基于一維卷積神經網絡的滾動軸承故障程度診斷
2021-07-21 08:31:58薛妍沈寧竇東陽
軸承 2021年4期
薛妍,沈寧,竇東陽
(1.中國礦業大學 化工學院,江蘇 徐州 221116;2.寧夏煤業洗選中心,銀川 750409)
滾動軸承是旋轉機械設備的關鍵部件,其可靠性直接影響設備的正常運行和安全生產。滾動軸承從正常運轉到完全失效要經歷一系列不同的性能退化過程,因此,軸承故障退化程度的評估是開展視情維修的基礎和重點[1]。
時域、頻域及時頻域分析是基于振動信號的傳統故障診斷方法[2]。為更好地表征振動信號的局部特征,通常采用短時傅里葉變換[3]、小波變換[4]、經驗模態分解[5]、局部均值分解[6]等時頻處理方法提取軸承振動信號的故障特征,再通過豐富的經驗知識分類故障特征,這些方法耗時費力且識別率較低。智能化的故障診斷方法則利用支持向量機[7]、k-鄰近算法[8]、人工神經網絡[9]等機器學習方法自動分類特征,降低依賴專家經驗出錯的概率,但準確率取決于人工提取的特征能否準確表達故障信息,仍存在較大的局限性。
軸承的失效是循序漸進的,文獻[10-11]通過研究軸承的性能退化過程,證明RMS指標、熵特征可以用來表征軸承的性能退化;文獻[12]運用支持向量機(SVM)對滾動軸承數據進行訓練分類,文獻[13]采用深度神經網絡對軸承壽命數據進行識別,都實現了對軸承的性能退化趨勢的監測。然而,相比于機器學習模型淺層的網絡結構,深度學習模型具有更深的網絡層,擁有較強的自適應特征學習和分類能力,不僅降低了對信號處理與診斷經驗的依賴,更加適應工業大數據背景下海量監測數據的分析需求[14-15]。
上述文獻處理的數據都是二維的,針對振動信號的一維特性,本文提出了基于一維卷積神經網絡的滾動軸承性能退化評估方法,嘗試直接將軸承振動信號輸入一維卷積神經網絡,提取振動信號相鄰時間點的特征,避免人工信號處理和特征提取帶來的誤差。
1 一維卷積神經網絡
一維卷積神經網絡(1DCNN)是一種前向傳導的人工神經網絡,通過反向傳播算法更新網絡參數[16],其結構如圖1所示。

