFW人臉數據庫Fig. 9 Correction of LFW Face Database

圖 10 LFW人臉數據庫樣本Fig. 10 Cropped face samples of LFW database
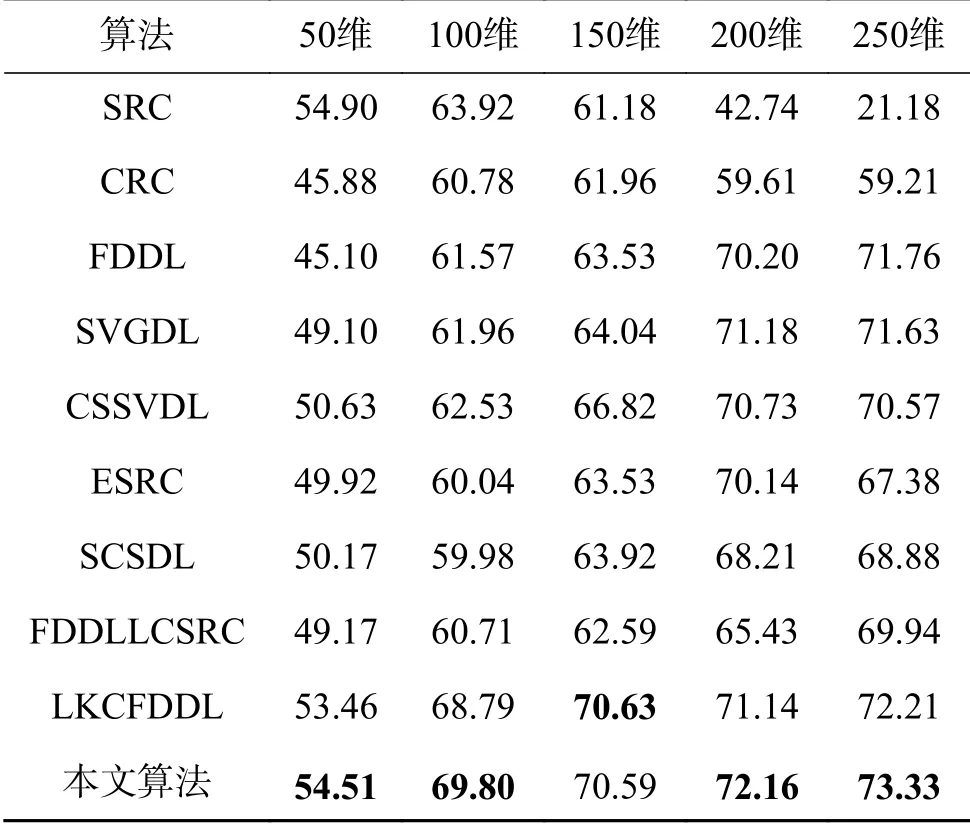
表 3 算法在LFW database 庫上的實驗結果 Table 3 Accuracy of different methods on Experiment1 of LFW database
如表3所示,多數情況下算法的識別率隨維數增多而升高,本文算法優于其他算法,但識別率整體不高,這可能是因為前期校正造成的信息損失。
為驗證低秩字典對算法影響,實驗2隨機挑選19、39、59、79個人作為低秩字典訓練數據及CSSVDL類內差異字典輔助數據,與基礎FDDL算法、包含輔助字典的CSSVDL算法進行對比,各算法在各集合上的識別率如圖11所示。
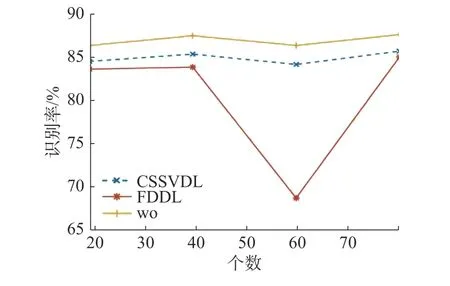
圖 11 LFW人臉數據庫識別率Fig. 11 Accuracy of different methods on experiment1 of LFW database
從圖11可知,隨著構筑類內差異字典的輔助數據增加,CSSVDL算法的識別率大致增加。隨著構筑低秩字典訓練數據增加,本文算法識別率大致增加。本文算法、CSSVDL算法、FDDL算法在59人實驗中識別率均受個別樣本選擇影響下降,本文算法和CSSVDL由于輔助數據捕捉數據共性,較FDDL算法有更好的魯棒性。在非受限人 臉數據庫LFW上,本文算法分類效果最優。
3 .5 算法評價
3.5.1 復雜度分析
本文算法復雜度分為擴充干擾字典、混合特色字典、低秩字典3個部分計算,每部分又分為更新稀疏編碼和更新字典兩步驟。
以擴充干擾字典為例,設訓練樣本個數為n,樣本特征維數為q,更新稀疏系數的時間復雜度為nO(q2nr),其中,r≥1.2 為常數。更新字典的時間復雜度為∑jnjO(2nq),其中,nj表示Di的原子個數。
擴充干擾字典總復雜度為
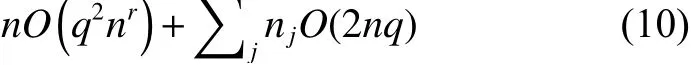
3.5.2 運行效率分析
為探究算法運行效率,本文設計實驗。如圖12所示,實驗1取AR數據庫80人,每人前13張圖片 訓練,其余圖片進行測試。

