基于Faster R-CNN的多任務增強裂縫圖像檢測方法
2021-07-05 10:57:40毛鶯池唐江紅王靜平萍王龍寶
智能系統學報 2021年2期
毛鶯池,唐江紅,王靜,平萍,王龍寶
(河海大學 計算機與信息學院,江蘇 南京 211100)
我國是世界上擁有水庫大壩最多的國家[1],但隨著時間的推移和壩齡的增長,大壩表面和內部發生形變,出險幾率增加,威脅人民生命財產安全。裂縫是大壩的主要危害之一。
近年來,圖像處理、模式識別和深度學習等技術的發展,為大壩裂縫圖像檢測提供技術支持。但由于大壩環境復雜等一系列因素的限制,導致裂縫圖像收集和標記成本過高,因此難以獲得大壩裂縫圖像檢測的分類模型。遷移學習主要是針對規模不大,樣本數量有限的特定領域數據集使用機器學習容易產生過擬合而導致無法訓練與學習的問題,通過利用具有一定相似性的領域中已訓練好的較好優秀模型和樣本構建滿足任務需求的模型,從而實現小數據集下構建良好模型的效果。
Faster R-CNN[2]是目前基于區域卷積神經網絡系列的目標檢測算法中綜合性能最好的方法之一,但其對多目標、小目標情況檢測精度不高。本文提出了一種基于Faster R-CNN的多任務增強裂縫圖像檢測方法,以適應大壩在不同光照環境,不同長度裂縫情況下的檢測。同時提出了一種基于K-means多源自適應平衡TrAdaBoost遷移學習方法輔助網絡訓練,解決樣本不足問題。
1 相關工作
根據卷積神經網絡的使用方式,將基于CNN目標檢測算法[3-4]分為兩大類:基于區域建議的深度學習目標檢測算法和基于回歸思想的深度學習目標檢測算法。前者的主流算法有:RCNN算法[5]、Fast R-CNN算法[6]和Faster RCNN算法。R-CNN首次將神經網絡應用在目標檢測算法上,在 Pascal VOC 2012 的數據集上將平均精度mAP提升了30%。Fast R-CNN將候選框識別分類和位置回歸合成到一個網絡中,不再對網絡進行分步訓練,提高了訓練速度。Faster RCNN與Fast R-CNN最大的區別就是提出了區域建議網絡(region proposal networks, RPN)網絡,極大地提升了檢測框的生成速度。基于回歸思想的深度學習目標檢測的主流算法有:SSD算法[7]和YOLO V2算法[8]。SSD算法和YOLO算法均沒有區域建議過程,極大地提高了檢測速度,但識別精度和位置回歸精度不足。
從20世紀90年代起遷移學習開始逐漸進入機器學習領域,受到研究者們的關注。常用的遷移學習方法有AdaBoost[9]和TrAdaBoost[10]算法等。AdaBoost算法基本思想:當一個訓練樣本被錯誤分類時候,對此樣本增加樣本權重,再次訓練時該樣本分錯的概率就會大大降低。TrAda-Boost算法是由AdaBoost算法演變而來的,該算法通過降低誤分類的源域訓練數據權重,增加誤分類的目標域訓練數據權重,使得分類面朝正確的方向移動并訓練出強分類模型。Al-Stouhi等[11]總結TrAdaBoost算法存在的問題,在此基礎上進行改進,提出一種動態TrAdaboost (dynamic TrAdaboost, DtrA)方法,DtrA方法能夠在迭代過程中動態調整樣本權重;郭勇[12]在DtrA方法基礎上進一步改進,提出一種自適應TrAdaBoost (adaptive TrAdaBoost, AtrA) 方法,AtrA方法能夠反映出源領域訓練數據集與目標領域訓練數據集之間是否具有相似性關系。
2 ME-Faster R-CNN與K-MABtrA方法
本文提出了一種基于Faster R-CNN的多任務增強裂縫圖像檢測的網絡模型,以適應大壩在不同光照環境、不同長度裂縫情況下的檢測。同時,提出了一種基于K-means多源自適應平衡TrAdaBoost遷移學習方法解決樣本不足問題。本文采用基于K-MABtrA遷移學習方法訓練MEFaster R-CNN網絡模型,該方法通過已準備的多源裂縫圖像數據集對卷積神經網絡的參數進行預訓練,然后使用預訓練得到的網絡權重作為初始權值,遷移到目標數據集上進行微調,得到適用于大壩裂縫檢測的模型。
2.1 ME-Faster R-CNN模型
ME-Faster R-CNN在Faster R-CNN模型基礎上進行改進,改進之處如圖1所示。其中,特征提取部分:選取輕量級的ResNet-50作為卷積神經網絡;特征融合部分以及候選區域生成部分:改進使用多任務增強RPN模型,改善錨盒尺寸大小提高Faster R-CNN搜索能力,提高檢測識別精度;檢測處理部分:特征圖和選擇區域建議經過感興趣區域(ROI)池、全連接(FC)層分別發送給邊界回歸器和SVM分類器得到分類與回歸結果。

