空間站有效載荷預測性維護支持系統設計
2021-07-09 06:41:30施建明王功王偉李緒志
載人航天 2021年3期
施建明王 功王 偉李緒志
(中國科學院空間應用工程與技術中心,北京 100094)
1 引言
空間站空間應用系統有效載荷設備包括信息管理、供配電、熱控、氮氣供應等共用支持設備、空間科學實驗和技術試驗機柜、艙內外獨立載荷等。在空間站運營期,這些設施、設備長期運行,需要定期在軌維護、維修及系統升級。空間站有效載荷維修保障資源有限,修復性維修和定期維修精準性低、資源代價大,難以滿足空間站運行安全性、可靠性要求。預測性維護對設備進行狀態監測、持續對監測數據進行分析計算、評判設備的健康狀態、預測健康趨勢,為有效載荷制定更合理的維護維修計劃和備品備件上行方案。
NASA針對國際空間站任務開展了集成系統健康管理(Integrated System Health Management,ISHM)技術研究,并開發了狀態監測工具軟件,用于航天飛機、ISS控制力矩陀螺、ISS主動熱控系統的狀態監測任務。軟件的核心算法是K最近鄰(Knearest Neighbor,KNN)和聚類(Clustering),這些算法和工具在航天器健康監測上有較成功的應用。借鑒NASA的經驗,余晟等提出一種基于推演式聚類學習算法的衛星健康狀態監視系統,并通過熱控分系統的測試數據對該系統的有效性進行驗證,能較好地完成狀態識別與評估。
有效載荷方面,NASA在科學實驗柜接口定義文檔中對有效載荷的健康和狀態數據的定義、數據傳輸、處理、顯示等進行了規定。中國空間站有效載荷設計了一定的在軌故障診斷功能,并將故障事件和傳感器參數等數據下行至地面。同時,也開展了預測及健康管理(Prognostic and Health Management,PHM)相關方法、算法研究與地面健康管理軟件開發工作,通過制冷機在軌數據、熱控子系統地面測試數據等進行了技術驗證。
有效載荷產品種類較多,故障模式與機理復雜,需要采用不同算法處理大量的監測數據、訓練故障診斷和預測模型。為提升算法、模型及業務程序的開發和集成效率,各有效載荷產品應統一開發范式,解決標準不統一、接口不匹配、數據不一致等問題。且預測性維護技術相關方法、理論研究成果急需工程化的軟件和平臺來承載,并通過實測數據來實現技術驗證和迭代。為此,本文構建面向有效載荷的系統層預測性維護支持平臺,對核心的自動輔助建模軟件開展架構設計和基礎開發工作,為后續持續擴展和優化打下基礎。
2 預測性維護支持系統方案設計
有效載荷產品自身集成了一定的在軌故障自檢測和診斷功能,對影響安全性和重要功能的異常狀態進行實時檢測,采用閾值判斷的方式來實現,適用于故障需要立即響應的場景。預測性維護支持系統能充分利用地面的存儲和計算資源,對有效載荷長期運行積累的大量數據開展分析,能完成在軌不便開展的趨勢分析、多維監測數據聯合分析以及復雜機器學習模型的訓練、使用、評價與再訓練等任務。經過實際數據充分驗證的算法和模型,還能用于在軌故障檢測功能和性能的升級。
