一種改進的廣域網低延遲分布式共識算法
2021-07-21 09:12:32牛保寧張栩豪
太原理工大學學報 2021年4期
弓 婷,牛保寧,張栩豪
(太原理工大學 信息與計算機學院,山西 晉中 030600)
目前,Paxos[1]及其改進算法[2-9]已經被應用到全球式分布式系統[10-11]中。Multi-Paxos[12]是Paxos的改進算法之一,分兩階段執行,在第一階段的準備階段(Prepare phase),發起共識請求的節點(proposer)廣播被賦予唯一編號的提案。收到提案的節點(acceptors)判斷當前提案的提案號是否最高,若是,則向proposer回復同意信息,否則不同意該提案。proposer獲得多數(51%)acceptors同意后,被確定為Leader,進入第二階段。回復同意信息的acceptors構成第一階段Quorum(Q1).在第二階段的接受階段(Accept phase),Leader將含有提案值的提案發送給acceptors.提案值獲得多數acceptors同意后,對該提案值達成共識。回復同意提案值的acceptors構成第二階段Quorum(Q2).Leader可以連續多次執行算法的第二階段,確定多個命令。現有應用于廣域網的分布式共識算法大多是以Multi-Paxos為基礎。
在廣域網中,分布式系統的節點被部署在各個不同的地理位置,通常以國家或地區為單位劃分區域。Multi-Paxos的執行需要大量的跨區域通信,每個命令達成共識的延遲L由兩部分構成:客戶端與服務器節點(proposer或Leader)間的通信延遲Lc、服務器節點執行Multi-Paxos的延遲Le.由分析達成共識的過程可知,延遲最大的部分是Le.當系統中無固定Leader時,Le由第一階段的延遲L1和第二階段的延遲L2構成;當系統中有Leader時,Le主要由L2構成。減小共識延遲L的關鍵在于減小L1和L2.在此基礎上,通過減小Lc可進一步減小L.
廣域網中的通信代價是共識延遲的主要原因,Q1和Q2節點數量越少,L1和L2就越小。Quorum相交要求是保證算法安全性要求的關鍵,算法的安全性要求是指算法兩階段確定的提案值是唯一的。現有算法對Quorum的改進思路主要是減少Q2節點數量,增加Q1節點數量。在Leader頻繁轉移的系統中,Q1節點數量增大,導致第一階段的執行代價也隨之增加。
Lc的大小受客戶端與服務器節點間的距離影響。若系統中無Leader,則客戶端所在區域的節點發起第一階段提案,成為Leader,Lc幾乎為0.若當前系統有Leader,且與客戶端不在同一區域,則會產生較大的Lc.在這種情況下,產生大量的跨區通信,導致通信延遲增加;當客戶端頻繁發起對某個數據操作的命令請求,產生所謂的hot-key現象,通信延遲更加嚴重。在Leader的改進方面,現有算法主要關注于Multi-Paxos中存在的單Leader瓶頸,采用Leader-Less和Multi-Leader方案,不考慮客戶端與Leader之間的位置關系。如果能夠動態優化Leader所在位置,使得Leader與發起操作的客戶端處于同一區域,可以減少跨區通信,降低共識延遲及hot-key現象。
針對上述第一階段執行代價大、Leader與客戶端的位置關系問題,本文提出一種適用于廣域網的分布式共識算法SQPaxos,分別從Quorum構成策略和Leader分配策略上對現有算法進行改進。本文的創新點總結如下:
1) 針對算法使用的Quorum,提出了最小Quorum實現方案。在Quorum的大小方面,根據系統容錯能力和算法安全性要求,計算出兩階段所需的最小Quorum節點數量。在Quorum節點構成方面,考慮到提案號的唯一性,提出建立提案號與節點編號之間的映射關系。根據提案號為該提案分配固定的節點集,構成兩階段的Quorum,滿足Quorum相交要求。
