
基于多智能體元強化學習的車聯網協同服務緩存和計算卸載
2021-07-16 13:05:16寧兆龍張凱源王小潔郭磊
通信學報 2021年6期
寧兆龍,張凱源,王小潔,郭磊
(1.重慶郵電大學通信與信息工程學院,重慶 400065;2.大連理工大學軟件學院,遼寧 大連 116620)
1 引言
隨著5G 時代的到來和互聯網設備的普及,萬物互聯的概念逐漸走進人們的生活,這推動了大量時延敏感型的移動應用,如增強現實、實時導航以及自動駕駛等[1-2]。雖然云技術逐漸成熟,但是隨著移動設備的指數性增長,單純依靠中央云服務器來控制廣域網存在時延難以保證的瓶頸[3],從而難以保證時延敏感型應用的服務質量。因此,移動邊緣計算應運而生,成為目前解決上述問題的一種可靠方案。移動邊緣計算將計算資源和存儲資源以分布式的方式部署在距離用戶層更近的邊緣節點上,使這些邊緣節點就近處理其覆蓋區域內的相關業務,從而減輕回程鏈路的傳輸壓力,并節約相應的服務響應時間。相對于中央云服務器的可擴展性,輕量化的邊緣服務器存在資源容量受限和資源利用不均等問題[4-5]。尤其是隨著移動應用的多樣性增強,其所需的資源也具有很強的異質性,這導致資源利用率低的問題日益凸顯。
人工智能和機器學習技術的不斷發展,以及其在多個領域的成功應用,使其正成為解決移動邊緣計算瓶頸問題的關鍵技術[6-7]。和傳統技術相比,人工智能技術對于環境的動態變化擁有更強大的感知能力。作為其重要分支,深度強化學習在資源分配方面已經得到一定的應用,文獻[8-12]都表明基于強化學習的車聯網資源分配解決方案具有較好的準確性和穩健性。隨著用戶需求的動態變化以及多方主體(設備節點、邊緣節點和云服務器)的參與,車聯網系統需要一種效率高、均衡性強的任務調度和資源分配方法。同時,由于邊緣節點的資源有限,需要輕量化、分布式的機器學習技術與其進行適配,從而完成高效的學習過程。
車聯網作為萬物互聯時代的重要一環,由于車輛的高移動特性和車輛應用需求的時變性,車輛應用的處理存在著更突出的難度[13]。為了更好地服務車輛用戶和建設智慧城市,需要部署大量裝配邊緣服務器的路側單元(RSU,road side unit)來更好地處理其覆蓋區域內的車輛應用。因此,車輛、RSU和云服務器構成了常見的三層車聯網框架[14]。然而實際情況下城市中車流分布通常是不均勻的,這導致一些RSU 沒有足夠的資源緩存車輛應用所需的服務,從而需要將計算任務卸載到云服務器;另一些RSU 還有很多剩余的緩存空間沒有得到利用,這就導致車聯網系統的整體時延增加[15]。因此,為了充分利用車聯網中的緩存和計算資源,需要網絡運營商挖掘RSU 之間的合作能力,從而提升車聯網的服務效率。
車聯網中的計算卸載和服務緩存得到學術界和工業界的廣泛關注,因為通過制定相應策略可以更好地提升網絡性能并減少能耗[16-17]。文獻[16]提出一種多時間尺度的強化學習框架來進行緩存和計算資源的分配來最小化車輛應用的服務時延。文獻[18]考慮了用戶的移動性和網絡連通性來進行內容緩存,從而能夠縮短用戶對內容的獲取時間。文獻[13]在能耗限制的情況下,通過計算卸載的方式滿足了所有基站的能耗約束。很多研究關注車聯網中的合作機制,文獻[19]中,當車聯網需要處理計算密集型任務時,多個邊緣服務器會共同合作處理相關應用。文獻[20]研究多接入車聯網,將資源豐富的車輛與云服務器相結合,構建協同計算架構。也有很多相關研究利用車輛用戶的屬性,比如社會信任、位置區域等構建相應的車輛應用處理集群[5,14]。然而,這些研究大多集中在用戶與服務器、用戶與用戶間的合作,缺少對于邊緣節點之間合作的研究來提升車聯網的整體服務性能。
本文考慮了車聯網中RSU 之間的合作來解決車輛應用處理過程中的服務緩存和任務調度問題。解決這一問題存在如下幾個挑戰:1) 車輛服務緩存和任務調度具有耦合性,車輛服務緩存決定任務調度的決策空間,任務調度的結果反映服務緩存的表現;2) 任務計算和傳輸的權衡,RSU 間合作會減少任務的計算時間,從而增加系統內的傳輸時間,如何在兩者之間進行權衡得到最優解也是一個挑戰;3) RSU 行為平衡,即RSU 間合作能夠降低系統時延,但求解過程中需避免陷入每個RSU 的局部最優,而是求解全局最優策略。
本文主要的研究工作如下。
1) 本文構建了多邊合作的車聯網服務模型,它聯合了任務緩存和邊緣任務調度問題,在可用資源約束的情況下,最小化系統時延。本文將車聯網服務問題建模成一個混合整數非線性規劃問題,并證明求解該問題需要非多項式的計算復雜度。
2) 本文提出了一種雙層的多RSU 協同緩存框架求解上述問題,它采用多智能體元強化學習框架為RSU 緩存車輛應用提供所需服務。每一個RSU作為一個本地智能體計算其對應狀態下的緩存決策,云服務器作為元智能體,采用長短期記憶(LSTM,long short-term memory)結構的神經網絡來平衡本地智能體的決策,并維護自己的狀態信息來進行更快的策略學習。
3) 在緩存策略確定的情況下,本文提出一種自適應的RSU 協同卸載算法,它采用拉格朗日乘子法來求解最佳協同卸載策略。本文通過二分迭代搜索的思想搜索最優拉格朗日乘子,從而調度系統中每一個RSU 的計算任務,實現系統中所有RSU 的工作量負載均衡。
4) 本文采用杭州交通流數據進行實驗,結果表明本文提出的算法具有良好的效能和實用性。與其他3 種基準算法相比,本文提出的算法能夠獲得更低的系統時延,并且能在大規模任務流下擁有相對穩定的表現。
2 系統模型
本文構建的多邊車聯網服務系統由N個RSU和一個提供服務的云服務器組成,如圖1 所示。

