基于Gecko瀏覽器內核的谷歌翻譯爬蟲
2021-08-06 08:25:36李健
現代計算機 2021年18期
李健
(戰略支援部隊信息工程大學,洛陽471003)
0 引言
網絡爬蟲是按照一定規則自動獲取Web信息資源的計算機程序[1-2]。根據目標資源的位置不同,網絡爬蟲可以分為淺層爬蟲和深層爬蟲。通過超鏈接能夠直接到達的為淺層數據,需要用戶登錄、提交表單、異步加載等操作才能獲得的為深層數據[3-4]。研究發現,Web中的深層數據量遠遠超過淺層數據[5-6],因此深層爬蟲就顯得十分重要。目前,異步加載技術廣泛使用,這給網絡爬蟲的開發帶來一些困難。對此,可采用模擬瀏覽器的方法進行采集——讓瀏覽器內核去處理那些復雜的技術細節,爬蟲只需要模擬用戶操作,等待目標數據返回[7-9]。在爬取過程中,可通過DOM路徑實現對元素的定位和數據的抽取[10-12]。
隨著人工智能技術的發展,機器翻譯的準確率也不斷提高,很多互聯網公司(如谷歌、百度、微軟等)都提供了在線翻譯服務。對于普通用戶來說,網頁翻譯是最主要的服務形式,而且是完全免費的。網頁翻譯雖然免費,但是往往會限制單次翻譯的字數。對于少量翻譯任務,我們可將原文復制到翻譯頁面就可以獲取翻譯結果;但對于較大規模的翻譯任務,若仍采用手動方式(逐段復制粘貼)則顯得十分低效。對此,可以采用“多次少取”的方式解決大規模語料的自動翻譯問題。本文將設計并實現一個基于Gecko瀏覽器內核的翻譯爬蟲——借助“谷歌翻譯頁面”實現自動批量翻譯。
1 相關技術
1.1 瀏覽器工作原理
網頁瀏覽器(Web Browser)簡稱瀏覽器,是一種用于檢索并展示萬維網信息資源的應用程序。用戶所看到的網頁都是經過瀏覽器解析、渲染后呈現出的結果,而并非原始網頁數據。瀏覽器的核心功能就是解析網頁,解析對象主要包括HTML、CSS和JavaScript,分別對應網頁的內容、樣式和行為。瀏覽器解析網頁的基本過程如圖1所示[13]。
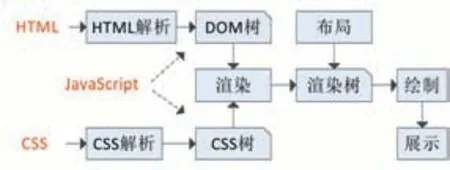
圖1 瀏覽器解析網頁的過程
資源加載后,瀏覽器會將HTML數據解析成DOM樹,將CSS數據解析成CSS規則樹,還可以通過執行JavaScript代碼對它們進行操作。解析完成以上對象,瀏覽器引擎通過DOM樹和CSS規則樹來構造渲染樹(Render Tree),結合其他資源最終生成頁面展示效果。
1.2 常見瀏覽器內核
瀏覽器內核是指瀏覽器的核心部件,主要包括頁面渲染器和JS解析器。頁面渲染器負責把數據轉換為用戶在屏幕所看到的樣式,JS解析器負責解釋和執行網頁中的JS代碼[14]。表1列出了常見瀏覽器內核[15-18]。
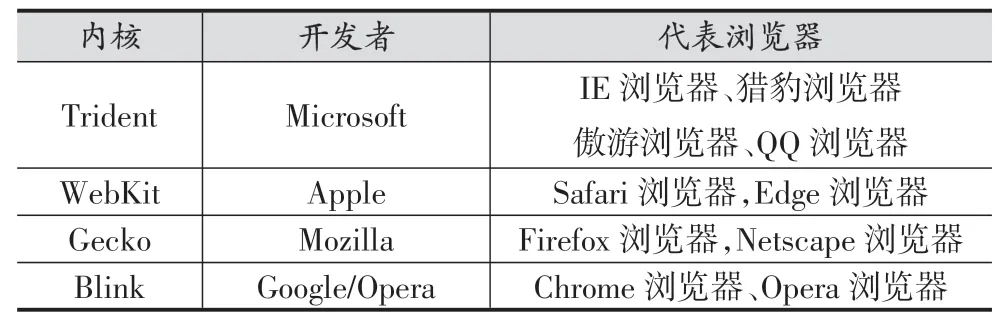
表1 常見瀏覽器內核
Trident是由微軟公司開發的瀏覽器內核,隨Internet Explorer 4.0首次發布(也稱IE內核)。Trident目前仍然是主流的瀏覽器內核之一,并被廣范應用于其他非IE瀏覽器。WebKit是由蘋果公司開發維護的開源瀏覽器內核,所包含的WebCore引擎和JSCore引擎都是從自由軟件衍生而來。Chrome和Opera瀏覽器早期也曾采用WebKit內核,由于某些原因Google公司從WebKit中分支出自己的Blink內核,隨后Opera公司也宣布將轉向Blink內核。Gecko是一個能夠跨平臺使用開源項目,該內核最早由Netscape公司開發,現在由Mozilla基金會維護[19]。
