基于知識蒸餾的分布式神經網絡設計
2021-07-09 17:19:34鄭宗新
現代計算機 2021年14期
關鍵詞:模型
鄭宗新
(重慶師范大學計算機與信息科學學院,重慶 401331)
0 引言
隨著深度學習的發展,深度學習在生活中的應用越來越廣泛。面對復雜的任務場景,深度學習的運算量也隨之增大。現有關于神經網絡的分布式研究多是關于訓練階段的,關于神經網絡推理階段的分布式研究較少。推理階段運算量較大的解決方法一方面是通過優化網絡結構[1-4],設計高效簡潔的模型來減少運算量;另一方面通過分布式架構使得多設備協同工作增加運算力。在推理階段的分布式研究主要是通過不同的設備間(邊緣節點和云服務器、邊緣節點和邊緣節點)的相互協助,加快邊緣節點推理速度。
基于動態卸載的分布式[5-7]網絡設計通過分析神經網絡的層的運算量,把神經網絡模型縱向劃分為兩部分,運算量較大的卷積層部分放在云服務器運算,利用云服務器計算速度快的特點,在云服務器計算后將計算數據發送到邊緣設備繼續另一部分運算量較小的計算,將計算延遲和通信延遲進行平衡,得到最優化的計算速度。另一種方法是通過將特征圖進行區域的劃分[8-9],將輸入數據橫向劃分為不同的區塊發送給不同的設備進行運算,最后一層時進行拼接。每個設備的運算量都較普通運算減少了,因此運算速度獲得提升。國內的相關的研究主要是通過動態卸載,將不同階段的運算放置于不同的設備,從而并行計算[10]。
以往的分布式推理研究主要在提升運行速度方面,容錯率較低,一旦通信中斷便無法完成推理。在無人機、自動駕駛等方面是無法接受的。對此本文提出一種基于知識蒸餾的神經網絡設計方法,與其余設備協同運算時具有較高的準確率,當通信不穩定時可離線運行,有著可以接受的準確率。
1 分布式神經網絡設計
1.1 知識蒸餾
知識蒸餾(Knowledge Distillation,KD)[11]是通過將訓練數據輸入一個訓練好的、高準確率的教師模型,得到教師模型的輸出結果,學生模型根據輸出結果進行學習。教師模型輸出為軟標簽(soft-target),其中包含了教師模型本身的信息,相比于訓練集原有的硬標簽(hard-target)信息量更大,因此訓練時效率更高。

表1 硬標簽和軟標簽
1.2 網絡剪枝與優化
網絡剪枝(Network Pruning)通過去除重要性較低的連接,降低神經網絡模型的運算量。網絡剪枝對于一個連接的重要程度的評價,一般是通過這個連接的參數絕對值的大小[12]、濾波器中位數[13]等信息來判斷。現有網絡剪枝方法多是依據參數自身信息進行判別[14],而忽略了其他信息。因此在裁剪較大的時候,準確率下降嚴重。如圖1 所示。

圖1 刪除不同比例的連接后的準確率
一個連接的參數絕對值越大,一般來說對準確率的影響就越大。若一個模型中參數值的分布較為均勻,每個連接都對準確率的影響差距不大,刪除小部分連接會導致準確率大幅下降。對于這個問題,本文提出一種促進參數中較大值的訓練算法(Promote Maxi?mum Weight SGD,PMW-SGD),通過在反向傳播時,根據參數的絕對值進行排序,根據相對大小來對應不同的學習率。公式如下:
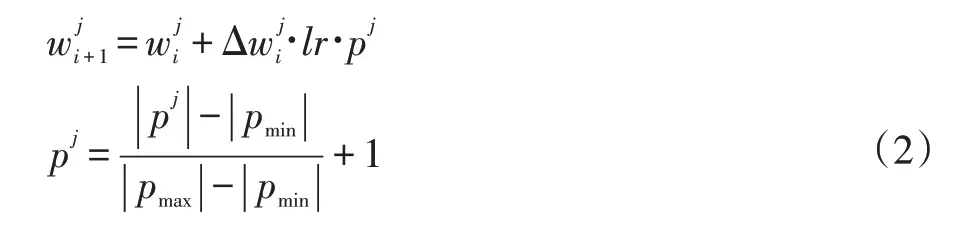
其中w為模型參數,Δw為更新的梯度,p為與參數絕對值大小相關的量。
通過將模型中參數值較大的一部分變得更大,使得這小部分連接對準確率的貢獻較大,在刪除大部分連接后模型仍然有較高的準確率。
1.3 模型分解
使用網絡剪枝刪除部分全連接層參數,通過刪除不同比例的參數從而得到不同的子模型;不同子模型參數數量不相同,一般參數越多的子模型準確率越高,如圖2 所示。在本文中,使用上一小節中經過PMWSGD 訓練后的模型,按照參數的權重絕對值進行排序,剪枝掉大部分權重絕對值較小的連接,根據剪枝的比例不同,得到不同準確率的子模型。

