基于牽引控制的深度強化學習路由策略生成
2021-07-23 02:11:16孫鵬浩蘭巨龍胡宇翔
計算機研究與發(fā)展 2021年7期
關鍵詞:策略
孫鵬浩 蘭巨龍 申 涓 胡宇翔
(解放軍戰(zhàn)略支援部隊信息工程大學 鄭州 450002)
隨著當前互聯網體系與經濟社會的深度融合,為滿足社會泛在通信、工業(yè)生產、生活娛樂等方面不斷增長的需求,現代信息網絡的規(guī)模不斷增長,業(yè)務種類日趨豐富.在此背景下,信息網絡上的流量在信息量規(guī)模、流量復雜度和時空分布動態(tài)性上也經歷了高速增長.為此,網絡運營商不斷更新網絡設備來適應高速增長的流量需求.然而,單純的硬件更新換代面臨著成本高、周期長、靈活性差等問題.相反,作為網絡性能的重要支撐部分,網絡路由協(xié)議等網絡中的“軟構件”更新緩慢[1].目前這種軟硬件迭代速率失衡的現狀正引起網絡運營商的關注,網絡“軟構件”升級的研究也在業(yè)界廣泛開展[2].
網絡路由的優(yōu)化問題是NP難問題[3].傳統(tǒng)的路由設計方案通常基于網絡流量特征的人工建模,并在此基礎上有針對性地設計路由策略[4].然而,當前網絡流量具有復雜的時空分布波動性,人工建模困難度極大提升.例如,許多基于模型的網絡路由優(yōu)化研究[5-7]都是針對特定網絡場景或者特定假設的流量模型進行求解,其方法由于假設本身帶來的誤差以及模型與真實網絡的區(qū)別造成所提出的方案難以在真實網絡場景中取得較好的路由效果.隨著軟件定義網絡(software-defined networking, SDN)等新型網絡架構的發(fā)展[8-9]和近年來人工智能(artificial intelligence, AI)技術的不斷成熟,基于AI的自動化網絡策略生成正受到業(yè)界的廣泛關注[10-12].機器學習(machine learning, ML)等AI技術通常可以自動提取網絡流量特征,并且不依賴人類專家經驗生成相應網絡策略,因此在解決網絡路由NP難問題上相對于傳統(tǒng)方案開辟了新的道路.目前,基于機器學習的網絡路由技術根據其學習算法主要可以分為3類:基于監(jiān)督學習的路由策略、基于無監(jiān)督學習的路由策略和基于強化學習的路由策略.基于監(jiān)督學習的路由策略目前主要利用深度神經網絡進行網絡流量特征提取,然后根據提取的流量特征人工設計相應路由策略[13-14].無監(jiān)督學習主要通過對網絡流量進行降維分析[15]和聚類[16]來對流量場景進行分類,進而設計相應的路由策略.然而,基于監(jiān)督和無監(jiān)督學習的方案在實際中難以施行:監(jiān)督學習需要大量的有標簽數據訓練神經網絡,目前網絡中難以獲得相應的高質量數據訓練集;無監(jiān)督學習無法實現復雜流量特征的分類,因此方案的設計精度有限.目前,基于深度強化學習(deep reinforcement learning, DRL)的路由方案克服了上述缺點.
DRL算法直接將網絡中相應的流量視圖數據作為算法輸入,在不需要人工提供數據標記的情況下,能夠自主判斷自身產生策略的質量,并且實現算法的自我更新、自主進化,因此近年來成為了研究熱點[17-19].例如,Xu等人[4]提出的DRL-TE方案通過DRL算法控制每條數據流的路由路徑,在仿真環(huán)境中相比其他流量工程算法取得了優(yōu)勢;Sun等人[19]提出了TIDE,通過調整鏈路權重來控制全局路由,在實驗環(huán)境下也證明了算法的優(yōu)勢.然而,當前基于DRL算法的智能流量工程/路由方案普遍存在可擴展性問題:DRL-TE針對每條數據流進行控制,實驗僅在20條流的網絡環(huán)境下取得了效果,無法實現實際網絡數據流數量規(guī)模的控制;TIDE針對每條鏈路進行權重調整,當網絡規(guī)模增大時,鏈路數量增多,DRL算法也難以實現精確控制.
