基于Transformer的機器閱讀理解對抗數(shù)據(jù)生成
2021-07-11 10:56:10范玚劉秉權
智能計算機與應用 2021年1期
范玚 劉秉權
摘?要:機器閱讀理解任務是衡量模型對于文本信息理解程度的一種重要方式,一直以來備受關注。近年來,很多學者在這一任務上提出了自己的模型,并取得了相當不錯的成績,其中一部分甚至已經(jīng)超越了人工回答的準確率。然而,這些模型是否真正地、深入地理解了文本語義,還是僅依靠淺層的詞語相似度和答案類型來進行簡單的搜索?為了進一步評價閱讀理解模型對于文章語義的理解程度,本文提出了一種基于Transformer結構的對抗數(shù)據(jù)生成方法,并對主流閱讀理解模型進行了檢測。
關鍵詞: 機器閱讀理解;文本生成;Transformer結構;深度學習
文章編號: 2095-2163(2021)01-0001-07?中圖分類號:TP183?文獻標志碼:A
【Abstract】Machine reading comprehension is an important way to measure the model's understanding of nature language. In recent years, many researchers have proposed their own models in this task, and achieved quite good results, some of which have even exceeded the human performance. However, do these models really and deeply understand human language, or simply rely on shallow word similarity and answer type to search for true answers? In order to evaluate systems' real language understanding abilities, the paper proposes a new method of to generate adversarial data based on Transformer structure, and test the mainstream reading comprehension models on the dataset in the paper.
【Key words】machine reading comprehension; text generation; Transformer architecture; deep learning
0?引?言
近年來,隨著深度學習、預訓練語言模型[1-5]等先進技術的相繼問世,計算機理解人類語言的能力獲得了長足的進步,許多自然語言處理領域的任務都有了新的突破,機器閱讀理解任務也重新受到了人們的關注。