圖1 1DCNN網絡模型示意圖Fig.1 Model of 1DCNN
一維卷積神經網絡用于軸承故障診斷包含了特征提取、特征分類和故障確定3個步驟,包括輸入層、卷積層、池化層、全連接層和分類層。輸入和卷積核依托卷積運算稀疏連接、權值共享的特性進行卷積運算得到特征圖譜。滾動軸承振動信號的原始數據作為輸入,每層卷積層均使用了多個不同尺度的卷積核。使用非限制性單元(Rectified Linear Unit,ReLU)作為激活函數,將卷積層的輸出作為激活函數的輸入獲得輸入信號的非線性表達,使學習到的特征更容易區分。
直接將卷積后的特征圖輸入到全連接層無疑會大大增加網絡模型的參數,在每層卷積層后采用2×1最大池化層,通過池化操作降低卷積層輸出的特征向量,減少參數;同時,采用均值池化保證信息的完整性,避免過擬合。使用softmax激活全連接層,并在全連接層之前添加防止過擬合的dropout層,系數為0.3。
2 故障診斷步驟
基于一維卷積神經網絡的滾動軸承故障診斷算法流程如圖2所示,具體步驟為:采集軸承的振動信號構建試驗數據集,劃分訓練集和測試集;將訓練集的信號樣本提前做好對應標簽(每一種故障信號對應一個故障標簽),輸入到1DCNN進行模型訓練;輸入測試樣本,同時引進機器學習經典算法-混淆矩陣,得到直觀、可視化的多標簽分類準確率。
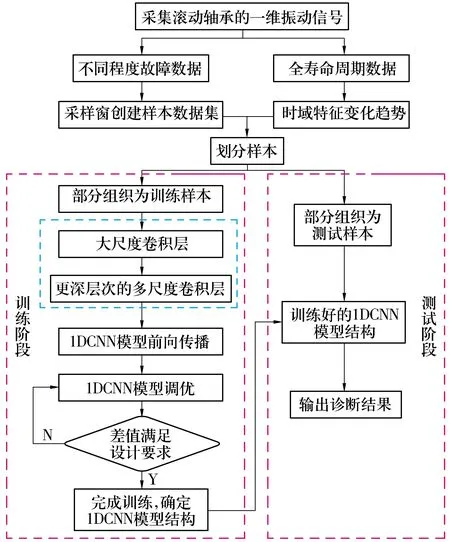
圖2 1DCNN故障診斷流程圖Fig.2 Fault diagnosis flowchart of 1DCNN
針對軸承振動信號非線性、非平穩的特點,同時為了保障原始振動信號的完整性以便提取時間序列信息,進行了一些針對性改進:
1)對于一維時間振動信號而言,小卷積核覆蓋范圍太小,很容易受到原始振動信號中高頻噪聲的干擾,無法準確提取有用信息,因此在模型的第1層就使用16個8×1的卷積核,增大感受野,學習時間信號的泛化特征,同時保證模型的運算速度。