總體來說,目前基于DRL算法實現的網絡智能路由方案主要面臨2個問題:
1) 可擴展性差.目前基于DRL算法實現的智能路由方案通常需要對于網絡中目標元素(鏈路或者數據流)的所有單元進行控制,隨著網絡規(guī)模的擴大,這種控制方式將導致DRL輸出動作空間過大,因此算法難以收斂.其根本原因在于,特定環(huán)境下的DRL算法的輸出動作空間有限,太大的輸出動作將會引發(fā)神經網絡中的典型問題——維度災難問題[20].
2) 魯棒性低.目前大多數基于DRL算法的智能路由方案中,其神經網絡由于與訓練網絡拓撲過擬合而不能適應網絡節(jié)點失效等帶來的拓撲變化,因此所訓練得到的DRL算法魯棒性較低.
針對DRL算法應用于網絡路由策略中普遍存在的可擴展性差的問題,本文提出了一種基于層級化控制的深度強化學習路由策略生成技術Hierar-DRL.Hierar-DRL通過分析網絡拓撲特征,根據網絡鏈路間拓撲關系結合牽引控制理論選取部分鏈路作為代表鏈路,通過DRL算法對代表鏈路生成控制信號;再結合網絡路由算法將施加到代表鏈路的控制信號擴散到全網路由上,完成對全網路由的智能化、動態(tài)化調整.本文的主要貢獻有3個方面:
1) 指出了目前DRL算法應用于網絡路由策略生成中普遍存在的可擴展性問題,并提出了基于牽引控制理論的網絡鏈路選擇算法解決該可擴展性問題;
2) 提出了適用于可擴展化智能路由策略的DRL算法框架,并且針對實際網絡應用場景適配了該算法框架中使用的深度神經網絡結構;
3) 基于OMNet++仿真器實現了基于SDN的網絡智能路由實驗環(huán)境,并且基于該環(huán)境完成了所提方案Hierar-DRL的性能測試.
1 問題分析
1.1 當前基于DRL實現的路由策略存在的問題
隨著DRL技術的蓬勃發(fā)展,近年來使用DRL技術產生路由策略開始受到廣泛關注.目前,使用DRL算法產生路由策略的方案主要可以分為3類:基于下一跳控制的DRL路由方案[21]、基于逐個數據流路徑調整的DRL路由方案[4]和基于全網鏈路權重調整的路由方案[19].其中,Yao等人[21]提出的NetworkAI方案中,在單一路由節(jié)點運行DRL算法,根據本地流量視圖動態(tài)調整數據流下一跳的位置.由于該方案只針對單一路由節(jié)點進行路由優(yōu)化,因此無法實現全網范圍的路由調整.Valadarsky等人[22]提出了基于DRL的流量預測模型,并根據預測的流量特征進行路由策略調整,但真實網絡流量特征通常不確定性強、難以預測,因此限制了該方案的實用性.DRL-TE[4]等逐條數據流調整的路由方案將網絡流量視圖作為DRL算法的輸入數據,使用DRL算法的輸出為網絡中的每條數據流分配傳輸路徑.以DRL-TE為例,該方案為每條端到端數據流預先計算3條備選路徑,以DRL算法的輸出為依據確定數據流在備選路徑上的實際流向.DRL-TE測試了該方案在20條數據流下的算法性能,其中DRL的輸出神經元數量需要20×3=60個神經元.然而在實際包含N個網絡節(jié)點的網絡中,最多可能出現N×(N-1)個不同的端到端數據流、需要3×N×(N-1)個輸出層神經元,極易引起神經網絡的維度災難問題.TIDE[19]使用加權最短路徑算法為網絡中的數據流選擇路由,通過DRL算法對網絡鏈路進行權重調整從而調整全網路由.然而,隨著網絡規(guī)模增大,網絡中的鏈路數量隨之增長,使用DRL算法輸出層神經元控制每條鏈路的權重也將引起維度災難問題.Xu等人[23]為降低輸出動作維度,將鏈路權重進行了離散化處理,從而限定了輸出動作空間,并且提出了使用多智能體強化學習[24]的方法提升網絡的負載均衡特性.但隨著網絡規(guī)模的增大,離散化的鏈路權重很可能難以得到較優(yōu)的路由結果,多智能體的工作方式也為網絡的信息交互增加了負擔.
