一種基于空間文本信息流的分布式的發布訂閱算法
2021-07-11 18:43:52周澤寧
智能計算機與應用 2021年1期
周澤寧
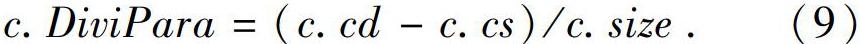
摘?要:發布訂閱系統是進行發布的事件和訂閱消息之間的匹配系統。首先需要對訂閱消息進行聚類操作,按照聚類結果,找到事件所屬類別,隨后在類別中,找尋和事件匹配的訂閱。本文提出了一個即時的發布訂閱的算法,統籌空間信息和事件屬性信息,不僅可以即時地處理事件和訂閱的匹配操作,也可以在分布式環境上即時地進行訂閱的更新和類別的更新。并且可以在沒有先驗知識的情況下即時地進行聚類操作和匹配操作。設計一個分布式的系統,將發布訂閱算法部署其上,并且提出了在分布式系統上該算法的負載均衡策略。隨后通過自建集群,使用真實的數據,實驗驗證本文提出的發布訂閱算法。
關鍵詞: 發布訂閱系統;分布式系統;聚類算法
文章編號: 2095-2163(2021)01-0046-06 中圖分類號:TP391.1 文獻標志碼:A
【Abstract】The publish and subscribe system is a matching system between published events and subscribed messages. First, it is necessary to perform a clustering operation on the subscription messages, find the category to which the event belongs according to the clustering result, and then find the subscription that matches the event in the category. This paper proposes an instant publish and subscribe algorithm, which coordinates the spatial information and event attribute information. It can not only handle the matching operation of events and subscriptions in real time, but also update subscriptions and categories in a distributed environment. In addition, clustering and matching operations can be performed immediately without prior knowledge. A distributed system is designed, the publish-subscribe algorithm is deployed on it, and the load balancing strategy of the algorithm is put forward on the distributed system. Therefore through the self-built cluster, using real data, the publish and subscribe algorithm proposed in this article is verified in the experiments.
【Key words】publish and subscribe system; distributed system; clustering algorithm
0 引?言
