面向推薦系統的分期序列自注意力網絡
2021-07-05 10:59:44鮑維克袁春
智能系統學報 2021年2期
鮑維克,袁春
(1. 清華大學 計算機科學與技術系,北京 100084; 2. 清華大學 深圳國際研究生院,廣東 深圳 518000)
隨著互聯網的普及,互聯網應用的用戶數量空前增長,阿里巴巴集團公布截至2019年12月31日的季度業績顯示[1],其中國零售市場移動月活躍用戶達8.24億,創12個季度以來新高。諸多互聯網公司在龐大的用戶數據之上采用智能推薦算法提高產品的可用性和用戶體驗。然而經典的推薦算法往往存在一些問題:1)對于用戶反饋(user-item interactions)數據表現出的相互依賴和序列性分析不足;2)對反饋數據和上下文的動態性應對不足;3)模型往往固定表達了用戶的長期/一般偏好,而非基于反饋數據對長期/一般偏好進行表達。
為此,本文提出了一種面向推薦系統的分期序列自注意力網絡(long-term & short-term sequential self-attention network,LSSSAN)。“分期”表示將用戶的反饋數據分為長期和短期,用戶的長期反饋數據反映了用戶的長期/一般偏好,用戶的短期反饋數據反映了用戶的短期偏好和序列性偏好;注意力(attention)機制,可以為不同的數據賦予不同的權重,幫助模型動態捕捉數據中重要的信息,自注意力(self-attention)機制在此基礎上,可以有效地捕捉長序列數據之間的相互依賴。本模型中,自注意力機制從用戶長期反饋數據提取用戶的長期/一般偏好,GRU(gate recurrent unit)從用戶短期反饋數據的提取用戶的序列性偏好,最后由以上所得綜合用戶短期反饋數據表現出的短期偏好參與注意力機制,得到了用戶的綜合偏好。總體來講,本文模型的亮點如下:
1)采用注意力機制為不同的反饋數據賦予不同的權重以動態捕捉重點信息,同時也考慮了不同用戶和不同item候選集對推薦結果的動態影響;
2)自注意力機制捕捉了長期反饋數據之間的長期相互依賴,準確地表達了用戶的長期/一般偏好,而非基于用戶特征固定地表達長期/一般偏好;
3) GRU捕捉了短期反饋數據的序列性并參與注意力機制賦權,GRU層輸入數據的順序相關性的強弱會影響注意力機制賦予序列性表示的權重,進而準確表達了用戶的序列性偏好;
4)在數據集上實驗的評價指標整體優于主流的推薦算法。
1 研究背景
1.1 推薦系統的一般任務
通常來說,推薦系統的一般模型可以用以下形式表達,如圖1所示。

圖 1 推薦系統一般模型的結構Fig. 1 Structure of general recommendation system model
圖1中,item表示推薦系統中的項(item可以為商品、視頻等),一個用戶的反饋數據記錄由多個item組成,Model表示推薦模型,推薦系統的任務是將合適的item推薦給用戶。u表示用戶 u 的特征表示;Lu表示用戶 u 的用戶反饋數據序列,由多個item組成,為用戶 u 的用戶反饋數據序列Lu中的一項;表示可能被推薦的候選item集合中的某一候選item;推薦系統基于以上內容,計算用戶 u 的綜合偏好表示并通過計算用戶 u 對候選item的偏好得分,得分越高說明用戶 u 越傾向于選擇候選item
1.2 相關工作