2) 針對客戶端與Leader之間的延遲問題,提出自適應的Multi-Leader方案,為數據對象劃分Leader,每個數據對象最多有一個Leader,實現不同數據對象的并行處理。同時優化客戶端與Leader之間的位置關系,當所有區域的客戶端對某個數據對象的操作次數超過某個固定值后,根據各區域客戶端對該數據對象的操作頻率,將Leader轉移至操作頻率最高的區域中。
1 相關工作
現有的廣域網分布式共識算法大多是對Multi-Paxos的改進,主要針對Quorum構成和Leader分配進行改進。
在Quorum方面,現有算法提出不同的Quorum相交要求,主要思路是在滿足算法安全性要求的基礎上,減小Q1和Q2.這些算法實現了最小化Q2,卻沒有實現最小化Q1.目前有3種Quorum相交方案:Majority Quorum(Paxos[1]、Multi-Paxos[12])、Flexible Quorum(FPaxos)[13]、Expanding Quorum(DPaxos)[14].Majority Quorum的主要思想是保證任意兩個Quorum相交不為空,由系統中的多數(51%)節點分別構成Q1和Q2.這是保證Quorum相交最直觀的方式,但是這種方式導致達成共識的過程中通信節點數量多,廣域網共識延遲大。Flexible Quorum要求不同階段的Quorum相交,根據Multi-Paxos第二階段使用頻率比第一階段高的事實,通過減少Q2節點數量,同時增加Q1節點數量,以降低總的延遲。但增大Q1,導致第一階段選舉Leader的代價增加。Expanding Quorum要求當前提案使用的Q1與之前提案使用的第二階段Quorum(Q2′) 相交,proposer提前聲明提案將使用的Q2,將提案與自己的Q2綁定在一起,方便其他提案獲取當前提案Q2的同時,也方便當前提案通過該方法獲取其他提案的Q2′.最壞情況下,DPaxos的第一階段需要兩輪廣域網通信,導致Q1的節點數量增加。另外,提前聲明Q2的方法增加了通信復雜度。
本文使用基于分區的Quorum模型實現Quorum相交方案,提出建立提案號與Quorum節點間的映射,根據提案號分配Q1和Q2節點,當前提案在發起第一階段提案之前,獲取到之前提案的Q2′,并將這些節點加入當前提案的Q1中,使用一輪通信完成第一階段,實現了最小的Q1和Q2.
在Leader分配問題方面,現有的改進算法采用Leader-Less(EPaxos)[15]和Multi-Leader兩種方法,其中Multi-Leader包括劃分序列塊領導權(Mencius)[16]和劃分數據對象領導權兩種實現方案。Leader-Less是由EPaxos提出的方案,所有節點都可以接收客戶端命令,在各節點處理的數據對象不沖突的情況下只需要一輪通信就能達成共識,但是如果命令發生沖突,需要解決沖突,導致延遲增加。Mencius提出為節點劃分命令序列實現Multi-Leader,節點輪流當命令序列中序列塊的Leader,這種方法有效解決了Leader與其他節點負載不均衡的問題,但算法整體性能受單個節點處理能力影響。另一種Multi-Leader實現方案是將數據對象的領導權劃分給不同節點,不同數據對象的提案可以并行處理,在此基礎上,WPaxos[17]以定時轉換的方法轉移領導權,存在Leader轉移不及時的問題。對此,本文提出了自適應劃分數據對象的Multi-Leader方案。
2 SQPaxos算法
SQPaxos通過最小化兩階段Quorum節點數量和自適應轉移Leader來降低共識延遲。圍繞以上途徑,2.1節介紹最小化Q1和Q2的思路;2.2節按照該思路,介紹如何構成Quorum;2.3節介紹如何自適應地轉移Leader.
2.1 最小化Q1和Q2的思路
最小化Q1和Q2節點數量的前提是滿足算法安全性和系統的容錯要求。在此基礎上,按照區域節點的分布選擇節點,構成Q1和Q2,實現最小化Quorum.
