在線機(jī)器學(xué)習(xí)在智能鉆井中的應(yīng)用
2021-07-25 10:03:14羅海峰王濤
電腦知識與技術(shù) 2021年16期
關(guān)鍵詞:機(jī)器學(xué)習(xí)
羅海峰 王濤

摘要:隨著國家對互聯(lián)網(wǎng)、人工智能、機(jī)器學(xué)習(xí)等前沿計算機(jī)技術(shù)的推廣,以及計算機(jī)技術(shù)所帶來的高效能力,提供的先進(jìn)決策方法,為智能鉆井提供了新的解決方案。相較傳統(tǒng)的離線學(xué)習(xí)的方法,在線機(jī)器學(xué)習(xí)在分析鉆井過程中具有更強(qiáng)的適應(yīng)性、更好的解析能力和糾錯能力。本文簡述了在線學(xué)習(xí)在鉆井工程的應(yīng)用。
關(guān)鍵詞:機(jī)器學(xué)習(xí);離線學(xué)習(xí);在線學(xué)習(xí);智能鉆井
中圖分類號:TP311文獻(xiàn)標(biāo)識碼:A
文章編號:1009-3044(2021)16-0188-02
開放科學(xué)(資源服務(wù))標(biāo)識碼(OSID)
Application of Online Machine Learning in Intelligent Drilling
LUO Hai-feng, WANG Tao
(School of Computer Science, Southwest Petroleum University, Chengdu 610500,China)
Abstract: With the country's promotion of cutting-edge computer technologies such as the Internet, artificial intelligence, and machine learning, as well as the efficient capabilities and advanced decision-making methods brought by computer technology, new solutions are provided for intelligent drilling. Compared with the traditional offline learning method, online machine learning has stronger adaptability, better analytical ability and error correction ability in the analysis and drilling process. This article briefly describes the application of online learning in drilling engineering.
Key words: Machine learning; Offline learning; Online learning; Intelligent drilling
1概述
隨著對油氣資源需求的增長,石油勘探開發(fā)的速度不斷提高,鉆井新技術(shù)迅速推廣,對智能化鉆井的需求不斷增加[1]。智能鉆井從空間環(huán)境來看主要分為井下工具的智能化、井上智能鉆井系統(tǒng)和高效的信息傳輸通道,當(dāng)前鉆井過程中將井下信息傳遞到地面已經(jīng)具備完善的鉆井裝備和解決方案,但是如何有效利用獲取的鉆井信息,是智能鉆井當(dāng)前需要解決的關(guān)鍵問題之一。機(jī)器學(xué)習(xí)的強(qiáng)大的高維非線性映射能力和大數(shù)據(jù)處理能力為鉆井?dāng)?shù)據(jù)分析利用提供了有效的解決途徑,減少現(xiàn)場作業(yè)人員,提供一定的決策支持能力,大幅提高作業(yè)效率和安全性。
