基于單向Transformer和孿生網絡的多輪任務型對話技術
2021-07-26 11:54:50劉超輝鄭青青黃嘉曦
計算機工程 2021年7期
王 濤,劉超輝,鄭青青,黃嘉曦
(深圳市易馬達科技有限公司,廣東深圳518055)
0 概述
使機器以自然語言的方式與人類進行交流,完成人類下達的任務,是人工智能[1-3]領域最具挑戰的一項研究。1951年,圖靈在《計算機與智能》一文中提出用人機對話來測試機器智能水平[4],隨后掀起了關于人機對話研究的熱潮。近年來,工業界更是將對話系統視為下一代人機交互的主要形式。2003年,BENGIO 等[5]率先將神經網絡應用于自然語言處理任務,并取得了較好的效果。2010年,MIKOLOV等[6]提出的RNNLM 更是顯著提高了語言模型的準確性,之后的循環神經網絡(RNN)及其各種變體如LSTM[7]、GRU[8],開始逐漸成為自然語言處理領域的常用技術。Google 于2017年提出了一種新的序列建模模型Transformer[9],在自然語言處理(NLP)領域引起了極大的反響,而后BERT[10]的發布更是將自然語言處理技術推上了一個新的臺階。
任務型對話系統[11-12],即接受人類指令完成特定任務的對話系統是被工業界廣泛使用的對話系統之一。相比于閑聊型對話系統,任務型對話系統存在以下難點:可供使用的數據集相對較小,面向任務的對話系統因為其任務的特殊性,很難像閑聊系統項目啟動之初即擁有大量的閑聊對話數據可以使用,而面向任務的對話系統針對不同的任務,通常只能生成或取得非常少量的數據。任務型對話系統對應答的準確性要求較高,閑聊型對話系統應答出錯一般情況下不會引起使用者的不適,而任務型對話系統應答出錯會直接導致用戶下達的指令或任務無法被完成。
為了解決上述問題,本文構建一種面向小數據集的任務型多輪對話控制模型。引入多個預訓練模型[13]與工具,借助外部知識對句子語意和對話過程進行深度編碼。通過對Transformer 模型做進一步精簡,僅保留編碼器[14]部分的單向Transformer,從而充分利用了多頭自注意力機[9]優秀的特征提取能力,并且使精簡后的單向模型可以支持并行計算,提升計算效率。在此基礎上,將應答部分抽象成指令,利用孿生神經網絡[15]在小數據集上的優勢對指令進行基于相似度的排序,最終選取相似度最高的指令生成應答。
1 相關工作
無論是學術界還是工業界,關于對話機器人的研究一直都沒有停止過。ZHOU[16]等提出了基于卷積神經網絡[17]和循環神經網絡的多輪對話檢索模型,該模型將對話上下文信息作為輸入,并從詞序列和句子序列2 個視角來計算匹配分數,最終結合2 個分數來選擇回復。基于詞序列的視角將文本中所有詞按順序輸入到一個GRU 中,將其隱藏向量作為文本的語義表示;句子序列的視角則基于卷積神經網絡,先通過卷積和池化得到每個話語的表示,再輸入到另一個GRU 中輸出文本的表示。
