基于多任務(wù)的多標(biāo)簽文本分類
2021-07-09 17:19:26覃杰
現(xiàn)代計(jì)算機(jī) 2021年14期
覃杰
(四川大學(xué)計(jì)算機(jī)學(xué)院,成都 610065)
0 引言
隨著時(shí)代的飛速發(fā)展,人機(jī)對(duì)話技術(shù)變得愈發(fā)重要。對(duì)話意圖的識(shí)別是通過(guò)文本分類任務(wù)實(shí)現(xiàn)的,而普通的文本多分類任務(wù)不能滿足人機(jī)對(duì)話中復(fù)雜意圖的識(shí)別功能,取而代之的是多標(biāo)簽文本分類任務(wù)。與傳統(tǒng)的文本多分類不同的是,現(xiàn)實(shí)生活中存在的大量數(shù)據(jù)其實(shí)是對(duì)應(yīng)多個(gè)類別的。例如一篇文章可能涵蓋了文化、科技、教育相關(guān)多個(gè)類別。多標(biāo)簽文本分類任務(wù)較傳統(tǒng)的文本分類任務(wù)的計(jì)算更為復(fù)雜,主要表現(xiàn)在一個(gè)樣本的文本特征需要與多個(gè)標(biāo)簽產(chǎn)生關(guān)聯(lián),這就要求更精細(xì)化的特征抽取并且正確地映射到對(duì)應(yīng)的標(biāo)簽上。此外,標(biāo)簽附帶的額外信息應(yīng)該被充分的利用起來(lái),而不能僅僅簡(jiǎn)單的作為一個(gè)分類ID 處理。
早期的多標(biāo)簽文本分類任務(wù)一般將多標(biāo)簽問題轉(zhuǎn)化為各個(gè)標(biāo)簽的二分類問題[1],然而這種方法忽略了標(biāo)簽之間的關(guān)聯(lián)關(guān)系并且當(dāng)標(biāo)簽數(shù)量過(guò)大的時(shí)候,模型的數(shù)量呈線性增加。后來(lái)Read et al.(2011)提出了鏈?zhǔn)蕉诸惸P蛠?lái)建模標(biāo)簽之間的高階關(guān)聯(lián)關(guān)系[2],但是計(jì)算復(fù)雜度依然十分龐大。隨著神經(jīng)網(wǎng)絡(luò)的興起,深度學(xué)習(xí)模型如CNN、LSTM 憑借其強(qiáng)大的特征抽取能力,在自然語(yǔ)言處理的眾多任務(wù)中成為主流模型。CNN[3](Kim,2014)采用多核卷積抽取文本特征,多個(gè)卷積核可以抽取不同窗口大小的文本特征,豐富了句子特征的表達(dá)。CNN-RNN[4](Chen et al.,2017)使用CNN和RNN 捕獲了局部和全局語(yǔ)義特征建模標(biāo)簽的內(nèi)在關(guān)聯(lián)關(guān)系。近期,SGM[5]模型,通過(guò)生成式seq2seq 結(jié)構(gòu),來(lái)建模標(biāo)簽間的依賴關(guān)系得到了很好的效果,但是標(biāo)簽之間的關(guān)系是復(fù)雜的,線性的標(biāo)簽解碼存在一定的不足。LSAN[6]模型,利用標(biāo)簽語(yǔ)義信息確定標(biāo)簽與文檔之間的語(yǔ)義聯(lián)系,構(gòu)造特定于標(biāo)簽的文檔特征表示,通過(guò)自注意力機(jī)制,捕獲屬于特定標(biāo)簽的文本信息,在多個(gè)數(shù)據(jù)集上獲得了優(yōu)異的成績(jī)。
本文基于LSAN 模型,引入多任務(wù)機(jī)制,通過(guò)計(jì)算文本與標(biāo)簽的相似度分?jǐn)?shù)作為輔助任務(wù),聯(lián)合相似度計(jì)算loss 和多標(biāo)簽分類loss 優(yōu)化模型,相關(guān)指標(biāo)得到進(jìn)一步提升。