傳統的推薦系統如基于內容推薦和協同過濾推薦,均是以靜態方式對用戶反饋數據進行建模,對用戶反饋數據的信息提取不夠充分。而序列推薦模型將用戶反饋數據視為序列,考慮了用戶反饋數據的序列性和相互依賴,進而準確估計了用戶的偏好[2-4]。
在序列推薦模型中,用戶反饋數據序列由較長的用戶反饋數據組成,使得用戶反饋數據序列具有更復雜的依賴特性。對于用戶反饋數據序列的處理,其中兩個主要的難點[2]是:
1)學習高階順序依賴
高階順序依賴在用戶反饋數據序列中普遍存在,低階依賴的可以用馬爾科夫模型[5]或因子分解機[6-7]解決,高階順序依賴由于反饋數據的多級級聯,模型往往難以表達。針對此問題,目前主要的兩種方案:高階馬爾科夫鏈模型[8]和RNN(recurrent neural network)模型[9]。但是,高階馬爾可夫鏈模型因參數數量隨階數呈指數增長,其分析的歷史狀態有限;而單一的RNN模型難以處理具有非嚴格順序相關性的用戶反饋數據序列。
2) 學習長期順序依賴
長期順序依賴指序列中彼此遠離的用戶反饋數據之間的依賴性。文獻[9-10]分別使用LSTM(long short-term memory)和GRU(gate recurrent unit)來解決這個問題。但是,單一的RNN模型依賴于序列中相鄰項的強相關性,對于弱相互依賴性和非嚴格順序相關性的數據處理表現不佳。文獻[11]通過利用混合模型的優勢,將具有不同時間范圍的多個子模型組合在一起,以捕獲短期和長期依賴關系。而注意力機制考慮了用戶反饋數據之間的聯系卻不依賴于數據的相鄰關系,阿里Deep Interest Network[12]、Next Item Recommendation with Self-Attention[13]、Sequential Recommender System Based on Hierarchical Attention Networks[14]等,通過注意力機制,模型能夠計算出用戶反饋數據的相對權重以動態捕捉重點信息,進而準確估計了用戶的偏好表示。
2 分期序列自注意力網絡
本文提出了一種分期序列自注意力網絡(longterm & short-term sequential self-attention network,L SSSAN)進行序列推薦。
2.1 問題表述
在基于LSSSAN的推薦系統中:u表示用戶 u的特征表示;Lu表示用戶 u 的用戶反饋數據序列,如用戶點擊、購買的item序列;vuj∈Lu表示用戶 u 的用戶反饋數據序列Lu中的一項item;Lucand表示可能被推薦的候選item集合;vu3j∈Lcuand表示候選item集合Lucand中的一項。
文獻[6, 9]表明短期反饋數據對推薦結果有著重要影響,結合長期和短期反饋數據能夠準確反映用戶的綜合偏好;文獻[14]的工作利用用戶長期反饋數據充分表達了用戶的長期/一般偏好,并結合短期反饋數據表達的短期偏好準確估計了用戶的綜合偏好。基于此,本文將用戶反饋數據Lu劃分為用戶長期反饋數據Lluong和用戶短期反饋數據Ls
uhort(在本文的實驗環節,將一天內的反饋數 據為短期反饋數據)。長期用戶反饋數據Lluong反映了用戶的長期/一般偏好,短期用戶反饋數據反映了用戶近期的短期偏好和序列性偏好。舉例來說,用戶A是個運動愛好者,平時喜歡購買一些運動設備,有一天,用戶A由于手機損壞,購買了手機和手機保護膜。此時如果基于用戶A的長期/一般偏好,推薦系統會更偏向于給用戶A推薦運動相關的item,而如果基于用戶A的短期偏好,推薦系統則會偏向于給用戶A推薦手機相關的item,考慮到用戶A短期購買日志(先后購買手機和手機保護膜)的序列性,推薦系統則可能會向用戶A推薦手機保護殼。
