新型智能防疫門禁系統的設計與應用
2021-07-27 03:48:14王卓群易超
電子元器件與信息技術 2021年5期
王卓群,易超
( 中山大學 電子與信息工程學院, 廣東 廣州 510006 )
0 引言
COVID-19病毒給人類帶來了嚴重影響。時至今日,人類仍然同疫情進行著艱苦的斗爭。佩戴口罩則是能夠防止病毒傳播有效措施之一,檢測體溫也能有效預防新冠病毒,如果在進行身份認證的過程中能夠避免口罩被摘下,無疑也能降低疫情傳播的風險。當前多地對于民眾是否佩戴口罩的監管與測溫工作還停留在人工檢測的階段,在無接觸且佩戴口罩的前提下也無法進行有效的身份認證。因此,在疫情背景下,開發一套實時的口罩佩戴檢測與體溫測量的免摘除口罩人臉識別門禁系統迫在眉睫。
相應的研究大多是在疫情爆發后才開展的。對于口罩佩戴檢測這一問題,我們將其視為深度學習神經網絡領域的目標檢測問題,基于深度學習的目標檢測算法十分豐富,有YOLO[1-2]系列算法,也有Fast R-CNN[3]等。這兩大類算法分別側重于速度和精度,因此在實際應用中應當綜合考量。對于戴口罩的人臉識別,之前醫學領域曾進行過相關研究[4],現階段百度、商湯科技等AI智能研發公司相繼推出相關的系統,其核心思想在于通過在傳統的人臉識別網絡中加重分析人眼眉部分的特征或者對口罩遮擋部分的人臉進行重構從而增加人臉在有口罩遮擋情況下識別的正確率。
本文中提出的門禁系統,通過OpenCV采集到的實時圖像,輸入進基于YOLOv3-tiny[5]的口罩佩戴檢測網絡和基于ResNeSt50[6]網絡的戴口罩人臉識別網絡,達到檢測用戶是否佩戴口罩以及身份識別的效果。為了驗證系統的實際應用可能,本文將其以python語言實現并應用到邊緣智能設備Jetson TX2上,搭配溫度傳感器,形成了一個功能完備可以實際使用的裝置。
綜上,對于疫情形勢下的門禁系統的設計問題,本文方法的優勢和創新在于:使用ResNeSt50神經網絡通過預訓練將特征點集中于眼眉部并修改神經網絡中的分類器從而實現戴口罩的人臉識別;用高速的邊緣智能設備搭載功能完整的系統,且多功能間相互配合。
1 口罩檢測模型
本文采用基于YOLOV3-tiny算法進行人臉上的口罩檢測。經過硬件設備上的攝像頭采集到初始圖像,這一圖像經過預先訓練的YOLOv3模型后能高效地檢測出人臉并用檢測框標出適用對象的面部區域在采集到的圖像中的位置。并設置不同的檢測框區別戴口罩和不戴口罩的人臉(如不同的顏色,方框上標注不同的信息)以達到口罩佩戴檢測的效果。在本文中以YOLO網絡的獨特網絡結構和YOLOv3-tiny的改進之處來介紹算法。
1.1 YOLOv3的網絡結構
與前兩代YOLO網絡相比,YOLOv3主要在分類網絡和多尺度預測兩大方面進行了改進。首先是基礎分類網絡Darknet-53[7],比先版本[1-2]引入了新的殘差模塊,并通過將卷積層增加至53層來加深網絡。在Residual結構[8]的作用下,梯度的傳播得到控制,減小了訓練53層卷積網絡的難度。其次是多尺度預測的方法,根據圖像卷積運算的特性,可以認為低層具有準確的目標位置信息,但是與特征相關的信息偏少;而高層的特征語義信息豐富,目標的位置信息卻在不斷地卷積中被混淆。因此YOLOv3網絡綜合了低層和高層信息的優點,分別提取了位于低層,中下層和中間層三個不同尺度的特征圖。每當圖像執行到采集尺度特征的位置時,都會將一部分信息進行處理后作為結果的一部分,另一部分信息進行升采樣后與深層特征圖融合繼續更深層的運算,但在最后的中間層為例外,此時無須保留信息繼續深層運算,只需將之前融合的特征圖卷積輸出即可。這兩點改進使得yolov3網絡在精度上有顯著的提升,并且對于小目標檢測的性能大大提升。
1.2 YOLOV3-tiny的改進之處
在本文中采用的YOLOv3-tiny則是在此網絡上稍加修改,其結構圖如圖1所示。減少了一些特征層,只保留了26*26和52*52兩個尺度,因此將網絡的大小壓縮了許多,有更快的預測速度,且便于部署。在本文想要解決的問題中,能夠檢測是否佩戴口罩的門禁系統需要有極快的反應速度且希望將其部署在嵌入式硬件系統上,因此YOLOv3-tiny很好的適用于門禁系統對于人是否佩戴口罩的快速響應。

