基于無人機(jī)圖像的行人重識(shí)別技術(shù)
2021-08-04 01:58:34張俊凱
數(shù)字通信世界 2021年7期
張俊凱
(中國(guó)電子科技集團(tuán)公司第五十四研究所,河北 石家莊 050081)
0 引言
隨著電子信息技術(shù)的飛速發(fā)展,無人機(jī)巡邏安全監(jiān)控系統(tǒng)作為屬于城市安防工程的重要組成部分,受到了越來越多的重視。目前,無人機(jī)巡邏安全監(jiān)控系統(tǒng)通常應(yīng)用于道路、廣場(chǎng)等公共場(chǎng)合,已經(jīng)對(duì)維護(hù)公共安全、解決取證困難、協(xié)助公安部門破案提供了極大幫助。在無人機(jī)巡邏安全監(jiān)控系統(tǒng)中,行人監(jiān)控和危險(xiǎn)分子識(shí)別是一個(gè)重要的組成部分,行人監(jiān)控能夠?qū)υ斐尚淌掳讣南右扇诉M(jìn)行追蹤,還可以協(xié)助進(jìn)行走失人員的查找[1]。
傳統(tǒng)對(duì)嫌疑目標(biāo)的搜索方案主要是通過調(diào)集警員觀看大量的監(jiān)控視頻進(jìn)行人工比對(duì)。一方面,耗費(fèi)的人力成本越來越高。其次,傳統(tǒng)人工比對(duì)的方式獲得的識(shí)別結(jié)果受人本身因素影響大。行人重識(shí)別技術(shù)正是為了解決這個(gè)問題而提出的[2]。行人重識(shí)別即在行人檢測(cè)的基礎(chǔ)上,對(duì)行人進(jìn)行進(jìn)一步識(shí)別以判斷其身份的技術(shù)[3-4]。行人重識(shí)別根據(jù)從輸入的目標(biāo)行人圖像提取到的特征,在無人機(jī)巡邏安全監(jiān)控系統(tǒng)中自動(dòng)查找出該目標(biāo)行人的其他圖像[5-7]。其針對(duì)實(shí)際場(chǎng)景中行人普遍都處于運(yùn)動(dòng)過程且受到視角變化、行人姿態(tài)變化、攝像機(jī)低分辨率、目標(biāo)遮擋以及光照條件變化等因素的影響難以進(jìn)行人臉比對(duì)的場(chǎng)景[7-8]。
本文將基于基礎(chǔ)卷積操作的輕量化方法,進(jìn)行基礎(chǔ)模塊的多層級(jí)多視野架構(gòu)設(shè)計(jì),使用整體結(jié)構(gòu)搜索設(shè)計(jì)技術(shù),完成總體結(jié)構(gòu)設(shè)計(jì),實(shí)現(xiàn)無人機(jī)視角下的行人重識(shí)別技術(shù)。
1 行人重識(shí)別技術(shù)
1.1 基礎(chǔ)卷積操作的輕量化方法
針對(duì)傳統(tǒng)3x3卷積結(jié)構(gòu)運(yùn)算量大的問題,對(duì)卷積結(jié)構(gòu)進(jìn)行改進(jìn),在傳統(tǒng)的卷積結(jié)構(gòu)中,每個(gè)輸入通道都通過一個(gè)卷積算子和所有輸出通道進(jìn)行信息交互。對(duì)傳統(tǒng)卷積結(jié)構(gòu)進(jìn)行改進(jìn),如圖1所示:
針對(duì)每個(gè)輸入特征通道,圖1中的結(jié)構(gòu)利用N個(gè)K×K卷積核進(jìn)行特征提取,由于這些卷積核是線性相關(guān)的,因而這種冗余會(huì)占用大量的存儲(chǔ)空間,并耗費(fèi)巨大的運(yùn)算量。在圖1的結(jié)構(gòu)中對(duì)每組N個(gè)K×K卷積核進(jìn)行主成分分析,提取出不相關(guān)的主成分,將模型進(jìn)行充分的精簡(jiǎn)。具體操作方法是,將每個(gè)輸入通道對(duì)應(yīng)的維度為N×K×K的卷積參數(shù)表示為G個(gè)K×K卷積核的線性組合,G為主成分的數(shù)量,線性組合的實(shí)現(xiàn)方式為1×1卷積。將輸入的M個(gè)通道分為M組,每組有G個(gè)獨(dú)立的卷積核,并用1×1卷積將其線性組合成N個(gè)K×K卷積核。
精簡(jiǎn)后模型的總計(jì)算量為