發布訂閱系統主要目的是方便事件發布者和事件訂閱者在網上進行信息交換這一過程,事件的訂閱者持續關注某一特定區域內的特定事件,事件的發布者將事件發生的空間位置和事件發布到網上,隨后這些事件和事件訂閱者的訂閱信息進行匹配并將符合要求的事件推送給訂閱者。
中央服務器上基于空間屬性信息的發布訂閱算法[1-8],使用樹狀結構按照空間索引訂閱數據,以加速空間屬性事件和空間屬性訂閱的比較。許多分布式系統[9-12]使用現有的空間索引將數據劃分到不同的服務器,這些系統是基于靜態數據的一次性查詢。
本文提出了一個沒有先驗知識、可以即時處理數據流、統籌事件信息和空間信息的發布訂閱系統,滿足了對于靈敏度的要求,并且提出了一個分布式的系統,將基礎的發布訂閱系統部署其上,滿足了大規模的數據量的要求。
1 基礎發布訂閱系統
發布訂閱系統包含發布的事件和訂閱這兩種數據流。在研究中,t表示一個發布的事件,包含至少2個信息:空間位置和屬性文本,可用二元組來表示:(t.s,t.k)。其中,t.s表示該事件發生的空間位置,空間位置采用經緯度的表達方式,表示空間中的一個點。t.k表示該事件的一系列屬性。同樣,q表示一個訂閱消息,用二元組來表示:(q.s,q.k)。其中,q.s表示該訂閱發布者關注的空間范圍,該數據使用的是此次訂閱關注范圍的最小鄰接矩形。q.k表示訂閱者持續關注的屬性信息,該信息是事件匹配時的屬性要求。
發布訂閱系統所關注的是事件和訂閱的匹配過程。如果滿足t.s在q.s的范圍中,即事件的發生位置在訂閱的要求的空間范圍之內,并且q.kt.k,也就是事件的屬性包含了訂閱要求的事件屬性,則認定事件t滿足該訂閱q的要求,就可將事件t分配給該查詢q。
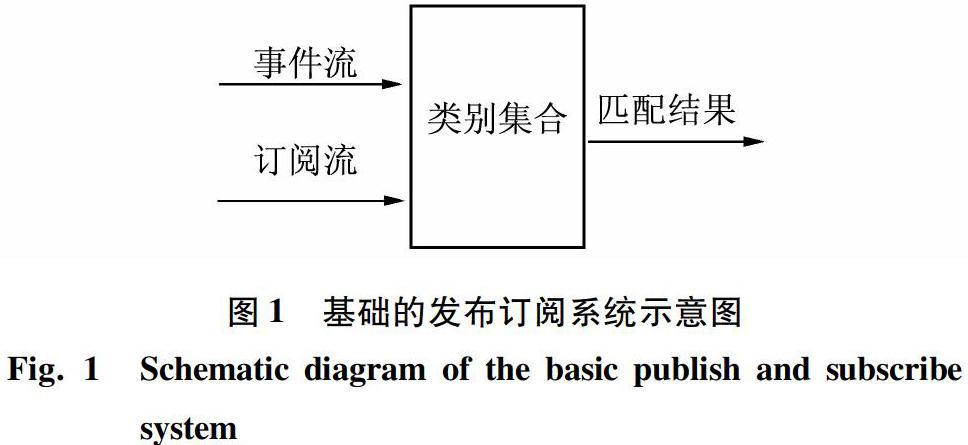
為了節省大量不必要的匹配操作,本文先是將訂閱進行聚類操作,將其按照空間信息和事件屬性通過聚類操作獲得眾多類別ci(i=1,2,3…),對到來的事件,將其分配到訂閱類別,再在匹配成功的類別中對訂閱和事件進行匹配操作,具體如圖1所示。
事件流進入類別集合后,首先找到相匹配的類別,再和類別中的訂閱一一匹配,找到相匹配的訂閱輸出。訂閱流進入類別集合后,如果進行訂閱的增加操作,就通過聚類算法更新類別集合;如果是訂閱的刪除操作,就找到該訂閱所屬類別,進行刪除操作。類別的集合最初為空,隨著訂閱的到來,逐漸通過聚類算法形成類別。
2 發布訂閱系統的聚類算法
對于發布訂閱系統,至關重要的就是訂閱的聚類算法,因其直接決定聚類結果的優劣,并最終影響整個算法的反應速度。本文提出一個沒有訓練集(在進行訂閱和事件的匹配過程中,同時進行訓練)、即時的聚類算法Rt-Cluter (RealTime-Cluter),可以對接受到的事件和訂閱進行即時的處理。通過對比實驗顯示了本算法的有效性。
訂閱和事件包含2種數據,分別是:空間信息和屬性信息。本文采取一個融合2種策略的混合策略。面對空間信息,文中采取網格的結構來存儲空間數據。面對事件的屬性信息,文中采取倒排索引的結構。其存儲形式如圖2所示。
Rt-Cluter算法使用相似性和相關性作為判斷標準。其中,相似性主要解決聚類操作中,對訂閱的聚類判斷問題。當一個新的需要添加的訂閱q到來時,需要按照空間信息和事件的屬性信息對其進行聚類操作,將其分配給最相似的一個類別c。本文將會分別計算屬性相似性和空間相似性,并對這2個相似性采用加權和的方式進行融合。屬性相似性KeySim的計算公式如下:
其中,key表示屬性,key.Pro表示屬性key在類別c的屬性集合c.k中所占的比例,即類別c中屬性key的頻數和類別c中所有屬性的頻數之比。
相應地,空間相似性SpatialSim的計算需要用到如下公式:
其中,ex表示如果類別c添加訂閱q,c.s需要擴展的大小,c.s表示類別c在添加訂閱q之前的最小鄰接矩形的面積大小。
綜上可得,進行相似性的比較時,總體相似性Sim的計算,要同時考慮空間和屬性的相似性,其數學公式可寫為:
其中,α表示權值(0≤α≤1),可以根據對屬性或者空間的重視程度進行調整。