傳統(tǒng)作業(yè)方法中,通過建立數(shù)理方程對鉆井參數(shù)分析,實現(xiàn)井眼監(jiān)測、卡鉆監(jiān)測、井涌預(yù)測和機(jī)械鉆速預(yù)測等。相比傳統(tǒng)方法,基于機(jī)器學(xué)習(xí)的鉆井參數(shù)分析具有更可靠的分析精度,并且可以更全面的考慮多種特征因素對分析結(jié)果的影響。但是,由于新開鉆井地質(zhì)和工程條件的差異,以及現(xiàn)場工況的復(fù)雜性導(dǎo)致離線模型的適用性會隨實際開采情況變化,不再具有穩(wěn)定的分析預(yù)測效率。在線模型具有的實時校正和在線更新的能力,因此,在某些工況下是更符合智能鉆井的需求。
2基于離線學(xué)習(xí)的智能鉆井
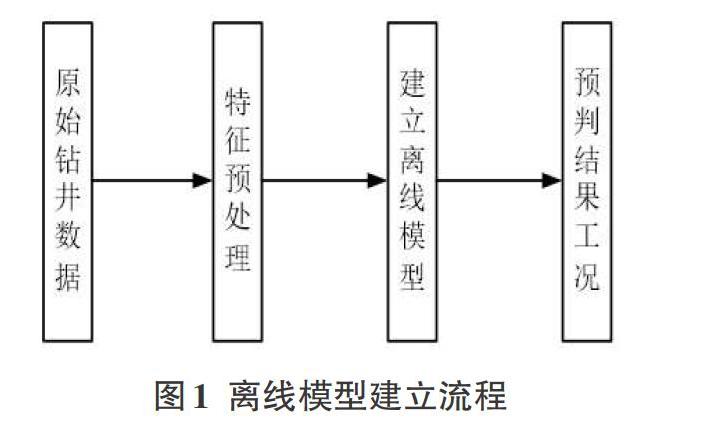
2.1 離線模型建立流程
基于離線模型的智能鉆井參數(shù)分析中,主要過程如圖1所示,獲取的鉆測井?dāng)?shù)據(jù)包括深度、鉆壓、轉(zhuǎn)速、鉤載、排量、鉆井液密度、轉(zhuǎn)盤扭矩、轉(zhuǎn)盤扭矩變異系數(shù)、鉆頭尺寸、鉆頭型號和地層等相關(guān)信息,經(jīng)過數(shù)據(jù)預(yù)處理剔除無效數(shù)據(jù),提取有效特征因素,構(gòu)建離線機(jī)器學(xué)習(xí)模型,將離線模型用于新井工況檢預(yù)測。
2.2 離線隨機(jī)森林
隨機(jī)森林可以理解為基于自助采樣法和決策樹的一種提升方法,如圖2所示,通過自助采樣法有放回隨機(jī)選取m個子樣本使用決策樹訓(xùn)練基礎(chǔ)模型,在訓(xùn)練決策樹時選擇k個屬性建立基模型,一般情況下k=log2d(d表示樣本中的屬性個數(shù)),這樣做的目的是提供一定的樣本擾動性和屬性擾動性,使得基礎(chǔ)模型盡可能有較大差異,具有多樣性的同時個體模型不會太差,最終的集成樹效果有提升。
機(jī)器學(xué)習(xí)在智能鉆機(jī)中典型應(yīng)用之一是巖性識別。文獻(xiàn)[5]集中探討了不同機(jī)器學(xué)習(xí)方法在巖性預(yù)測上的性能表現(xiàn)。
基于離線方法建立模型的方式中,一個重要假設(shè)是我們已經(jīng)獲取了全部可能的樣本。在利用堪薩斯大學(xué)[2]提供的鉆井?dāng)?shù)據(jù)集中,使用傳統(tǒng)離線方式建立預(yù)測模型,將數(shù)據(jù)集隨機(jī)打亂并按照1:4的比例劃分為訓(xùn)練集和測試集,采用隨機(jī)森林算法實現(xiàn)巖性分類,模型的效果能夠達(dá)到85%。但是當(dāng)我們模擬現(xiàn)場鉆井過程,數(shù)據(jù)是按照順序流的方式到來,由于未學(xué)習(xí)過的樣本模型是不能識別的,只能對學(xué)習(xí)過的樣本識別,模型準(zhǔn)確率僅有47.65%,所以此時訓(xùn)練出的模型是不適用此類工況環(huán)境的。
3基于在線學(xué)習(xí)的智能鉆井
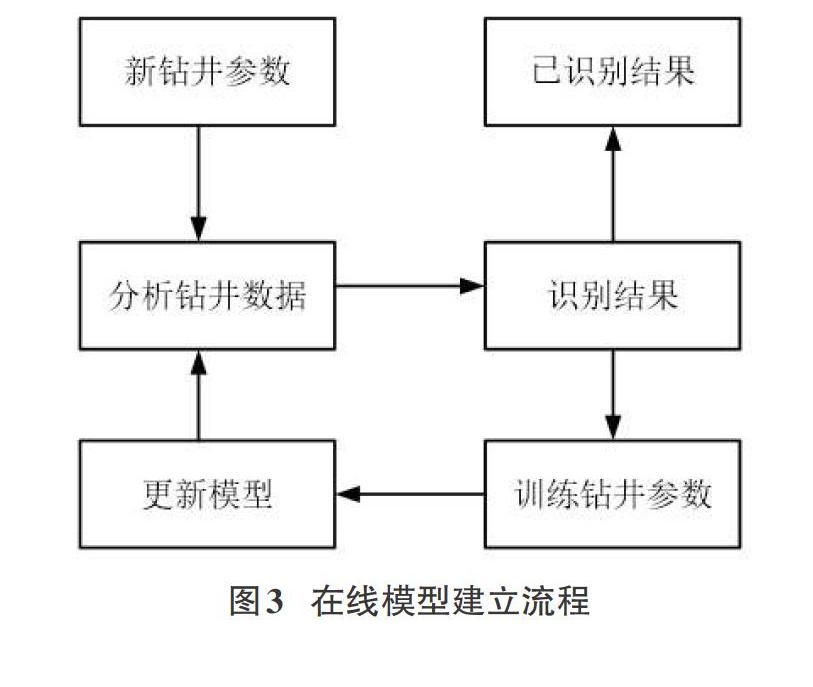
3.1在線模型建立流程
同離線模型相比在線模型的建立過程中主要的不同點在于模型的更新過程,通過有效的更新模型使得模型更加適用于這類隨時間變化隨工況變化的存在概念漂移的數(shù)據(jù)。如圖3所示,為了使模型能夠適用概念漂移在新樣本到達(dá)時,首先基于上一輪的模型對新樣本進(jìn)行預(yù)測分析,再基于新樣本對模型更新,學(xué)習(xí)新樣本的數(shù)據(jù)特征。
3.2在線隨機(jī)森林
在線隨機(jī)森林[3]中一種有效的模型更新方法是每個決策樹模型可以在線分裂,分裂的條件是預(yù)測的數(shù)量和葉子節(jié)點的Gini指數(shù)達(dá)到設(shè)定的閾值。這種方法不會改變整個森林的結(jié)構(gòu)。如圖4所示,基于決策樹更新的方式流程圖。