2)在第1層卷積層之后引入3層小尺度卷積層,分別為64個4×1卷積,256個4×1卷積,256個2×1卷積,從而有效控制網絡模型的參數,同時利用不同尺寸的小卷積核精確提取小范圍的故障信息。
Keras[17]是一個基于Theano和TensorFlow等框架提供的底層運算而實現的高層框架,相比其他深度學習框架,采用Keras能以最短時間完成模型的搭建和訓練。因此,利用python語言基于Keras框架實現模型建立、訓練和診斷分析全過程。
3 不同故障程度滾動軸承故障診斷
3.1 試驗數據
為驗證本文的診斷方法,采用凱斯西儲大學(CWRU)滾動軸承數據中心提供的試驗數據[18]。對驅動端的6205軸承人為添加電火花侵蝕,產生不同位置及不同磨損程度的故障。使用12 kHz的采樣頻率進行樣本采集,軸承健康狀況分為鋼球、內圈、外圈損傷三大類,每種故障依據損傷程度又分為0.178,0.356和0.533 mm這3種故障尺寸,總計10種軸承故障狀態(表1)。在本文的試驗中,使用數據集增強技術獲取10 000個樣本,劃分為訓練集、驗證集和測試集,各占7 000,2 000和1 000個樣本,每個樣本長度為2 048。
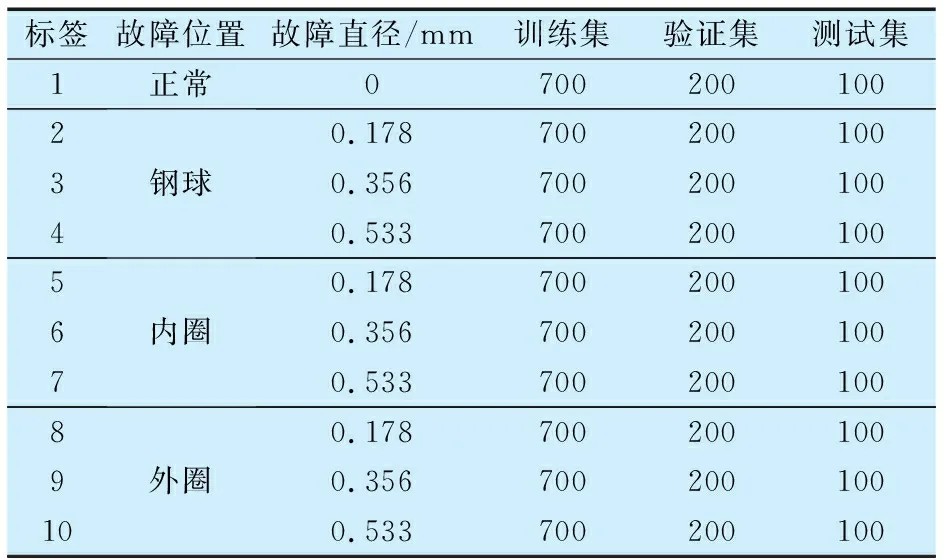
表1 軸承試驗數據集Tab.1 Experimental data set of bearing
3.2 數據增強
為避免數據集過小、需要訓練的網絡參數過多而導致模型過擬合的問題,采用數據增強技術對數據集的樣本進行擴充。例如,對于一段有S個點的振動信號,用尺寸為M的采樣窗以L個單位長度的步幅進行滑動取樣,就能得到N個樣本數據,其表達式為
(1)
每種軸承狀態的數據長度S約為120 000,若單一訓練樣本長度M為2 048,則平均采樣訓練樣本共有58個;采用數據增強技術,選定滑動步長L為28,可得訓練樣本N約為4 213,從中隨機選取1 000個作為這種故障狀態的樣本進行劃分。該方法大大增加了數據集的樣本數量,保證了樣本數據的連續性,有利于模型的訓練和參數的更新,從而提高模型的診斷準確率。
3.3 結果分析