對于等待被分配的訂閱,將其分配給相似值最大的類別。但是如果最大的相似度仍然足夠小(小于一個閾值),本文則為其創造一個新類別,并將該新類別分配到與其最為相似的類別所在的工作節點中,如此一來就保證了最相似的類別將處在同一個工作節點中,在后續數據傳輸上節省了資源。
在聚類算法中,除了新類別的創建,還需要進行類別融合,使用閾值CMaxNumTh來表示所能擁有的最大類別數量,一旦類別數量超過該值,就要進行類別融合操作。本文使用相關性來做類別融合研究。總體而言,如果2個訂閱q0和q1被同一個發布的事件t所匹配并且匹配成功,那么就認為這2個訂閱具有一點相關性,即:Correlation(q0,q1) = 1。需要進行類別融合操作時,將相關性最大的2個類別進行融合。
3 分布式系統設計與部署
網絡中數據量不斷擴大,單處理器無法滿足現實要求,本文提出了一個分布式系統來承載發布訂閱算法,將分布式系統下的發布訂閱算法命名為DRt-Cluster(Distributed-Realtime-Cluster)。其邏輯結構如圖3所示。
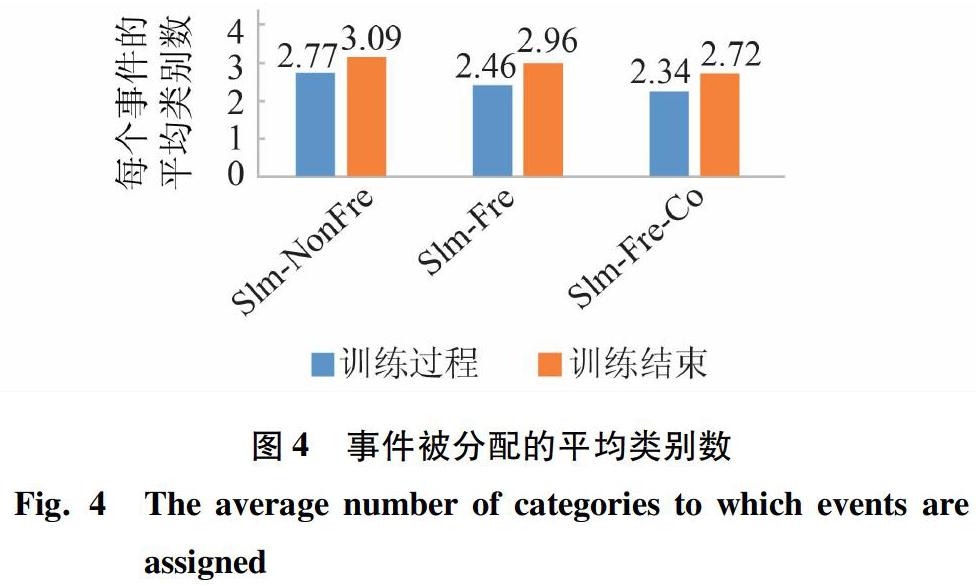
該系統中包含有2類節點,分別是聚類節點di(0 (1)聚類節點。主要進行聚類操作,功能如下: ① 對于事件t,在聚類節點中,同各個類別的特征相比較,找尋可能存在與其相匹配的訂閱所在的類別。 ② 對于訂閱的增加,為其找尋歸屬的唯一類別,進行類別更新的相應操作。 ③ 對于訂閱的刪除,需要找尋可能包含該事件的類別,并進行刪除操作。 (2)匹配節點。節點中分別保存著各個類別,主要進行事件的匹配和訂閱的增刪操作。功能如下: ① 對于事件,會根據其所從屬的訂閱類別,尋找符合匹配條件的訂閱。 ② 對于訂閱的增刪操作,根據其所從屬的訂閱類別,進行類別的更新。 ③ 類別的更新,按照聚類節點對類別的更新信息,相應地更新本節點內的類別。 將算法應用到分布式系統上需要注意數據傳輸問題。此外,在分布式系統中還應注意負載均衡的問題,以避免某一個節點負載過重,成為性能瓶頸。 3.1 類別融合 分布式環境下,需要在滿足聚類要求的情況下,盡量減少節點間的數據傳輸,同時根據相關性,本文將優先進行同一節點內的類別融合。過程中擬用到2個變量:CS(correlation in the same worker)和CD(correlation in the different worker)。 研究中可得,c.cs表示類別c和其同一匹配節點中的類別的相關性之和,相應數學公式可寫為: 其中,w表示類別c所處的匹配節點。 進一步得到,c.cd表示類別c和其不同匹配節點中的類別的相關性之和,相應數學公式可寫為: 在此基礎上,本文采用c.MergeJudgePara作為類別c的判斷標準,選擇該值最大的類別c進行同一匹配節點之內的相關性值最大的類別進行融合操作。相應數學公式可寫為: 如果一個類別和其同一匹配節點中的類別相關性很差,而和不同匹配節點間的相關性很好,即MergeJudgePara很小,在這種情況下,本文提出一個匹配節點間的類別融合策略。首先新增一個閾值merge,該閾值用于判斷僅僅使用節點內融合是否合理,如果計算得到的最大的MergeJudgePara 3.2 負載均衡 負載均衡的主要目的是為了均衡各個節點的負載,避免出現某一節點負載過重,成為性能瓶頸。若經過一定數量的事件和訂閱(本文使用經過λ數量的事件)后,就要判斷節點的負載是否失衡,一旦發生失衡,將盡快修復。 為了判斷是否存在負載不均衡的情況,先要對工作負載進行量化。經過分析可知,類別c需要處理的數據包括3種,分別是:事件t、新添加的訂閱q、需要刪除的訂閱q',故而其工作負載也包含3部分,具體如下: 其中,t.num表示接收到的事件數量; c.size表示類別c的大小,使用類別中訂閱的數量表示。 