圖1 多邊車聯網服務系統模型
RSU 分布在城市中的不同區域,并配置邊緣服務器為其相應區域內的車輛提供計算服務,不同的RSU 之間通過局域網連接,且具有計算功能和服務緩存功能。車輛用戶會和其鄰近RSU 通過無線通信的方式,將計算任務上傳到對應的邊緣服務器上,考慮它們之間的連接采用正交頻分復用技術,因此多個車輛可以在不考慮干擾的情況下和同一個RSU 通信。為了完成不同類別的車輛應用,系統需要從服務商處下載不同的服務,例如視頻轉碼服務和障礙物識別服務等,設 S={1,2,…,S}表示系統提供的服務集合,且緩存服務所需的存儲空間為ps,Fn和Cn分別表示RSUn擁有的計算能力和緩存能力,M={1,2,…,M}和 N={1,2,…,N}分別表示車輛用戶和RSU的集合。假設RSUn接收車輛應用任務是一個泊松過程[20],且任務接收速率為,處理一個任務所需的計算資源(CPU 周期數)服從期望為h的指數分布。本文主要變量及其含義如表1所示。

表1 主要變量及其含義
2.1 服務緩存模型
由于車輛資源有限,并且車輛應用對于處理時延具有嚴格要求,因此需要通過計算卸載的方式上傳到RSU 進行實時處理。此外,為了處理車輛任務,RSU 需要從中央云服務器上緩存任務所需的服務;否則,RSU 需要將任務上傳到云服務器上進行處理。中央云服務器擁有充足的計算能力和緩存能力,因此,如果在云服務器上處理任務,時延主要由從RSU 上傳到云端的傳輸時延Tcloud造成。設表示服務的緩存策略,表示RSUn的緩存策略。由于RSU 的緩存能力有限,因此對于每一個RSU,不等式成立。同時,由于同一個服務可能緩存在多個RSU 上,不同的RSU 處理應用所需的服務可能緩存在其他RSU 上,因此,系統需要根據服務緩存情況進行協同卸載,從而更好地利用系統中的空閑資源。
2.2 任務計算模型
在協同卸載過程中,本文假設計算任務在服務器間只能卸載一次,即如果計算任務從RSUi卸載到RSUj,那么任務將在RSUj上的服務器上執行,而不會再卸載到其他RSU。設表示系統的協同卸載策略,其中表示t時刻由RSUi卸載到RSUj的計算任務數量,表示RSUi自身處理的任務數量,則RSUi在t時刻處理的任務數量可以表示為。RSU 接收任務的過程是一個泊松過程,本文采用M/M/1 排隊系統來為任務處理建模[21],車聯網系統的計算時延可以表示為