本次試驗基于python-Keras搭建網絡模型,1DCNN的一次訓練過程如圖3a所示。經過50次迭代后,使用訓練好的模型對隨機劃分的1 000個測試集樣本進行故障分類,結果達到了98.2%的準確率,損失函數僅為0.74×10-4,模型診斷精度非常高且收斂速度快。
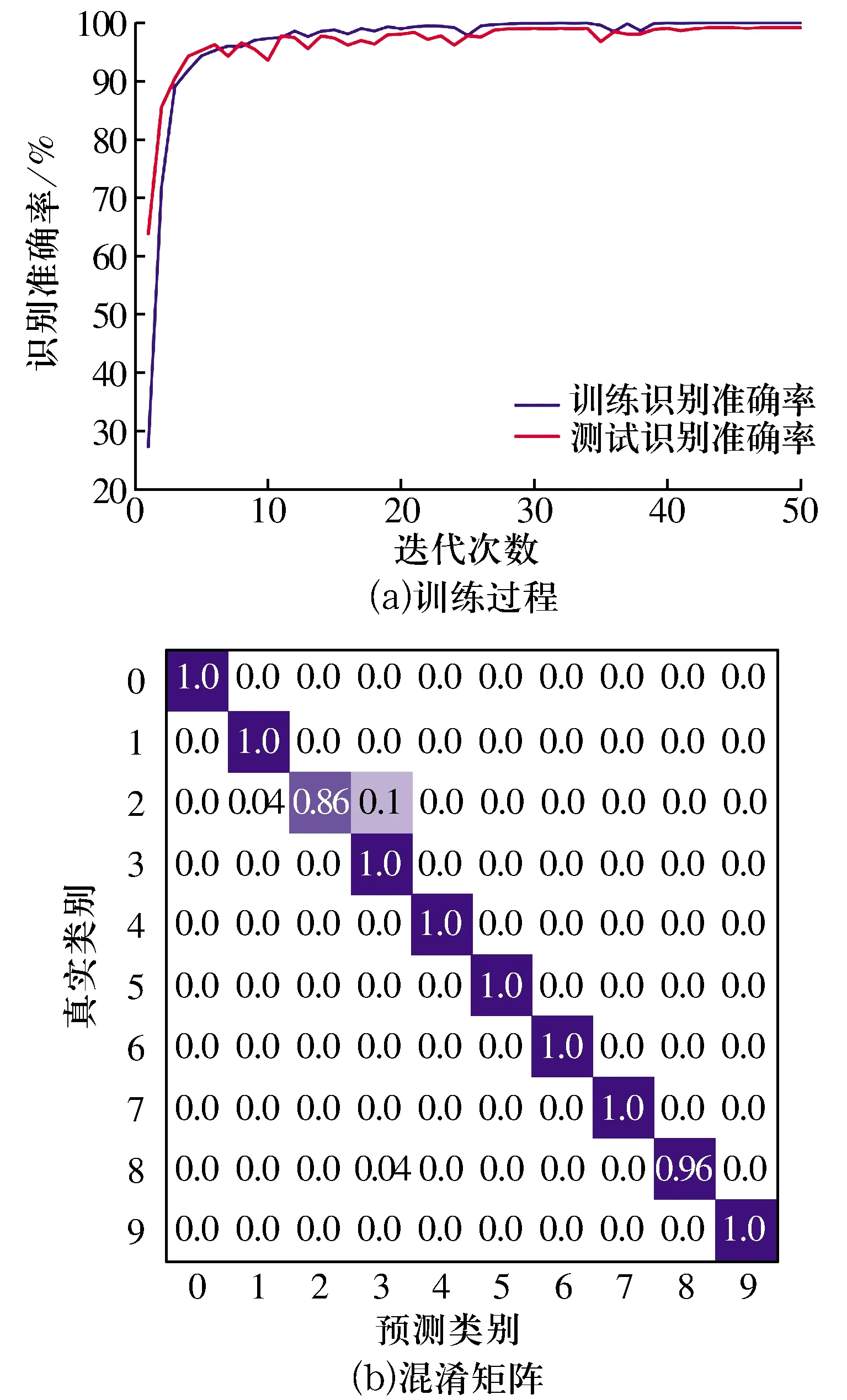
圖3 1DCNN的訓練過程和混淆矩陣Fig.3 Training process and confusion matrix of 1DCNN
由故障分類混淆矩陣(圖3b)可以看出,4%的2類故障被錯誤識別為1類故障,10%的2類故障被錯誤識別為3類故障,4%的8類故障被錯誤識別為3類故障,另外8種故障類型的識別率則達到了100%,說明該模型能夠準確監測軸承的健康狀態。
與其他故障分類方法的對比結果見表2,由表可知:基于1DCNN的診斷模型能夠有效地提取故障特征并進行軸承的故障識別,具有較高的準確度,比SVM及深度神經網絡(DNN)算法的診斷效果更好。

表2 故障識別算法對比Tab.2 Comparison of fault recognition algorithms
4 全壽命周期滾動軸承故障診斷
4.1 試驗數據
實際工況中,軸承性能退化是一個循序漸進的過程,軸承所處的損傷階段也會由輕微到嚴重演變,要想做到軸承的視情維修,還需準確地識別軸承性能退化階段。因此,采用美國辛辛那提大學智能維護系統中心軸承疲勞壽命試驗臺數據[21]進行分析。試驗臺主軸上裝有4套型號為Rexnord ZA-2115的雙列圓柱滾子軸承,采樣頻率為20 kHz,間隔10 min采集一次數據,每次采集時間為1 s。每次試驗有4套軸承,當某一套軸承損壞時,停止試驗并保留試驗數據。整個數據集描述的數據內容為軸承從健康運行到失效的整個試驗中振動信號的變化過程。
4.2 數據處理
