基于正樣本的產品缺陷檢測研究
2021-07-31 10:51:54齊宇霄
物聯網技術 2021年7期
關鍵詞:檢測
齊宇霄,王 正,謝 輝,唐 倩,童 瑩
(南京工程學院 信息與通信工程學院,江蘇 南京 211167)
0 引 言
表面缺陷檢測對工業生產而言至關重要,缺陷檢測通常是指對物品表面缺陷進行檢測。傳統缺陷檢測通過人眼檢查,費時費力,效率低下,檢測精度難以達標。
近幾年,隨著機器視覺的興起,表面缺陷檢測隨之發生變化,使用機器視覺系統代替人類視覺系統大大提高了檢測效率和檢測精度。傳統圖像特征提取算子處于較低水平,在很多情況下提取的特征無法處理,因此很多算法并不適用。最近,深度學習在圖像特征提取方面展現出其優勢,卷積神經網絡對目標分類與定位、語義分割等精度較高。
Faghih-Roohi等[1]使用深度卷積神經網絡在軌道表面執行缺陷檢測。將軌道圖像分為6類,包括1類非缺陷圖像和5類缺陷圖像,之后使用DCN對它們再次分類。LIU等提出了兩階段方法[2],該方法將選擇性搜索和卷積神經網絡相結合,檢測并識別獲得的區域,然后完成對膠囊表面缺陷的檢測。Yu等[3]使用2個FCN語義分割網絡檢測缺陷[4],其中一個為粗略定位,另一個為精細定位,由此準確繪制缺陷的輪廓,該方法在DAGM 2007數據集[5]上比原始FCN具有更高的精度,并可以實時完成[6]。
工業檢測應用在實際當中時,因訓練樣本中的缺陷較少,因此難以事先收集全面的缺陷樣型。所以,在訓練過程中正樣本和負樣本的數量極不平衡,生成的模型可能不穩定或無效。同時,手動貼標簽價格昂貴,因此難以在實際缺陷檢測過程中采用。由于缺陷種類不同,且檢測標準和質量指標也不同,這就需要針對特定需求手動標記大量訓練樣本,因此人力需求較大。
針對該問題,本文設計了一種基于正樣本的產品缺陷檢測方法。首先,需要在已有正樣本中構建簡單的缺陷特征,形成自構建負樣本。之后,將自構建負樣本放入自動編碼器,恢復缺陷特征,實現對自動編碼器的訓練。然后,將測試集中的真實負樣本放入訓練好的自動編碼器進行缺陷修復,生成修復樣本。最后,使用LBP算法將修復樣本與真實缺陷樣本的LBP特征圖相減得到差值特征圖,再將差值特征圖二值化,得到缺陷區域坐標。該方法無需手動粘貼標簽,無需大量負樣本進行訓練,缺陷檢測精度高、效率高,對工業檢測的實際應用有很大參考價值。