圖 1 ME-Faster R-CNN模型改進之處Fig. 1 Improvements of ME-Faster R-CNN
ME-Faster R-CNN檢測流程主要分為3個部分,分別是特征提取、特征融合以及候選區域生成、檢測處理。
1)特征提取:本文選用ResNet-50深度殘差網絡[13]作為大壩裂縫圖像特征提取器,通過5級ResNet-50將圖片轉換成特征圖。
2)特征融合以及候選區域生成:將所得特征圖輸入多任務增強RPN模型,并改善RPN模型的錨盒尺寸和大小以提高檢測識別精度,最后生成候選框。具體方法如下:
①多任務增強RPN方法:最初Faster RCNN模型結構中只有一個RPN,RPN使用最后一個卷積層獲得特征圖[2]。稱之為原始RPN,其結構如圖2(a)所示,輸入圖像大小為 224×224,原始RPN在網絡中感受野要遠遠大于 2 24×224,僅能獲得少量典型裂縫特征。然而,圖像中裂縫存在不同大小和比例。如果檢測到裂縫大小對于檢測區域太大,則檢測區域周圍多余裂縫形狀可能會被視為噪音。如果檢測到裂縫大小對于檢測區域太小,RPN將無法生成ROI。因此,原始RPN的功能不足以檢測不同大小和比例的完整裂縫對象。