空間站有效載荷在軌出現故障時,很多情況下無法通過自診斷功能獨立確認要更換的目標部件,即在軌可更換單元(Orbital Replaceable Unit,ORU),而人工分析和排查往往費時費力。通過綜合分析有效載荷監測數據,調用診斷模型,結合推理邏輯,能實現故障的快速準確定位,這是預測性維護支持系統的智能診斷功能。有效載荷包含有退化特征的產品,例如泵組、過濾器、電池、制冷機等,建立性能退化模型,持續跟蹤退化趨勢,預測剩余壽命,為備件保障和維修準備提供預測性指示。此外,還需定期對設備、分系統、系統開展基于監測數據的健康評估,讓地面人員能全面掌握有效載荷健康動態。圖1為空間站有效載荷預測性維護支持系統的方案設計圖,由數據庫、自動輔助建模軟件、計算平臺、Web UI程序4個部分組成。

圖1 預測性維護支持系統方案Fig.1 Scheme of the predictive maintenance support system
2.1 數據庫
空間站有效載荷數據量大、來源多,為充分挖掘數據中對預測性維護有指導意義的信息,應統一規劃數據源。根據數據來源不同,分為研制階段產生的數據與運行階段產生的數據。以運行階段的數據為主要數據來源,根據需要提取研制階段的數據輔助分析。數據類型分為結構化數據和非結構化數據,針對不同數據類型選擇合適的數據庫。有效載荷監測數據以時序數據為主,在工業大數據、工業互聯網領域,InfluxDB、OpenTSDB等是常用的開源時序數據庫軟件,可用于存儲與管理有效載荷狀態監測數據。表1列出了預測性維護支持系統的數據源及相應的數據庫產品選型。

表1 預測性維護支持系統數據源Table 1 Data sources of PMSS
有效載荷運行狀態監測數據以遙測、工程數據(下行的狀態監測數據)為主,包含了在軌診斷(例如機內測試)給出的故障或異常狀態的指示量,在排除錯誤診斷的前提下,這些指示量可為數據標記提供重要的參考。數據通過天地通訊鏈路下行至地面,地面控制中心進行通訊管控,地面數據中心進行數據管理,預測性維護支持系統作為地面系統的一部分,提供非緊急故障的診斷、健康狀態長期跟蹤和預測等服務,允許一定的時間延遲。因此,數據庫可貼近業務端進行部署,以近實時的方式從數據中心獲取所需的數據。
2.2 自動輔助建模軟件
設計開發自動輔助建模軟件是為提供統一的有效載荷故障診斷和預測建模平臺,在此平臺上,建模專家和領域專家協作開展建模工作,把概率統計、信號處理、機器學習等數據建模技術同有效載荷產品知識和故障機理緊密結合起來,并進行快速迭代、集成與擴展。建模流程如圖2所示,具體步驟如下:
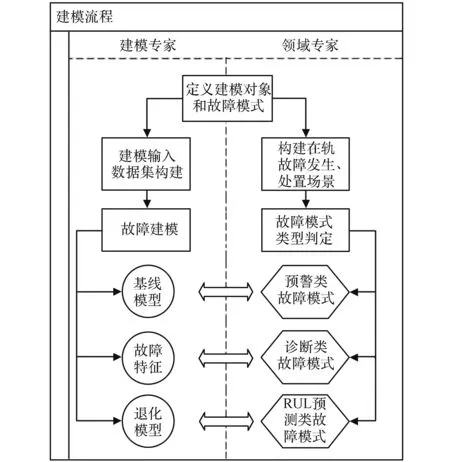
圖2 PHM建模流程Fig.2 PHM modeling process
1)定義建模對象和故障模式。根據有效載荷產品組成和FMEA報告等,建模專家和領域專家共同梳理出模型清單;
2)構建故障模式發生和處置場景,為建模提供應用依據;
3)對故障模式類型進行判定,包括預警類、診斷類及RUL預測類;
4)基于模型清單,對每個模型建立所需的輸入數據進行梳理,構建輸入數據集;
5)建立故障模型,包括用于故障預警的基線模型、用于故障診斷的特征識別模型、用于RUL預測的退化模型。
空間站有效載荷產品類型多樣、故障模式復雜、研制單位眾多,不同故障診斷、預測算法和模型應能以標準接口進行集成,并以統一范式實現。自動輔助建模軟件是預測性維護支持系統的核心部分,承載有效載荷數據智能分析、故障診斷與預測建模、模型優化及管理的功能,第3節將對輔助建模軟件的設計進行詳細論述。
2.3 計算平臺