其中,μi=Fi/h。為了滿足任務隊列處理的穩定性,≤μi需要得到滿足以確保每一個RSU 的服務性能。
由于網絡帶寬有限,協同卸載會導致額外的擁塞時延。系統的擁塞時延由網絡中的全部任務數量決定,系統中的總任務數量為,其中=表示RSUi卸載到其他RSU 的任務數量。根據M/M/1 排隊模型相關理論[18],系統的擁塞時延為

其中,τ表示在帶寬充足情況下通過局域網傳輸一單位計算任務的時延。
2.3 問題描述
綜上所述,系統時延主要由3 個部分組成,分別是計算時延、擁塞時延和(從RSU 上傳到中央云服務器的)傳輸時延。系統時延sT為
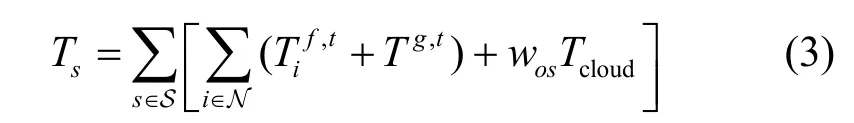
其中,wos≥0表示系統中需要服務s且需要上傳到云服務器上處理的任務數量。
本文聯合考慮服務緩存策略和服務器間的協同卸載策略,目標是最小化車輛任務的處理時延,得到如下優化問題。

其中,約束C1 保證每個RSU 緩存的服務不能超過其緩存能力;約束C2 保證每個RSU 協同卸載的任務數量不能超過其接受的車輛任務數量;約束C3保證每個RSU 處理的任務數量不超過其計算能力。
定理1優化問題P1是一個混合整數非線性規劃,求解其需要非多項式的計算復雜度。
證明效用函數凸凹性
通過2 種簡化情況來分析優化問題P1 的計算復雜度。
1) RSU 不進行協同卸載。當RSU 不進行協同卸載時,不同服務所對應的計算任務只能由接收任務的RSU 進行本地計算或者上傳到云服務器上。因此,系統時延不僅由RSU 的計算能力決定,也高度依賴于RSU 的服務緩存能力。這時,優化問題P1 可以轉化為服務緩存問題和任務流輸出問題,類似于文獻[13]。文獻[13]已經證明這個問題是一個混合整數非線性規劃問題,并且擁有非多項式的計算復雜度。
2) 所有計算任務需要同一種服務。當所有計算任務需要同一種服務時,在計算資源充足的情況下,服務會被緩存在任一個緩存空間充足的RSU。因此,該種情況可以被看作一個協同卸載問題,即在計算資源約束的情況下,進行計算任務的分配,類似于文獻[18]。文獻[18]已經證明求解這一問題擁有非多項式的計算復雜度。
通過上述分析,2 種簡化情況都具有非多項式的計算復雜度。因此,求解本文的優化問題P1 也具有非多項式的計算復雜度。證畢。
3 算法設計
由于求解優化問題P1 具有非多項式的計算復雜度,本文提出一種雙層的多RSU 協同緩存算法(MPO,mutli-RSU service caching and peer offloading algorithm),外層采用多智能體元強化學習框架來為RSU 緩存車輛應用所需的服務;內層在緩存策略確定的情況下,在緩存同一種服務的RSU 間進行協同卸載,本文提出一種自動任務適應算法來求解系統的協同卸載策略。算法流程如圖2 所示。

圖2 算法流程
3.1 基于多智能體學習的緩存分配策略
本文提出一種多智能體元策略的強化學習(MAMRL,multi-agent meta reinforcement learning)框架進行RSU 的緩存分配,算法架構如圖3 所示。