圖 2 原始RPN模型與多任務增強RPN模型Fig. 2 Primitive RPN module &multi-task enhanced RPN module
針對以上問題,ME-Faster R-CNN方法提出一種多任務增強RPN方法,其結構如圖2(b)所示。該方法在ResNet-50的基礎上引入多個RPN來產生ROI,提取不同大小特征圖。具體是在ResNet-50的第3卷積層Conv3_x后加入一個RPN模塊,其感受野大小為 146×146,用來檢測較小目標;同時在ResNet-50的第4卷積層Conv4_x后加入一個RPN模塊,其感受野大小為 229×229,用來檢測較大目標;在ResNet-50的第5卷積層Conv5_x之后利用多RPN任務可以輸出圖像總體信息。
由于每個RPN輸出獨立的ROI數組,為聚集和選擇有效的區域,多任務增強RPN方法提供ROI-Merge Layer用于接受獨立ROI數組,ROIMerge Layer僅輸出一個數組。為了避免重復的ROI和低的ROI裂縫似然分數,本文使用非極大值抑制方法,不同卷積層后RPN輸出的候選區域中,在對應位置兩ROI的交并比大于0.7的ROI為同一ROI。具體方法為,3個卷積層后RPN輸出的候選區域均帶有建議得分,該分數對應的是目標的可能性,在對應位置選取分數最高的一個ROI區域,另外兩層對應位置的ROI與所選ROI交并比IoU若大于0.7,則認為是同一ROI,ROI-Merge Layer的輸出數組中對應位置僅輸出該得分最高的數組。在使用非極大值抑制方法之后,選擇前100個值較高的ROI。因此,ROIMerge Layer只需要調整超參數即可控制ROI的數量。
②改善RPN模型的錨盒尺寸和大小:FasterR-CNN模型經過卷積層提取特征圖,然后特征圖輸入RPN區域進行特征融合以及生成候選區域,此時特征圖上每個像素點映射不同比例寬度錨點,每個錨點放置若干個不同大小的錨,為解決不同尺度間隔的錨盒搜索能力不平衡的問題,本文設計了一種新型錨盒,新型錨盒尺度為:50×50 、 2 00×200 、 3 50×350 和 5 00×500,其中,50×50 和 2 00×200 適用于較小的裂縫檢測,350×350 和 5 00×500 適用于較大的裂縫檢測。這4種尺度每種尺寸按1∶1,1∶2,2∶1 的長寬比例縮放,共12種尺度作為RPN需要評估的候選框,在預測時候選框的順序是固定的。RPN的目標就是對原圖中的每個錨點對應的12個框,預測其是否是一個存在目標的框。框與真值框的 IoU>0.7就 認為這個框是一個候選框,反之,則不是。
2.2 K-MABtrA方法
針對大壩裂縫圖像較少,訓練樣本分布不均衡,以及TrAdaBoost算法在訓練過程中易削弱輔助數據集作用的問題,本節提出一種基于Kmeans的多源自適應平衡TrAdaBoost的遷移學習方法K-MABtrA,使用遷移學習充分利用多個領域的大量相關訓練集,動態調整樣本權值,訓練出網絡的強分類器,提高大壩裂縫檢測的準確率。如圖3所示為基于K-means的多源自適應平衡TrAdaBoost遷移學習方法的過程,主要分為兩個階段:K-means圖像聚類方法[14]和多源自適應平衡TrAdaBoost遷移學習。
1) K-means圖像聚類方法:通過K-means圖像聚類方法,利用歐式距離將圖像進行聚類排序。將聚類距離遠的圖片從裂縫圖像庫中刪除,有利于后續分類器的訓練,提高訓練效率。K代表聚類質心數目,means表示簇內數據的均值。K-means圖像聚類方法具體步驟如下:
①首先將圖像庫中圖像Xi(i=1,2,···,n) 進行灰度化,依次存儲到一維矩陣DX中;
②接著以10像素長度,3像素移動步長依次進行分塊存儲,記錄每小塊的首位置,得到n個像素塊數據集,從中任意選擇30個圖像小塊的灰度均值作為初始聚類中心;
③根據每個圖像矩陣小塊的灰度均值,利用歐幾里得距離,如式(1)所示,計算這些對象與30個圖像樣本聚類中心的距離;并根據最小距離重新對相應圖像小塊灰度均值進行劃分,將每個圖像矩陣小塊賦給最相近的類;