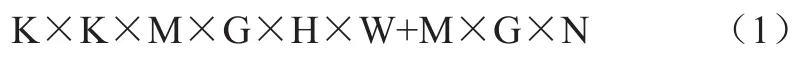
深度可分離卷積相對(duì)傳統(tǒng)卷積的計(jì)算量
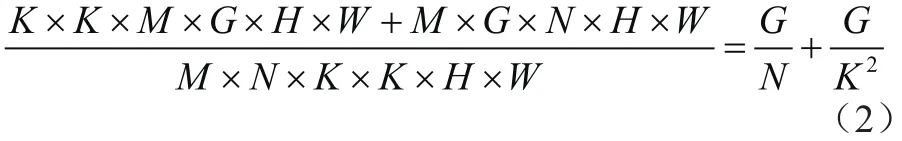
通常情況下,G取1至3,因此運(yùn)算量能夠得到極大的精簡(jiǎn)。圖1中的結(jié)構(gòu)被用來建立整個(gè)模型的基礎(chǔ)計(jì)算單元,如圖2所示:
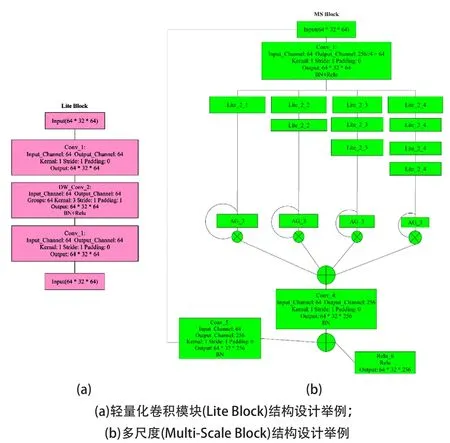
圖2 重識(shí)別模型的計(jì)算模塊
圖2(a)所示為輕量化卷積模塊Lite,其首先通過1×1卷積對(duì)輸入特征通道進(jìn)行信息融合,接下來利用1中的K×K卷積進(jìn)行特征提取,最終利用1×1卷積進(jìn)行進(jìn)一步信息融合,獲得輸出。圖2(b)是利用多通道進(jìn)行多層級(jí)信息處理的計(jì)算架構(gòu),其中每一路包含不同數(shù)量的Lite模塊,不同分支能夠提取不同層次的圖像特征。每個(gè)分支的最后利用聚合模塊(Aggregation Block,AG)將不同通道的特征分別進(jìn)行加權(quán)。AG模塊的結(jié)構(gòu)由一個(gè)全局池化層和兩個(gè)全連接層組成,如圖3所示,全局池化層融合各個(gè)特征通道的空間信息,后續(xù)的兩個(gè)全連接神經(jīng)網(wǎng)絡(luò)層負(fù)責(zé)對(duì)池化層的輸出進(jìn)行信息整合,最終獲得不同特征通道的權(quán)重,并將計(jì)算出的權(quán)重對(duì)相應(yīng)特征通道進(jìn)行加權(quán)。圖2(b)中四個(gè)通道加權(quán)后的特征在級(jí)聯(lián)之后利用1×1卷積層進(jìn)行整合,獲得輸出特征。
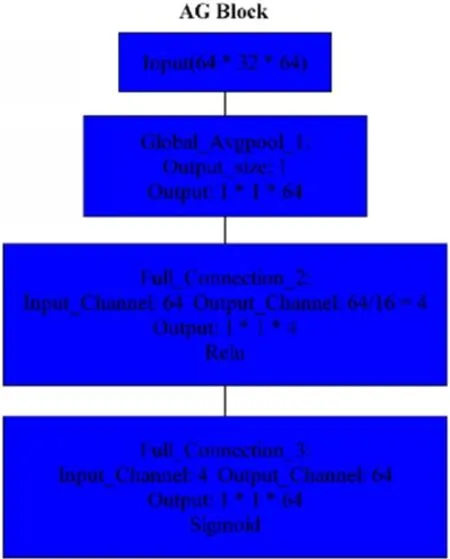
圖3 級(jí)聯(lián)模塊(AG Block)組成結(jié)構(gòu)和原理說明
1.2 整體模型結(jié)構(gòu)
在進(jìn)行整體結(jié)構(gòu)設(shè)計(jì)之前,首先考慮引入歸一化模塊,降低真實(shí)世界圖像在風(fēng)格、光照、環(huán)境、相機(jī)位置等方面的變化帶來的影響。由于需要遍歷的模型較多,采用One-Shot NAS(Neural Architecture Search)方法,將所有候選結(jié)構(gòu)以0-1編碼方式集成到一起再進(jìn)行搜索。在圖4中,圖4(a)是一個(gè)簡(jiǎn)單的鏈?zhǔn)缴窠?jīng)網(wǎng)絡(luò),如果將其每一層可以選擇的操作算子進(jìn)行限制,例如限制為只能從三種操作算子之一進(jìn)行選取,而在圖4(b)中所表示的網(wǎng)狀網(wǎng)絡(luò)就是代表這一簡(jiǎn)單鏈?zhǔn)缴窠?jīng)網(wǎng)絡(luò)的超網(wǎng)絡(luò)。每一個(gè)合法的鏈?zhǔn)缴窠?jīng)網(wǎng)絡(luò)都是這一超網(wǎng)絡(luò)的子圖。

圖4 One-Shot 架構(gòu)搜索方法原理示意
One-Shot的模型設(shè)計(jì)過程分為三個(gè)階段:第一階段,根據(jù)搜索空間 訓(xùn)練權(quán)重為W的超網(wǎng)絡(luò)S,W中既包含卷積權(quán)重,也包含0-1編碼的結(jié)構(gòu)信息,如果某一候選結(jié)構(gòu)訓(xùn)練后編碼為0,則此結(jié)構(gòu)不包含在最優(yōu)模型中。訓(xùn)練過程描述為:
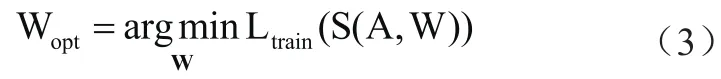
其中Ltrain()為目標(biāo)函數(shù),其隨著模型精度提升而降低,隨著模型復(fù)雜度降低而降低,當(dāng)精度和復(fù)雜度達(dá)到最佳平衡時(shí),Ltrain()數(shù)值最低。
最終模型結(jié)構(gòu)設(shè)計(jì)如圖5所示:

圖5 行人重識(shí)別模型總體結(jié)構(gòu)