LSSSAN基于以上內容,估計用戶的綜合偏好,并利用用戶u的綜合偏好計算用戶 u 對候選項itemv3jcand的偏好得分,得分越高說明用戶 u 越傾 向于選擇候選項itemv3jcand。
2.2 模型結構
在序列推薦的場景中,用戶偏好往往有以下的特點:1)用戶反饋數據往往是長序列,用戶反饋數據存在著復雜的相互依賴關系;2)短期用戶反饋數據和其表達的序列性,影響推薦結果的重要因素;3)相同的item,在不同的候選item集合或不同的用戶下,對于推薦結果有不同的影響;4)在考慮不同的item對于結果的影響時,應對不同的item賦予不同的權重以動態捕捉重點信息。
基于此,本文設計了LSSSAN模型,網絡結構如圖2所示。
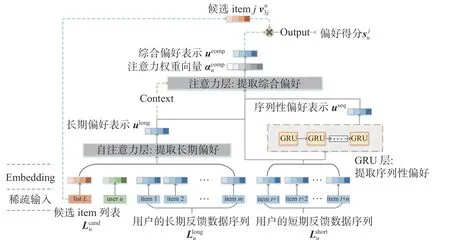
圖 2 分期序列自注意力網絡的結構Fig. 2 Structure of LSSSAN
Embedding層:對用戶、可能被推薦的候選item集合、用戶反饋數據的特征的稀疏表示進行embed,轉化為稠密的embedding表示。
自注意力層:在推薦系統中,應用注意力機制,可以為不同的用戶反饋數據賦予不同的權重,以動態捕捉重點信息,反映了不同的用戶反饋數據對推薦結果影響的差異性。自注意力機制是一種特殊的注意力機制,由于在機器翻譯領域的成功表現,自注意力機制逐漸走入研究者們的視野[15]。自注意力機制在動態賦權的同時,捕捉了用戶反饋數據之間的相互依賴,并且自注意力機制在長序列的數據上表現出色。文獻[13]的工作將自注意力機制應用于從用戶短期反饋數據上提取用戶的短期偏好,但這項工作忽視了用戶長期反饋數據在序列推薦中的作用,同時自注意力機制對短期反饋數據的序列性分析不足。基于此,本文考慮將自注意力機制應用于用戶長期反饋數據,結合用戶和候選item集作為上下文,得到用戶長期/一般偏好的表示。

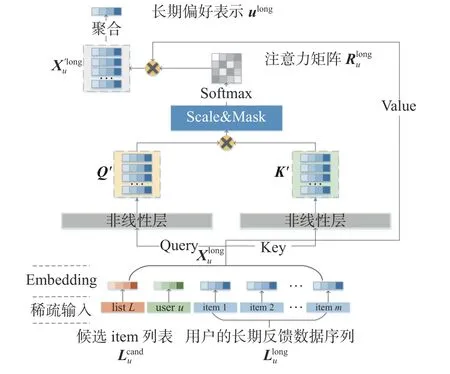
圖 3 自注意力層的結構Fig. 3 Structure of self-attention net


式(1)和(2)中的,WQ∈Rd×d=WK∈Rd×d分別為Query和Key非線性表示層的權重參數,ReLU(·) 在本模型中表示Leaky_ReLU激勵函數,Q′和K′分別表示Query和Key的非線性表示。Leaky_ReLU是ReLU的變體,解決了ReLU函數進入負區間后,導致神經元不學習的問題。




式中,對Xu′long聚合(如sum、max,這里采用均值),得到了用戶長期/一般偏好的表示ulong∈R1×d。
GRU(gate recurrent unit)層:與利用自注意力層提取用戶長期反饋數據之間的相互依賴不同,用戶短期反饋數據的重點是提取用戶短期反饋數據中的序列性偏好。GRU是RNN的一種,解決了長期記憶和反向傳播中的梯度等問題,且易于計算[16]。模型將用戶短期反饋數據Lsuhort輸入GRU,計算得到短期反饋數據表現出用戶的序列性偏好表示useq。模型GRU層的公式化表示如下:
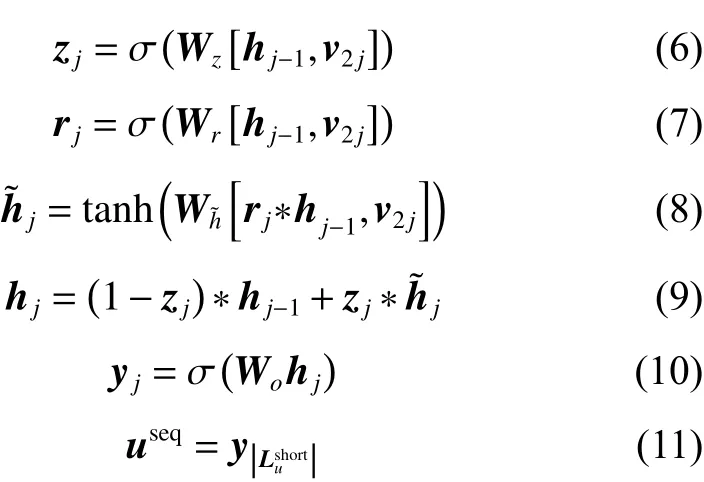



2.3 模型的參數學習