自動輔助建模軟件生成的模型,由計算平臺調用完成數據計算處理,并將結果輸出,包括異常預警信號、故障診斷結果、指標預報或RUL預測值等信息。當數據量不大時,可在單臺計算機或服務器上完成計算任務。隨著數據量的增大,需要并行計算甚至分布式大數據計算平臺,以提高計算速度,滿足業務需求。
根據異常預警、故障診斷、預報預測等業務特點的要求,分別采用實時計算、觸發計算、定時計算等策略來實現對數據的計算處理。
2.4 Web UI程序
界面程序將與狀態監測和診斷相關的信息通過數據可視化的形式展示出來,包括基于2D、3D的設備畫面展示、基于儀表盤或圖表的數據展示等。UI界面顯示出的診斷、預測、預報等信息,可支持地面人員開展維護維修決策活動。
基于Web技術開發后端程序包括:①構建SpringBoot后端框架;②編寫數據庫訪問配置文件;③開發數據查詢與寫入程序。開發前端程序包括:①2D、3D顯示圖紙設計和代碼開發;②對圖元進行數據綁定配置,實現與后端測點的關聯。數據庫中的各類數據經由后端程序查詢后,設置到前端圖元、圖標上,實現數據的實時呈現。
3 自動輔助建模軟件設計
設計開放式、層次化、可擴展的軟件架構,不同有效載荷產品研制方可在統一的架構上增量式開發算法和模型,匯聚成空間站有效載荷預測性維護的算法庫和模型庫。
3.1 層次化架構與軟件包設計
自動輔助建模軟件的層次化架構設計如圖3所示,由接口層、特征層、算法層、模型層、應用層5個層級構成。
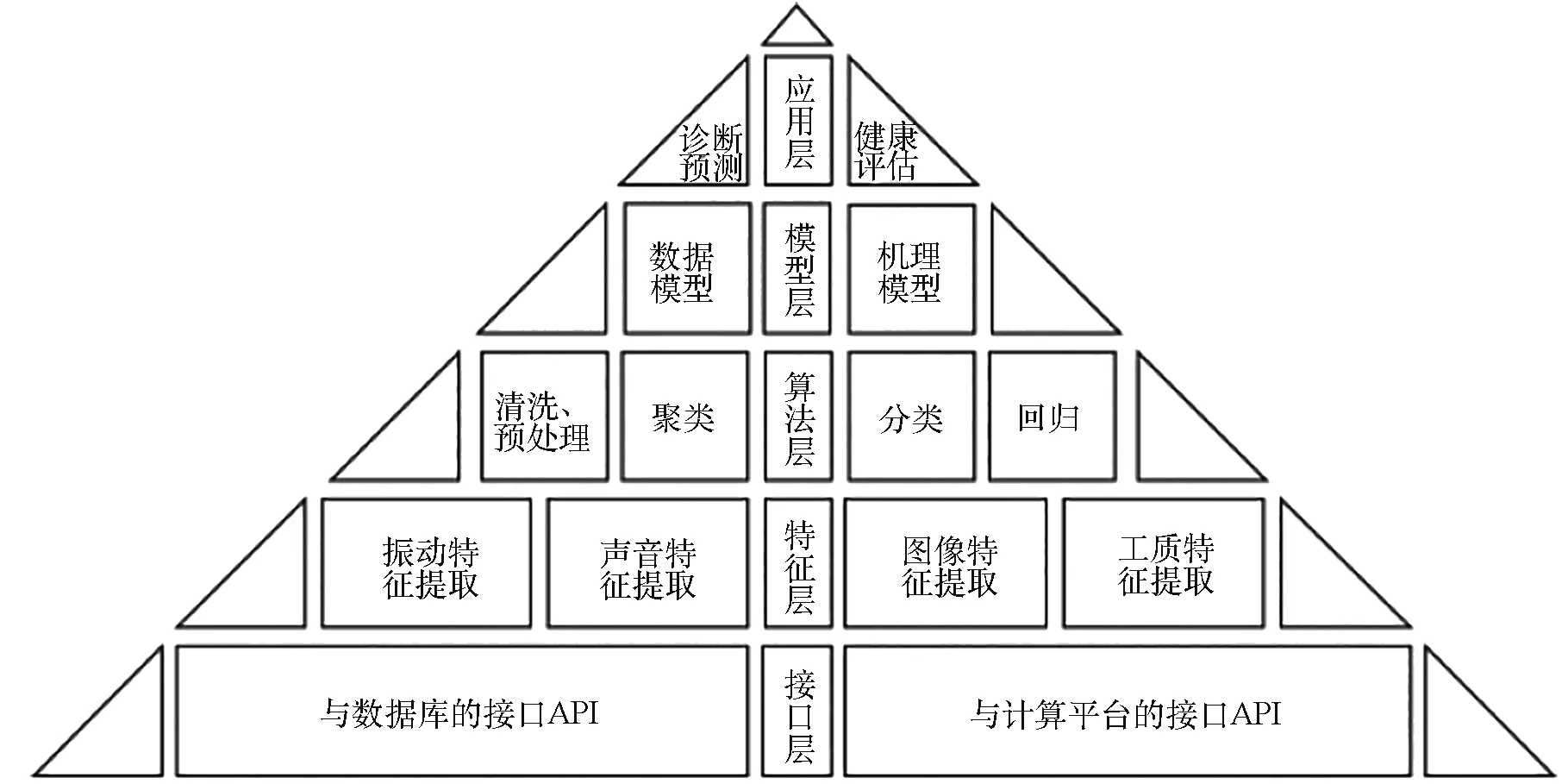
圖3 自動輔助建模軟件架構Fig.3 Architecture of the AAMS
基于圖3所示的層次化架構,構建與架構一一匹配的軟件包,由代表各層軟件子包組成,程序文件分門別類地放置在設計好的路徑下,方便函數的調用和類的實例化。程序集成、擴展和升級在軟件包的統一管理下有序開展。由于涉及大量復雜的工程計算和智能建模,自動輔助建模軟件可采用Matlab、Python等進行開發,利用已有的框架或工具來構建定制化的算法庫和模型庫,提高開發效率。圖4所示的軟件包是基于Matlab環境設計的,一級軟件子包分為“+api”、“+features”、“+algorithms”、“+models”、“+app”,其中“+”不可或缺,其作用是將子包納入可執行路徑下。

圖4 自動輔助建模軟件包組成Fig.4 The AAMS package
3.2 各層程序設計
3.2.1 接口層
接口層承載建模軟件與外部的接口程序,包括與數據庫的接口程序及與計算平臺的接口程序。通過與數據庫的接口,軟件可對數據庫進行讀寫操作,獲取所需的數據,并將處理后的輸出結果寫入數據庫。通過與計算平臺的接口和外部計算程序進行交互,使用外部計算資源,或由外部計算程序調用內部的模型和算法。
在“+api”文件夾下建立相應數據庫接口程序的二級子包,例如“+InfluxDB”、“+TSDB”等,包括數據庫配置文件、配置文件解析程序、數據查詢程序、數據寫入程序等。
為便于開發人員調用建模軟件包中的程序,在接口層提供相應的API(Application Programming Interface)。通過接口層,自動輔助建模軟件方便集成到預測性維護支持系統中,或移植到已有的運維平臺上去使用。
3.2.2 特征層