隨著Transformer的流行,越來越多的研究人員開始嘗試用Transformer構建多輪對話模型。HENDERSON[18]等利用Transformer 在Reddit 數據集上構建了一個大型的多輪對話模型,其中在對話控制和回復生成上全都采用了Transformer 結構,取得了較好的效果,證明了Transformer 在多輪對話系統建模上的優秀性能。DINAN[19]等采用了一個類似的結構使用Transformer 對多輪對話進行建模,只是在回復生成部分,其設計提供了2 種方式:一種是檢索式的,即Transformer 模型用于對回復部分進行排序:另一種是生成式的,即使用Transformer 直接生成token-bytoken 的回復。
2 多輪對話控制模型
本文提出的基于單向Transformer和孿生網絡的多輪對話控制技術,引入了多個預訓練模型來彌補數據樣本集較小和信息不足的問題,借助外部知識對模型輸入和對話過程進行深度編碼,同時對Transformer 模型進行進一步精簡,僅保留編碼器部分的單向Transformer。最后的應答部分沒有采用傳統的分類模型,而是采用孿生神經網絡,通過最大化對話之間的相似度來為當前的對話狀態和每個回復指令進行建模。在預測階段,將當前的對話狀態與所有可能的回復指令進行比較,并選擇具有最高相似度的指令生成回復。具體的模型結構如圖1所示。
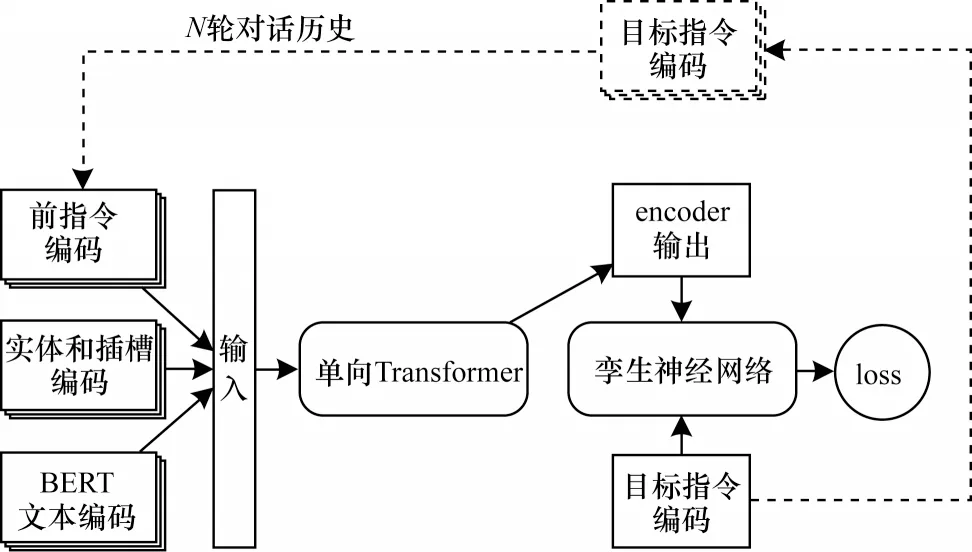
圖1 控制模型結構Fig.1 Structure of control model
2.1 預訓練模型
為了解決樣本數量較小的問題,本文引入多個預訓練模型和工具對句子語意和對話過程進行深度編碼。首先充分利用預訓練模型BERT 的先天優勢將用戶輸入的文本編碼成特征向量,同時利用斯坦福大學的StanfordNLP[20]工具對用戶輸入的文本進行進一步處理,提取出文本中包含的實體、預定義插槽等深度語義特征,并將上述抽取的特征統一進行one-hot 編碼。除此以外,為了盡可能地保存對話狀態,將上一輪對話輸出的目標指令同樣進行one-hot編碼,一起加入到本輪對話的輸入中,最后將上述3 種編碼后的向量進行拼接,作為單向Transformer的輸入。
2.2 單向Transformer
單向Transformer 的輸入包含了系統的歷史指令和文本的深度語義特征,如實體、插槽、預訓練特征向量等,這樣就可以充分利用Transformer 的自注意力機制,使其自發地選擇一些重要的特征,同時忽略一些對對話過程影響不大的非重要特征,這一點在復雜多變的多輪對話中尤其重要。
2.3 孿生神經網絡
本文將單向Transformer 的輸出作為孿生神經網絡的其中一個輸入,再將目標指令的one-hot 編碼作為另一個輸入。在輸出部分將正確的樣本標記為1,錯誤的樣本標記為0,同時由于某些指令要比其他指令多很多,負樣本的數量也要比正樣本多,因此采用隨機采樣算法處理樣本均衡問題,最后通過優化孿生網絡的損失函數訓練模型。在預測階段選用相似度最高的指令生成本輪對話中系統的回復。孿生神經網絡的結構如圖2所示。