在線機(jī)器學(xué)習(xí)在Shai[4]等人首次設(shè)計出一種高效的在線SVM求解算法后由此掀起了在線學(xué)習(xí)在機(jī)器學(xué)習(xí)領(lǐng)域的研究和應(yīng)用高潮,并在近年持續(xù)成為熱點研究問題。鉆井工程中在線學(xué)習(xí)還未得到相關(guān)的研究。
基于在線方法建立模型的方式中,我們同樣將測井?dāng)?shù)據(jù)集[2]模擬實際開采過程數(shù)據(jù)流的到達(dá)方式,在線隨機(jī)森林相比離線隨機(jī)森林能夠有效地提高模型對未知新樣本的識別能力,模型分類效果達(dá)到62%。
4結(jié)束語
在線學(xué)習(xí)算法相對離線機(jī)器學(xué)習(xí)對新樣本的處理能力有效提高,但是在我們的應(yīng)用中,模型效果還不足以用于實際開采工作中給出具有指導(dǎo)性決策支持,下一步可行的方案是在獲取大量可靠數(shù)據(jù)后首先建立傳統(tǒng)的離線模型,將離線模型融合到在線模型中,提高在線模型效率。
參考文獻(xiàn):
[1] 王茜,張菲菲,李紫璇,等.基于鉆井模型與人工智能相耦合的實時智能鉆井監(jiān)測技術(shù)[J].石油鉆采工藝,2020,42(1):6-15.
[2] Xie Y X,ZhuCY,ZhouW,etal.Evaluation of machine learning methods for formation lithology identification:a comparison of tuning processes and model performances[J].Journal of Petroleum Science and Engineering,2018,160:182-193.
[3] http://www.kgs.ku.edu/PRS/petroDB.html
[4] SaffariA,LeistnerC,SantnerJ,etal.On-line random forests[C]//2009 IEEE 12th International Conference on Computer VisionWorkshops,ICCVWorkshops.September27 - October4,2009,Kyoto,Japan.IEEE,2009:1393-1400.
[5] Shalev-ShwartzS,SingerY,SrebroN.Pegasos:primal estimated sub-GrAdientSOlver for SVM[C]//Proceedings of the 24thinternational conference on Machine learning - ICML '07.June20-24,2007.Corvalis,Oregon.NewYork:ACM Press,2007:807-814.
【通聯(lián)編輯:梁書】
猜你喜歡
電子技術(shù)與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導(dǎo)刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學(xué)與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(shù)(2016年20期)2016-08-19 18:49:49
電腦知識與技術(shù)(2016年12期)2016-06-14 00:45:31
科教導(dǎo)刊·電子版(2016年10期)2016-06-02 19:17:03
科教導(dǎo)刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(shù)(2016年3期)2016-04-07 16:12:55