1 算法實(shí)現(xiàn)
1.1 LSAN模型
LSAN 模型由三個(gè)主要部分構(gòu)成,第一部分是由Bi-LSTM 構(gòu)成的特征提取層,第二部分是由文本自注意力機(jī)制提取文本特征的嵌入表示和標(biāo)簽注意力機(jī)制提取標(biāo)簽特征嵌入表示組成。第三部分是融合文本和標(biāo)簽的嵌入特征進(jìn)行預(yù)測(cè)的全連接網(wǎng)絡(luò)。具體模型結(jié)構(gòu)如圖1 所示。
模型結(jié)構(gòu)不同層的相關(guān)定義和功能表達(dá)如下:
(1)Bi-LSTM
雙向LSTM 模型在LSAN 模型中主要用于提取文本的詞特征嵌入表示。為了解決傳統(tǒng)的RNN 的長(zhǎng)期以來(lái)問題和梯度消失問題,Hochreiter 和Schmid huber提出了LSTM 模型。該模型引入了自適應(yīng)門控機(jī)制來(lái)決定LSTM 的狀態(tài)單元在某時(shí)刻保存多少上一個(gè)時(shí)刻的狀態(tài)信息,以及提取當(dāng)前輸入特征的程度。Bi-LSTM 在LSTM 的基礎(chǔ)上增加了反向的LSTM 單元,使得在正向提取特征的情況下,又能進(jìn)行逆序特征提取,從而獲得了更好的特征抽取能力。LSTM 由三部分組成:輸入門、忘記門、輸出門。所有門控單元使用當(dāng)前輸入和上一時(shí)刻的隱層狀態(tài)hi及當(dāng)前細(xì)胞單元狀態(tài)活值ci來(lái)計(jì)算下一時(shí)刻的細(xì)胞單元狀態(tài)。具體公式如下:

其中it,ft,ot分別對(duì)應(yīng)t時(shí)刻的輸入門、忘記門、輸出門的信息,Ct為t 時(shí)刻的細(xì)胞狀態(tài),W為對(duì)應(yīng)權(quán)重參數(shù),b為對(duì)應(yīng)的偏置項(xiàng)。
(2)Self-Attention[7]和Label-Attention
自注意力機(jī)制主要用于抽取文本的高階特征。自注意力機(jī)制是由(Lin et al.,2017)提出的,成功地在各種文本任務(wù)上取得了很好的表現(xiàn)。注意力機(jī)制的計(jì)算過(guò)程由信息輸入,計(jì)算注意力分布,根據(jù)注意力分布來(lái)計(jì)算輸入信息的加權(quán)平均組成。具體的公式如下:

A(s)是文本的自注意力得分矩陣,M(s)j是由注意力得分加權(quán)到文本隱層表征對(duì)應(yīng)的j類標(biāo)簽的結(jié)果。其中,W2∈Rc×da,k為embedding 維數(shù),c為標(biāo)簽數(shù)目,da為超參數(shù)可以調(diào)整。H∈R2k×n為Bi-LSTM 輸出的隱層張量,M(s)∈Rc×2k是通過(guò)自注意力機(jī)制進(jìn)行文本特征抽取的所有標(biāo)簽的具體化表示。
標(biāo)簽注意力機(jī)制主要是通過(guò)Bi-LSTM 的隱層張量與標(biāo)簽嵌入計(jì)算注意力得分然后將得分與Bi-LSTM輸出的隱層張量加權(quán)計(jì)算得到具有標(biāo)簽注意力分?jǐn)?shù)的文本特征的隱層表示。具體公式如下:
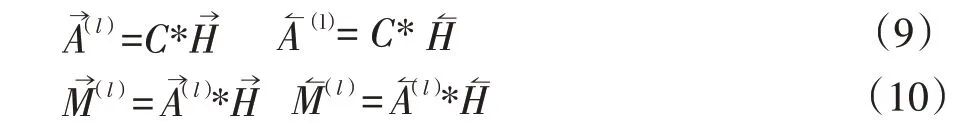
其中C是標(biāo)簽嵌入向量,A→為C與H→計(jì)算出的注意力分?jǐn)?shù),M?(l)為最終文本在標(biāo)簽注意力下的嵌入表示。
(3)基于注意力的適應(yīng)性融合策略