1 網絡介紹及算法流程
1.1 算法流程
系統訓練流程和測試流程分別如圖1、圖2所示。
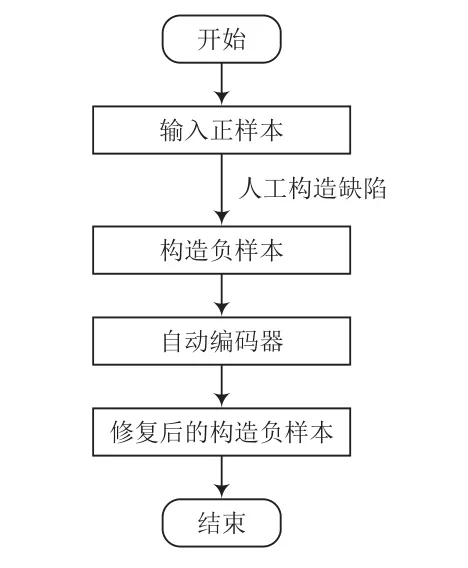
圖1 訓練流程
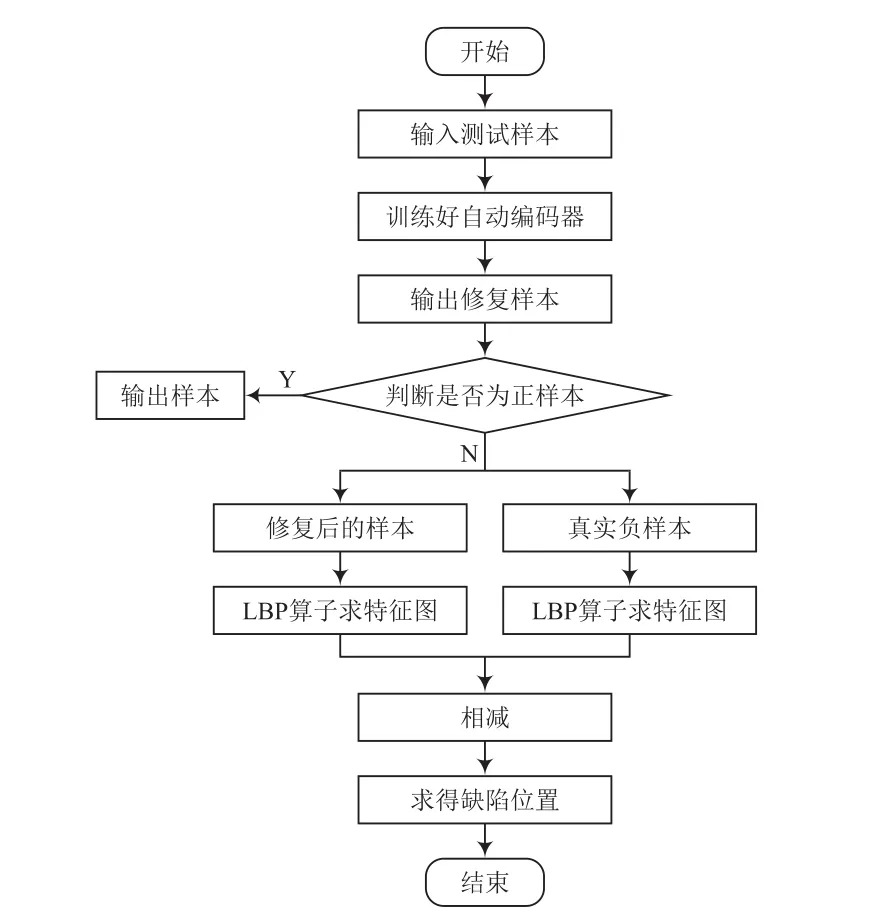
圖2 測試流程
1.2 Autoencoder自動編碼器
Autoencoder(簡稱AE)[7]是一種可以以無監督方式進行學習的人工神經網絡。早期,自編碼器被用于解決表征學習中的編碼問題,其結構如圖3所示。
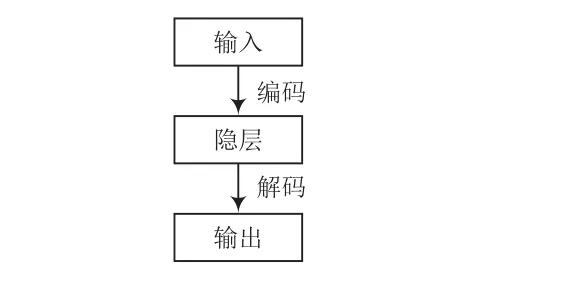
圖3 自編碼器結構
自編碼器結構簡單,訓練時無需標簽,輸出數據與輸入數據基本可保持一致,所以自編碼器是一種無監督算法。重建輸入的神經網絡訓練過程,其隱藏層向量具有降維作用。編碼器會創建一個隱藏層(或多個隱藏層),包含有輸入數據含義的低維向量。解碼器通過隱藏層的低維向量重建輸入數據,通過神經網絡的訓練,AE在隱藏層中得到一個代表輸入數據的低維向量,幫助數據進行分類、可視化顯示、存儲。
為了能讓網絡更好地處理圖像類的輸入數據,我們用卷積層和反卷積層替換了自編碼器中的全連接層,自編碼器結構如圖4所示。
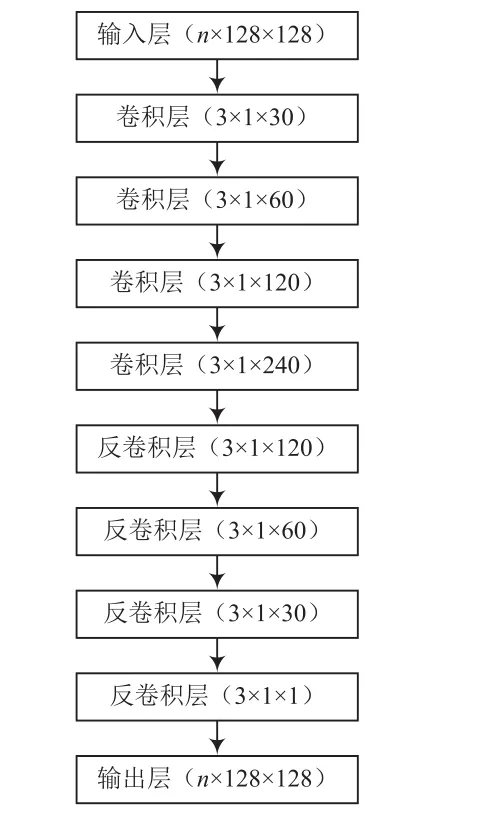
圖4 自編碼器結構
用卷積的思想替換全連接層,可以大大減少網絡架構的參數,同時卷積可以更好地學習圖像特征(具有平移不變性)。一般的卷積神經網絡在卷積層之后接池化層,但這往往會遺漏很多圖像信息,為改善這一現象,我們設置卷積核的步長為2。逐層卷積后,圖像尺寸越來越小,所以在網絡后部分使用反卷積方法,逐漸將特征圖融合復原成原始尺寸,通過訓練盡可能讓輸出接近原始圖像。損失函數計算:
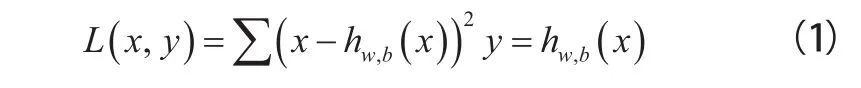
1.3 LBP算子
局部二值模式(Local Binary Pattern, LBP)是用于描述圖像局部紋理特征的算子,具有旋轉不變性和灰度不變性等優點。它首先由T. Ojala,M.Pietikainen于1994年[8]提出,用于紋理特征提取。