基于分區的Quorum模型將系統中的節點劃分到不同區域,模型如圖1所示。為方便描述,不妨假設各區域的節點數量一樣,圓代表節點,列代表區域。Q1的任務是選舉Leader,為保證同一時刻,系統中的每個數據對象至多有一個Leader,要求任意兩個Q1至少有一個公共節點,因此最小的Q1應該由系統中的多數區域,以及這些區域中的多數節點構成。對于Q2,需要滿足系統的容錯要求,即大于系統能夠容忍的最大區域故障數和區域內的節點故障數。區域故障是指區域中的所有節點都不可用。除遭遇自然災害,一般情況下,不會發生區域故障,因此Q2應該盡量由Leader所在區域內節點構成。如圖1,系統中有8個區域Z1-Z8,每個區域中有5個節點,如圖中實線框所示,最小的Q1由5個區域組成,每個區域中選擇3個節點。注意,此時Q1中節點的數量是15個,少于全部節點數量(40)的一半。假定系統容錯模型是最多允許0個區域故障,區域中允許1個節點故障,則如圖中虛線框所示,最小的Q2由1個區域中的2個節點構成。
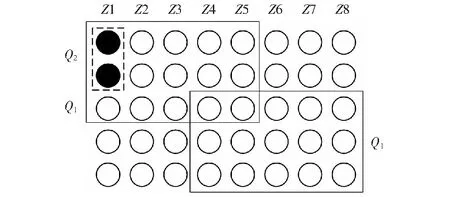
圖1 分區Quorum模型Fig.1 Partitioned Quorum model
最小Q1和Q2不能保證兩者相交,需要通過選擇用哪些節點構成Q1和Q2來保證。按照DPaxos的Quorum相交要求,當前提案使用的Q1與之前提案使用的Q2′相交,這樣做可以保證算法第一階段的任務的正確完成。一是判斷當前提案的提案號是否是最高提案號,只有提案號最高的提案才能繼續執行算法;二是為了獲取已經被acceptors接受的提案,proposer從這些提案中,選擇具有最高提案號的提案值,將該值作為自己第二階段的提案值。這提示我們:如果可以預先確定最高提案的Q2′的節點,就可以確定Q1.選舉Leader時,把Q2′的至少一個節點作為Q1的節點,獲取提案值,滿足Q1與Q2′相交。因此,本文首先確定Q2,在此基礎上確定Q1.
對于Q2的確定,我們注意到每個提案的提案號是唯一的,可以建立提案號與節點編號間的映射關系。也就是說,根據提案號,可以預先確定Q2的節點,從而按照上述思路為提案分配滿足系統容錯要求的Q2.需要注意的是,該映射關系為不同提案號分配不同的Q2節點,具有負載均衡的作用。
對于Q1的確定,根據上述分析,Q1應該包含Q2′中的至少一個節點。通過上一段的分析可知,滿足該要求的關鍵是:新提案的proposer能及時獲取到之前提案的提案號。實際上,新提案只需要獲取到完成第一階段并且開始第二階段的提案中提案號最高的提案,而不是所有之前提案的提案號。因為這些提案中包含了第一階段未成功執行和第二階段未成功執行的提案以及過時的提案。為方便獲取有效提案的提案號,可以為每個數據對象設立一個數據項BM,用來存放有效提案號。新提案可以直接獲取BM,根據提案號與節點編號的映射關系,獲取BM對應的Q2′,將其加入自己的Q1中。
上面分析了最小化Q1和Q2、并保證兩者相交的思路。下面我們分析在優化Quorum的基礎上,減少Leader與客戶端間延遲的思路。要減少Leader與客戶端間的延遲,需要分配與客戶端相近的節點做Leader,即預測hot-key所在區域,自適應轉移Leader.預測hot-key所在區域,可以通過統計各區域的客戶端操作當前數據對象的命令數量,當Leader處理的總命令數量超過允許處理的最大數OP時,將領導權轉移至發起操作命令最頻繁的區域中。
為方便描述,給出以下符號,如表1所示。

表1 符號表Table 1 Symbol table
2.2 最小化Quorum
本節的討論基于以下分區Quorum模型:一個分布式系統由N個節點構成,節點分布在Z個不同的區域中,假定各區域內的節點數量一致,為NZ,即
N=Z×NZ.
(1)
根據系統容錯性,要求Z≥2ZF+1;NZ≥2NF+1.其中ZF和NF是用戶自定義的容錯標準。
根據上節的分析,為滿足Quorum相交要求,proposer在第一階段開始之前,獲取BM使用過的Q2′,將這些節點加入本次提案的Q1中,保證相交。因此,我們先給出確定Q2的方案,在此基礎上,再介紹如何構成Q1.
2.2.1第二階段Quorum
為方便新提案獲取之前使用過的Q2′,提出建立提案號與Q2節點之間的映射關系。提案號B由數值部分Bi和發起該提案的全局節點編號I組成,其中Bi是不斷遞增的數值,I由區域號IZ和區域內的節點編號IN組成,即B=Bi.I,I=IZ.IN.
第二階段Quorum節點構成規則:
1) 確定區域,選擇ZF+1個區域。若ZF=0,則Q2由Leader所在區域的節點構成;若ZF≠0,則Q2由Leader及離Leader近的ZF+1個區域中的節點構成;
2) 確定區域內節點數,在以上區域中選擇NF+1個節點;
3) 選擇節點,為保證各區域內節點的負載均衡,Leader根據Bi,選擇以IN開始的NF+1個節點,其中
IN=[1+(Bi-1)(ZF+1)] .