M(S)側(cè)重于文檔內(nèi)容,M(l)側(cè)重于文檔內(nèi)容與標(biāo)簽文本之間的語(yǔ)義關(guān)聯(lián)。通過(guò)一個(gè)全連接層經(jīng)過(guò)sig?moid 函數(shù)計(jì)算各自的分?jǐn)?shù),進(jìn)行適應(yīng)性加權(quán)得到最終的特定于標(biāo)簽的文檔特征表示。具體公式如下:


1.2 多任務(wù)實(shí)現(xiàn)
多任務(wù)機(jī)制是同時(shí)考慮多個(gè)相關(guān)任務(wù)的學(xué)習(xí)過(guò)程,目的是利用任務(wù)間的內(nèi)在關(guān)系來(lái)提高單個(gè)任務(wù)為學(xué)習(xí)的泛化性能。在多標(biāo)簽文本分類中,建模標(biāo)簽和文本的關(guān)系不僅可以通過(guò)上述注意力機(jī)制來(lái)實(shí)現(xiàn),也可以通過(guò)計(jì)算標(biāo)簽嵌入表示和文檔句向量表示的相似度來(lái)實(shí)現(xiàn)。假設(shè)某一訓(xùn)練樣本屬于A標(biāo)簽,那么A標(biāo)簽的嵌入表示和該樣本的句子表示就應(yīng)該比較接近。具體的公式如下:

訓(xùn)練文本對(duì)應(yīng)分類的標(biāo)簽嵌入向量與該文本嵌入向量的相似度較高,所以通過(guò)公式(15)計(jì)算得到的loss值相對(duì)較低,而不屬于該訓(xùn)練樣本的其他標(biāo)簽計(jì)算得到的相似度較低,則得到的loss值較高。
2 算法實(shí)現(xiàn)
2.1 實(shí)驗(yàn)環(huán)境與數(shù)據(jù)
為了驗(yàn)證加入多任務(wù)相似度計(jì)算的有效性,本文在Ubuntu18 操作系統(tǒng),配備顯卡(NVIDIA GTX1660 6GB),以及深度學(xué)習(xí)框架PyTorch 的環(huán)境下進(jìn)行仿真實(shí)驗(yàn)。數(shù)據(jù)部分本文采用了Arxiv Academic Paper Da?taset 數(shù)據(jù)集,該數(shù)據(jù)是由Yan 論文中[5]提供,該數(shù)據(jù)集從包含了55840 每篇學(xué)術(shù)論文摘要以及對(duì)應(yīng)54 個(gè)不同的學(xué)科標(biāo)簽主題。一篇學(xué)術(shù)論文摘要可能對(duì)應(yīng)多個(gè)學(xué)科名稱。通過(guò)將該數(shù)據(jù)集劃分為訓(xùn)練集、驗(yàn)證集以及測(cè)試集。模型訓(xùn)練結(jié)束采用在驗(yàn)證集上模型效果最好的模型作為測(cè)試集的預(yù)測(cè)模型。其中訓(xùn)練集、驗(yàn)證集、測(cè)試集的大小分別設(shè)置為:53840、1000、1000。
2.2 數(shù)據(jù)預(yù)處理
對(duì)AAPD 數(shù)據(jù)集進(jìn)行簡(jiǎn)要的數(shù)據(jù)分析,其中訓(xùn)練集和測(cè)試集的句子長(zhǎng)度分別為163 和171。為了覆蓋大部分?jǐn)?shù)據(jù)集,我們將句子長(zhǎng)度設(shè)定為500,不足部分進(jìn)行不全,超過(guò)的部分進(jìn)行截?cái)唷榱藢?shí)現(xiàn)相似度計(jì)算任務(wù),需要對(duì)句子真實(shí)長(zhǎng)度進(jìn)行標(biāo)記,以便在實(shí)驗(yàn)的過(guò)程中,實(shí)現(xiàn)補(bǔ)全token 的掩碼,從而提取到句子真實(shí)長(zhǎng)度的隱層向量特征的平均表達(dá)。