傳統的LBP算子定義在3×3窗口內,以窗口中心像素為閾值,將相鄰8個像素的灰度值與其進行比較,若周圍像素值大于中心像素值,則該像素點的位置被標記為1,否則為0。這樣,3×3鄰域內的8個點經比較可產生相應的二進制數(通常轉換為十進制數,即LBP碼,共256種),之后得到該窗口中心像素點的LBP值,并用該值反映該區域的紋理信息。LBP計算如圖5所示。
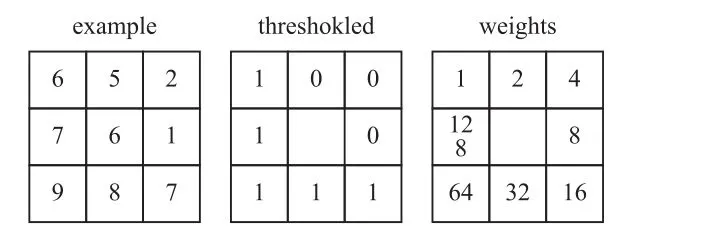
圖5 LBP計算
提取LBP特征向量的步驟如下:
(1)首先將檢測窗口劃分為16×16的小區域(cell)。
(2)對于每個cell中的像素,將相鄰8個像素的灰度值與其進行比較,得到該窗口中心像素點的LBP值。
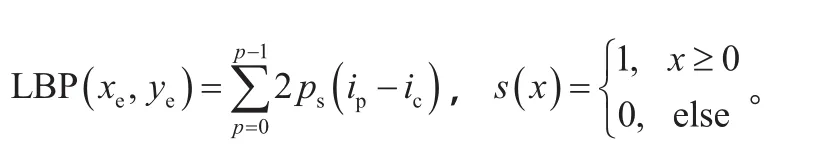
(4)將得到的每個cell的統計直方圖連接成為一個特征向量,即整幅圖的LBP紋理特征向量。
圖6所示為本文模型使用LBP求缺陷位置的流程。
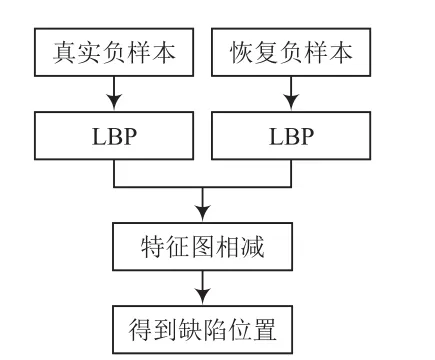
圖6 利用LBP求缺陷位置的流程
2 訓練策略
2.1 訓練模塊
在訓練過程中,輸入訓練集中給定的正樣本,在正樣本上人工構建缺陷,形成缺陷樣本。然后將缺陷樣本放入自動編碼器中訓練其修復能力。本次實驗使用“征圖杯”人工智能大賽數據來測試實驗模型的性能,數據集為平坦區下的缺陷數據集與非缺陷數據集。其中,訓練集全為正樣本,測試集既有負樣本也有正樣本。訓練流程如圖7所示,使用自構建負樣本訓練自動編碼器的效果如圖8所示。
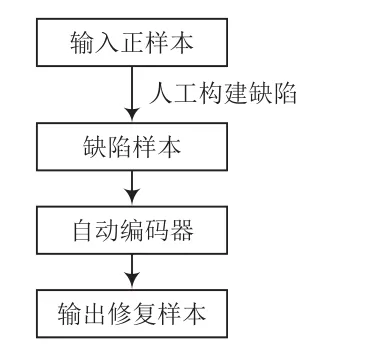
圖7 訓練流程

圖8 使用自構建負樣本訓練自動編碼器的效果
2.2 測試模塊