許多學者提出了不同的機器閱讀理解數(shù)據(jù)集,其中較為出名的,有斯坦福研究者提出的Stanford Question Answering Dataset(SQuAD)數(shù)據(jù)集[6]。這是一個片段抽取型的閱讀理解數(shù)據(jù)集,其中共包含了536篇文章和107785個文章-問題對。許多研究者針對這一任務提出了自己的方法,其中一些優(yōu)秀的模型得到的性能甚至已經(jīng)超過了人工的準確度。
然而,這樣的片段抽取式閱讀理解任務,由于答案原文可以直接在文章中找到,并且答案所在原文中的位置附近的詞匯和問句中的詞匯往往具有很大的相似度[7-8]。所以,僅通過簡單的詞語相似度的匹配,和對答案詞性的預測,就可以很大程度上尋找到正確答案,進而解決這一問題。這就使得人們不由得產(chǎn)生了一個疑問,機器是否真正地、深入地理解了文章的意思?為了解決這一問題,本文通過對SQuAD數(shù)據(jù)集進行一定限度的改進,即在文章中增加一些可能對模型選擇答案產(chǎn)生誤導的句子,來進一步檢測模型對于文章理解的程度。
本文的主要內容安排如下:第1節(jié)主要介紹本實驗用的數(shù)據(jù)集;第2節(jié)簡要闡述了現(xiàn)有的2種機器閱讀理解對抗數(shù)據(jù)集,及其生成的方法;第3節(jié)主要提出了本文中生成對抗閱讀理解數(shù)據(jù)的方法,及其中涉及的相關數(shù)據(jù)和工具;第4節(jié)給出了主流機器閱讀理解模型在新生成的對抗數(shù)據(jù)集上的性能表現(xiàn)及結果分析,第5節(jié)是本次研究的工作總結。
1?實驗數(shù)據(jù)集
本文所主要使用的數(shù)據(jù)集為斯坦福學者Rajpurkar等人提出的Stanford Question Answering Dataset(SQuAD)數(shù)據(jù)集。SQuAD數(shù)據(jù)集共有2個版本,第二個版本[9]在前者的基礎上新增了一個無答案檢測,即其中的某些文章-問題對中,該問題對應的答案在相應的文章中無法獲得,此時模型應返回一個No Answer。該設計對本實驗沒有作用,因此為了簡化實驗、突出重點,本文選擇更早的SQuAD1.1版本作為本實驗采用的主要數(shù)據(jù)集。
SQuAD1.1數(shù)據(jù)集中,所有問題的標準答案都是原文中存在的短語,大概可分為時間、除時間外其余數(shù)字、人物、地點、常用名詞短語、形容詞短語、動詞短語等共10個類別,每個類別在整體數(shù)據(jù)中所占比重見表1。
2?現(xiàn)有的對抗性閱讀理解數(shù)據(jù)集介紹
在SQuAD1.1數(shù)據(jù)集發(fā)布以后,大量的學者提出了自己的解決方案,使得這一數(shù)據(jù)集的state-of-the-art成績被不斷提高,其中最優(yōu)秀的一些模型甚至已經(jīng)超越了人工準確率。因此,有學者對此數(shù)據(jù)集進行了改進,來增加其難度,并更加全面地驗證閱讀理解模型的魯棒性和其對于自然語言的真實理解程度。