圖3 多智能體元策略的強化學習框架
和傳統的強化學習相比,MAMRL 框架包含2 種智能體:一種是本地智能體,它配置在每一個RSU上,根據任務量和RSU 上的可用資源并利用強化學習算法進行自身緩存資源的分配;另一種是元智能體,它配置在云服務器上,根據每一個本地智能體學習到的信息和任務量的信息,利用LSTM 進行全局緩存資源分配。MAMRL 減輕了因任務產生和資源需求帶來的維度災難,同時減少了RSU 和云服務器之間的消息傳遞(本地智能體只需向元智能體上傳其處理過的信息而不是全部信息),從而提供一個計算和通信復雜度更低的緩存分配方案。


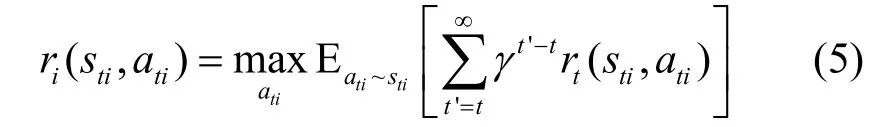
其中,γ∈(0,1)為折扣因子。在狀態sti下采取動作定義為一個策略πθi,它是由參數θi決定的。策略πθi決定了狀態轉移函數Γ:S ti×Ati?St′i,以及相應的獎勵值函數ri(s ti,a ti):S ti×Ati?R。因此,在給定狀態sti下,策略的狀態值函數可以表示為

狀態值函數可作為評論家的角色來評判每一個動作在該狀態下的表現。因此,對于狀態sti下的最佳策略(ati|sti),可以由該狀態的值函數最大值確定,即最大的狀態值函數可以獲得其對應的最佳策略,最優值函數為

通過式(7)可以選擇出每一個決策智能體i的最佳策略。采用時序差分(TD,temporal difference)法求解最優值函數和最優策略,采取策略iθπ的優勢函數(TD 誤差)定義為

其策略梯度為

通過式(9)可以將網絡中每一個RSU 的緩存決策離散化求解。在所有狀態信息已知的情況下,本文可以采用集中式的解決策略,它的時間復雜度為O(Si Ai|N|2T),這需要消耗大量的計算資源。同時,由于集中式的解決策略忽略了其他智能體的決策,導致強化學習過程中的探索和開發出現不平衡的現象,因此本文提出一種元策略的強化學習框架來解決上述困難。
2) 元策略強化學習模型

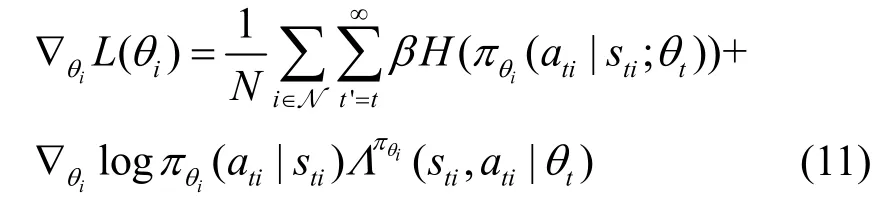
元智能體由LSTM 結構的神經網絡組成,設它的網絡參數為φ,且由4 個門層來計算出下一個狀態st'i的最優決策和其對應的優勢函數,4 個門層分別為遺忘門Ft'、輸入門It'、單元狀態層和輸出層Zt'。元智能體的具體實現為
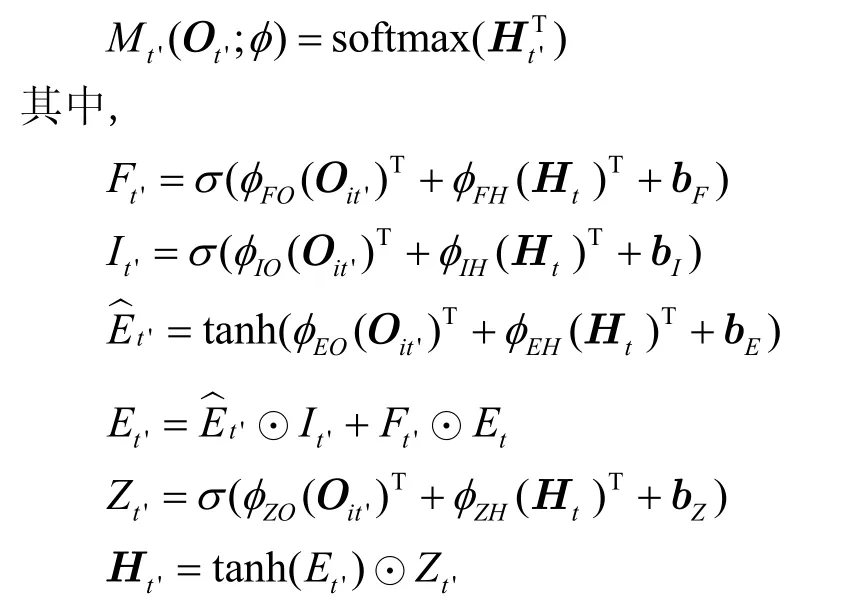
其中,遺忘門Ft'負責確定哪些信息需要拋除;輸入門It'負責確定哪些信息需要更新;單元狀態層使用tanh(·) 函數產生新的候選值向量,并通過公式更新單元狀態層;輸出層Zt'決定哪些信息輸出,通過公式計算單元輸出,并將最終的輸出利用softmax 函數輸出最佳策略。因此,元智能體的損失函數是由本地智能體的分布所決定的,其損失函數的期望可以表示為