總體來說,當前的全網范圍使用DRL算法控制路由的方案都存在可擴展性問題,即隨著網絡規(guī)模的增大,DRL算法面臨維度災難問題從而難以實現神經網絡的收斂,造成方案性能下降甚至無法使用.而該問題產生的原因在于當前方案都采用了全局控制的思想,即試圖采用DRL算法針對需要調整的元素(數據流路徑或者鏈路權重)進行全部調整.
1.2 牽引控制理論的啟發(fā)及面臨的問題
網絡中的路由調整問題是復雜網絡控制理論在信息通信網絡領域的具體應用場景之一,其最終目的是控制網絡中所有數據流的流向,從而達到平均時延最短、網絡負載均衡等設計目標.近年來,復雜網絡控制理論中的牽引控制理論[25-26]取得了一定的研究進展.牽引控制理論指出,對于大規(guī)模網絡的控制,只需通過對部分節(jié)點施加控制信號(稱為牽引節(jié)點),通過節(jié)點間的連接關系實現控制信號的擴散,最終即可實現全網協(xié)同,從而達到控制目標.其中,牽引控制理論將復雜網絡建模為線性耦合常微分方程(linearly coupled ordinary differential equations, LCODES):

(1)

1) 一個網絡系統(tǒng)中最少需要多少牽引節(jié)點才能達到理想的控制效果;
2) 牽引節(jié)點在網絡中的位置怎樣選取;
3) 給牽引節(jié)點施加何種控制信號能夠達到控制效果.對于問題1、問題2,Liu等人[27]的研究取得了初步進展.Liu等人[27]指出,信息通信網絡等無標度網絡中,牽引節(jié)點的數量計算為
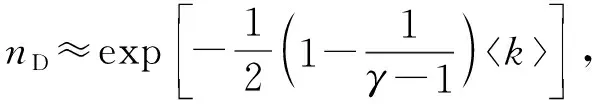
(2)
其中,nD表示牽引節(jié)點的數量,k表示網絡的平均連接度,γin和γout分別為入連接度和出連接度,γin=γout=γ表示無標度參數.Liu等人[27]在研究結果中指出,在一個全連接網絡中,牽引節(jié)點的選取通常要避免具有高連接度的節(jié)點.在Hierar-DRL中,我們將以牽引控制理論研究結論為依據,選取網絡中的控制元素.然而,對于問題3,目前牽引控制理論并沒有得出明確結論.本文中,我們引入DRL,通過DRL智能算法的自主策略探索能力,使其自主優(yōu)化控制信號,實現網絡自動化路由策略生成.
2 系統(tǒng)設計
Hierar-DRL通過調整鏈路權重實現全網路由的調整.其中,為減少維度災難問題、提高路由算法的可擴展性,Hierar-DRL采用了牽引控制理論的思想,選擇網絡中特定鏈路進行調整.Hierar-DRL基于SDN網絡架構建立,通過SDN控制器收集數據層相關信息,并使用植入于控制層的相關鏈路選擇算法和DRL算法實現可擴展的智能路由策略生成.
Hierar-DRL的主要架構如圖1所示.其工作過程主要分為2個環(huán)節(jié):拓撲鏈路選擇和在線路由策略部署.其中,拓撲鏈路選擇階段,通過控制器收集數據層拓撲信息建立全網視圖,在此基礎上運行鏈路選擇算法選擇相應鏈路作為牽引鏈路(詳見2.1節(jié)).在線路由策略部署階段,由控制器收集牽引鏈路上的流量視圖信息,DRL算法基于此信息通過神經網絡計算輸出相應地牽引鏈路權重調整方案,控制器以此為依據計算全網路由、將相應路由策略更新到數據層(詳見2.2節(jié)).