有些情況下,故障特征與原始監測數據無直接的關聯,例如設備振動信號、聲音信號、圖像數據、工質理化特性等。需要采用特征提取程序將原始數據轉化成相應的特征數據。
在建模軟件中設計特征層,將可能用到的特征提取程序歸于“+features”路徑下。一般包括特征配置文件、配置文件解析程序、特征提取函數、特征提取腳本等。
通過特征提取出的中間數據可寫入到數據庫中,或保存在“+features”下的FeatureData路徑下,便于統一管理。
3.2.3 算法層
在工業系統預測性維護場景中,數據驅動是當前的主流,在“+algorithms”算法包中,除了數據清洗、預處理、聚類、分類、回歸等算法程序外,還有數據集構造、流程檢查等輔助性程序。在運營階段初期,大部分有效載荷處于正常狀態,通過聚類算法或回歸算法可學習健康基線,得到各種運行模式下的正常類簇或參數關聯模型。通過類簇識別、偏移量計算能發現異常征兆。隨著有效載荷出現退化或故障,提取特定窗口的多維監測數據用于構造數據集。通過回歸算法能訓練相應的預測模型,用于預測未來健康退化趨勢和RUL;通過分類算法能訓練故障特征識別模型,用于故障診斷。
為提高算法開發和使用算法分析數據的效率,需設計一種標準化同時又具有彈性的數據處理機制,包括標準化算法類設計、彈性數據處理模板和可追溯的算法比對機制。
1)標準化算法類設計。首先,設計7個算法父類,分別是數據清洗算法Cleaner、數據預處理算法Preprocessor、聚類算法Clusteringer、分類算法Classifier、回歸算法Regressor、深度學習回歸算法(Long Short Term Memory,LSTM)、深度學習分類算法(Convolutional Neural Network,CNN)。每個父類下繼承了多個具體的算法子類,例如聚類下有Kmeans聚類、層次聚類、自組織映射等。其次,每個算法子類采用標準的框架設計,類的屬性為算法參數,類方法主函數是數據處理流程,包括數據輸入、算法參數設置文件導入、交叉驗證數據集構造(必要時)、核心處理模塊、結果整理和輸出。
2)彈性數據處理模板。建模時可采用單一算法處理數據,也可采用多算法串接的方式處理數據,并有不同算法、不同算法參數設置比對的需求。為不重復編寫算法代碼,且能靈活配置算法和設置算法參數,采用數據和算法分離的策略模式及多算法串接的模板模式。串接多算法形成數據處理流程后,調用流程檢查程序,確保所構造的流程符合數據分析處理的邏輯。
3)可追溯的算法對比機制。設計一種可追溯的比對機制,使得建模人員能快速完成模型批訓練、批測試,并回看不同算法參數設置下的模型評分,自動導出最優的算法參數和模型。在標準算法類設計時考慮算法調參和比對問題,算法每次調用都會自動去讀取相應的參數設置文件,通過記錄每次參數設置及對應的評分來進行追蹤。
3.2.4 模型層