因此,MAMRL 框架將元智能體的學習參數傳遞給本地智能體,以便每個本地智能體更新自身的學習參數來計算出最優的緩存分配策略。其參數更新式為

MAMRL 框架可以理解成一個多參與人(N-player)的馬爾可夫博弈模型。根據當前對多人馬爾可夫博弈模型的研究[22],MAMRL 模型至少存在一個納什均衡點來保證最佳的緩存分配策略。因此,對于MAMRL 模型求解的最優性,有命題1 成立。
命題1對于RSUi,其最佳的緩存分配策略是一個納什均衡點,且其納什均衡值為。
證明對于RSUi而言,是綜合考慮所有RSU 動作后產生的納什均衡的最優策略。因此,BSi無法采取更優的策略來提升,則對于式(10),有如下不等式成立

通過上述不等式可知,MAMRL 模型中的元智能體Mt'(Ot';φ)能夠在RSUi采取策略時達到納什均衡,且RSUi的最優值為
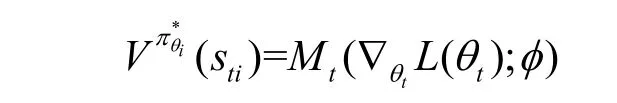
因此,最優策略是緩存分配問題的一個納什均衡點。證畢。
對于MAMRL 模型的收斂性,有命題2 成立。
命題2對于式(10)的梯度估計,可以建立估計值θiL(θi)和真實值?θiL(θi)之間的關系為

證明對于RSUi在時刻t采取動作ati的概率可以表示為

考慮單個狀態的情況下,策略梯度的估計量可表示為

因此,RSUi的期望獎勵可以表示為
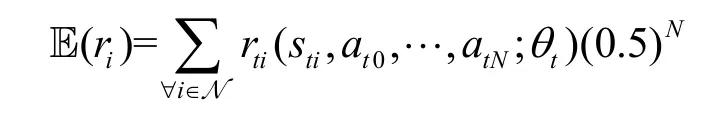

上式說明,在求解過程中,梯度步長朝著正確的方向移動,且隨著RSU 數量的增加而呈指數級下降。證畢。
MAMRL算法的偽代碼如算法1和算法2所示,其中算法1 為本地智能體訓練過程,算法2 為元智能體訓練過程。
算法1本地智能體訓練


算法2元智能體訓練

3.2 RSU 協同計算卸載算法
當所有RSU 的緩存策略確定后,優化問題P1將轉換為車輛任務在緩存同一服務的RSU 之間進行協同計算卸載的子問題P2

將式(1)~式(3)代入優化問題的目標函數中,可以得到

變量和 是2 個獨立變量,根據上文定義可知,它們都是由RSU 協同計算卸載策略β決定的,其定義和關系見2.2 節,因此可以通過求解式(14)來確定最優協同計算卸載策略。對于每一個緩存服務s,它與其他的緩存服務之間是獨立的。因此,在問題求解過程中,下文以服務s為例,對于子問題P2,本文采用一種迭代的思路搜尋解空間中滿足KKT 條件的結果作為優化問題的解。在RSU 協同計算卸載過程中,對于每一個RSU 都有工作量負載均衡等式成立,其中,Ii表示RSUi的接收任務量,Oi表示RSUi的輸出任務量。根據定義,有成立。將上述等式代入優化問題,可將優化問題P2 轉化為關于變量I和O的優化問題P3