對外圈全壽命周期數據進行時域指標分析,軸承性能退化過程中的信號波動情況如圖4所示,由圖可知:峭度指標對沖擊信號比較敏感,隨著軸承性能退化,其值從初始的4以下逐漸升高到17左右,但在軸承損傷嚴重的后期,峭度曲線反而出現了短暫的下降趨勢;均值指標呈現總體平穩的趨勢,只在軸承外圈失效時出現波動;峰峰值前期平緩,后期沖擊雜亂;無故障時標準差在0.1附近且曲線較平緩,當軸承最終損壞時標準差增加至0.7左右,表明標準差隨著軸承損傷程度加深而逐漸升高,550點左右時標準差曲線出現上升趨勢,暗示著故障的發生,可以較好地反映軸承性能退化過程;另外,均方根、方根的變化趨勢與標準差相似,可以較好對應軸承性能退化過程;裕度指標、波形指標、脈沖指標和偏度指標則不能較好地反映軸承性能退化過程。
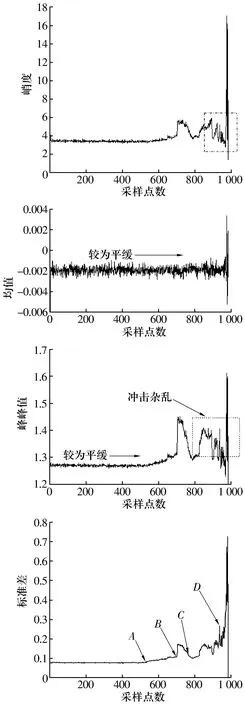
圖4 軸承外圈全壽命周期數據的部分時域特征Fig.4 Some time-domain characteristics of bearing outer ring life cycle data
綜上分析,選取標準差變化趨勢作為分類依據,根據圖4標準差曲線中的點A,B,C,D將軸承性能退化過程分為5個階段:正常、外圈輕微退化、外圈中度退化、外圈嚴重退化、外圈失效。根據軸承退化過程標準差的變化趨勢,掌握軸承失效的發展規律,為開展視情、適時維修做好基礎。
軸承性能退化過程標準差曲線的局部特征如圖5所示,由圖可知:
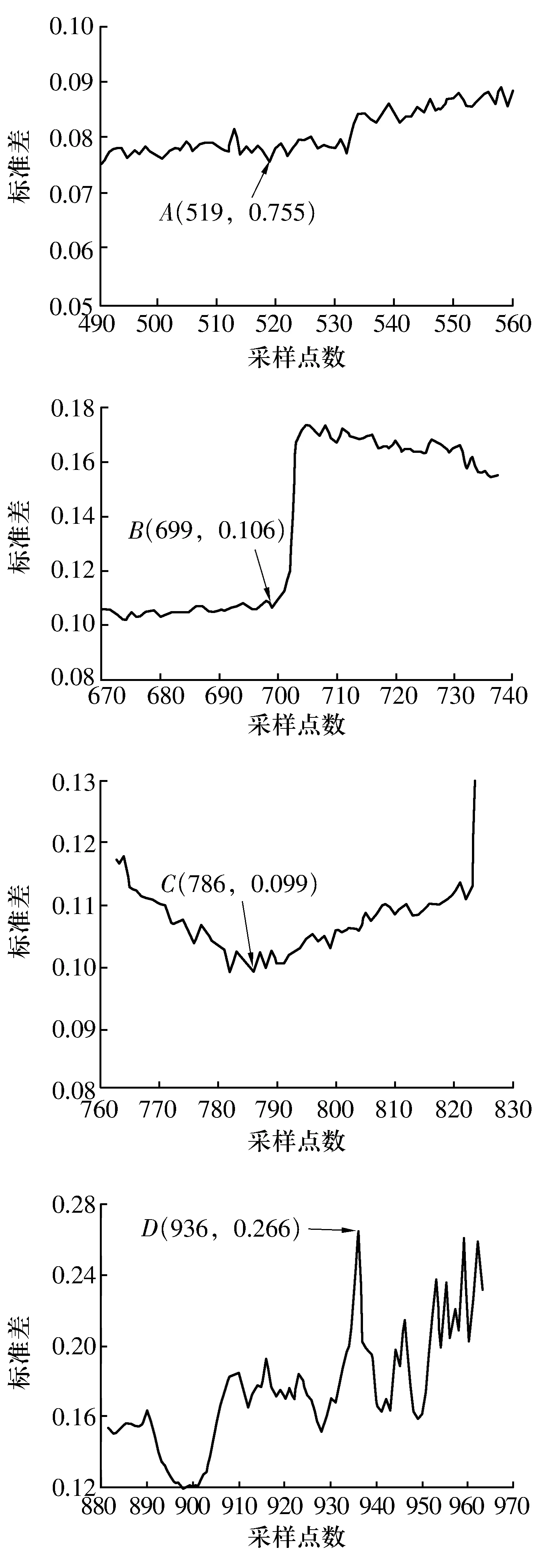
圖5 軸承性能退化過程標準差曲線的局部特征Fig.5 Local characteristics of standard deviation curve of bearing performance degradation process
1)A點之前,標準差基本不變,時域和包絡波動較小,無明顯故障特征幅值,軸承狀態良好,在第520個樣本(圖6b)周圍出現波動,包絡幅值明顯增加,且出現230.5 Hz(幅值為35.2 m/s2)的外圈故障特征頻率,而在第519個樣本(圖6a)處的包絡譜圖上則沒有出現故障頻率,表明第520個樣本時外圈損傷,可以初步判定A點故障已經發生。