式中:dis(xi,yj) 為數據對象xi和yj之間的距離。該值越大,說明xi和?yj越相似;反之xi和yj差距越大。
④重新計算每個有變化的圖像小塊像素灰度均值的質心;
⑤重復上述步驟3)、4)直至各個數據類的集合 中心不再發生變化為止。
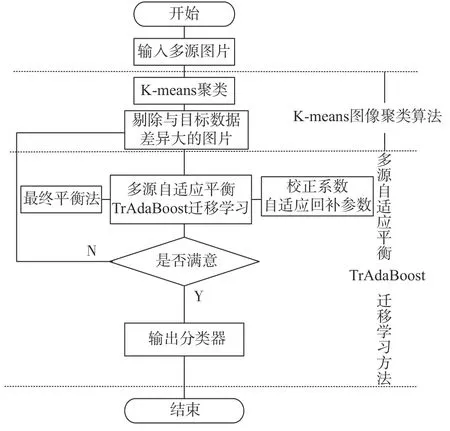
圖 3 K-MABtrA方法流程圖Fig. 3 Flow chart of K-MABtrA method
2)多源自適應平衡TrAdaBoost遷移學習:利用不同領域裂縫圖像和真實大壩裂縫圖像一一組合進行訓練,生成基分類器;在TrAdaBoost基礎上引入校正系數[12],避免由于迭代次數的增加,導致源領域權重下降過快,與目標源領域權重之間差距過大的問題;在校正系數中引入自適應回補參數[13],反映源領域訓練數據集與目標領域訓練數據集之間是否具有相似性關系,提高方法檢測性能;最后,使用最終平衡權重法,使最終得到的目標源數據集與各領域裂縫數據集重要度一致。
① 增加校正系數更新源領域樣本的權值
遷移學習在訓練過程在,各領域輔助訓練集隨著迭代次數增加得到的權值不斷減小以至于與目標數據集不相關,無法起到輔助目標數據集學習的作用。為了更好地利用各領域輔助訓練集和目標數據集訓練,在TrAdaBoost基礎上增加校正系數更新源領域樣本的權值。當迭代次數m不斷增大,各個領域輔助訓練集都能被正確回歸,當 m 次迭代結束后,各個輔助領域樣本權值之和為

式中:na為輔助訓練集 a 中樣本個數;wma為 a 中各訓練樣本權重。
目標數據集 b 中預測樣本正確的樣本權值不變,nb為目標數據集 b 中樣本個數, wmb為 b 中訓練樣本權重,εmb為弱分類器在 b 上的錯誤率,正確樣本的權值之和為

目標數據集 b 中預測錯誤樣本需要更新 φm,則 b 中錯誤樣本的權值之和 Sb2為

所有目標域樣本權值之和,即正確樣本和錯誤樣本權值之和:

當 m+1 次迭代的輔助數據集樣本權值分布為
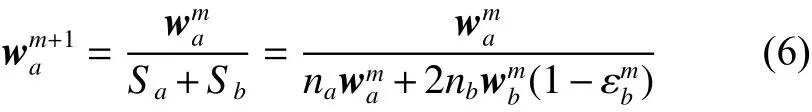
當迭代次數足夠大時,各領域輔助訓練集都能被正確回歸,迭代結束后,wma+1=wma,聯系式(6)可得:
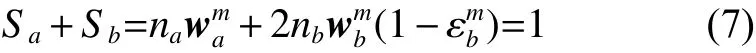
設輔助數據集樣本增加校正系數為 Cm,其權值變為


從式(9)可以看出,校正系數 Cm與弱分類器在目標數據集 b 上的錯誤率 εmb負相關,輔助數據集樣本權值增加,對下一次迭代訓練弱分類器的影響增加;反之對下一次迭代訓練弱分類器的影響減小。因此,在TrAdaBoost算法基礎上加入校正系數 Cm能夠同時保持目標數據集和輔助數據集樣本權值得到收斂。
② 引入自適應回補參數
然而,即使 εb較低時,弱分類器對源領域訓練集的分類效果也會存在差異,這種差異同樣可以反映出源領域訓練集與目標領域訓練集之間的相關性。為了反映這種相似性關系,在校正系數中引入自適應回補參數,自適應回補參數為基分類器在輔助數據集和目標數據集上的分類正確率之和,即