Fig. 1 Illustration of Hierar-DRL圖1 Hierar-DRL示意圖
2.1 牽引鏈路選擇算法
本節(jié)主要論述牽引節(jié)點選擇算法.由于牽引控制理論目前尚未對復雜網絡的具體牽引控制元素選擇方法做出具體指導,本節(jié)中,我們設計相應的啟發(fā)式算法來選擇牽引鏈路.算法設計思路為:在圖G=(V,E)中以連接度最小的節(jié)點為起點,逐層向外擴展搜索鄰居節(jié)點,每隔一層將相應鏈路標記為牽引鏈路(記節(jié)點vi,vj間的鏈路為e(vi,vj)),最終完成全部鏈路的搜索.具體算法如算法1所示.
算法1.牽引鏈路選擇算法.
輸入:網絡拓撲G=(V,E);
輸出:牽引鏈路集合L.
① 計算節(jié)點v∈V的度degree(v);
② 初始化已探測節(jié)點集合Vb=?;
③ 初始化牽引鏈路集合L=?;
④ 將所有節(jié)點顏色初始化為white;
⑤ 標記V中度最小的節(jié)點v0顏色為grey;
⑥Flag=0;
⑦ while (Vb≠V)
⑧ 對于所有節(jié)點v若color(v)==grey則放入集合Vg;
⑨ for all nodesviinVg
⑩ for all nodesvj∈neighbour(vi)
其中,算法行①~④初始化相應數值;行⑤選擇連接度最低的節(jié)點作為起點;行⑥設置牽引標記信號(當該信號為偶數時,表示選擇該層鏈路作為牽引鏈路);行⑦確保網絡所有節(jié)點被訪問;行⑧選擇當前標記為灰色的節(jié)點集合Vg作為當前層搜索起點;行⑨~搜索每個Vg中節(jié)點的白色鄰居節(jié)點,并且在Flag為偶數時取相應鏈路為牽引鏈路;行更新牽引標記信號;行~將Vg中完成搜索的節(jié)點標記為黑色,并添加到Vb;行~結束循環(huán).
2.2 在線路由策略部署
在線路由策略部署階段主要分為3個環(huán)節(jié):網絡信息收集、智能策略生成和策略執(zhí)行.其中,網絡信息收集主要通過SDN控制器完成,智能策略生成主要由DRL算法生成,策略執(zhí)行主要通過相應路徑算法生成并將路由信息更新到數據平面.具體地,這3個環(huán)節(jié)執(zhí)行過程為:
1) 網絡信息收集.本文實現方案中,網絡信息收集環(huán)節(jié)由控制器通過OpenFlow[28]協(xié)議收集數據平面的牽引鏈路流量信息.OpenFlow定義了端口數據量統(tǒng)計字段,通過不同時刻采集的統(tǒng)計字段的相應數值大小結合采集間隔,即可近似計算得到該時段內相應端口的數據吞吐量.計算得到端口的數據吞吐量后,即可得到牽引鏈路吞吐量,最終匯集形成牽引鏈路的流量視圖.經過特定輸入格式轉化后,該流量視圖即可作為DRL神經網絡的輸入參數.
2) 智能策略生成.智能策略生成階段主要以流量視圖作為輸入數據,通過DRL中的神經網絡完成計算;每個輸出層神經元對應于一個牽引鏈路,輸出層數值即為各個牽引鏈路的權重值.
3) 策略執(zhí)行.策略執(zhí)行階段主要由控制器負責執(zhí)行.控制器在全網視圖中,默認將所有鏈路權重設置為1.在獲得DRL輸出的牽引鏈路權重值后,更新相應鏈路權重.鏈路權重更新完畢后,通過Floyd-Warshall算法計算網絡中所有端到端通信的加權最短路徑、并將相關更新后的路徑值轉換為數據平面的流表,更新到交換機中,從而最終改變網絡中數據流的路由.
其中,Hierar-DRL在線路由策略應用于實際網絡之前,需要完成對DRL算法的訓練.該訓練過程基于仿真數據離線進行,因此不干擾實際網絡的運行狀態(tài).同時,訓練過程中,由于DRL算法需要完成對所輸出的策略質量進行評估,因此網絡信息收集階段還要進行策略質量信息收集,其內容為Hierar-DRL的路由優(yōu)化目標(例如全局平均時延).