(2)
例如,當系統模型為Z=8,NZ=5,ZF=0,NF=1時,每個提案的Q2由1個區域及該區域中的2個節點構成,即
|Q2|=(ZF+1)(NF+1)=1×2 .
(3)
根據提案號B=1.1.1可知Bi=1,I=1.1,分配區域號IZ=1開始的1個區域,由公式(2)計算出,在該區域中選擇節點編號IN=1開始的2個節點,即Q21.1.1={1.1,1.2}.
2.2.2第一階段Quorum
本節介紹Q1節點構成方法。為了保證系統中的每個數據對象在同一時刻最多只有一個Leader,Q1由多數區域中的多數節點構成,即
|Q1|=(Z/2+1)(NZ/2+1) .
(4)
發起第一階段提案的proposer節點為候選Leader,候選Leader在發送第一階段提案之前,先獲取BM,根據第二階段Quorum節點構成規則,獲取到該提案的Q2′.
第一階段Quorum節點構成規則:
1) 確定區域,Q1由Z/2+1個區域構成。當|Q2′|≥|Q1|時,將Q2′作為新提案的Q1;當Q2′的區域數ZF+1 2) 確定區域內節點數,每個區域由NZ/2+1個節點構成。當Q2′各區域內的節點數量NF+1 3) 選擇節點,為實現區域內節點的負載均衡,選擇以IN開始的NZ/2+1個節點,其中 IN=[1+(Bi-1)(NZ/2+1)] . (5) 例如,系統模型為Z=8,NZ=5,ZF=0,NF=1時,|Q2|=1×2,|Q1|=5×3.假設之前的提案號B=1.1.1,該提案使用的Q21.1.1={1.1,1.2}.當節點1.1完成提案后,區域5中的節點5.1發起第一階段提案,成為候選Leader,節點5.1提出的提案號B=2.5.1,即Bi=2,IZ=5,IN=1,如圖2所示,提案2.5.1的Q1由提案1.1.1的Q2和其他節點構成,首先獲取B=1.1.1的Q21.1.1,Q2區域中的節點數為2,小于Q1區域中的節點數3,需要再擴展1個節點。除Q21.1.1包含的1個區域外,提案2.5.1還需要選擇距離區域5近的其余4個區域:5、6、7、8,根據公式(5),在每個區域中選擇以IN=4開始的3個節點,故Q12.5.1={1.1,1.2,1.3,5.4,5.5,5.1,6.4,6.5,6.1,7.4,7.5,7.1,8.4,8.5,8.1}. 圖2 Q1的構成Fig.2 Composition of Q1 本節介紹在使用劃分數據對象領導權方法實現Multi-Leader的基礎上,將Leader自適應轉移至操作頻率較高的區域的機制。 Leader自適應轉移規則如下:在Leader擁有數據對象領導權的期間,統計各區域對該數據對象的操作次數,當總操作次數超過固定值OP后,自適應地調整Leader的位置,將領導權轉移至操作頻率最高的區域中,由該區域中的節點發起第一階段提案,申請成為Leader,獲取領導權。OP的大小由請求流量、系統基本運行情況及Leader故障頻率等參數共同決定,不同數據對象可設置不同的OP. 本節通過實驗驗證SQPaxos在Quorum性能和Leader性能兩方面的有效性,其中Quorum性能是指在不改變Leader分配等其他配置的情況下,測試算法使用不同的Quorum構成策略時所需的共識延遲;Leader性能是指在不改變Quorum等其他配置的情況下,測試算法使用不同Leader分配策略時所需的共識延遲。 實驗環境:本節模擬系統節點部署在加利福尼亞(CA)、俄勒岡州(OR)、弗吉尼亞(VI)、東京(TK)、愛爾蘭(IRE) 5個不同的區域中,每個區域配置3個節點。節點配置如下:64位Ubuntu 18.04操作系統,2個CPU,8G內存。 測試指標:測試在系統平穩運行的狀態下,算法對請求達成共識的平均響應延遲,包括算法整體、第一階段Q1、第二階段Q2,以及在不同的數據分布模式下使用Leader分配機制時的延遲表現。其中,響應延遲是指從客戶端發起請求開始,到服務器對該請求達成共識,并向客戶端返回結果結束,整個過程花費的時間一般以毫秒(ms)為單位。本節給出了算法在各區域的第95百分位數(95thpercentile)延遲,以表明平均延遲的有效性。 測試方法:采用YCSB Benchmark隨機選擇數據對象生成命令請求,生成的請求中,50%為讀操作請求,50%為寫操作請求,數據池中共有1 000個數據對象,對比各算法對請求達成共識的平均延遲測試算法性能。 