主要的改進思路有2種.第一種是對文章進行改進,在不擾亂文章語義結構的前提下,通過在文章中加入一些帶有迷惑性的句子,來干擾模型提取答案;第二種是對問題進行改進,在不改變問題語義的前提下,仿寫出多個問句,來測試模型對于不同表述的問句,是否能夠一致地找到正確答案。對此擬展開研究分述如下。
2.1?基于文章擴充的方法簡要介紹
在SQuAD數(shù)據(jù)集的基礎上,同樣是來自斯坦福的研究者Jia等人[10]提出了通過向文章中填充一些具有迷惑性的句子,來干擾閱讀理解模型對于答案的選擇。
該文作者首先討論了用于擴充文章的句子應放在文章的什么位置比較合適,此后得出結論,新增句子放在文章中間最容易打亂文章的語義結構,破壞文章上下文的連貫性;而放在文章開頭則會使得文章第一句不是中心句,可能會影響模型對文章的理解。綜上所述,在本方法中,新增的句子將被統(tǒng)一放置在文章的末尾。
此方法通過改造問句和標準答案來生成被填充的語句。主要步驟可以分為以下4步:
首先,對問句進行改動。將問句中的形容詞替換為WordNet[11]中的反義詞;再對問題中的命名實體和數(shù)字,在GloVe[12]詞向量空間中選擇最相近詞匯來進行替換。在本步驟中,如果問句沒有產(chǎn)生變化,則返回原樣例。
其次,制造了一個和原始答案相同類型的假答案。通過Stanford CoreNLP工具命名實體識別和詞性標注的結果,該文作者構建了26種答案類別,并為每一種類別手工設計了一些假答案。當獲得真答案和問題時,通過模型計算出真答案的類別,并從該類別中選出相應的假答案。
然后,將改動過后的問句和新生成的假答案轉變?yōu)殛愂鼍洹榱藢崿F(xiàn)這一目標,論文通過CoreNLP工具來對問句進行成分分析,并人工設計了超過50條規(guī)則,這就可以將問句和答案轉化成陳述句。
最后,考慮基于規(guī)則的方法生成的陳述句很可能出現(xiàn)語法的錯誤,論文對于每個生成的陳述句,讓5個工作人員來進行人工檢測,當有超過3名工作人員認為這一句有語法錯誤時,將取消這一樣例,對原文章不做修改。
該文作者使用Match-LSTM[13]和BiDAF[14]兩種方法在新生成的數(shù)據(jù)集和原始的SQuAD1.1數(shù)據(jù)集上分別進行了測試。發(fā)現(xiàn)對比在SQuAD數(shù)據(jù)集上的結果,在新生成數(shù)據(jù)集上的結果均下降了超過一半。
2.2?基于問句仿寫的方法改進介紹
和上一小節(jié)不同的是,Gan等人[15]提出了通過對問句進行仿寫,來檢驗閱讀理解系統(tǒng)穩(wěn)定性的方法。
該文提出了2種仿寫問句的方法,并分別構建了各自的數(shù)據(jù)集,來檢測閱讀理解系統(tǒng)的過敏感性和過穩(wěn)定性。其中,過敏感性使用了僅做微小變更的相同語義的問句,來對系統(tǒng)進行檢測,判斷閱讀理解模型是否對于問句的微小變動過于敏感;過穩(wěn)定性則在文章中找一個正確答案詞性相同的短語,繼而用該短語附近的詞匯來改寫問句,并保持問句語義不變,以此來判斷閱讀理解模型是否過于依賴詞匯表面意思的匹配。為此可做剖析概述如下。
2.2.1?針對過敏感性的方法