由模型的前向傳遞得到了用戶綜合偏好的表示ucomp,現在用內積方法如式(15)所示,表示ucomp和候選item v3j∈Lcuand的相似度,以表示用戶u 對候選item v3j的偏好得分 suj:

在隱反饋的推薦系統場景中,用戶往往沒有對item的具體評分,而只是交互記錄。這種情況下,推薦系統只有正樣本而缺乏負樣本,模型的訓練效果會因此受到影響[17]。
可以簡單地將與用戶沒有交互記錄的item作為用戶的負樣本,從而構造負樣本集。而模型只需要和正樣本集差不多大的負樣本集,這種做法會造成負樣本集龐大,且負樣本集的質量低下。
BPR方法[18]是一種基于矩陣分解的方法,一對用戶交互與未交互的兩個item項構成偏序關系對,一個用戶下item之間的偏序關系形成偏序矩陣,遍歷用戶集建立預測排序矩陣,BPR方法對預測排序矩陣分解生成用戶矩陣和item矩陣,用戶矩陣和item矩陣相乘可以得到用戶對每個item偏好程度。利用BPR方法生成低偏好程度的負樣本集,大小與正樣本集等同,參與訓練。
模型的Loss函數定義如下:

式中:D 表示用戶、正樣本、負樣本構造的訓練集;suj表示用戶 u 對正樣本候選item j的偏好得分;s′uk 表示用戶 u 對負樣本候選item k的偏好得分; σ (·) 表示sigmoid函數。第一個加號后的3項為正則項,Θe表示embedding層的權重參數;ΘA表示自注意力層和注意力層的權重參數;Θseq表示GRU層 的權重參數,λe、λA、λseq為對應的正則項系數。
3 實驗分析
3.1 實驗概述
數據集:本文選擇Tmall數據集[19]和Gowalla數據集[20]為模型進行訓練和測試,其中Tmall數據集是在中國最大電商平臺Tmall.com場景下的用戶行為日志數據集,Gowalla數據集是在社交簽到類應用Gowalla場景下的用戶行為日志數據集。
在實驗過程中,僅考慮7個月內在兩個數據集上生成的數據,并將1天內的用戶反饋數據視為表示短期反饋數據序列。
評價指標:選擇召回率(Recall)和AUC作為評價指標。召回率表示為用戶推薦偏好程度排序前N項的樣本為預測的正樣本,計算被正確預測的正樣本在原始正樣本集中比例;而AUC衡量了模型對樣本正確排名的能力。
方法對比:與其他先進模型在Tmall數據集和Gowalla數據集上的表現為對比[6,8,13-14,18,21](以其他文獻在Tmall數據集和Gowalla數據集上給出的實驗數據,或在Tmall數據集和Gowalla數據集復現的結果為準),以驗證模型的有效性:1) BPR是一種基于矩陣分解的方法,BPR方法對useritem偏序關系矩陣分解得到user矩陣和item矩陣,user矩陣×item矩陣得到用戶對每個item偏好程度,依據偏好程度排序得到推薦列表;2) FOSSIL利用馬爾科夫鏈估計用戶的短期和長期偏好;3) HRM對用戶偏好進行層次表示,捕獲用戶的長期/一般偏好和短期偏好;4) FPMC通過矩陣分解、馬爾科夫鏈提取序列信息,以估計用戶偏好,最后以線性方式計算得到推薦列表;5) AttRec利用自注意力機制在分析用戶短期反饋數據之間的相互依賴的同時,動態提取了用戶的短期偏好;6) SHAN利用注意力機制對長期和短期反饋數據建模,準確表達了用戶的長期/一般偏好;7) LSSSAN是本文的模型,利用自注意力機制和上下文估計長期/一般偏好,利用GRU分析短期反饋數據表現出的序列性偏好,并綜合長期/一般偏好和短期反饋數據序列參與注意力機制加權得到用戶的綜合偏好;8) LSSSAN1和LSSSAN2為本模型消融實驗的對照,LSSSAN1表示LSSSAN模型消去自注意力層后的模型(同時將長期反饋數據接入注意力層,自注意力層的上下文向量接入注意力層),LSSSAN2表示消去GRU層的模型。