3 DRL算法實現
本節(jié)主要論述Hierar-DRL中使用的DRL算法,包括DRL算法框架的實現和其所使用的神經網絡結構.
3.1 DRL算法框架
Hierar-DRL使用的DRL算法以TD3算法[29]為基礎,將DRL與作用環(huán)境的交互過程建模為Markov過程.該Markov過程可通過s,a,r三元組表示.其中,s為DRL所觀測到的環(huán)境狀態(tài)(本文中即網絡流量視圖);a為DRL輸出策略內容(本文中即相應鏈路權重值);r為策略獎勵值.在每個決策時刻,DRL算法完成a=μθ(s)的計算過程,即由s得到a值,其中μθ(·)為神經網絡,θ為神經網絡中的參數值.其中,在訓練過程中通常以對a加噪聲的方式增加隨機性,以提高算法的策略探索效果.
DRL算法在輸出策略后,通過價值函數來衡量策略質量Q.其中,在時刻t下的策略質量表示為
Q(st,at)=E[rt+γQ(st+1,at+1)],
(3)
其中,γ為未來折扣因子,即對于未來獎勵值進行折扣計算.策略價值函數通過神經網絡實現,因此可進一步表示為Q(st,at|θ).為區(qū)分策略生成網絡a=μθ(s)(actor network)使用的神經網絡和策略價值網絡的神經網絡Q(st,at|θ)(critic network),將二者神經網絡分別記為θμ和θQ.訓練過程中,需要通過反向傳播的方式將策略的獎勵值和策略價值衡量之間的誤差值反饋到神經網絡中以更新神經網絡的連接權重等參數.Hierar-DRL使用的誤差函數定義為
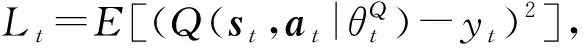
(4)


(5)
為提升神經網絡更新穩(wěn)定性,Hierar-DRL采用了文獻[30]提出的目標網絡方法,即為策略生成網絡θμ和策略價值網絡θQ分別建立1份鏡像θμ′和θQ′,稱之為目標網絡(target network).本文所使用的整體DRL架構如圖2所示,其中每個時刻策略生成網絡(actor network)根據觀測到的網絡狀態(tài)值s計算出相應動作a,該狀態(tài)-動作(s,a)由2個策略價值網絡(critic network)分別計算Q值,并與2個目標策略價值網絡(target critic network)中的較小價值Q′計算生成誤差值(式(4))來更新策略價值網絡的神經網絡參數.策略生成網絡根據具有較小Q值的策略價值網絡按照式(5)進行神經網絡參數更新.更新完成后,目標網絡中的相應網絡(目標策略生成網絡和目標策略價值網絡)則根據其對應網絡的參數進行更新.

Fig. 2 The architecture of DRL圖2 DRL架構
DRL的整體訓練過程如算法2所示:
算法2.DRL訓練更新算法.
輸入:s,r;
輸出:a.
① 初始化神經網絡參數θQ1,θQ2,θμ;
② 初始化緩存B;
③ forepisode=1 toM
④ 初始化隨機過程N用于策略探索;
⑤ fort=1:STEP_NUM
⑥ 收集牽引鏈路信息st;
⑦ 計算at=μ(st|θμ)+Nt;
⑧ 在網絡中執(zhí)行at,收集rtandst+1;
⑨ 在緩存B中保存 (st,at,rt,st+1);
⑩ 從緩存B中隨機提取數據;
3.2 神經網絡結構
本節(jié)主要論述Hierar-DRL所使用的神經網絡結構,即相應的神經網絡輸入輸出接口.由于網絡流量信息具有時間相關性,因此可以使用循環(huán)神經網絡(recurrent neural network, RNN)提取流量中的時間相關信息.其中,Hierar-DRL使用RNN中的門控循環(huán)單元(gated recurrent unit, GRU)網絡提取相應特征,以提高特征提取能力.GRU網絡結構如圖3所示.其中,每個時刻狀態(tài)輸入st需和上一時刻的網絡隱藏狀態(tài)ht-1進行系列運算、經過不同激活門控函數σ(sigmoid函數)進行激活運算后得到當前神經網絡狀態(tài)ht,即可作為GRU的輸出.Hierar-DRL中,GRU的輸入狀態(tài)即為網絡流量視圖,輸出狀態(tài)連接到2層前饋神經網絡(feedforward neural network, FF)進行進一步運算.前饋神經網絡的輸出即為整個神經網絡的輸出.