圖 12 AR實驗Fig. 12 Experiment on AR
實驗2選取YALE數據庫,如圖13所示,每人前2張人臉圖像為訓練集,剩余9張為測試圖像。隨機選取5人作為輔助數據,數據庫其余人數作為訓練和測試數據,算法運行時間及實驗結果如表4所示。

圖 13 YALE實驗Fig. 13 Experiment on YALE
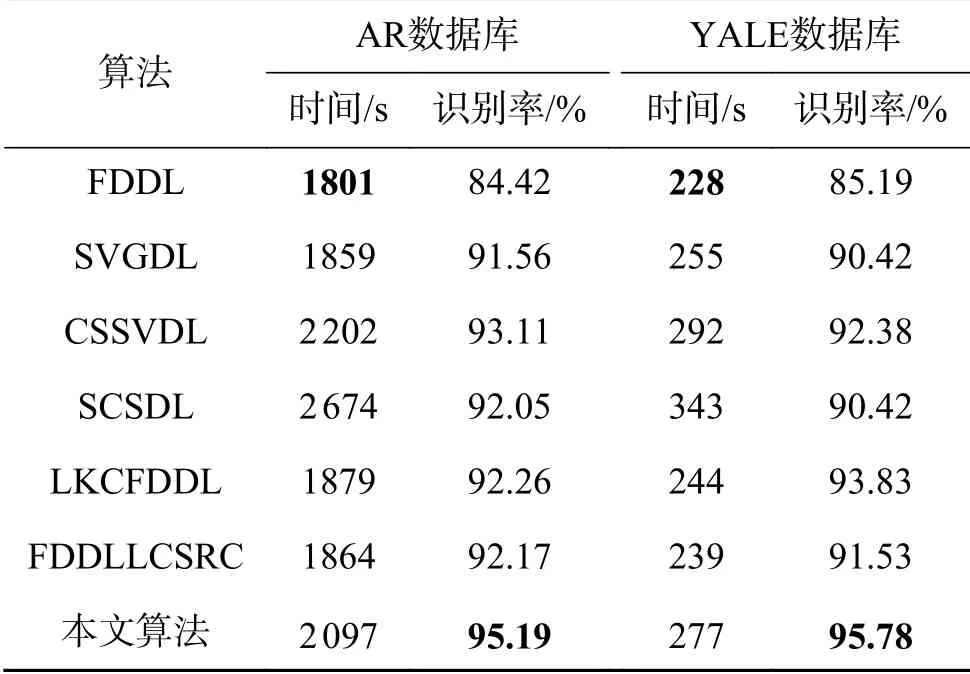
表 4 AR及YALE庫實驗Table 4 Experiment on AR and YALE
綜合表4可以看出,本文算法、CSSVDL算法、SCSDL算法由于輔助數據的構建,雖然算法識別率提高,但算法運行時間也隨之增加。兩實驗中本文算法識別率最高,且運行時間小于CSSVDL算法、SCSDL算法,證明本文算法具有更高的性價比。
4 結束語
本文提出稀疏綜合字典模型,加入Fisher判別準則,學習混合特色字典提取數據共性和特殊性,學習擴充干擾字典與低秩字典提取數據異常、干擾性,分別在AR、YaleB、LFW等人臉庫上進行實驗。實驗表明,在小樣本訓練情境下,即使測試樣本與訓練樣本存在較大差異如表情變化、遮擋等,本文仍能保持較好的性能。在實際應用中還需進一步探討算法對訓練樣本的依賴性以及算法的穩定性。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