輔助建模軟件的模型層包括數據模型和機理模型。基于聚類、分類、回歸等算法對數據進行處理所輸出的模型即數據模型:聚類模型是聚類分析得到的類簇信息,包括類簇的中心、半徑及其標記;分類模型是通過分類算法處理得到的模型,如決策樹(Decision Tree,DT)分類模型、支持向量機(Support Vector Machine,SVM)分類模型、淺層神經網絡(Neural Network,NN)分類模型、卷積神經網絡CNN分類模型等;回歸模型是通過回歸算法得到的模型,如線性回歸(Linear Regression,LNR)模型、非線性回歸(Nonlinear Regression,NLR)模型、關聯向量回歸(Relevance Vector Regression,RVR)模型、序列到序列LSTM回歸模型等。在“+models”下建立ModelLearned路徑,將訓練好的模型保存在該路徑下,也可導出為標準數據格式的文件用于其他分析軟件或平臺。
與有效載荷產品層級一一對應,構建故障診斷和預測的機理模型。以有效載荷熱控系統為例進行說明,“+models”下建立“+ThermalControlSystem”二級軟件子包,所有熱控系統相關的模型層程序文件均放置在該路徑下。
首先,“+ThermalControlSystem”下建立@Component文件夾,在此文件夾中定義一個抽象的父類Component,在Component父類中定義熱控系統及其部件的通用屬性,例如名稱(Name)、設計參數(Design Param)、輸入數據(Input Data)、故障診斷和預測模型、診斷結果等屬性,其中,診斷結果屬性包含運行模式(Opt Mode)、健康基線(Base Line)、異常檢測結果(Is Anormal)、故障模式(Fault Mode)、健康狀態(Health Status)健康指標(Health Indices)等。
然后,構建熱控系統模型子類包:@Thermal-ControlSystem、@Pumppackage、@Accumulator、@Pipeline、@Controller、@Filter、@Sensor等,涵蓋熱控的系統級模型和部件級模型。在子類方法中,編寫診斷模型或預測模型的建模邏輯函數,該函數調用算法進行建模,或者從已訓練好的模型庫中導入模型,并對數據模型和產品的實際故障進行關聯。例如,在@ThermalControlSystem子類文件夾下構建ThermalControlSystem子類,在該子類方法中定義用于構建熱控系統健康狀態識別所用聚類模型的函數,該函數的主要功能是調用聚類算法(需要時增加數據清洗、預處理算法)處理輸入數據,得到聚類模型,并對設定的健康狀態和類簇進行關聯綁定。這樣,實例化ThermalControlSystem子類后,就可以通過調用相應的方法來完成針對具體業務的建模任務。
3.2.5 應用層
應用層是軟件的頂層,包括主程序及下屬的異常檢測、故障診斷、健康評估、健康指標合成、預測性分析等子程序。子程序各司其職,每個程序實現自己的單一職能。根據需求和場景的不同,預測性維護業務可對監測數據開展實時分析診斷,輸出異常檢測和故障診斷結果;可在發現指標異常偏離基線后,對指標進行預測,并對可能的風險進行預警;可定期開展健康狀態評估;還可在健康狀態發生變化時開展RUL預測等。建立以業務流為主線的主程序,并調用下屬各子程序,應用層以類似于搭積木的方式靈活快速地搭建好特定的業務流程。
此外,還可開發圖形用戶界面應用(GUI App),便于建模人員、領域專家開展離線數據分析和建模,并對后臺業務進行可視化的操控和實時分析結果查看。
4 開發與測試實例
4.1 采用策略模式分離數據和算法