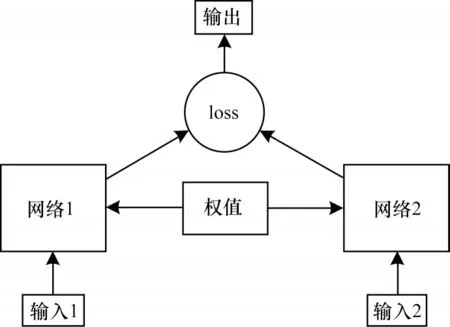
圖2 孿生神經網絡結構Fig.2 Structure siamese network structure
3 實驗驗證
本文實驗使用了2 個基線模型作為對比模型:第1 個是傳統的基于LSTM 的seq2seq 模型[21],該模型是現階段最穩定也是工業界應用最廣泛的模型之一;第2 個是HENDERSON 等于2019年提出的基于Transformer 的模型,該模型是現階段在任務型對話系統中表現最出色的模型之一。同時,使用MultiWOZ 2.1 數據集[22]分別進行了3 組實驗:第1 組實驗對比了預訓練模型對最終結果的影響;第2 組實驗通過縮減數據集規模,對比在小數據集下本文模型的表現效果;第3 組實驗對比了本文模型與另外2 個模型在時間效率上的差別。
3.1 MultiWOZ 數據集
在任務型對話系統中,需要對下一步的指令進行預測,因此類似WikiQA[23]或DailyDialog[24]這樣的數據集無法滿足需求,因為例如“ok”“copy that”等回復實際對應的是同一個指令“YES”。因此,選用MultiWOZ 2.1 數據集作為本文的實驗數據集。
MultiWOZ 2.1 數據集包含了酒店、飯館、火車站、出租車、旅游景點、醫院、警察局等7 個不同情境的對話數據集,共包含10 438 條數據。所有的對話都發生在用戶和接待員之間。用戶會問接待員相關問題,要求接待員完成相關任務,接待員會響應用戶請求或要求用戶補充相關信息,如要求用戶提供姓名等。
在本次任務中,將數據集按7∶3 的比例劃分成訓練集和測試集,訓練集7 307條數據,測試集3 131條數據。
3.2 深度編碼實驗結果
第1 輪實驗中,采用全量的數據對上文基于LSTM、基于Transformer和本文模型進行有無深度編碼的對比實驗。在無深度編碼的分組,使用常用的詞向量[25]技術對用戶輸入進行編碼;在深度編碼分組,采用本文提出的使用預訓練的BERT 對用戶輸入進行編碼,同時融入了實體、插槽等深度特征。最終的實驗結果如表1所示。
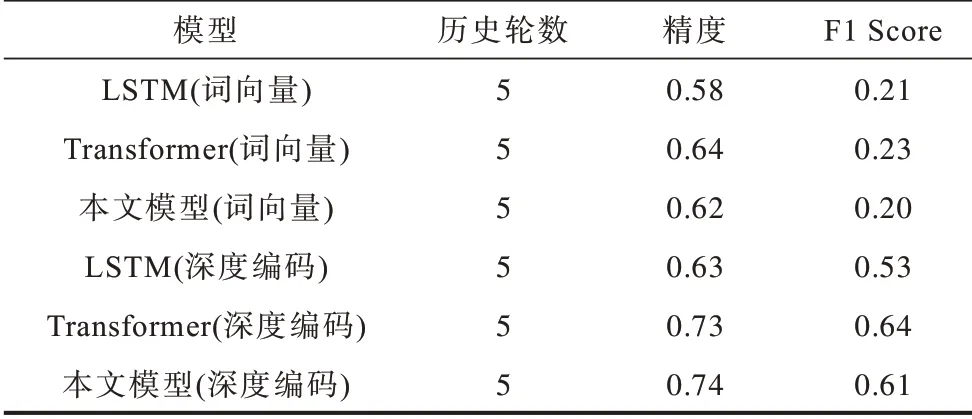
表1 深度編碼實驗數據Table 1 Experimental data of deep encoding
通過對比表1 的數據可以發現,在任務型對話系統中,由于機器的每輪回復都是非常明確的指令,因此傳統的基于詞向量的編碼方式由于缺少任務中的關鍵信息而難以取得好的效果。分別對比3 個模型的詞向量編碼方式和深度編碼方式,可以發現本文提出的深度編碼方式總能取得更好的效果,特別是本文提出的模型相比于傳統的LSTM 基于詞向量的模型,在F1 Score 上取得了近3 倍的提升。
3.3 小數據集實驗結果