模型輸入為RGB圖像中的行人區(qū)域,針對(duì)每個(gè)區(qū)域輸出一個(gè)長(zhǎng)度為512的特征向量,模型分為四個(gè)串行階段,每個(gè)階段按照統(tǒng)一分辨率處理圖像,并由普通卷積層與利用NAS方法優(yōu)化獲得的多個(gè)模塊組合而成,整個(gè)模型中共計(jì)有6個(gè)NAS優(yōu)化獲得的模塊。由于在搜索過程中兼顧了精度和運(yùn)算復(fù)雜度的考量,最終模型針對(duì)輸入尺寸128*64的浮點(diǎn)操作數(shù)為0.96GFlops,能夠在常見嵌入式芯片上達(dá)到40fps以上的理論計(jì)算量。
2 實(shí)驗(yàn)
2.1 測(cè)試指標(biāo)說明
指標(biāo)包含Rank-n(n=1,2,5,10,15…)和mAP(mean Average Precision)。由于重識(shí)別任務(wù)類似于分類任務(wù),模型對(duì)每個(gè)輸入行人區(qū)域都會(huì)輸出一系列概率值,對(duì)應(yīng)于該行人屬于不同身份的概率。針對(duì)某一個(gè)行人目標(biāo),如果模型預(yù)測(cè)的其最可能屬于的n個(gè)身份中包括該人的真實(shí)身份,則該人的Rank-n對(duì)應(yīng)的精度為100%。通過將所有測(cè)試行人的指標(biāo)進(jìn)行平均可獲得該數(shù)據(jù)集的Rank-n對(duì)應(yīng)的精度。精度隨Rank變化的曲線為CMC(Cumulative Matching Characteristics)曲線。
mAP是測(cè)試集中所有輸入行人的AP(Average Precision)的平均值,而每個(gè)行人的AP又指Precision(準(zhǔn)確率)的平均值。
2.2 測(cè)試結(jié)果
由于雇傭演員拍攝成本較高,因而拍攝場(chǎng)景中行人目標(biāo)較少(少于50人),為了更好的反映算法效果,在公開的大數(shù)據(jù)集(包含超過1000個(gè)行人身份)上進(jìn)行測(cè)試。數(shù)據(jù)集中包含1501個(gè)行人身份和32688張圖像,并充分涵蓋了場(chǎng)景的變化、尺度、遮擋以及人數(shù)密集等會(huì)對(duì)識(shí)別效果產(chǎn)生影響的因素。在Rank-1,Rank-5,Rank-10,Rank-20下對(duì)模型進(jìn)行測(cè)試,并求測(cè)試數(shù)據(jù)集中的mAP數(shù)值,結(jié)果圖6所示:

圖6 行人重識(shí)別測(cè)試結(jié)果
測(cè)試數(shù)據(jù)集中的mAP數(shù)值為75.0%,Rank-1為91.2%,Rank-5為96.6%,Rank-10為97.9%,Rank-20為98.5%,顯著高于當(dāng)前研究現(xiàn)狀。
3 結(jié)束語
本文設(shè)計(jì)的基于無人機(jī)圖像的行人重識(shí)別技術(shù)基于基礎(chǔ)卷積操作的輕量化方法,設(shè)計(jì)了一種基礎(chǔ)模塊的多層級(jí)多視野架構(gòu),使用了整體結(jié)構(gòu)搜索設(shè)計(jì)技術(shù),完成的總體結(jié)構(gòu)設(shè)計(jì)實(shí)現(xiàn)了無人機(jī)視角下的行人重識(shí)別技術(shù)。實(shí)驗(yàn)證明,本文算法在無人機(jī)視角下的圖像中,克服了攝像頭位置較高、視角較偏的難題,獲得了較好的行人重識(shí)別效果。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學(xué)評(píng)論(2021年2期)2021-08-22 01:53:34
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
影視與戲劇評(píng)論(2016年0期)2016-11-23 05:26:01
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