度量標準:在保證數據一致的前提下,達成共識的速度越快,算法性能越好。通過檢查各節點的工作日志確認數據的一致性,在此基礎上,對比各算法達成共識的平均延遲,比較算法的優劣。 平均延遲是共識算法性能最直觀的表現,其大小受節點規模、節點間的距離、通信輪次等因素的影響。首先,當前階段需要通信的節點規模決定了該階段的延遲。例如,SQPaxos的Q1大小為3個區域,每個區域2個節點,則將各區域內節點與候選Leader間的延遲按遞增順序排序后,第3小的區域內第2小的延遲影響了SQPaxos第一階段的性能。因此,Quorum節點規模越小,延遲就越低。其次,節點間的距離以及客戶端與Leader間的距離越近,延遲就越低。最后,廣域網環境下,每一輪通信都會產生較大的延遲,通信次數越少,延遲就越低。例如,Multi-Paxos的第一階段需要一輪通信即可選出Leader,而DPaxos的第一階段使用第一輪通信中獲取Q2′后,再發起第二輪通信。因此,DPaxos的第一階段延遲高于Multi-Paxos. 對比算法:對于Quorum性能測試方面,分別對比SQPaxos、Multi-Paxos、FPaxos和DPaxos使用第一階段轉移Leader和使用第二階段確定提案內容時所需的延遲;同時,對比系統正常運行時,各算法的整體延遲表現;對于Leader性能測試方面,對比在多種數據分布模式下,使用Multi-Leader自適應轉移方案的SQPaxos、未使用Multi-Leader自適應轉移方案的SQPaxos、使用定時Leader轉移方案的WPaxos以及實現Leader-Less方案的EPaxos算法的延遲表現。 3.2.1整體性能 在Multi-Leader模式下,分別對比容錯模式為ZF=0,NF=1時,SQPaxos、FPaxos、DPaxos、Multi-Paxos的延遲性能,結果如圖3所示,其中柱狀圖表示平均延遲,誤差線表示將所有請求的共識延遲排序后,第95%位延遲的大小。在本實驗配置環境下,SQPaxos的第一階段Q1大小為3個區域,每個區域2個節點(3×2),比FPaxos(5×2)和DPaxos(4×2)小,第二階段Q2大小為1個區域中的2個節點(1×2),比Multi-Paxos(3×2)小,因此,SQPaxos的平均延遲均低于以上算法。實驗結果表明,SQPaxos的平均延遲比FPaxos、DPaxos、Multi-Paxos分別低47.1%、39.6%、53.9%. 圖3 整體性能Fig.3 Overall performance 3.2.2第一階段Quorum性能 實驗采用不固定Leader的方法,對比ZF=0,NF=1時,SQPaxos、FPaxos、DPaxos、Multi-Paxos轉移Leader所需的第一階段平均延遲,結果如圖4所示。SQPaxos和Multi-Paxos的Q1大小一樣,均為3個區域,每個區域2個節點(3×2),比DPaxos(4×2)和FPaxos(5×2)小,因此SQPaxos和Multi-Paxos的延遲低于以上兩種算法。 圖4 第一階段Quorum性能Fig.4 Performance of Q1 SQPaxos的延遲略低于Multi-Paxos,因其將請求發送給固定節點集,而不是廣播給所有節點,減少了通信量。綜上,SQPaxos的第一階段平均延遲比FPaxos、DPaxos、Multi-Paxos分別低47.6%、57.9%、6.0%. 3.2.3第二階段Quorum性能 在確定Leader后,Leader可以連續多次執行第二階段,對多個請求達成共識。本次實驗將Leader分別固定在不同區域,測試各算法使用不同Q2時所需要的共識延遲,結果如圖5所示。當容錯模型為ZF=0,NF=1時,SQPaxos、FPaxos、DPaxos的Q2均為1個區域中的2個節點(1×2),Multi-Paxos的Q2不受容錯模型影響,為3個區域,每個區域2個節點(3×2).SQPaxos的Q2比Multi-Paxos小,并且SQPaxos直接將請求發送給固定的目標Quorum,而不是廣播給所有節點,減少了通信量,因此SQPaxos的第二階段Q2性能優于其他算法。實驗結果表明,SQPaxos的第二階段平均延遲,比FPaxos、DPaxos、Multi-Paxos分別降低了3.9%、3.8%、93.8%. 圖5 第二階段Quorum性能Fig.5 Performance of Q2 由以上三組實驗可知,實現最小化兩階段Quorum能夠有效降低廣域網共識延遲。 