③ 最終平衡權重法
最后,循環達到設定迭代次數 M ,得到強學習器。但在迭代后,目標數據集與源數據集的權重已經嚴重偏離,所以,造成最終分類器也過于偏向目標小數據集的問題。針對上述問題,在最終分類器生成方式中引入最終平衡權重法。最終平衡權重法的基本概念是:在迭代過程中,源數據權重不斷下降,目標數據權重不斷增加,迭代結束后,源數據權重與目標數據權重之間差距較大,但在最終分類器生成形式上,將目標數據集最終權重重置為最后一次迭代中各領域輔助訓練集權重的平均值,使最終得到的目標源數據集與各領域輔助訓練集要度一致,提高算法的檢測準確 率。
3 實驗與結果
3.1 數據集介紹
目前公開的大壩裂縫圖像數據庫較少,為了實現對大壩裂縫圖像檢測與識別,從大壩日常監測過程以及Google圖像搜索引擎中收集并整理已標記好的裂縫圖像組建成數據庫。該數據庫包含大壩、公路、混凝土墻壁和橋梁4個領域裂縫圖像,其中大壩裂縫圖像635張,其他領域裂縫圖片 每個領域各2 500張,總計8 135張裂縫圖片。
3.2 實驗結果與分析
本次實驗根據選取數據集的特點,選取mAP[15](mean average precision)和檢測評價函數交并比[16](intersection over union,IoU)作為目標檢測算法的評價指標。mAP作為目標檢測中用于衡量識別精度指標;IoU 表示感興趣區域和標定區域的重疊率。
本實驗主要從以下4個方面對基于Faster RCNN參數遷移的裂縫圖像檢測訓練方法的優劣進行對比分析:
1)視覺對比分析
在裂縫檢測過程中,對裂縫圖像提取感興趣區域,并對感興趣區域進行裂縫特征提取,通過訓練好的分類器進行裂縫檢測識別后,每個感興趣區域邊框都會得到一個分數,即置信度。隨機選取3組實驗結果進行視覺對比分析如圖4所示。以圖4(a)為例,其中,原圖中央有一條長度和開合度明顯的裂縫痕跡,其下方有一條短且開合度不明顯的裂縫痕跡。Faster R-CNN能夠檢測出長度和開合度明顯的裂縫,在其下方的裂縫并未準確檢測出來。而ME-Faster R-CNN模型不僅提高 I oU 重疊度,更為準確地檢測出長裂縫,同時能夠準確檢測出下方小裂縫痕跡,做到不誤檢也不漏檢。實驗結果表明,在相同的實驗條件下,ME-Faster R-CNN方法不僅能提高檢測精度,而且在應對目標小、多目標情況時,能獲得很好的 檢測效果。
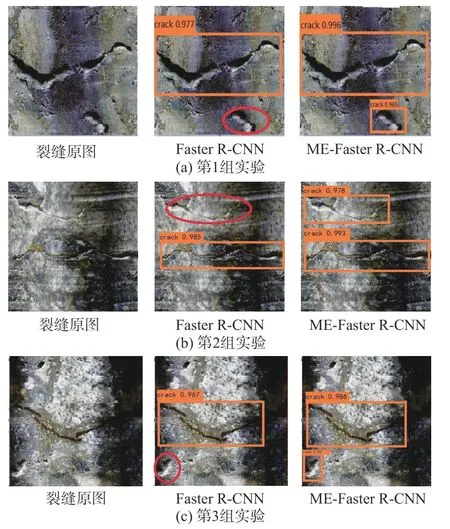
圖 4 視覺對比分析Fig. 4 Visual contrast analysis
2)與不同基準網絡模型之間對比分析
該部分采用ZF網絡[17]、VGG-16[18]網絡、Res-Net-50和ResNet-101網絡作為特征提取基準網絡,Faster R-CNN作為目標檢測模型進行實驗。
由表1可得,在同樣數據集的訓練測試下,ZF-Net可以達到66.51%的mAP值,VGG-16網絡可以達到71.90%的mAP值,而ResNet網絡的mAP值可以超過78%,提高了6個百分點,網絡的檢測準確度得到提高,由表1可以看出ResNet-50比ResNet-101的檢測精度略低,但是ResNet-50的參數量為ResNet-101參數量的 1 /2,能夠有效減少網絡權重數量,加速模型訓練[14],綜合訓練速度與檢測精度本文選取ResNet-50為基準模型。