該方法主要采用了基于Transformer[16]的編碼-解碼結構,并對其中的解碼器進行了修改,加入了復制機制,即考慮了從原問句中選擇詞匯的概率分布,使得在生成仿寫的問句的時候,可以考慮加入原句中現(xiàn)有的詞語。
此方法將仿寫建議和原問句首尾相接在一起作為模型的輸入。其中,仿寫建議是可用來替換原問句中部分詞匯的單詞或詞組。
該模型的訓練數(shù)據(jù)來源有2個,分別為WikiAnswers dataset和Quora dataset這兩個仿寫數(shù)據(jù)集。在WikiAnswers dataset數(shù)據(jù)集中,原句和仿寫句中的詞組存在一一對應關系,故而,此方法只需從仿寫句隨機選擇一個對應好的詞組,即可獲得仿寫建議;對于Quora dataset數(shù)據(jù)集中的數(shù)據(jù),研究中使用了TextRank方法來分別從原句和仿寫句中獲得關鍵詞,并將仿寫句中排名最高且未在原句中出現(xiàn)過的關鍵詞作為仿寫建議。
在預測過程中,作者使用paraphrase database(PPDB)[17]仿寫數(shù)據(jù)庫來根據(jù)問句生成仿寫建議。PPDB中包含了數(shù)以百萬記的仿寫詞組對。作者首先從原問句中提取出所有的1~6-grams詞組,并去除掉其中unigram詞語中的停止詞;然后在PPDB中為剩下的詞組尋找相似度大于0.25的仿寫詞組;再將這些仿寫詞組分別作為仿寫建議,和原句一起傳入模型,獲得多個仿寫問句;最后,將獲得的多個仿寫問句和原問句進行相似度計算,在此基礎上就可去除相似度小于0.95的仿寫問句。
2.2.2?針對過穩(wěn)定性的方法
為了檢測模型的過穩(wěn)定性,該研究從SQuAD1.1驗證集中人工選擇了一些樣例,并從這些樣例文章中分別選擇了一個與原答案類型相一致的短語,接下來則用這個短語附近的詞組對問句進行改寫,保持問句語義不變。
這一過程均為人工完成,過程結束后總共編寫了56個新的問句。
至此,研究又采用了BERT、DrQA、BiDAF三種模型對SQuAD數(shù)據(jù)集和2種仿寫問句的數(shù)據(jù)集進行性能測試。測試結果發(fā)現(xiàn)相比于標準的SQuAD數(shù)據(jù)集,這三種方法在第一種針對過敏感性的測試集上的性能都略微下降了2~3個百分點,而在第二種針對過穩(wěn)定性的測試機上的性能則下降了大約一半。
3?基于Transformer結構的對抗閱讀理解數(shù)據(jù)生成方法
綜上小節(jié)所述,現(xiàn)存的強調對抗性的閱讀理解數(shù)據(jù)集大多都是依賴人工方法生成,這使得基于人工編寫規(guī)則的生成結果容易出現(xiàn)錯誤,而純手工編寫的數(shù)據(jù)集過于耗時耗力,往往規(guī)模很小。本小節(jié)將介紹一種基于端到端模型的對抗閱讀理解數(shù)據(jù)生成方法,使得這一過程可以擺脫人力的限制。
3.1?相關技術介紹
3.1.1?命名實體識別相關技術介紹
命名實體識別的主要任務是識別出文本中的人名、地名等專有名詞,以及時間、日期、百分比等有意義的數(shù)據(jù)短語,并對其加以分類。