為了求解上述優化問題,本文首先將RSU 處理計算任務分為3 種模式:接收模式、平衡模式、卸載模式。接收模式表示RSU 接收來自其他RSU的計算任務;平衡模式表示RSU 不接收其他RSU的任務也不發送計算任務給其他RSU;卸載模式表示RSU 發送自身的計算任務給其他RSU。RSU 在處理計算任務時,只能選擇一種模式。同時,本文定義2 個輔助函數來進行優化問題求解,一是邊界計算時延函數

它表示當RSU 處理任務的計算時延的邊界值;二是邊界網絡擁塞時延

定理2RSU 在t時刻的任務處理模式和最優協同計算卸載策略如下所示。


其中,λt*和α是式(17)的解,λt*表示最優網絡擁塞時延,α表示拉格朗日乘子,R和 F 分別表示網絡中處于接收模式和卸載模式的RSU 集合。
由于直接通過求導來求解α存在較大困難,因此本文采用一種二分迭代搜索的思路來通過工作量負載等式尋找最優解。在每一次迭代中,首先通過初始參數α確定處于接收模式的RSU 以及其接收的任務量λR。然后,令λ=λR來確定網絡中處于平衡模式和卸載模式的RSU,并計算卸載的任務量λF。如果λ R=λF,此時的α為最優解;否則,算法更新參數α并進入下一輪迭代。求解算法流程如算法3 所示。
算法3二分迭代協同計算卸載算法
輸入RSU 接受任務量,i∈N,t∈T,RSU服務速率μi,i∈N,網絡通信時間τ
輸出

4 實驗結果和分析
本文利用杭州真實的交通流數據模擬任務的產生,驗證本文提出的車聯網系統的有效性。系統中由一個云服務器和9 個RSU 組成(如圖4 所示),每一個RSU 的覆蓋區域為200 m×200 m,且為車輛提供8 種類型不同的服務。為了適應不同規模的任務量,RSU 布置在杭州市中心如圖4 所示的9 個十字路口,且每一個車輛產生任務服從速率為[0,4]任務/2 分鐘的泊松分布。其他參數設定如表2 所示。

圖4 車聯網系統布置說明

表2 參數設定
本文與3 種基準算法進行比較。1) 非協作卸載算法:RSU 完成緩存分配后,只有RSU 本地處理或上傳到云服務器處理2 種情況。2) 單智能體緩存算法:采用單智能體強化學習進行緩存分配,然后采用協同計算卸載進行計算任務分配。3) 貪婪緩存策略:每個RSU 緩存最流行的服務,然后計算任務將在本地處理或上傳到云服務器進行處理。
4.1 系統表現
圖5 為不同智能體(9 個本地智能體和一個元智能體)獲得的獎勵值,本文計算每50 次迭代的平均獎勵值。在MAMRL 框架中,所有的智能體經過1 000 輪迭代都會得到一個收斂的獎勵值,其中,元智能體擁有最高的獎勵值(大約為90),所有的本地智能體(RSU)在收斂時大約為80 到85,只有一個RSU 6 收斂時獎勵值在70 左右。不同RSU 上的獎勵值變化是由RSU 上處理任務的不同和分配資源的不同所導致的,同時也由強化學習中各個本地智能體求解資源分配方案過程中的探索和利用權衡所決定。

圖5 多智能體元強化學習中不同智能體的獎勵值
圖6為本文提出的緩存分配策略在不同探索衰減下的系統表現。探索率表示強化學習過程中對于動作空間的探索概率,從而在探索和利用之間進行權衡搜索到最優的緩存策略。初始情況下,探索率大可以快速探索動作空間中的優秀策略,探索率逐漸衰減可以平衡動作選擇過程中的探索利用效率,從而使智能體逐漸搜索到最佳策略(動作)。較大的探索衰減強調動作選取中的探索過程,可以獲得更快的收斂速度,但是可能導致智能體對于動作空間探索不夠完全;較小的探索衰減則強調動作選取中的利用過程,可能會獲得更好的收斂結果,但是不斷減小該值可能會影響收斂速度。因此在仿真實驗中,本文將探索衰減設置成不同值來觀察收斂效果,可以看出,當探索衰減大于1 0?4時,1 000 輪迭代內可以收斂;當探索衰減為0.1 時,收斂時的獎勵值較低。