Fig. 3 Illustration of the neural networks in Hierar-DRL圖3 Hierar-DRL神經網絡結構示意
Hierar-DRL中的神經網絡輸入輸出接口即對應于整個DRL算法的輸入輸出.現將算法的輸入s、輸出a和策略獎勵值r定義為:
輸入s為網絡中鏈路的吞吐量信息,以st×l×n表示.其中,t為序列的時序長度,l為鏈路的數量,n為網絡數據流的分流數量.
輸出a對應于牽引鏈路的權重,以al×n表示,l為牽引鏈路的數量,n為網絡數據流的分流數量.
獎勵值r用來為神經網絡提供路由策略價值反饋,為標量值.路由策略質量可以通過多種指標衡量,例如數據流平均時延、網絡負載均衡程度等.通用r計算可以使用r=f(delay,balance,jitter)表示,即綜合考慮路由策略在平均時延、負載均衡和抖動等方面的表現.本文中主要使用數據流平均時延作為衡量指標.
4 實驗評估
本節(jié)主要介紹Hierar-DRL的仿真測試環(huán)境及性能測試結果.
4.1 仿真環(huán)境
本文使用OMNet++ 4.6編寫了Hierar-DRL的仿真測試環(huán)境.仿真平臺運行于Ubuntu系統(tǒng),硬件平臺為PC臺式機,集成Intel i8700 CPU和32 G DDR4 RAM.DRL算法使用Keras實現(基于Tensorflow 1.12.0),語言版本為Python 3.7.為測試Hierar-DRL在不同網絡拓撲規(guī)模下的性能,本文分別使用NSF網絡[31]、OS3E網絡[32]以及BRITE[33]拓撲產生工具等不同網絡拓撲結構.其中,NSF網絡具有14個網絡節(jié)點,OS3E網絡具有34個網絡節(jié)點,BRITE工具生成具有61個節(jié)點和87個節(jié)點的網絡.本文按照Lakhina等人[34]提出的骨干網流量模型生成網絡訓練和測試流量,即:網絡端到端流量主要由周期性流量和隨機流量構成,其中周期性流量占據了網絡流量的主要成分(例如Sprint-1數據集[34]中,周期性流量占據了總流量的90%).本文中,為測試不同流量環(huán)境下Hierar-DRL的性能,通過設置周期性流量比例δ來生成不同的流量,例如δ=0.9表示周期性流量占據總流量的90%;隨機流量的產生服從泊松分布[4].其中,DRL算法中的r采用網絡平均端到端時延計算.
4.2 性能評估
本節(jié)針對不同的性能指標將Hierar-DRL(實驗結果中簡稱Hierar)與3個方案進行對比:
1) 最短路徑優(yōu)先(SPF).基于最短路徑優(yōu)先的路由策略是網絡中的基本路由策略之一,在OSPF等協(xié)議中使用.最短路徑優(yōu)先路由根據網絡鏈路的預先分配權重值進行加權最短路徑計算從而得到路由.
2) TIDE方案[19].TIDE收集網絡全局的流量視圖,通過DRL算法動態(tài)分析網絡流量并為網絡中所有鏈路分配動態(tài)權重值,并基于動態(tài)權重值完成網絡路由的路徑計算.
3) DRL-TE方案[4].DRL-TE通過DRL算法收集網絡數據流的流量信息并且針對每條數據流進行路由調整.其中,針對目標數據流提前計算3條備選路徑,根據DRL算法輸出結果調整備選路徑上的數據流.