在對產品狀態監測數據進行處理時,經常會遇到需要對數據施加不同算法的情形。聚類(Clustering)分析常用來識別設備的工作狀態,聚類算法有很多種,如Kmeans、Hierarchical Clustering(HC)、SOM(Self Organizing Map)等。在用聚類算法進行建模時,需要對比不同的算法,每種算法下面又有不同的算法參數需要設置。通過策略模式能將算法封裝起來,用戶可方便地選擇或替換算法,而算法也獨立于數據。圖5為采用策略模式開發聚類算法的統一建模語言(Unified Modeling Language,UML)圖。
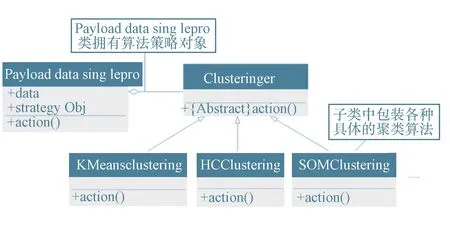
圖5 策略模式分離算法和數據Fig.5 Separation between algorithm and data based on strategy pattern
各類之間通過如下的機制進行協作,以實現數據和算法的分離:
1)在PayloadDataSinglePro類對象中存放數據,而在Clusteringer子類對象中存放算法,PayloadDataSinglePro類的屬性strategyObj指向具體的Clusteringer子類對象,可以對該屬性的重新賦值來自由地更換算法;
2)PayloadDataSinglePro類對象把對具體的數據處理請求轉交給Clusteringer子類對象;
3)當轉交計算請求時,PayloadDataSinglePro類對象把自己作為一個參數傳遞給Clusteringer子類對象方法中action函數,從而使得子類對象擁有了計算所需要的數據。
4.2 結合策略模式和模板模式實現數據處理模板
當需要采用2個或2個以上算法串接來處理設備監測數據時,就需要構造一種既符合數據處理流程邏輯,又可靈活配置算法的數據處理模板。不論數據如何變化,也不論數據處理流程如何改變,封裝好的算法類始終保持不變,只是每次處理所選的算法和算法組織順序有所不同。
采用多算法來處理數據有一套固定的流程,全流程處理遵循數據清洗、數據預處理、機器學習3個骨干步驟,這3個骨干步驟是不能顛倒順序的。另外根據數據處理目標的不同,數據處理流程有以下6種模板:①僅選擇數據清洗步驟中的多個算法;②僅選擇數據預處理步驟中的多個算法;③選擇跨數據清洗、數據預處理2個步驟中的多個算法;④選擇跨數據清洗、機器學習2個步驟中的多個算法;⑤選擇數據預處理、機器學習2個步驟中的多個算法;⑥選擇跨3個骨干步驟中的算法。這里假定機器學習算法一次處理只采用1種算法。
首先設計一個數據處理基類PayloadDataPro,將固定的處理步驟封裝在PayloadDataPro的templateMethod方法中,然后設計6個數據處理子類PdConcretePro1~PdConcretePro6,與上述6種數據處理模板一一對應。為子類能夠自由選擇算法,在PayloadDataPro的屬性中定義strategyObj,使得基類擁有策略對象,以聚類算法Clusteringer為例,該設計的UML如圖6所示。PayloadDataPro類中的templateMethod要聲明成封裝的方法(Sealed),在基類中約定固定的數據處理流程,保證子類不會違反順序,3個骨干步驟的方法要聲明成抽象(Abstract)和訪問受保護(Access=protected),以此固定接口且強制要求子類必須實現相應骨干步驟。PdConcretePro子類實現3個骨干步驟具體數據處理流程,方法聲明為protected,以保證這些方法只能被內部的方法templateMethod調用。