早期的命名實體識別大多采用的是基于啟發(fā)式算法和手工編寫規(guī)則的方法[18],由于這一任務本身是一個標注任務,很多專有名詞或數(shù)據(jù)都較容易識別,并且原先的數(shù)據(jù)集對于實體劃分的種類較少,使得這些比較樸素的方法也表現(xiàn)出較好的性能。隨著機器學習技術的興起,有學者相繼提出了基于隱含馬爾可夫模型的方法[19]、基于條件隨機場的方法[20]等一系列基于學習的方法,進一步提高了命名實體任務的準確率。
本文中所使用的是斯坦福大學提供的Stanza工具[21]。這是基于深度學習的方法。該方法先是通過字符級的長短時記憶網(wǎng)絡來學習每個單詞的向量表示,并將其和對應單詞的詞嵌入相連接,再傳入一層雙向長短時網(wǎng)絡標注器,最終使用條件隨機場方法來對標注結果進行解碼。
本文采用的命名實體分類標準采用的是OntoNotes5.0數(shù)據(jù)集中規(guī)定的標準,共包含11類名稱和7類數(shù)據(jù),所有18種分類見表2。
3.1.2?Transformer結構簡介
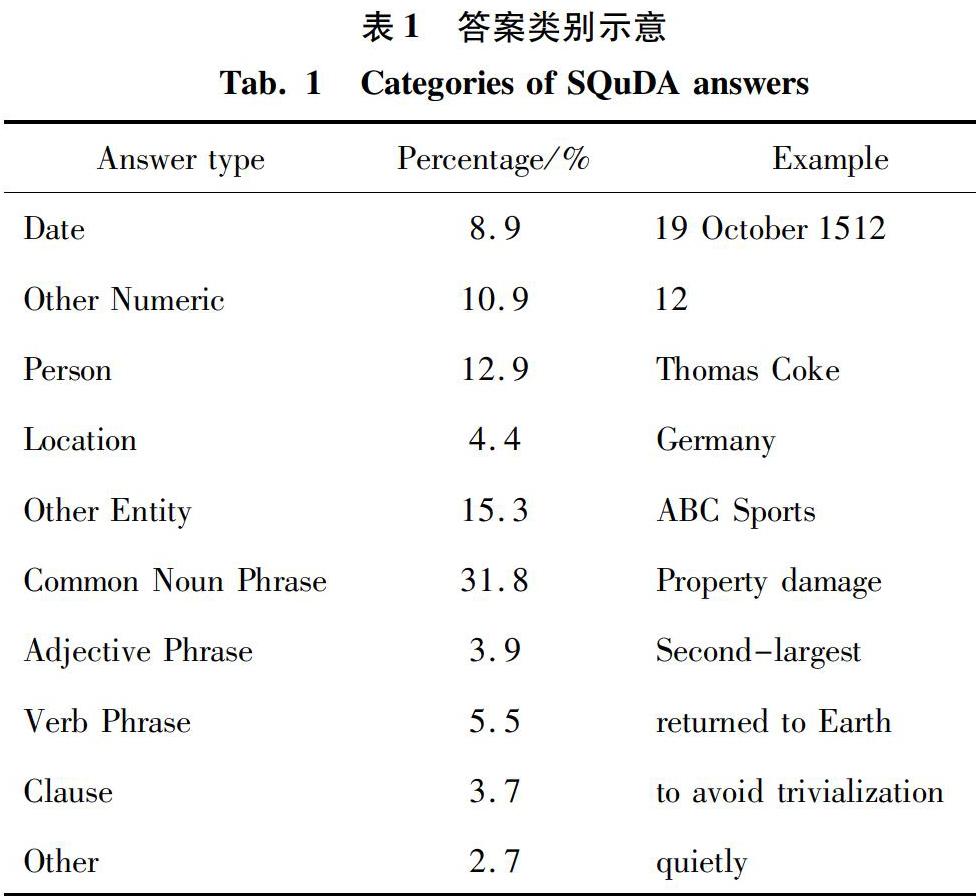
Transformer是由Ashish Vaswani等人提出的Seq2Seq模型。與之前的模型不同,Transformer完全依賴于注意力機制來挖掘文本中的上下文聯(lián)系,而沒有采用循環(huán)神經(jīng)網(wǎng)絡結構及其變體。Transformer模型的結構如圖1所示。
Transformer的編碼器由2個子層組成。其中,一個子層是多頭注意力機制層。和普通的注意力機制相比,多頭注意力機制將
Transformer的解碼器和編碼器結構相似,最大的區(qū)別在于解碼器多了一個子層。該子層的作用是對編碼器的輸出使用多頭注意力機制進行處理。
值得一提的是,由于沒有采用類似于循環(huán)神經(jīng)網(wǎng)絡的時序模型,為了保存文本中的上下文順序關系,Transformer采用了位置嵌入。
本文將使用Transformer作為生成對抗數(shù)據(jù)的基本結構。另外,由于本任務的目的只是將疑問句轉換為陳述句序,為了讓模型在生成語句的同時會考慮輸入中原有的詞匯,本文在Transformer解碼器中引入了復制機制。模型具體結構將在下文中予以詳細解釋。
3.2?模型整體結構
和大量現(xiàn)有的工作不同,本實驗將采用一種不需要人工介入的生成干擾句的方法,此方法主要分為2個模塊,即:問句改寫和虛假答案生成模塊、基于端到端結構的干擾句生成模塊。相關的研究論述詳見如下。
3.2.1?問句改寫和虛假答案生成模塊
本模塊的目的,是使用原始數(shù)據(jù)中的問題和標準答案,生成一個與原意不同但形式類似的問句,以及一個和標準答案類型相同的虛假答案。
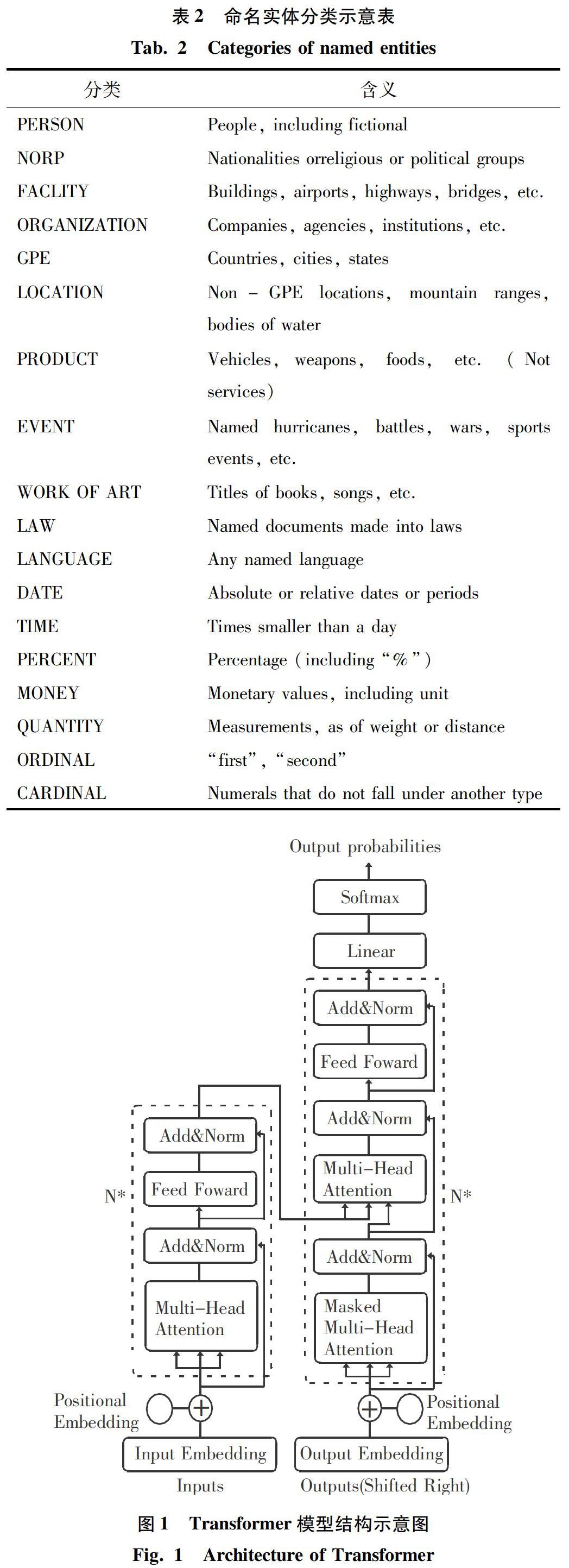
首先,本文使用上文提到的Stanza工具對SQuAD開發(fā)集中的所有段落進行命名實體識別,并將獲得的所有不重復的實體按照其本身的類別分別存儲,以此來構建備用的分類實體庫。