圖6 不同探索衰減的收斂結果
4.2 性能對比
和其他3 種基準算法(非合作卸載、單智能體緩存、貪婪緩存)相比,本文提出的多RSU 協同緩存算法表現最優,能夠得到最低的系統時延。圖7 給出了不同緩存大小下不同算法的網絡時延。緩存大小對于RSU 緩存內容的選擇具有重要的影響,緩存大小為0 則表明所有處理任務的服務需要從云服器上下載,因此所有的緩存策略失去意義;如果緩存大小超過任務所需的服務個數,服務器可以緩存所有的服務,緩存策略也失去意義。因此,本文只討論緩存大小在區間內不同算法的表現情況。從圖7 中可以看出,隨著緩存大小的增加,所有算法的系統時延都會有所下降,但是本文提出的算法相比較其他3 種算法表現更加優異;在緩存空間明顯不足時,本文提出的算法相較其他3 種算法提升更明顯,這說明本文提出的算法能夠更好地應對資源有限情況下的緩存分配問題,即能夠在有限的資源情況下,最小化系統時延。

圖7 不同緩存空間下系統時延對比
圖8 說明了不同緩存大小下不同方法中從RSU輸出到云服務器處理的任務大小。當RSU 之間無法通過協同卸載來處理用戶任務時需要將任務傳輸到云服務器來處理,這一過程需要相對高的傳輸時延。因此,輸出到云服務器的任務量可以表明不同方法的協同卸載處理情況。從圖8 中曲線可以看出,隨著RSU 緩存空間的增加,更多的任務可以在RSU 集群內進行處理,因此傳輸到云服務器的任務數會越來越小,相比其他3 種算法,本文提出的算法因為具有協同計算卸載機制會在RSU 之間進行處理任務,而不是直接上傳到云處理器,因此會大幅減少輸出任務量;相比單智能體緩存算法,多智能體算法在緩存空間相對不足的情況下,表現更佳,這說明本文提出的算法在受限資源情況下表現更佳。

圖8 不同緩存空間下輸出任務情況對比
圖9 和圖10 分別表明了在用戶產生不同數量任務的情況下不同方法的系統時延和輸出到云服務器的任務數量分布。當用戶產生的任務數量增加時,系統的計算壓力會增大,導致系統時延增加,同時也需要將更多的任務上傳到云服務器上進行處理。如圖9 所示,用戶產生的任務越多,所有算法的系統時延都呈上升趨勢,其中貪婪算法和非協作卸載算法上升趨勢明顯,因為在緩存資源有限的情況下,依靠單獨RSU 來處理對應任務效率低,只有通過多RSU 合作來處理相應任務才能獲得更低的系統時延,相對于單智能體緩存算法,多智能體算法同時考慮每一個RSU 的任務情況,因此能夠獲得更低的系統時延。圖10 表明用戶產生任務的增加導致更多任務需要上傳到云服務器處理。從圖10 可以看出,用戶任務在3 到6 時增長趨勢較緩慢,而當用戶任務繼續增加后,由于RSU緩存空間有限,所有算法都需要將大量的任務上傳到云服務器,因此輸出任務數量增長趨勢會更加明顯。

圖9 不同任務數下系統時延對比

圖10 不同任務數下輸出任務情況對比
5 結束語
本文在車聯網邊緣計算系統中聯合考慮了用戶任務緩存和邊緣任務調度問題,并將其建模成一個混合整數非線性規劃問題,從而最小化系統時延。為了降低問題求解的計算復雜度,本文提出一種雙層的多RSU 協同緩存框架將問題進行解耦,其中外層采用多智能體元強化學習方法,在每個本地智能體進行決策學習的同時,采用LSTM 作為元智能體來平衡本地決策并加速學習,從而得到最優的RSU 緩存策略;在緩存策略確定后,內層采用拉格朗日乘子法求解最佳協同卸載策略,實現RSU 間的任務分配。基于杭州真實交通數據的實驗表明,本文提出的算法具有很好的能效性能,并且能夠在大規模任務流下保持網絡穩健性。
猜你喜歡
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
數學大世界(2018年1期)2018-04-12 05:39:14