第2 輪實驗中,為了驗證本文模型在小數據集上的表現效果,僅使用第1 輪實驗1/5 的數據量,采用上述同樣的深度編碼的方式進行實驗。實驗結果如表2所示。
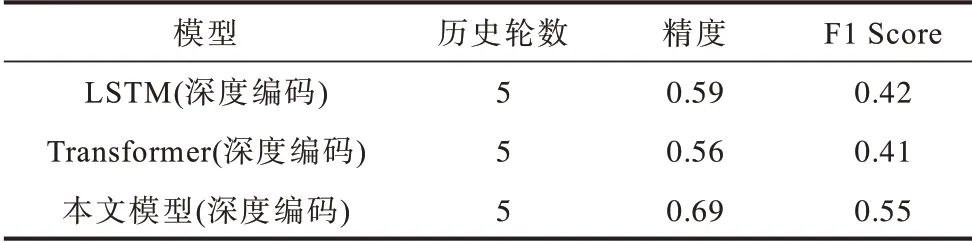
表2 小數據集實驗數據Table 2 Experimental data of small dataset
通過對比表2 和表1 的數據可以發現,當訓練數據縮減為原來的1/5 后,3 個模型的F1 Score 都有不同程度的下降,但本文提出模型的下降幅度遠小于另外2 種模型,僅下降了9.8%,而另外2 種模型分別下降了35.9%和20.8%。HENDERSON 等提出的基于Transformer 的模型在數據集縮減后,分類的準確率甚至不如傳統的基于LSTM 的模型。而本文提出的精簡后的單向Transformer 模型融合孿生神經網絡,在小數據集上取得了比傳統LSTM 和HENDERSON 等提出的基于Transformer 模型都要好的效果。
3.4 預測時間對比實驗結果
第3 輪實驗中,為了驗證本文模型在時間效率上的表現效果,隨機取出1 000 條數據,然后分別使用3 種模型進行預測,從而對比3 種模型在計算性能上的表現效果。實驗結果如表3所示。
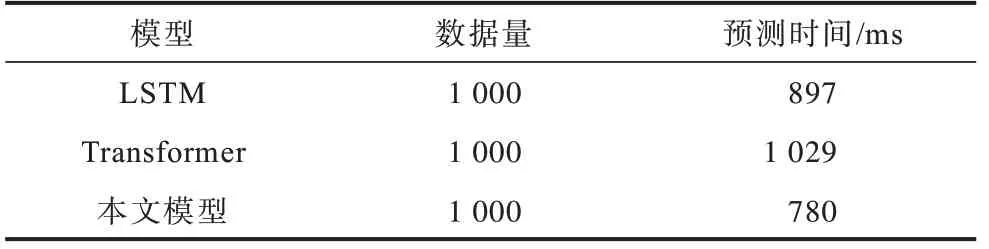
表3 預測時間實驗結果Table3 Experimental results of prediction time
通過對比表3 數據可以發現,本文提出模型的預測時間比HENDERSON 等提出的基于Transformer的模型要短24.1%,與傳統的基于LSTM 的模型的預測速度相近。
4 結束語
本文研究面向任務型對話系統的多輪對話控制技術。通過引入預訓練模型和工具,借助外部知識對模型輸入和對話過程進行深度編碼,同時對Transformer 模型進行精簡,僅保留編碼器部分的單向Transformer。本文在應答部分采用孿生網絡對對話過程進行基于相似度的建模,最終選取相似度最高的指令生成回復。實驗結果表明:在任務型對話系統中,當數據集比較大時,本文提出的模型效果優于傳統的基于LSTM 的模型,與現階段先進的基于Transformer 的模型的表現效果相當,且本文提出的深度編碼方式更加適合任務型對話系統;當數據集規模減小時,在小數據集上,本文提出的模型準確率損失幅度遠小于傳統的基于LSTM 的模型和目前最先進的基于Transformer 的模型,且總體表現效果比LSTM、Transformer2 種模型都更加優秀,本文提出的模型在計算效率上也有一定幅度的提升,說明本文模型相比另外2 種模型在速度上更快且更加適用于小型數據集。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
發明與創新(2016年38期)2016-08-22 03:02:52