2)A—B段,標準差一直在緩慢上升,直至B點(第699個樣本點)突增,包絡譜圖(圖6c)中出現明顯的故障頻率和倍頻。
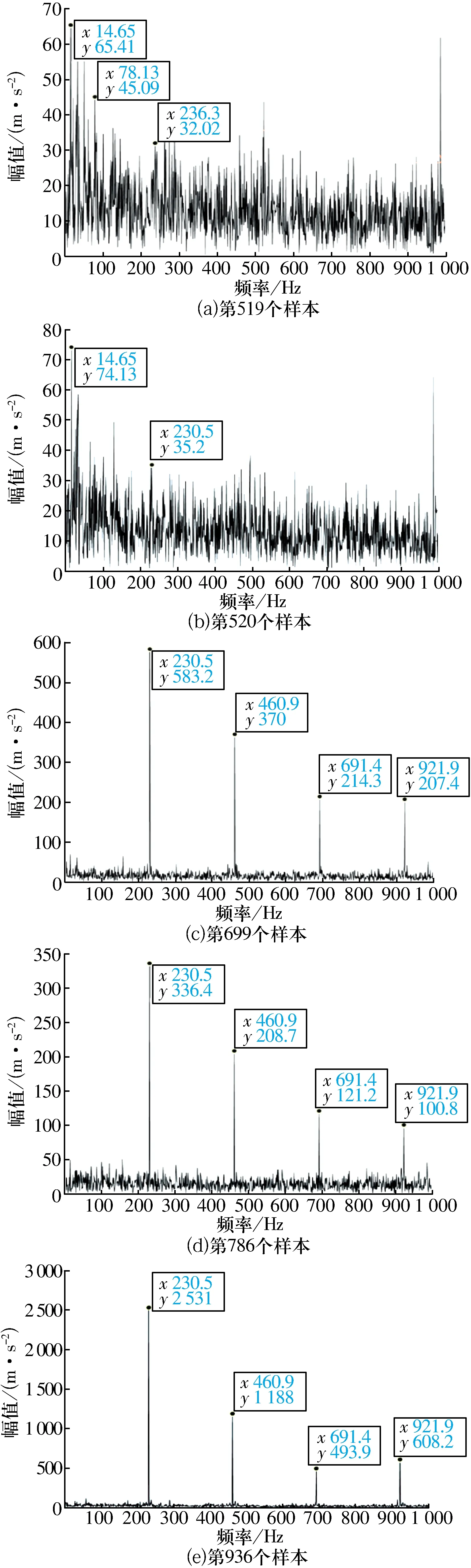
圖6 軸承性能退化過程不同樣本點的包絡譜Fig.6 Envelope spectrum of different sample points during bearing performance degradation process
3)B—C段,標準差逐漸下降,直至C點(第786個樣本)之后才緩慢上升,此時包絡譜圖(圖6d)中幾乎只出現了外圈故障頻率及其倍頻,且幅值(336.4 m/s2)有明顯上升,但仍低于A—B段,這是由于沖擊力作用使故障點逐漸被磨合,從而導致幅值有所降低。
4)D點(第936個樣本)出現了更明顯的沖擊,包絡譜圖(圖6e)中也幾乎只出現外圈故障頻率及其倍頻,且幅值(2 531 m/s2)大幅度上升。
綜上,將A點之前劃分為正常階段,A—B段為外圈輕微退化階段,B—C段為外圈中度退化階段,C—D段為外圈嚴重退化階段,D點之后外圈完全失效。至此試驗數據準備完畢,將樣本分為正常、外圈輕微退化、外圈中度退化、外圈嚴重退化和外圈完全失效,分別對應標簽0,1,2,3,4。與上一組試驗類似,也是包含原始振動信號和劃分好的故障程度,但此組故障程度包含漸變過程,更符合實際。
4.3 試驗結果分析
基于python-Keras搭建網絡模型,1DCNN的訓練過程如圖7a所示,由圖可知:約經過15次迭代后陷入局部極值,表明該模型的分類效果較差;
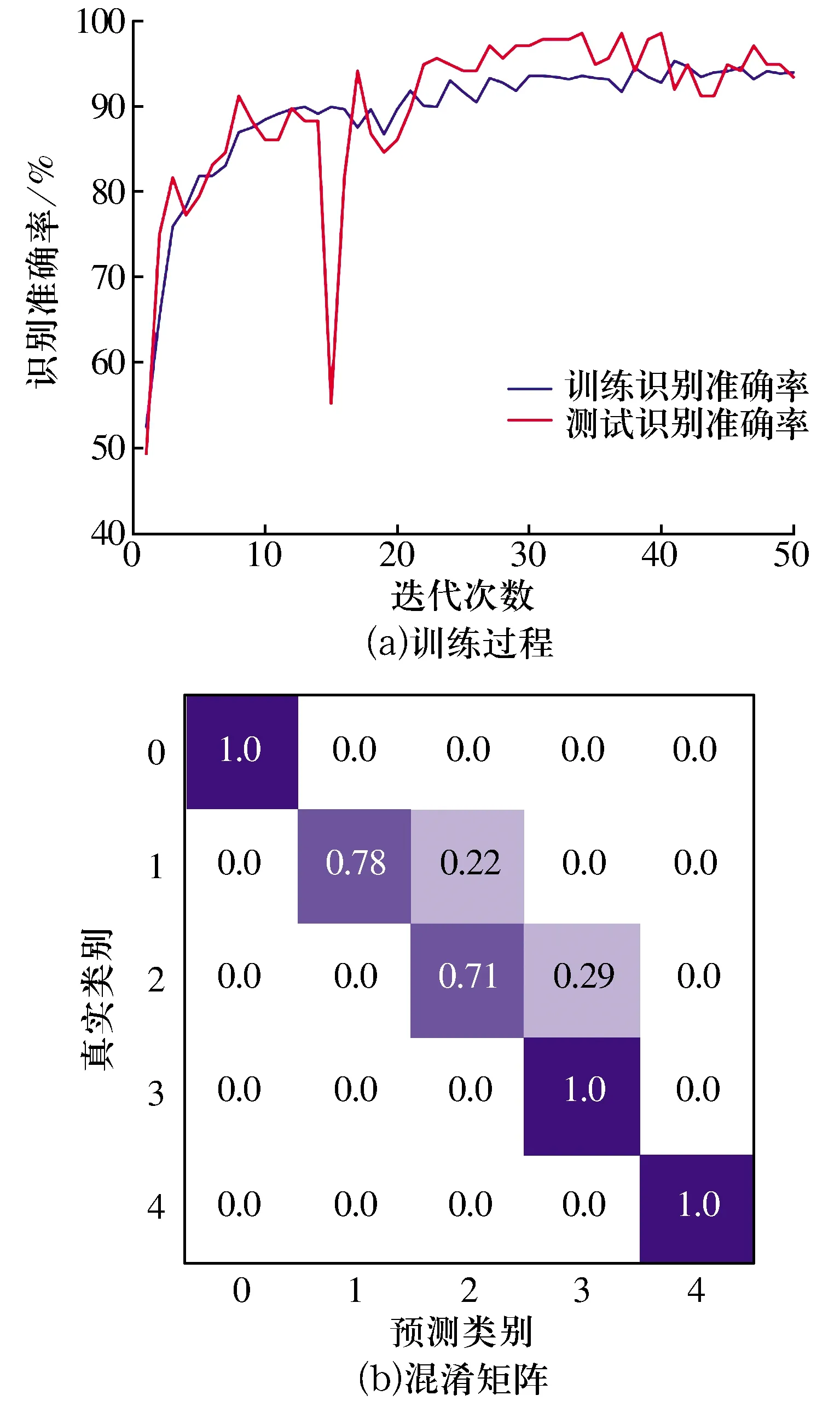
圖7 1DCNN對滾動軸承外圈故障程度的識別結果Fig.7 1DCNN identification result of outer ring fault degree of rolling bearing