在公式(7)中,第一部分表示處理事件t的匹配操作的工作負載,其中c.size會隨著訂閱的增刪而變化;第二部分表示在這一段時間內增加訂閱所需的資源消耗;第三部分表示這一段時間內刪除訂閱所需的資源消耗。工作節點的總工作負載就是一段時間內節點內所有類別的工作負載之和。本文使用匹配操作的工作負載表示類別的工作負載。 本文采取的負載均衡策略可描述為:當某一個節點負載過大,直接將其中的一部分遷移到另一個節點中。研究中,將所有節點的工作負載之和設為TotalLoad,假設共有m個工作節點,如果一個節點w的工作負載滿足公式(8): 則認為該節點的工作負載過大,需要進行均衡。在負載均衡過程中,就要從負載最大的節點中選擇一部分訂閱轉移到其他的節點,在選擇這一部分訂閱時,本文判斷轉移操作是否應該停止的標準參見公式(8)。 文中采用貪心策略來計算需要遷移的子集,使用DiviPara作為選擇標準,對其進行運算時需用到公式為: 選擇DiviPara值最大的類別作為需要遷移的子集,直至滿足負載的均衡的要求。使用公式(9),對節點內類別進行排序,轉移類別至待接收的節點,直至達到負載均衡的要求。對于待接收節點,可以選擇和待遷移類別相關性最大的節點。 4 實驗 本節將給出基礎的發布訂閱算法的實驗驗證結果。實驗時使用3臺計算機來搭建分布式環境,3臺計算機的參數配置為:1臺內存為8GB,處理器為Intel(R) Core(TM) i5-8400 2.8GHz,2臺Inter(R) Celeron(R) CPU 1007U 1.5GHz,4GB內存。每個處理器為單核CPU。該分布式環境由研究者自行設計,計算機系統使用Ubuntu18.04,分布式系統使用zookeeper和storm組件進行搭建,涉及到的聚類節點僅選擇2個,匹配節點為4個。 實驗數據采取的是網站http://www.pocketgpsworld.com/上的數據,選擇了網站中大約10萬條數據。這些數據僅僅可用作發布的事件信息,本文使用事件信息生成相應的訂閱信息,方法如下:首先規定訂閱的數量,本文選擇為事件數量的0.01倍;緊接著隨機生成該數量的訂閱,方式為每一個訂閱隨機選擇一個事件,訂閱的屬性集合取該事件的隨機屬性子集,訂閱的空間位置選擇以該事件為中心,經緯度隨機擴大的一定數量為訂閱的空間位置。這樣做就是希望訂閱和事件的匹配結果數盡量多。方便更新相關性。 本文對實驗過程中的參數定義如下:公式(3)中,平衡屬性相似性和空間相似性的參數α=0.5。節點內類別融合和節點間的類別融合的判斷閾值merge=1,聚類節點中網格的間隔設置為5,匹配節點中網格的間隔設置為2,新類別生成的閾值NewTh=0.5,類別負載均衡的次數為2,由事件平均分配,即如果總共10萬條事件,每進行5萬條則轉入負載均衡判斷。 首先,驗證相似性和相關性是否能夠優化聚類操作,從而提升事件和訂閱的匹配速度。提供3種算法來進行對比,分別為: (1)僅僅使用不包含頻數的相似性來進行聚類操作,使用Sim-NonFre來表示。 (2)使用包含頻數的相似性來進行聚類操作,使用Sim-Fre表示。 (3)同時使用包含頻數的相似性和相關性來進行聚類操作,使用Sim-Fre-Co來表示。 針對這三種算法,測量的數據為事件經過空間篩選和屬性篩選后,被分配的類別平均數量。測量的時機分別為: (1)事件流和訂閱流同時存在的過程,該過程從0開始,即從接收到的第一個事件和訂閱開始,同時進行數據的訓練和匹配操作,結果如圖4所示。 (2)僅僅存在事件流的過程,此時訂閱聚類過程已經結束,數據訓練完成,僅僅存在匹配過程,結果如圖4所示。 在圖4中,訓練過程表示事件流和訂閱流同時存在,訓練結束表示訓練完成,僅僅進行事件流的研究。事件需要進行匹配的平均類別數量使用Sim-NonFre結果最多,Sim-Fre結果居中,Sim-Fre-Co結果最少,即使用帶頻率的相似性和相關性相比較于普通的相似性有效地減少了事件需要進行匹配操作的類別數量。