本文提出自適應Leader分配機制,減少達成共識的延遲。每個Leader最多允許處理OP個請求,當請求數量超過OP后,自動將數據對象的領導權轉移至請求操作次數最多的區域中。 為了增強對比效果,算法的并行度為5,即Leader可同時處理5個數據對象的請求,并且設置了兩種不同的OP值:OP=1 000、OP=10 000.測試在數據對象均勻分布模式(uniform distribution)、客戶端請求操作的數據對象與本區域擁有的數據對象匹配度為70%(Maturity=70%)以及匹配度為90%(Maturity=90%)三種模式下,SQPaxos與WPaxos、EPaxos的性能對比。結果如圖6所示。 圖6(a)為uniform distribution模式下,各算法在5個區域中的平均延遲性能。SQPaxos(OP=1 000)比未增加Leader轉移模式的SQPaxos、WPaxos、EPaxos的平均延遲分別降低了2.4%、73.7%、80.3%;SQPaxos(OP=10 000)比未增加Leader轉移模式的SQPaxos、WPaxos、EPaxos的平均延遲分別降低了2.9%、73.1%、80.1%. 圖6(b)為Maturity=70%模式下,各算法在5個區域中的平均延遲性能。其中SQPaxos(OP=1 000)比未增加Leader轉移模式的SQPaxos、WPaxos、EPaxos的平均延遲分別降低了8.8%、62.6%、90.5%;SQPaxos(OP=10 000)比未增加Leader轉移模式的SQPaxos、WPaxos、EPaxos的平均延遲分別降低了4.6%、60.9%、90.1%. 圖6(c)為Maturity=90%模式下,各算法在5個區域中的平均延遲性能。其中SQPaxos(OP=1 000)比未增加Leader轉移模式的SQPaxos、WPaxos、EPaxos的平均延遲分別降低了12.9%、56.2%、92.9%;SQPaxos(OP=10 000)比未增加Leader轉移模式的SQPaxos、WPaxos、EPaxos的平均延遲分別降低了7.4%、53.8%、92.5%. 圖6 (a)均勻分配模式;(b)數據對象匹配度為70%;(c)數據對象的匹配度為90%Fig.6 (a) Uniform distribution; (b) Maturity=70%; (c) Maturity=90% 分析實驗結果可知,使用自適應Multi-Leader轉移機制的算法能夠有效降低共識延遲。當客戶端操作的數據對象與本區域擁有的數據對象匹配度越高時,達成共識所需的延遲越低。 本文針對現有廣域網分布式共識算法存在的不足之處,提出了SQPaxos算法。SQPaxos的主要目標是減少廣域網共識延遲,分別從減少Quorum大小和Leader分配兩方面實現此目標。在Quorum大小方面,在滿足算法安全性要求的基礎上,實現了最小的第一階段Quorum和第二階段Quorum;在分配Leader方面,自適應地將Leader轉移至請求操作頻率較高的區域,使客戶端請求盡量由本區域的服務器節點處理,減少跨區域的通信。實驗表明,與現有算法相比,SQPaxos具有更低的延遲性能。
2.3 Multi-Leader自適應轉移方案
3 實驗分析
3.1 實驗設計
3.2 Quorum性能



3.3 Leader性能

4 總結與展望
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20今日農業(2021年9期)2021-11-26 07:41:24發明與創新·小學生(2021年3期)2021-03-25 11:48:49軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30北京測繪(2020年12期)2020-12-29 01:33:58裝備制造技術(2019年12期)2019-12-25 03:06:46中國洗滌用品工業(2019年4期)2019-05-11 09:27:34家庭影院技術(2017年9期)2017-09-26 03:41:45中國科技博覽(2016年2期)2016-04-25 20:32:39小學生導刊(2016年34期)2016-04-11 00:49:44
