基于深度學習的FPL 報文航路糾錯研究
2021-07-09 17:19:30郭舒言
現代計算機 2021年14期
郭舒言
(四川大學視覺合成圖形圖像技術國防重點學科實驗室,成都 610065)
0 引言
航空固定電信網(Aeronautical Fixed Telecommuni?cation Network,AFTN)格式電報供空中交通管制部門使用,共包括16 類,領航計劃報(Filed Light Plan Mes?sage,FPL)是其中使用頻率最高的報文,由空中交通服務單位根據航空器運營人或代理人提交的飛行計劃數據,拍發給沿航路所有相關空中交通服務單位。FPL報對于保證飛行安全和提高工作效率有著十分重要的意義,也由此對其正確性提出較高要求。但由于報文是由人工進行編寫和拍發,實際工作中難免出現錯漏,收報單位在解析航路時,若發現航路中存在系統無法識別的航路點或發現某航路點偏離航路,需將報文發送至人工席等待處理[1]。本文設計的FPL 報文自動糾錯方法旨在報文發送端識別錯誤航路并給出修正提示,從而節省人力、物力資源,在實際工作場景中具有一定的應用價值[1]。
目前對于報文的處理多集中于報文解析[3]和格式層面[4]的糾錯,本文則針對報文航路內容層面進行糾錯,將報文看作一種具有特殊規則的語言,把報文糾錯任務視為文本糾錯任務,引入基于深度學習的自然語言處理技術。Transformer 模型是Google 于2017 年提出的一種新型網絡結構[5],其在保持經典的“編碼器-解碼器”結構的同時,拋棄傳統的循環神經網絡和卷積神經網絡,僅使用注意力機制,并行結構提升了訓練效率,且獲得了較高的準確度。本文通過實驗驗證了Transformer 模型在報文糾錯上的有效性,同時根據報文特點提出一種基于N-Gram 思想的結果修正機制,通過片段共現詞打分的方法對修改進行取舍,進一步提高了報文糾錯的正確率。
1 背景
文本糾錯任務是指通過分析輸入句子成分之間的依賴性和邏輯性,對其中出現的多詞、少詞、錯詞或搭配不當等錯誤進行識別并自動修正,從而獲得更流利的句子[6],該任務多以自然語言為研究主體。傳統的文本糾錯任務研究方法主要包括:①基于規則的方法,利用語言學知識針對特定錯誤進行糾正[7];②基于統計的方法,如數據驅動的傳統機器學習[8]和分析利用上下文信息的N-Gram 模型[9-10]。
將文本糾錯任務看作翻譯任務,即把糾錯過程看作將錯誤文本改成正確文本的翻譯過程,為糾錯任務的研究提供了新思路。Brockett 等人[11]首先采用該方法,并提出了一個基于短語統計的機器翻譯糾錯模型。Ehsan 等人[12]針對上下文敏感錯誤檢測,提出了一種基于規則和統計機器翻譯相結合的方法。隨著深度學習的發展,基于端到端的深度神經網絡的機器翻譯方法興起[13-14],也被應用到文本糾錯任務中。Chollam?patt 等人[15]結合N-Gram 信息,提出一種基于多層卷積的端到端神經網絡的改進語法自動校正方法。郝亞男等人[16]提出一種基于BiGRU 和注意力機制的中文文本校對方法,能較好地捕捉詞間語義邏輯關系。黃浩洋[17]提出一種結合預訓練方法獲得語義信息嵌入的堆疊深度神經網絡模型。周旺[18]提出一種反饋過濾算法,結合Seq2Seq 模型構建了英語語法糾錯模型。
2 FPL報文說明
根據《民航飛行動態固定格式電報管理規定》,一條完整的FPL 報文應包括9 個編組,如下所示,“(”代表報文開始,“)”代表報文結束,各編組間用“-”隔開,編組內有多個數據項的用空格或“/”隔開。
FPL 報文構成說明