2.3 模型訓(xùn)練
數(shù)據(jù)經(jīng)過(guò)預(yù)處理后,使用Google Word2Vec 預(yù)訓(xùn)練詞向量(300 維),構(gòu)成文本的嵌入矩陣,得到Bi-LSTM的輸入embedding 特征。標(biāo)簽的嵌入向量維數(shù)也取300 維,通過(guò)隨機(jī)初始化生成。Bi-LSTM 中的隱層單元設(shè)置為500,批處理大小(batchsize)設(shè)置為64,每個(gè)樣本長(zhǎng)度通過(guò)截?cái)嗪脱a(bǔ)齊固定為500,激活函數(shù)采用ReLU,學(xué)習(xí)率設(shè)定為0.001,da 參數(shù)設(shè)置為200,b 設(shè)置為256。模型訓(xùn)練損失函數(shù)采用BCE(Binary Cross En?tropy)loss。使用Adam 優(yōu)化器。模型訓(xùn)練過(guò)程中損失函數(shù)值以及P@1,P@2,P@3 指標(biāo)變化情如圖2 所示。
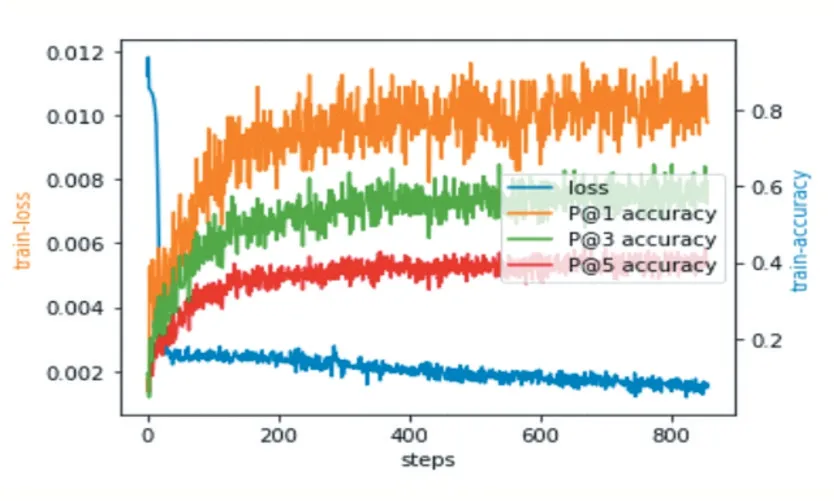
圖2 Loss及指標(biāo)變化
2.4 仿真實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)對(duì)比了對(duì)比加入了多任務(wù)相似度計(jì)算的LSAN 模型與未修改的模型訓(xùn)練結(jié)果。相關(guān)結(jié)果如表1 所示。定義改進(jìn)的方法名字為MT-LSAN。評(píng)估指標(biāo)采用Top-K 中的精確度。公式定義如下:
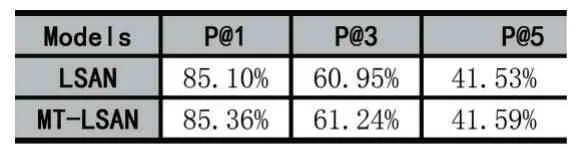
表1 對(duì)比實(shí)驗(yàn)結(jié)果

其中k表示取排名從高到底的前k個(gè)標(biāo)簽的預(yù)測(cè)值進(jìn)行精度計(jì)算,l表示對(duì)應(yīng)的標(biāo)簽類別。
通過(guò)對(duì)比實(shí)驗(yàn)可以發(fā)現(xiàn),加入多任務(wù)機(jī)制的模型,其精度得到了一定的提升,其中P@1 提高了0.26%,P@3 提高了0.29%。仿真實(shí)驗(yàn)結(jié)果表明,加入了多任務(wù)機(jī)制的模型試驗(yàn)結(jié)果得到了一定的提升。
3 結(jié)語(yǔ)
本文在LSAN 模型的基礎(chǔ)上通過(guò)引入標(biāo)簽與文本相似度計(jì)算的多任務(wù)機(jī)制,豐富了標(biāo)簽自身的隱含信息,使得文本內(nèi)容與標(biāo)簽的關(guān)聯(lián)關(guān)系變得更加緊密,在現(xiàn)有的實(shí)驗(yàn)結(jié)果上獲得了一定的提升。在現(xiàn)有的對(duì)話系統(tǒng)意圖識(shí)別中,多標(biāo)簽文本分類可以解決多意圖識(shí)別問題,該模型具有一定的應(yīng)用指導(dǎo)意義。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
文苑(2018年21期)2018-11-09 01:23:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國(guó)衛(wèi)生(2015年9期)2015-11-10 03:11:12
中國(guó)衛(wèi)生(2014年3期)2014-11-12 13:18:12