對比訓練過程和訓練結束,訓練完成后單純進行匹配操作時,事件被分配的類別增加,因為同時進行訓練和匹配操作,有一些事件發布后,尚未對其給予訂閱關注,隨后才有訂閱關注該事件,使得事件需要進行更多的匹配操作。 隨后,驗證類別融合策略的數據傳輸量。本文將提供訓練過程中DataTra的結果,分別給出僅僅使用節點內的類別融合(使用InNode表示)和同時使用節點內類別融合和節點間的類別融合的數據傳輸量(InAndBetNode表示)。實驗結果如圖5所示。同時使用節點內融合和節點間融合的數據傳輸量InAndBetNode從訓練初期就處于上升階段,但是此后類別將逐漸下降。僅僅使用節點內類別融合的數據量InNode,由于僅僅使用節點內數據融合,類別的分布不合理,使得類別融合操作次數一直居高不下。 接下來,將驗證類別融合策略的效果。本節擬給出2種算法進行對比,分別是:本文的DRt-Cluster算法,Chen等人[13]的發布訂閱算法,Chen等人[13]的研究使用kd-tree作為聚類算法,所以本文使用kd-tree表示該算法。本文將提供事件的吞吐量進行對比,對比結果如圖6所示。經過事件和訂閱的訓練之后,單單進行事件的匹配過程和訂閱的增刪過程來驗證類別的聚類結果和在匹配節點上的分布結果,使用tran/sec表示。由圖6可知,本文的DRt-Cluster算法的吞吐量略高于kd-tree算法。 最后,本文研究了DRt-Cluster算法負載均衡操作前后,數據的吞吐量變化,實驗結果如圖7所示。經過負載均衡操作后,類別的分布更加均勻,數據的吞吐量獲得一定的提升。 5 結束語 本文首先詳細介紹了發布訂閱系統,采取混合屬性的應用方法,提出了相似性和相關性這2種聚類算法中的判斷參數,設計并實現了一個單處理器上的即時發布訂閱算法,隨后設計一個分布式的系統,并且將即時的發布訂閱算法部署其上提出了與其相適應的負載均衡策略,最后通過實驗驗證其效果。 參考文獻 [1]LI G, WANG Y, WANG T, et al. Location-aware publish/subscribe[C]// ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Chicago:ACM SIGMOD Record, 2013:802-810. [2]HU Huiqi, LIU Yiqun, LI Guoliang, et al. A location-aware publish/subscribe framework for parameterized spatio-textual subscriptions[C]// IEEE 31st International Conference on Data Engineering. Seoul, South Korea:IEEE, 2015:711-722. [3]WANG Xiang, ZHANG Ying, ZHANG Wenjie, et al. AP-Tree: Efficiently support continuous spatial-keyword queries over stream[C]// ICDE Workshops 2015. Seoul, South Korea:IEEE,2015, 6(1):1107-1118. [4]CHEN L, CONG G, CAO X. An efficient query indexing mechanism for filtering geo-textual data[C]// ACM SIGMOD International Conference on Management of Data. New York:ACM, 2013:749-760. [5]WANG X, ZHANG Y, ZHANG W, et al. Skype: Top-k spatial-keyword publish/subscribe