1.3 使用Gecko內核
GeckoFx是對Gecko內核的.NET封裝,提供完善的編程接口,這使得.NET程序員可以在WinForm或WFP程序中方便地使用Gecko內核。在Visual Studio中通過NuGet包管理器可直接安裝GeckoFx。
在DOM標準下,HTML文檔中的每個成分都是節點:大到整個HTML文檔,小到每個HTML標簽,甚至底層的純文本都被看作一個結點[20]。GeckoFx核心類之間的關系如圖2所示。其中實線表示繼承關系,虛線表示包含關系。
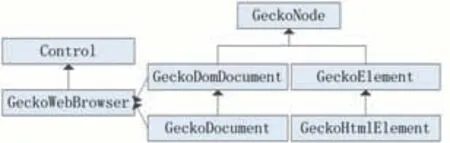
圖2 GeckoFx核心類
在GeckoFx框架中,GeckoNode表示所有DOM結點的基類,GeckoDomDocument用于描述DOM文檔,GeckoDocument用于描述Html文檔,Gecko Element用于描述DOM元素,Gecko Html Element用于描述HTML標簽元素。Gecko Web Browser是一個Web瀏覽器控件(可直接顯示在WinForm窗體中),其DomDocument和Document屬性分別屬于GeckoDomDocument和Gecko Document類型。通過上述對象,可以實現頁面的加載和導航,元素的查詢和修改。
2 爬蟲設計
2.1 系統框架
為了便于描述,我們將任務簡化為對中文詞表的翻譯,每次提交一個詞條進行翻譯,翻譯完成后可導出雙語詞表。并具體規定如下:中文詞表按行存放于文本文件中(對應全部翻譯任務),每次提交一行文本進行翻譯(對應單次翻譯任務),翻譯結果以Excel格式導出。翻譯爬蟲的總體架構如圖3所示。
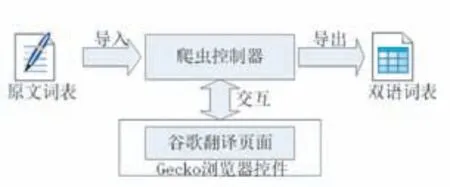
圖3 翻譯爬蟲架構
2.2 工作流程
根據上述思路,爬蟲工作流程如圖4所示:首先使用瀏覽器控件加載翻譯頁面;然后提示用戶選擇并導入中文詞表;每次從待翻譯詞表中取出一個詞條,復制到翻譯網頁的原文輸入框,等待翻譯結果返回,從譯文輸出框讀取結果;若翻譯任務全部完成則導出結果,否則繼續翻譯下一詞條。
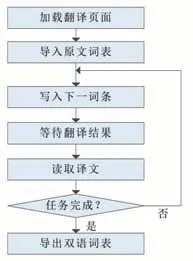
圖4 翻譯爬蟲工作流程
2.3 爬蟲界面
爬蟲界面如圖5所示:使用分隔容器(SplitContain?er)將主窗體分為左右兩個區域,左側為用戶操作區,包括兩個按鈕(導入、導出)和一個DataGridView控件;右側是翻譯頁面加載區,GeckoWebBrowser控件充滿整個區域。
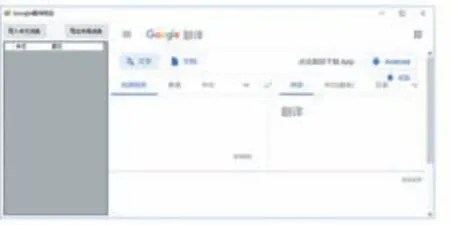
圖5 翻譯爬蟲主界面
3 爬蟲實現
我們在.NET平臺下使用C#語言編寫程序,實現了谷歌翻譯爬蟲的全部功能。下面將介紹關鍵模塊的實現。
3.1 加載頁面
爬蟲啟動后,首先需要初始化Gecko運行環境,才能使用GeckoWebBrowser控件加載頁面。其主要代碼如下:

上述代碼定義了一個GeckoWebBrowser類型的成員變量(browser),表示Gecko瀏覽器控件;頁面跳轉后為瀏覽器控件添加Document Completed事件,以保證網頁加載完畢才能導入詞表。
3.2 單次翻譯
翻譯爬蟲的關鍵步驟就是要模擬用戶操作,在瀏覽器頁面中完成原文的輸入和譯文的讀取。通過Firefox開發者工具箱查看頁面元素(如圖6圖所示),可以發現Google翻譯頁面的原文輸入框為一個