3.2 方法對比
圖4和圖5展示了以召回率(N為10~60)和AUC為評價指標,各方法在Tmall數據集和Gowalla數據集上的表現。

圖 4 各方法在Tmall和Gowalla數據集上表現的對比Fig. 4 Performance comparsion of methods on Tmall and Gowalla datasets
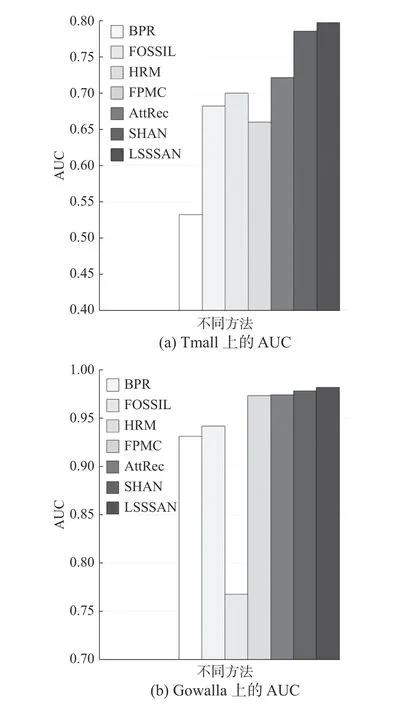
圖 5 各方法在Tmall和Gowalla數據集上表現的對比Fig. 5 Performancecomparsion of methods on Tmall and Gowalla datasets
1) LSSSAN在整體上優于基于自注意力的AttRec模型,LSSSAN在Tmall數據集上召回率(N為20)和AUC分別為0.126、0.797,在Gowalla上兩個指標分別為0.461、0.982。相比AttRec模型,LSSSAN在兩個數據集上指標召回率(N為20)分別提升了6.07%和20.49%,在兩個數據集上AUC指標分別提升了10.45%和0.81%。表明相比AttRec模型固定表達用戶的長期/一般偏好、忽視序列性偏好,LSSSAN的Self-Attenion層從長期反饋數據中提取了用戶的長期/一般偏好、GRU層從短期反饋數據中提取了用戶的序列性偏好、并從結構上賦予了短期反饋更高的權重,對推薦結果更有利。
2) LSSSAN在Gowalla數據集上的表現整體優于SHAN模型,在Tmall數據集上的表現與SHAN模型相比各有優劣。LSSSAN在Gowalla數據集上指標召回率(N為20)和AUC分別提升了1.51%和0.37%,在Tmall數據集上指標AUC分別提升了1.48%,而在Tmall數據集上指標召回率(N為20)落后于SHAN模型14.6%。其原因是Gowalla數據集用戶反饋數據之間的相互依賴和順序相關性比Tmall數據集嚴格,本文模型相比SHAN模型利用自注意力機制和GRU著重捕捉了用戶反饋數據之間的相互依賴和序列性,因此在Gowalla上LSSSAN的表現整體優于SHAN模型,而在Tmall數據集上的表現的穩定性不如SHAN模型。同時文獻[22]也表明,對于相互依賴和序列性強的簽到類型數據集,結合GRU的模型有較好的效果。綜上所述,相比SHAN對長期數據的相互依賴分析不足、忽視序列性偏好,LSSSAN的Self-Attenion層分析了長期數據的相互依賴、GRU層提取了序列性偏好,在推薦結果上具有更好的表現。
3.3 消融實驗
圖6和表1展示了消融實驗在Tmall和Gowalla數據集上的對照數據。
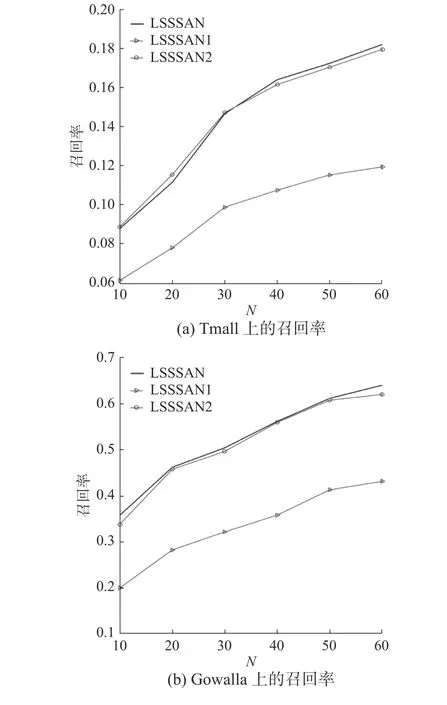
圖 6 LSSSAN在Tmall和Gowalla數據集上的消融實驗對照Fig. 6 Ablation study of LSSSAN on Tmall and Gowalla Datasets
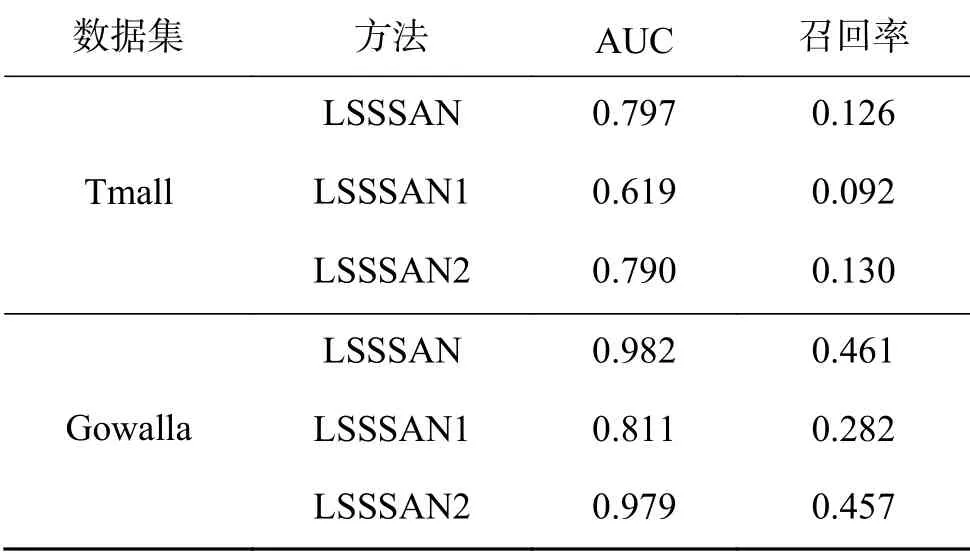