圖1 YOLOv3-tiny 網絡構架
2 戴口罩人臉識別模型
本文采用基于ResNeSt50網絡的戴口罩人臉識別算法。在經過硬件設備上的攝像頭采集到初始圖像,并對這一圖像在經過的YOLOV3-tiny模型判斷用戶是否佩戴口罩后。將這一步驟預測出的檢測框范圍內的圖像截取作為鑒別身份模型的輸入。通過將人臉識別主要特征采集點集中在人眼眉部的方法提取戴口罩情況下的人臉信息。將人臉的圖像輸入進預先訓練好的模型后將輸出的特征向量與數據庫進行比對以實現人臉識別。在本文中,通過ResNeSt50以及具體的人臉識別流程來介紹模型。
2.1 ResNeSt50網絡特性
ResNeSt(Split-Attention Networks)是當前深度學習領域內新型網絡結構之一。其核心思想是對最經典的卷積神經網絡ResNet的兩種改良版網絡ResNeXt[9]和SENet[10]中的重要優勢進行融合,其主要優勢在于相比其他的ResNet系列網絡不需要增加額外的計算量而影響工作效率,且網絡具有分組卷積以及注意力機制兩大重要優勢的同時,在圖像分類的實際應用中也能取得很好的效果。應用在本文中的則可以讓模型在訓練的過程中自動將采集的特征點聚焦在眼眉部。而在本文對ResNeSt50的應用中,改進了原本ResNeSt結構,完成神經網絡的訓練并進入應用階段時,將最后具體將特征向量處理成具體類別的全連接層去除,即神經網絡中不再有分類器。神經網絡在處理輸入圖像時只輸出經過模型運算后的特征向量而不是具體的類別。這是因為在做戴口罩的人臉識別過程中,如果由神經網絡來完成身份的判別,一旦人臉識別設備面向的用戶范圍發生變動,則需要將整個網絡重新訓練達到效果。經過本文中所講述的修改,系統只需要將用戶的實時圖像與數據庫中的圖像經過模型生成的特征向量進行比對即可實現身份的認證,并且修改數據庫的過程更加方便快捷且具有實用性。