不同方案端到端時延對比.圖4顯示了不同方案在不同網絡規(guī)模下的端到端流量傳輸的性能對比.其中,周期性流量比例δ=0.9.從圖4可以看出,在不同網絡下,相比于其他方案,SPF路由端到端時延總是最大,表明網絡中的靜態(tài)最短路徑路由擁塞明顯,造成數據包傳輸時延增大.其中,隨著網絡規(guī)模的增大,TIDE和DRL-TE的性能下降比較明顯而Hierar-DRL性能下降較小,其主要原因在于網絡規(guī)模增大后,TIDE和DRL-TE方案的神經網絡遇到了維度災難問題,導致DRL算法沒有較好收斂.其中,DRL-TE在較大網絡規(guī)模下性能要優(yōu)于TIDE,由于DRL-TE將數據流分到3條備選路徑,總體上擁塞發(fā)生概率要低于TIDE的單路徑路由;而DRL-TE,TIDE,Hierar的端到端時延波動性要大于SPF,表明神經網絡在分析波動流量時相比靜態(tài)方案存在更大方差.總體上,隨著網絡規(guī)模增大,Hierar-DRL相對于其他方案的優(yōu)勢逐漸明顯,在網絡拓撲為87個節(jié)點時,Hierar-DRL的平均端到端時延為98 ms,相比于當前最優(yōu)方案(137 ms)降低了28.5%.

Fig. 4 Delay comparison among different schemes圖4 不同方案端到端時延對比
控制層信息交互量.基于SDN實現路由的過程中,需要通過控制器收集網絡信息并動態(tài)下發(fā)流表到數據層.數據層信息的上傳和下發(fā)過程需要占據控制信道帶寬資源.圖4展示了不同方案信息上傳和下發(fā)信息量的對比.其中,由于SPF無需通過SDN更新路由信息,因此不在方案比較中.由圖5可以看出,由于DRL-TE需要收集網絡中所有數據流信息并對每條端到端數據流進行控制,其上傳信息量和下發(fā)信息量明顯高于TIDE和Hierar-DRL.TIDE和Hierar-DRL都是針對鏈路權重進行調節(jié),而Hierar-DRL僅針對牽引鏈路收集信息和調整權重,因此其上傳和下發(fā)信息量要低于TIDE.

Fig. 5 Amount of information for interaction圖5 控制層信息交互量
多種網絡流量特征性能測試.圖6展示了不同周期性流量比例δ設置下Hierar-DRL的性能.其中,σ=0表示網絡流量為固定周期性數值,而σ=1表示網絡流量為完全隨機值.由圖6中數據可以看出,隨著δ值的增大,Hierar-DRL的性能呈現出下降趨勢.其主要原因在于目前基于神經網絡實現的智能路由通過對神經網絡的訓練提取網絡流量特征、生成相應路由策略.網絡流量的隨機性增加,增大了神經網絡提取流量特征的難度,因此基于DRL的路由策略性能會下降.

Fig. 6 The performance of Hierar-DRL under different traffic圖6 不同流量下Hierar-DRL性能
維度災難.圖7展示了在網絡節(jié)點數為87時,TIDE和DRL-TE因為維度災難問題,算法無法實現明顯的收斂.相對應地,Hierar由于引入了牽引控制理論,有效減少了輸出動作空間,因此算法在訓練過程中仍然能夠較好地提升并收斂.