然后,同樣對原問句進行命名實體識別,對于其中識別出來的實體,隨機地從此前獲得的分類實體庫中按照類別選擇實體來進行替換。如果最終問句沒有變動,則不對這一樣例進行處理,返回原樣例。
最后,對于原答案進行分類,判定其所屬的實體類別,并從分類實體庫中選擇相同類別的實體作為虛假答案。如果原答案分類不成功,則不對該樣例進行處理,返回原樣例。
問句改寫和虛假答案生成模塊的結構如圖2所示。
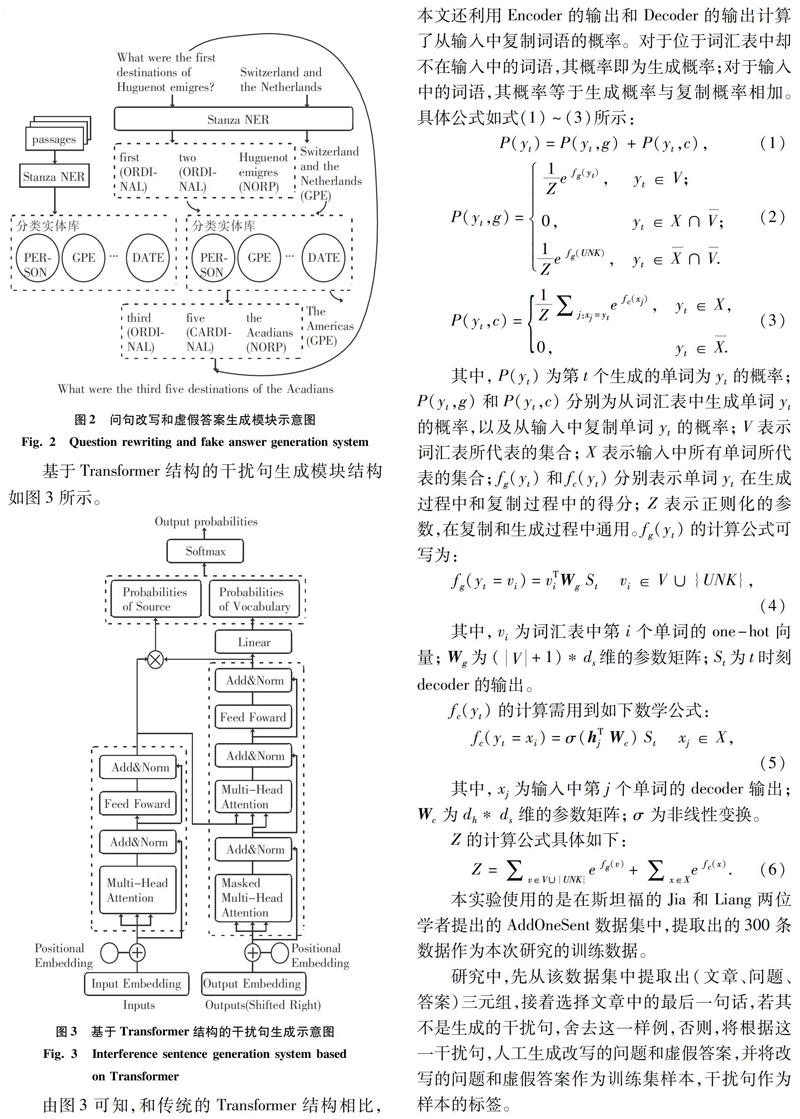
3.2.2?基于Transformer結構的干擾句生成模塊
本模塊使用基于Transformer框架的端到端結構來進行干擾句生成。模塊的輸入是3.2.1節(jié)中生成的改寫后的問句和虛假答案,首尾相接并用[Sep]標志隔開,模塊的輸出是陳述句形式的干擾句。由于新生成的干擾句中必然包含輸入中的很多詞語,因此本文改寫了Transformer框架的解碼器結構,在其中加入了復制機制,即在生成每一個詞語時,會考慮從輸入中選擇一個詞語的可能性。
基于Transformer結構的干擾句生成模塊結構如圖3所示。
由圖3可知,和傳統(tǒng)的Transformer結構相比,本文還利用Encoder的輸出和Decoder的輸出計算了從輸入中復制詞語的概率。對于位于詞匯表中卻不在輸入中的詞語,其概率即為生成概率;對于輸入中的詞語,其概率等于生成概率與復制概率相加。具體公式如式(1)~(3)所示:
本實驗使用的是在斯坦福的Jia和Liang兩位學者提出的AddOneSent數(shù)據(jù)集中,提取出的300條數(shù)據(jù)作為本次研究的訓練數(shù)據(jù)。
研究中,先從該數(shù)據(jù)集中提取出(文章、問題、答案)三元組,接著選擇文章中的最后一句話,若其不是生成的干擾句,舍去這一樣例,否則,將根據(jù)這一干擾句,人工生成改寫的問題和虛假答案,并將改寫的問題和虛假答案作為訓練集樣本,干擾句作為樣本的標簽。
4?實驗結果與分析
4.1?問句改寫和虛假答案生成的實驗結果
在此模塊中,本文先是利用SQuAD開發(fā)集中的全部文檔和命名實體識別方法提取出了不同類別的命名實體,以此構建了分類實體庫,用來進行后續(xù)的替換操作。由于WORK OF ART和LAW兩個種類中的實體較少,所以在構建分類實體庫時,本文將這兩類刪去。該分類實體庫的構建結果見表3。
然后,本文利用分類實體庫,對問句進行了改寫。
最后,根據(jù)真實答案的類別,本文將從分類實體庫中選擇相應的實體進行替換,進而生成虛假答案。問句改寫和虛假答案生成的樣例見表4。
4.2?基于Transformer結構的干擾句生成實驗結果
在此模塊中,本文采用了Transformer結構,并引入了復制機制,實現(xiàn)了由改寫問句和虛假答案生成干擾句的功能。本實驗中生成的部分樣例與現(xiàn)有人工方法生成的干擾句樣例比較見表5。
由表5中可以看出,本文中的結構所生成的大部分干擾句都能保證語義正確、成分完整,整體性能較好。對于一小部分語句可能出現(xiàn)少量的語義錯誤和前后不連貫的問題,但這并不會影響到測試模型抗干擾能力的功能。