圖6 結合策略模式與模板模式構建有效載荷數據處理流Fig.6 Payload data processing flow constructed by strategy pattern and template pattern
4.3 數據分析與建模測試
采用公開的燃料電池耐久性試驗數據來測試自動輔助建模軟件的可用性,電池堆的總輸出電壓Utot反映設備的性能或健康狀態,隨著時間積累,Utot呈現下降的趨勢,燃料電池性能逐漸退化。主要開展以下2方面的測試:①對比KMeans算法和HCClustering算法,測試算法更換和調參模式;②先采用MidFilter中值濾波算法進行數據清洗,后采用Kmeans或HC聚類算法進行聚類,檢驗數據處理流程的設計。
采用4.1、4.2節中的開發策略,開發出算法類、數據處理類等程序,然后編寫相應的測試腳本,對電池數據進行建模分析。以MidFilter+HC為例進行說明,如表2所示。

表2 數據分析與建模測試腳本Table 2 Testing script for data analysis and modeling
在執行聚類分析時,程序自動讀取參數設置文件,實現不同參數下的模型訓練,當需要更改算法時,只需要對測試腳本做簡單的更改即可,例如將聚類算法改成Kmeans算法,將表2程序的第4行改為mlStrategy=MachineLearning.KMClustering()即可。
評分采取Calinski-Harabasz(CH)準則,CH指標通過計算類中各點與類中心的距離平方和來度量類內的緊密度,通過計算各類中心點與數據集中心點距離平方和來度量數據集的分離度,CH指標由分離度與緊密度的比值得到。CH越大代表著類自身越緊密,類與類之間越分散,即更優的聚類結果。
表3展示了聚類分析不同算法或算法組合和不同參數設置下的評分,其中采用中值濾波加Kmeans且分類數為4時得到的聚類模型最佳。

表3 聚類分析評分結果Table 3 Scores of data clustering with different algorithms
5 結論
本文提出了一種可行的預測性維護支持系統框架,設計了自動輔助建模軟件架構,并進行了基礎開發,解決了相關算法、模型和業務程序開發缺少統一標準的問題。已開發出算法庫,建模人員無需重復編寫算法代碼即可快速完成常見數據驅動故障診斷和預測建模工作,能提高大量數據處理和建模時的效率。此外,通過外部接口定義和接口程序,自動輔助建模軟件易于部署,與系統其他模塊的集成也十分便利。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
人大建設(2019年12期)2019-05-21 02:55:44
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
光學精密工程(2016年6期)2016-11-07 09:07:19
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