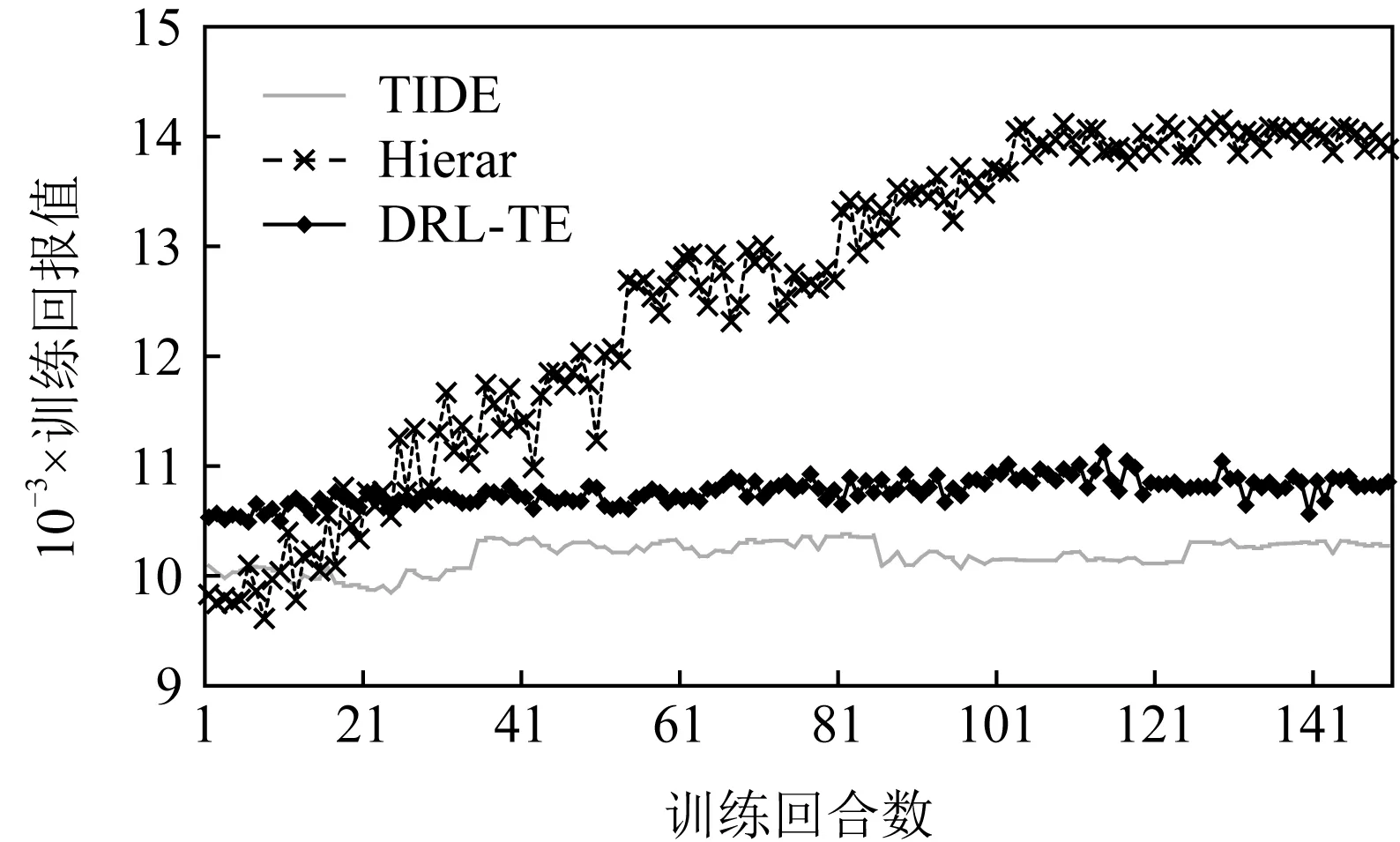
Fig. 7 An example of the curse of dimensionality problem (each iteration contains 1 000 steps)圖7 維度災難結果示意(每回合包含1 000步)
5 總 結
本文提出了一種基于牽引控制理論的DRL智能路由技術Hierar-DRL,分析了當前基于DRL算法實現的智能路由方案普遍存在的問題并創(chuàng)造性地引入控制論中的牽引控制理論解決其他方案中算法可擴展性問題.Hierar-DRL基于牽引控制理論設計了牽引鏈路算法,減少了DRL算法所需實現的控制策略維度;同時,引入了當前最新的DRL算法框架TD3實現路由策略的自動探索優(yōu)化,實現了自動化路由策略生成.本文基于OMNet++實現的仿真測試表明了Hierar-DRL相對于其他方案的性能優(yōu)勢.在下一步工作中,我們將繼續(xù)探索規(guī)模化網絡下的智能路由策略,提升牽引鏈路選擇的精確度進而提升系統(tǒng)性能.
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:42
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年9期)2018-10-08 02:29:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:10
數學大世界(2018年1期)2018-04-12 05:39:14
幸福(2017年18期)2018-01-03 06:34:53
中國衛(wèi)生(2016年8期)2016-11-12 13:26:50