圖2 人臉識別模型框架
2.2 人臉識別具體步驟
首先需要制作人臉信息數據庫。經過對ResNeSt50的訓練,得到將輸入圖像轉化為特征向量的模型。作為門禁系統僅讓系統能夠識別給定范圍的人臉識別即可,無須要正確識別出我們用于訓練的數據集中全部的人臉。因此提取想要識別的人員戴口罩的圖像每人各一張,經過模型的運算將每個人提供的樣本圖像作為模型的輸入,得到每個人對應的特征向量。將每個人的身份信息和對應的特征向量文件用于讀取。在人臉識別的過程中需將實時攝像頭提取到的圖像經過同樣的模型得到特征向量,并與字典中的特征向量進行一一比對,當向量之間的相似度大于某一閾值,則判定為人臉識別成功。
YOLOv3-tiny檢測口罩佩戴時,會產生一個預測框,該預測框會框住待檢測者的人臉。在此預測框的基礎上進一步裁剪,得到只包含人臉的截取圖像。應用Retinaface算法[11]檢測該圖像中人臉的左眼坐標與右眼坐標,根據這兩個坐標進行人臉對齊,輸入到訓練好的ResNest50網絡進行特征提取。最后將提取出的特征向量與數據庫中的各特征向量計算余弦相似度。若提取出的特征向量與數據庫中的各特征向量的余弦相似度均小于某一閾值時,則判斷當前來訪者為陌生人;反之則取其中數據庫中與當前來訪者的特征向量的余弦相似度最大的特征向量所對應的人作為身份判別結果。
本文采用余弦相似性通過測量兩個向量的夾角的余弦值來度量它們之間的相似性。0度角對應余弦值是1,其他任何角度的余弦值都不大于1;并且其最小值是-1。、兩個向量之間的角度的余弦值可以確定兩個向量是否大致指向相同的方向。兩個向量有相同的指向時,余弦相似度的值為1;兩個向量夾角為90°時,余弦相似度的值為0;相似度的運算結果與向量的長度無關的,僅僅與向量的指向方向相關。余弦相似度通常用于正空間,因此給出的值為0到1之間。其表達式如下,其中的iA和iB表示向量A和B之間的各個分量。

對于人臉在不同環境和條件下展現出特征向量的數值大小可能會有所不同,但人臉在不同情況下的特征向量在超球面面所呈現的角度是大致不變的。因此本文選擇余弦相似度來比對實時讀取到的人臉圖像的特征向量和數據庫中的特征向量。
3 實驗
3.1 數據集與訓練
對于用于口罩檢測模型的訓練,口罩檢測的網絡需要大量佩戴口罩和未佩戴口罩的人臉圖片。在本文選用了武漢大學國家多媒體軟件工程技術研究中心所構建的RMFD數據集[12]。對800張戴口罩和未佩戴口罩的人臉圖片進行了角度旋轉,水平翻轉,顏色抖動等數據增強操作后,得到了3200張的訓練集。同時選用了1200張戴口罩和未佩戴口罩的人臉圖片圖片作為測試集。在訓練集和測試集中均含有兩種標簽:masked和unmasked。

圖3 數據集示例圖
訓練參數如下:

表1 YOLOv3-tiny 訓練參數
在ResNest50的訓練中使用了三個數據集,分別是RMFD數據集,FaceMask CelebA數據集和Umdfaces數據集。其中,RMFD數據集包括10000人的約50萬張戴口罩和不戴口罩的人臉圖,FaceMask CelebA含有10177人的約20萬張戴口罩的人臉圖片,Umdfaces有8277人的367888張人臉圖片。
進行ResNest50模型的訓練的過程中。口罩人臉數據集的數據相對較少,直接用口罩人臉數據集訓練網絡會導致模型訓練速度較慢,且最終訓練得到的模型性能較差,容易出現過擬合問題。因此,本文先使用普通的人臉數據集Umdfaces對ResNeSt50模型進行預訓練,讓模型更加適應人臉的特征提取方式之后再使用RFMD數據集進行正式訓練。
訓練參數如下:

表2 ResNeSt50 預訓練參數

表3 ResNeSt50 訓練參數
3.2 口罩檢測模型測試
由于口罩檢測的功能可以視為一個二分類問題,即識別到的人臉是戴口罩的還是未戴口罩兩種中的哪一種,對于二分類問題,一共可出現四種預測情況:

表4 四種預測情況
其中TP,TN是預測正確的樣本,FP,FN是預測錯誤的樣本,本文通過對模型計算精確率和召回率來評估模型的分類性能。
精確率表示樣本中被正確判定為正的正樣本數占所有被判定為正的樣本數的比例,這是從預測結果的角度評估模型性能,可用來衡量模型的分類能力,計算公式如下:
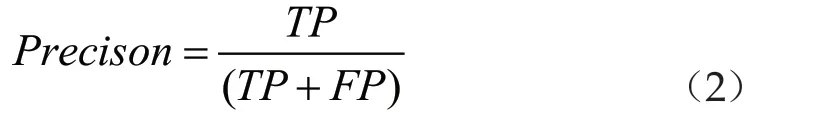
召回率表示樣本中被正確判定為正的正樣本數占原來樣本中正樣本數的比例,這是從原來樣本的角度評估模型性能,可用來衡量模型的檢測能力,計算公式如下:

由圖4可知,模型的準確率,召回率隨訓練次數總體均呈上升趨勢,并且最終收斂在0.9和0.95以上。由此可知,模型具有很好的檢測能力,漏檢情況極少,且對是否佩戴口罩的分類能力很強。

圖4 準確率、召回率曲線
3.3 戴口罩的人臉識別測試
最終訓練得到的ResNeSt50網絡在測試集上有99.62%的準確率,在測試集上有81.48%的準確率,通過CAM熱力圖可以觀察到經過訓練的網絡主要提取眼眉部的特征點。

圖5 訓練前后模型的特征提取點
考慮到實際進行1:N模式的人臉識別的時候,是通過計算人臉圖片間的相似度來確認身份的,ResNest50網絡只作為該過程的特征提取部分,故其用于身份識別的具體性能需要計算人臉識別算法的評價指標值來評估。本文選用人臉識別傳統的TAR和FAR衡量模型的效果。
TAR(True Accept Rate)表示正確接受的比例,FAR(False Accept Rate)表示錯誤接受的比例。計算TAR和FAR需要將兩張人臉圖片組合在一起湊成一對。設一共有N對圖片,這些圖片中既有兩張圖片為同一個人的圖片對,又有兩張圖片不為同一個人的圖片對。稱前者為正對,后者為負對。正對的總數為NT,負對的總數為NF,保證正對的數量和負對的數量近似相同。則用這N對圖片對來對模型進行測試時,模型一共會做出N次判斷。用T表示圖片對為正對且系統判斷確實為同一人的次數,用F表示圖片對為負對但系統判斷為同一人的次數。那么,TAR與FAR的計算公式如下:

通常希望TAR越大越好的同時FAR也也不能超過一定的數值,這代表漏檢率很低同時錯檢率很低。設定一個閾值,當圖片對的兩張圖片的相似度大于該閾值時,則判斷為正對;當圖片對的兩張圖片的相似度小于該閾值時,則判斷為負對。
在確定閾值時, 我們首先去確定令FAR=0.1/0.01/0.001的閾值及所對應的TAR的值,測試結果如下:
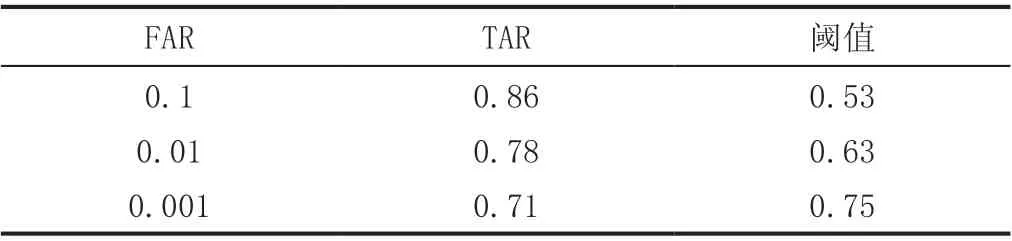
表5 人臉識別網絡在不同閾值下的性能
因此在實際部署系統的過程中,應當根據實際應有需要選擇側重漏檢率還是錯檢率而相應的調整閾值,從而可以實現更加廣泛地應用場景。
3.4 系統總體硬件設置
本項目根據邊緣智能的核心思想設計了一個款以深度學習為基礎能實現口罩佩戴監督和測溫功能的口罩佩戴情況下的人臉身份識別門禁系統。該系統使用卷積神經網絡ResNest50作為身份檢測模型,YoloV3-tiny作為口罩檢測模型,兩個模型并行運行,同時進行口罩佩戴檢查與身份檢測。以NVIDIA Jetson TX2作為核心硬件平臺,以TX2上自帶的攝像頭實時采集公共場合入口的視頻作為數據輸入,以MLX90614紅外測溫模塊測量體溫。
目標進入設定距離范圍內后,同時檢測目標是否佩戴口罩、鑒別目標的身份、測量目標的體溫。只有在目標佩戴口罩,溫度正常(體溫<37.3℃)且與身份被正常識別且無風險記錄時,該門禁系統才能得出允許目標進入的結論,上述三個條件不同時滿足時禁止目標進入。
整個系統涉及到三大主要功能:一,運行YOLOv3-tiny網絡檢測用戶是否佩戴口罩;二,TX2從紅外線測溫模塊進行數據傳輸,獲取溫度數據;三,運行ResNeSt50網絡進行人臉身份識別。三個功能的工作量大小不同,運行速度也不同,因此若在同一個進程中依次執行這三個功能,則每個功能的運行速度都會受限于其他功能的執行速度,從而導致整個系統卡頓,無法實現實時的檢測,而且也無法發揮TX2的優秀算力。
基于邊緣硬件智能平臺強大的運算處理性能,能夠滿足多線程執行的硬件需求,使用python中的thread模塊,創建三個線程并行執行。其中第一個進程進行串口通信,接收來自傳感器得到的體溫并保存。在第二個進程中運行YOLO神經網絡,同時在打開視頻流的時候,若檢查到人臉,則將當前截取后且經過對齊的人臉圖片保存到本地,同時保留存儲地址。在第三個進程中運行ResNeSt50網絡,將進程二中所存儲的人臉圖片輸入到ResNeSt50網絡,得到特征向量后進行身份判別,并將判別結果反饋給進程二,實時顯示在進程二中所繪制的矩形框中。三個進程在時間上互不干擾,三個功能都得以流暢高效的運行。同時三個進程之間也存在必要的信息互通與協作,從而構成一個完整的系統。
將上述系統部署到邊緣智能設備,可以得到集口罩檢測,戴口罩的身份識別以及體溫測量一體化的系統。實際應用效果如下圖所示。

圖6 系統的實際應用效果
在本系統中通過檢測框的顏色和界面上的提示文字在提示用戶是否佩戴口罩,并且在檢測框上方標注出測量到的體溫和身份信息。
4 結論
為了解決疫情時期對于門禁系統獨特的要求,既要要求用戶要佩戴口罩體溫正常,還要求用戶在免拆除口罩的情況下進行認證。本文提出了基于YOLOV3-tiny的深度學習算法用于口罩檢測,同時還使用基于ResNeSt50神經網絡將特征采集點集中在人眼眉部附近,改進原本的網絡分類器實現身份認證,最后將這二者功能和測溫功能使用多進程技術同時部署在嵌入式硬件設備上。利用公開的數據集對模型進行訓練和測試,最終實驗結果顯示口罩檢測模型和戴口罩的人臉識別模型都有較高的精度且具有應用價值。
但本文設計的系統仍然有改進的空間,當前身份認證的過程需要的響應時間會隨著數據庫增大而增大,這一特點將會使得在數據庫極其龐大時降低其使用效率。此外,該系統還可以通過上傳異常用戶信息實現多機互聯,更進一步提高其在防疫工作中的使用價值,是未來進一步改良的方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
學生天地(2020年31期)2020-06-01 02:32:06
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