over sliding window[J]. Vldb Journal, 2017, 26(3):301-326. [6]YU Minghe, LI Guoliang, FENG Jianhua. A cost-based method for location-aware publish/subscribe services[C]//Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. New York:ACM,2015:693-702. [7]CHEN Lisi, CONG Gao, CAO Xin, et al. Temporal Spatial-Keyword Top-k publish/subscribe[C]// IEEE 31st International Conference on Data Engineering.Seoul, South Korea:IEEE, 2015:255-266. [8]AJI A, WANG Fusheng, VO H, et al. Hadoop-GIS: A high performance spatial data warehousing system over mapreduce[J]. Proceedings of the VLDB Endowment, 2013,6(11):1009-1020. [9]ELDAWY A, MOKBEL M F. SpatialHadoop: A MapReduce framework for spatial data[C]// IEEE 32nd International Conference on Data Engineering. Helsinki, Finland: IEEE, 2016:1352-1363. [10]AKDOGAN A, DEMIRYUREK U, BANAEI-KASHANI F, et al. Voronoi-based geospatial query processing with MapReduce[C]// 2010 IEEE Second International Conference on Cloud Computing Technology and Science. NW Washington,DC: IEEE Computer Society, 2010:9-16. [11] NISHIMURA S, DAS S, AGRAWAL D, et al. Md-HBase: A scalable multi-dimensional data infrastructure for location aware services[C]// 2011 12th IEEE International Conference on MDM. Lulea, Sweden:IEEE, 2011,1: 7-16. [12]ALY A M, MAHMOOD A R, HASSAN M S, et al. AQWA: Adaptive query-workload-aware partitioning of big spatial data[J]// Proceedings of the VLDB Endowment,2015,8(13):2062-2073. [13]CHEN Zhida, CONG Gao, ZHANG Zhenjie, et al. Distributed publish/subscribe query processing on the spatio-textual data stream[C]// IEEE International Conference on Data Engineering.San Diego, CA, USA:IEEE, 2017: 1095-1106.