本文中,只提取每條FPL 報文中編組13 的起飛機場代碼、編組15 的航點(線)代碼以及編組16 的目的機場代碼,組成一條完整的訓練所需數據。
3 算法實現
3.1 基于Transformer模型的航路糾錯
Transformer 模型由編碼器和解碼器組成,整體結構如圖1 所示。輸入序列經編碼器被映射成相同長度高維向量,再由解碼器解碼生成輸出序列。其中,編碼器端的輸入為待糾錯文本,解碼器端的輸入需區分訓練階段與測試階段,訓練階段解碼器端輸入與待糾錯文本相對應的正確文本,測試階段則輸入解碼器前一時刻的輸出。解碼器輸出經過Linear 層和Softmax 層得到輸出詞概率,概率最大的詞確定為該時刻輸出,每一時刻輸出的詞拼接為最終輸出序列。

圖1 Transformer模型結構
因為模型不包含循環和卷積,為了利用序列的位置信息,在詞嵌入的基礎上加入位置向量(Positional Encoding),計算方法如式(1)~(2)所示:

其中,pos指該詞在序列中的位置,i指第i維,dmodel為模型隱層維度。
編碼器共N 層,每層包含兩個子層,分別為多頭注意力(Multi-Head Attention)層和全連接的前饋網絡(Feed Forward)層。每個子層后有一個殘差連接及歸一化結構,殘差連接避免梯度消失,歸一化。多頭注意力使用點積注意力,計算如式(3)~(5)所示。
其中,Q、K、V為三個向量矩陣,Q為查詢矩陣(query matrix),K為鍵矩陣(key matrix),V為值矩陣(value matrix);dk為隱層維度分別為對應的權重矩陣。Multi-Head 的注意力由多個head拼接而成,可以并行計算,提高模型訓練效率。前饋網絡層計算如式(6)所示,包含兩個線性變換和一個Re?LU 激活:

其中,W1、b1和W2、b2分別為兩次線性變換對應的權重和偏置。
解碼器也為N層,每層包含三個子層。第一個子層掩碼多頭注意力(Masked Multi-Head Attention)層,掩碼的作用是避免解碼器在訓練時讀到后續位置的信息,使預測只依賴當前時刻已知輸出。解碼器的多頭注意力層接受來自編碼器的Q、K和來自上一子層的V。
3.2 基于N-Gram的結果修正機制
與自然語言文本的流利性判斷相類似,僅從航路文本本身出發,一條航路的正確性判斷主要依據其中每個點與前后點的連續組合的可行性。根據航路文本特性,本文設計了一種基于N-Gram 思想的結果修正算法,以詞為最小單位,對航路進行大小為n的滑動窗口操作,獲得長度為n的共現詞信息。本文利用正確航路組成的語料庫,使n取2、3,建立二元和三元的共現詞表。如航路片段“TOL A470 DOTMI DCT”,進行n為2 的滑動窗口操作得到“TOL A470,A470 DOTMI,DOTMI DCT”,進行n為3 的滑動窗口操作得到“TOL A470 DOTMI,DOTMI DCT”。在航路糾錯中,只考慮多元詞的正確性,不考慮其出現的概率。針對待分析片段使用同樣大小的滑動窗口,將得到的所有二元詞和三元詞在共現詞表中進行查找,找到的記1 分,否則計0 分。所有共現詞的得分相加,用該片段總共現詞數進行歸一化,得到該片段的得分S,如式(7)所示:

其中CB、CT分別為子片段經滑動窗口獲得的二元詞、三元詞個數,Bi、Ti分別為相應二元詞、三元詞的查表后的得分。Bi,Ti∈{0,1};S∈[0,1]。當S=1 時,認為該片段是正確的。
每當Transformer 模型對輸入進行一處修改,都會得到一對輸入、輸出中對應的相異子片段。以原始輸入為基準,與Transformer 模型輸出進行比較,對于兩條航路中不一致的子片段分別進行打分,以決定修改的保留或還原。若片段得分相同,考慮到實際工作中會遇到新增但未被收錄的航路,則還原原始輸入的子片段;若Transformer 模型輸出航路子片段得分高于原始航路子片段,則進行片段替換,保留模型修改。修正后的航路即為最終輸出結果。
3.3 評估標準
本文使用查準率P、查全率R和F0.5值作為評價指標,定義如式(8)~(10)所示。查準率衡量模型對航路的修改是否正確,查全率衡量模型的修改是否有遺漏。使用F0.5作為評價指標與F0.1的區別在于將查準率的權重定為查全率的兩倍,其原因在于,對于糾錯模型,更看重模型編輯的準確性而非編輯的數量。
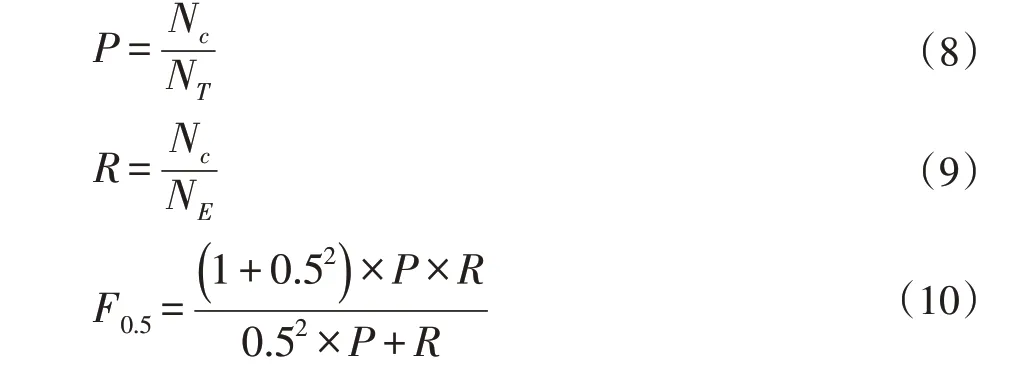
其中Nc指修改正確的錯誤樣本數,NT指發生修改的樣本數,NE指語料中含有的錯誤樣本數。
4 實驗
4.1 實驗數據
本文收集了2019 年8 月的全國FPL 報文數據453910 條,從中提取并整理得到正確且無重復的航路10348 條,以此建立訓練詞表并制作數據集,數據集統計如表1 所示,以訓練集中的正確樣本統計制作二元詞和三元詞的共現詞表作為修正算法依據。錯誤樣本為人工在正確樣本的基礎上進行多輪造錯得到,每條航路隨機添加1~3 處錯誤,錯誤類型包括多詞、少詞、錯詞,詞類型為詞表中出現過的任意已知詞和未登錄詞

表1 數據集統計
4.2 實驗結果與分析
本文設置Transformer 模型編碼器與解碼器層數為6,隱層維度為128,head 數為8;使用Adam 優化算法[19],learning_rate 設為0.0003;dropout 設為0.1。利用上述訓練集訓練Transformer 模型,并用測試集測試。同時,與基于LSTM 的Seq2Seq 模型、添加了Attention 機制的基于BiLSTM 的Seq2Seq 模型進行比較,并對結果使用基于N-Gram 的修正算法進行修正。最終實驗結果如表2 所示。

表2 航路糾錯實驗結果
實驗結果表明,深度學習模型可以有效糾正FPL報文航路中的錯誤,同時,經由N-Gram 修正算法修正后的結果在P值、R值、F0.5值三個指標中均有所提升。Transformer 與N-Gram 修正算法的組合在三個指標上取得最佳結果。
表3 中給出糾錯實例。該錯誤樣本共有2 處錯誤,用斜體加粗標示錯誤位置,“(…)”表示信息缺失。“IKATA A470”之間多了“LG Z17”,“A1 UBL W1”中“UBL”缺失。經過Transformer 模型糾錯,上述2 處錯誤已得到糾正,但出現了一處新錯誤,“W597 IKATA”之間多了“BINUS W597”。可以看出,Transformer 模型共對錯誤樣本做出了3 處修改,分別對輸入、輸出中這3 對不一致的子片段進行N-Gram 修正,最終保留了2處修改,還原1 處修改,得到最終糾錯結果。

表3 糾錯實例
5 結語
本文將基于深度學習的自然語言處理技術引入FPL 報文航路糾錯工作,實驗驗證了Transformer 模型能對航路中出現的多處錯誤進行有效修改。同時,本文基于N-Gram 思想并結合航路文本特征,提出了一種共現詞得分的結果修正算法,分段對Transformer 模型做出的修改進行取舍,提高了糾錯模型的正確率。本文的工作還有很大的提升空間,后續模型的優化、在更大數據集上的驗證以及針對實際應用場景中的改良都有待進一步研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