測試過程中,將測試圖片真實負樣本輸入自動編碼器中,得到生成的修復樣本(若判別為正樣本則直接輸出),由于還原的圖片細節信息存在一些錯誤,因此不應直接將還原圖片與原始圖片進行分割。使用LBP算法進行特征提取,然后在每個像素周圍搜索最匹配的像素。LBP算法是一種非參數算法,具有光不變性特征,適用于密集點環境。獲取有缺陷圖片的步驟:通過LBP算法對真實負樣本和修復樣本進行處理,設得到的特征圖為x和y。對于x的每個像素點,在y的對應位置搜索最近的特征值點,該點作為匹配點的像素點。得到2個匹配點特征值之差的絕對值,獲得的值越小,該點成為缺陷的可能性就越低。使用固定閾值二值化進行處理[9],找到缺陷的位置。測試流程如圖9所示,測試效果如圖10所示。
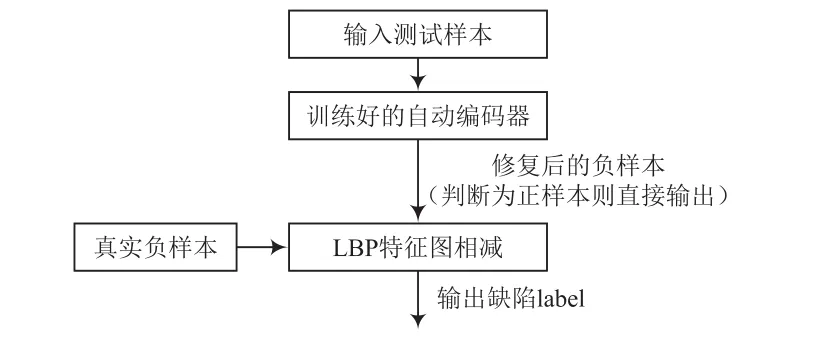
圖9 測試流程

圖10 測試效果
3 實驗結果分析
本實驗基于Keras深度學習框架,采用Python語言,選擇首屆“征圖杯”校園機器視覺人工智能大賽的初賽A榜數據集[10],在只使用給定正樣本數據集訓練的情況下,檢測出給定正樣本與負樣本混合的測試集缺陷樣本。實驗將同時使用本文提出的網絡模型與傳統的圖像邊緣檢測(使用Sobel算子)加填充的方法對缺陷區域進行檢測,對比模型的效果優劣。數據信息見表1所列。結果對比如圖11所示。

表1 數據信息

圖11 結果對比
從測試模塊中得到的效果圖像結果可以看出,我們的模型對于缺陷區域檢測的檢測精度較傳統的檢測方法更高。此外,分別計算2個模型測試得到的缺陷標簽圖與缺陷真實標簽的交并比和漏檢率與過檢率之和,比較2種模型的優劣。標簽對比結果如圖12所示。測試結果比較見表2所列。

圖12 標簽對比結果
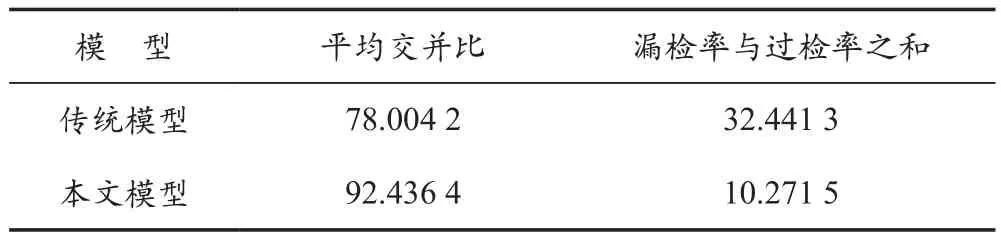
表2 測試結果比較 %
實驗表明,在只有正樣本作為訓練集的情況下,我們的模型與傳統方法相比,在缺陷區域檢測精度上有很大優勢。可以看出,對于傳統的邊緣檢測加填充的方法,樣本分類存在很多缺點,自動編碼器與LBP結合的模型效果更好。
4 結 語
本文提出的基于正樣本的產品缺陷檢測方法對于只有正樣本作為訓練集且背景較平坦的缺陷檢測有著不錯的效果,該方法無需手動設置標簽,無需大量負樣本訓練,在缺少負樣本的情況下缺陷檢測精度和效率更高。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