最后,本文采用較為主流的3種機器閱讀理解模型,在本文中生成的對抗性閱讀理解數(shù)據(jù)集(ADV)進行實驗,試驗結果見表6。
由表6的結果中可以看出,這三種主流機器閱讀理解模型在生成的對抗數(shù)據(jù)集上的結果都出現(xiàn)了較大程度下降,并和現(xiàn)有的人工生成的AddOneSent數(shù)據(jù)集上的表現(xiàn)相近。這說明在測試機器閱讀理解模型抗干擾能力上,本文使用機器自動生成的數(shù)據(jù)集和現(xiàn)有的人工生成的數(shù)據(jù)集有相似的表現(xiàn)。
5?結束語
傳統(tǒng)的機器閱讀理解數(shù)據(jù)集難度較低,涉及的很多問題僅通過答案的類型和詞匯相似度的計算就可以得到正確答案,因此這樣的數(shù)據(jù)集無法真正、全面、深入地評價一個機器閱讀理解模型對于文章的理解程度。
近年來,多位學者陸續(xù)提出了不同的方法,來對傳統(tǒng)閱讀理解數(shù)據(jù)集進行改進,以增加其難度和對抗性,從而更好地評價機器閱讀理解模型對于文章的理解程度。然而,由于對抗數(shù)據(jù)生成的難度較大,現(xiàn)有的方法往往都大量地借助了人工編寫的方法。只是這些方法耗時耗力,極大地限制了對抗數(shù)據(jù)集的規(guī)模。針對這一狀況,另有學者則提出了人工編寫規(guī)則來生成數(shù)據(jù)的方法,但是大量的編寫規(guī)則不僅繁瑣,而且也不能保證性能,生成的結果仍然需要依靠人工來進行篩選。
基于此,本文提出了一種基于Transformer結構的對抗數(shù)據(jù)生成方法。將生成對抗數(shù)據(jù)的過程分為了問句改寫及虛假答案生成和干擾句生成兩個模塊。
首先,為了更加方便地進行問句改寫和虛假答案生成,本文利用命名實體識別技術從SQuAD開發(fā)集的全部文章中抽取出了分類實體庫,并以此對問句中的實體根據(jù)類別進行隨機替換。同樣地,也對真實答案根據(jù)其類別標簽從分類實體庫中選擇相應的實體進行了替換。
然后,本實驗利用現(xiàn)有的對抗數(shù)據(jù)集AddOneSent中的數(shù)據(jù),人工生成了訓練數(shù)據(jù),這也是本實驗中僅有的一個利用人工完成的部分。這一模塊中,本文在Transformer結構的基礎上,在其解碼器上拓展了復制機制,使其在生成干擾句的同時可以從改寫過后的問句和虛假答案中選擇詞匯。
最后,本文使用現(xiàn)有的3種主流機器閱讀理解模型對生成的對抗數(shù)據(jù)集進行測試。通過測試結果看出,本實驗中機器自動生成的數(shù)據(jù)集可以和人工手寫的數(shù)據(jù)集相似地檢測機器閱讀理解模型的魯棒性,并能以此來評價其對于文章真正的理解程度。
參考文獻
[1]DEVLIN J, CHANG Mingwei, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805,2018.