但隨著迭代次數的增加,該模型可以快速恢復可靠、良好的分類性能,因此將網絡的迭代次數設置為50。使用訓練好的模型對隨機劃分的測試集樣本進行故障分類,平均準確率達到了93%,模型的診斷精度非常高。另外,模型訓練速度和收斂速度都很快。
軸承外圈故障程度分類的混淆矩陣如圖7b所示,由圖可知:22%的1類(外圈早期故障)被模型錯誤識別為2類(外圈中度退化),29%的2類(中度退化)被模型錯誤識別為3類(外圈嚴重退化),模型對其他故障程度的識別率都達到了100%。由于軸承故障是緩慢形成的,劃分的故障程度會有一定的重疊部分,因此模型識別存在一定的誤差,但已經能夠很好地對軸承的運行狀態進行監測。
5 結束語
針對滾動軸承的故障退化程度問題提出了基于一維卷積神經網絡的“端到端”診斷方法,分別進行了不同故障程度和全壽命周期滾動軸承數據的試驗驗證,取得了很高的正確率。
1DCNN方法能夠直接處理原始振動信號,提取原始信號相鄰時間點之間的信息,省去了大量耗時費力的人工特征提取過程,并能減少網絡參數,加快網絡模型的訓練過程,拓寬并加深神經網絡的結構;1DCNN可以學習到原始振動信號更加穩定的特征信息并保留原始振動信號的完整性,根據時域特征變化趨勢建立軸承狀態的不同階段。通過深度學習對軸承振動信號原始數據進行有監督學習,能夠實現對軸承的全壽命分析和狀態預測。
猜你喜歡
科學大眾(2023年17期)2023-10-26 07:39:14
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
天天愛科學(2020年6期)2020-09-10 07:22:44
汽車維修與保養(2019年7期)2020-01-06 03:30:42
電子制作(2018年11期)2018-08-04 03:25:42
數學物理學報(2017年6期)2018-01-22 02:26:40
汽車維護與修理(2016年10期)2016-07-10 08:17:41
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
汽車維修與保養(2015年6期)2015-04-17 03:31:50