圖2 完整模型分解為三個子模型
2 實驗結果與分析
本文通過PyTorch 框架,在ResNet18 和LeNet 模型及CIFAR10 數據集上進行算法有效性驗證。
2.1 PMW-SDG算法
首先將訓練好的ResNet18 模型作為教師模型,LeNet 作為學生模型,進行知識蒸餾,先采用minibatch SGD 梯度下降算法訓練。在初步經過50 次迭代訓練后采用PMW-SGD 梯度下降算法對全連接層的參數進行知識蒸餾的訓練,參數分布如圖3 所示。
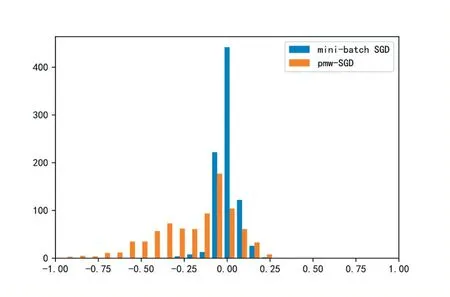
圖3 mini-batch SGD和PMW-SGD訓練算法訓練后的參數分布
在使用PMW-SGD 算法后全連接層中的參數絕對值較大的一部分變得更加大,對應節點的重要性變高,對于準確率的貢獻因此變大。在刪除部分全連接層的參數時,保留的節點主要為權重絕對值較大的,因此準確率較mini-batch SGD 算法高。如圖4 所示。

圖4 mini-batch SGD與PMW-SGD訓練后的模型刪除不同比例參數后的準確率
2.2 知識蒸餾
首先通過網絡剪枝將上小節中訓練好的ResNet18模型全連接層參數進行剪枝,按照參數權重的絕對值進行排序,從小到大將全連接層剪枝95%得到子模型A;剪枝85%得到子模型B。從而將ResNet18 分解為兩個子模型A 和B;其中A 模型中節點較少,因此準確率相對較低;B 模型節點較多,準確率較高。詳細信息如表2 所示。
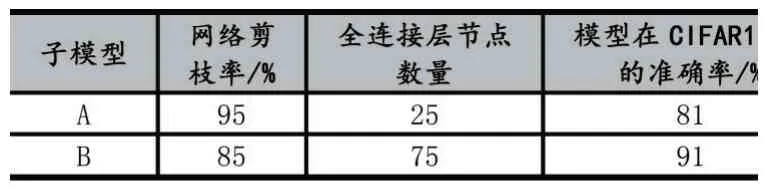
表2 兩個子模型的信息
基于LeNet 構造兩個模型,分別為LeNetA 和LeNetB;其全連接層節點數分別25 和50 個。使用知識蒸餾讓LeNetA 模型全連接層節點學習子模型A 中全連接層節點的輸出;LeNetB 模型全連接層節點學習子模型B 中去掉子模型A 中的25 個節點后的全連接層節點的輸出;最后將兩個模型作為一個整體進行微調訓練。
然后將上述方法中的LeNetB 模型換成更加復雜的EfficientNet 模型,在模型中添加節點總數為50 的全連接層。進行與上述相同的訓練過程。
普通數據集訓練LeNetA 模型、知識蒸餾訓練LeNetA 模型和本文方法訓練后結果如圖5。

圖5 不同訓練方法下的準確率變化
其中普通訓練和知識蒸餾訓練LeNetA 模型的準確率分別為:74.4%和74.3%。在本文訓練方法中第一階段訓練LeNetA 模型的準確率為69.3%,在第二階段LeNetB 模型加入訓練后準確率為77.8%;在最后一階段整體微調后,準確率達到78.1%。用EfficientNet 模型替換LeNetB 模型后準確率為83.4%,微調后準確率的84.9%。結果如表3 所示。
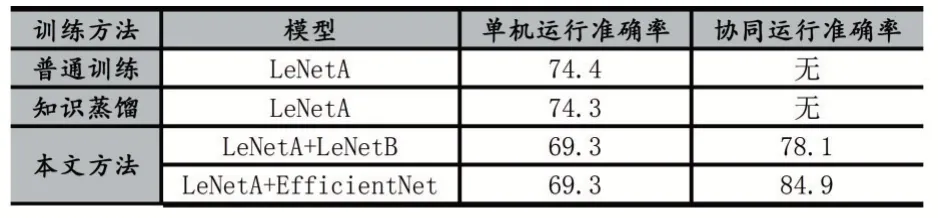
表3 不同訓練方法下的準確率
3 結語
可以看出,通過本文方法設計的分布式神經網絡與多個設備協同計算時,使用更加復雜的神經網絡模型進行協同運算時可達到的準確率較高,對此適用于通信條件良好時通過與云服務器協同運算達到較高的準確率;通信情況一般時通過與附近的邊緣設備協同運算,有良好的準確率。協同運算的準確率都比原始模型較高;在出現干擾等情況無法與其他設備協同計算時,單機運算的準確率較原始模型稍低,仍在可接受范圍內。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