表 1 消融實驗對照表Table 1 Results table of ablation study
LSSSAN1為LSSSAN消去自注意力層后的模型,在兩個數據集上表現不佳。相比LSSSAN、LSSSAN1在兩個數據集上指標召回率(N為20)分別降低了26.98%和38.83%,其原因主要是消去自注意力層后模型缺乏對長期/一般偏好的表達,也降低了相對重要的短期反饋數據在模型中的權重。
LSSSAN2為LSSSAN消去GRU層后的模型,LSSSAN2在Gowalla上的兩個指標相比LSSSAN分別降低了0.87%、0.31%,LSSSAN2在Tmall上的AUC相比LSSSAN降低了0.89%,雖然LSSSAN2在Tmall數據集上指標召回率(N為20)相比LSSSAN提升了3.17%,但由圖6可以觀察到LSSSAN2在Tmall數據集上的整體表現稍劣于LSSSAN。以LSSSAN為基準,消去GRU層的LSSSAN2在Tmall數據集上的表現優于其在Gowalla的表現,其原因是Tmall數據集的順序相關性和相互依賴性不如Gowalla數據集嚴格。而LSSSAN與LSSSAN2相比,N參數較大時指標召回率較穩定,此時對推薦結果而言,GRU層提取序列性偏好的優勢會大于GRU層受非嚴格順序相關性和弱相互依賴性的影響而不穩定的劣勢。當數據集表現出明顯的非嚴格順序相關性和弱相互依賴性時,可以考慮以消去GRU層后的LSSSAN作為推薦模型的候選。
至此,消融實驗驗證了模型的GRU層和自注意 力層發揮的重要作用。
3.4 超參數分析
全局維度參數d反映了模型embedding和表示層的維度,圖7反映了在Tmall和Gowalla數據集上維度參數d對模型效果的影響。可以觀察到,高維度的表示可以更精確地表達用戶和item,并有助于和模型之間的信息交互。在實驗中,本模型權衡計算成本和模型精度,設置維度參數d=80。

圖 7 維度參數對模型的影響Fig. 7 Impact of dimension parameter
4 結束語
LSSSAN相比AttRec方法,利用長期反饋數據對長期/一般偏好進行準確表達,并從結構上賦予了相對重要的短期反饋數據更高的權重;相比SHAN方法,LSSSAN考慮了序列性偏好和長期數據中的相互依賴關系。
本文在Tmall和Gowalla上對LSSSAN進行訓練和測試,其效果整體優于其他先進的方案。且由于Gowalla數據集的反饋數據相互依賴性和順序相關性嚴格于Tmall數據集,模型在Gowalla上表現優于在Tmall上的表現,表明模型擅長于處理相對嚴格的相互依賴關系和順序相關性的數據,也表明模型可能會因為數據集數據的弱相互依賴性和弱順序相關性而出現不穩定的情況。同時本文通過消融實驗驗證了模型結構的合理性,并給出了當數據出現明顯的弱相互依賴性和弱順序相關性時的候選方案。
LSSSAN在實際應用上可為眾多互聯網應用提供推薦模型,尤其在數據具有強相互依賴性和順序相關性的互聯網應用上將會保證可靠的性能;未來的工作會考慮在LSSSAN的基礎上嘗試采用內存機制以提高性能,并在更多的數據集上測試模型性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國衛生(2015年9期)2015-11-10 03:11:12
創業家(2015年5期)2015-02-27 07:53:25