表 1 不同基準網絡模型的準確度Table 1 Accuracy of different baseline network models
3)與不同目標檢測算法對比分析
該部分以ResNet-50網絡為基準網絡,以SSD算法、YOLO V2算法、Faster R-CNN算法和ME-Faster R-CNN算法作目標檢測模型進行實驗。
表2給出不同目標檢測算法獲得的平均IoU、召回率、準確度以及平均精度。其中,MEFaster R-CNN算法的平均 IoU 是最高的,表明ME-Faster R-CNN算法在裂縫位置檢測的準確性方面更優異一些,且其mAP值也是最大的,達到80.02%,表明ME-Faster R-CNN檢測模型的綜合性能很好。

表 2 不同目標檢測算法對比分析Table 2 Comparison of different target detection algorithms
此外,注意到裂縫尺寸大小對準確度也會存在一定影響。因此,將采集到的真實大壩裂縫圖像根據其尺寸大小分為3組。第1組包含100個樣本,其尺寸大小在[0,50]范圍內,第2組包含100個樣本,其尺寸大小在[50,200]范圍內,第3組包含100個樣本,其尺寸大小超過200像素。各目標檢測算法在不同尺寸裂縫圖像的準確度如圖5所示。

圖 5 不同尺寸裂縫圖像的準確度Fig. 5 Accuracy of crack images with different sizes
從圖5可以看出,Faster R-CNN系列模型檢測的準確度要整體優于SSD算法和YOLO V2算法,所有的檢測算法在較大裂縫圖像上都能表現得最好,而在小裂縫圖像的檢測上,準確度卻不是很高。Faster R-CNN算法和ME-Faster RCNN算法在較大裂縫圖像檢測性能上實力相當,而在小裂縫圖像的檢測上,ME-Faster R-CNN算法要更優于Faster R-CNN算法。綜上所述,MEFaster R-CNN算法在保持一定準確度的基礎上,在面對小目標檢測難度較大的情況,也能獲得很好的效果。
4)遷移學習對比實驗
該部分以ResNet-50作為基準網絡,ME-Faster R-CNN作為目標檢測模型,目標數據集樣本占源訓練集樣本的比例為r,r取2%、5%和10%,分別用K-MABtrA方法、ATrA方法、DTrA方法、TrAdaBoost遷移學習方法進行分類器訓練。
由表3可得出,同一方法,不同比例r下訓練得到的分類器,在一定的范圍內隨著比例r不斷增加,分類器的各評價指標都有所提升,說明在一定范圍內目標源數據占總數據比例越大,分類器的各評價指標越高,檢測效果越好。在目標源數據所占比例r相同情況下:ATrA和DTrA方法各評價指標均高于TrAdaBoost,證明了引入校正系數和自適應回補參數的有效性。本文提出的K-MABtrA方法各指標均高于ATrA方法。說明K-MABtrA方法引入最終平衡權重法,使最終得到的目標源數據集與各領域裂縫數據集重要度一致,提高算法的檢測準確率。綜上所述,K-MAB-trA方法能夠更多地利用其他領域的共享信息,得到更好的遷移學習效果,訓練出強分類器,高效 地完成大壩裂縫圖片的檢測任務。

表 3 不同遷移學習方法對比分析 Table 3 Comparison of different transfer learning methods
4 結束語
經實驗驗證,本文提出的ME-Faster RCNN方法在多目標、小目標檢測準確性方面更優異;且本文提出的遷移學習方法更有效地解決了樣本不足的問題。本文所提出方法的局限性在于ME-Faster R-CNN相比于Faster R-CNN只在特定檢測任務中準確度較高,比如本文的應用場景:大壩裂縫檢測,或類似的檢測任務。而對于目標大小相似、亮度相同的目標檢測其結果與FasterR-CNN所差無幾。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