[2]PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations[C]//North American Chapter of the Association for Computational Linguistics. Louisiana, USA:NAACL, 2018: 2227-2237.
[3]RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[EB/OL].[2018].https://s3-us-west-2. amazonaws. com/openai-assets/researchcovers/languageunsupervised/language understanding paper. pdf.
[4]YANG Z L, DAI Z, YANG Y M, et al. XLNet: Generalized autoregressive pretraining for language understanding[C]//Advances in Neural Information Processing Systems. Vancouver:NIPS foundation,2019: 5753-5763.
[5]LAN Z, CHEN M, GOODMAN S, et al. Albert: A lite bert for self-supervised learning of language representations[J]. arXiv preprint arXiv:1909.11942, 2019.
[6]RAJPURKAR P, ZHANG J, LOPYREV K, et al. Squad: 100,000+ questions for machine comprehension of text[J]. arXiv preprint arXiv:1606.05250, 2016.
[7]SEN P, SAFFARI A. What do models learn from question answering datasets?[J]. arXiv preprint arXiv:2004.03490, 2020.
[8]WEISSENBORN D, WIESE G, SEIFFE L. Making neural qa as simple as possible but not simpler[J]. arXiv preprint arXiv:1703.04816, 2017.
[9]RAJPURKAR P, JIA R, LIANG P, et al. Know what you don't know: Unanswerable questions for SQuAD[C]//Meeting of the Association for Computational Linguistics. Melbourne, Australia:ACL, 2018: 784-789.
[10]JIA R, LIANG P. Adversarial examples for evaluating reading comprehension systems[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen, Denmark:ACL, 2017: 2021–2031.
[11]MILLER G A. WordNet: A lexical database for English[J]. Communications of the ACM,1995,38(11): 39-41.
[12]PENNINGTON J, SOCHER R, MANNING C D. Glove: Global vectors for word representation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar:dblp,2014:1532-1543.
[13]WANG S, JIANG J. Machine comprehension using match-lstm and answer pointer[J]. arXiv preprint arXiv:1608.07905, 2016.
[14]SEO M, KEMBHAVI A, FARHADI A, et al. Bidirectional attention flow for machine comprehension[J]. arXiv preprint arXiv:1611.01603, 2016.
[15]GAN W C, NG H T. Improving the robustness of question answering systems to question paraphrasing[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy:ACL,2019:6065-6075.
[16]VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Advances in Neural Information Processing Systems. Long Beach:NIPS, 2017:5998-6008.
[17]GANITKEVITCH J, VAN DURME B, CALLISON-BURCH C. PPDB: The paraphrase database[C]//Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Atlanta:IEEE ,2013: 758-764.
[18]RAU L F. Extracting company names from text[C]//Proceedings of the 7th IEEE Conference on Artificial Intelligence Applications. Los Alamitos:IEEE,1991: 29-32.
[19]BIKEL D M, SCHWARTZ R, WEISCHEDEL R M. An algorithm that learns what's in a name[J]. Machine Learning, 1999, 34(1-3): 211-231.
[20]LIAO Wenhui, VEERAMACHANENI S. A simple semi-supervised algorithm for Named Entity Recognition[C]//Proceedings of the NAACL HLT 2009 Workshop on Semi-supervised Learning for Natural Language Processing. Boulder,Colorado:ACL,2009: 58-65.
[21]PENG Qi, ZHANG Yuhao, ZHANG Yuhui, et al. Stanza: A Python natural language processing toolkit for many human languages[J]. arXiv preprint arXiv:2003.07082,2020.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
意林原創(chuàng)版(2016年10期)2016-11-25 10:28:30
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
