面向低延時目標檢測的FPGA神經(jīng)網(wǎng)絡(luò)加速器設(shè)計
2021-08-06 08:25:44鄭思杰李杰賀光輝
現(xiàn)代計算機 2021年18期
鄭思杰,李杰,賀光輝
(1.上海交通大學電子信息與電氣工程學院,上海200240;2.上海航天測控通信研究所,上海201109)
0 引言
隨著大量可信數(shù)據(jù)的積累,以數(shù)據(jù)為研究基礎(chǔ)的深度神經(jīng)網(wǎng)絡(luò)在目標檢測分類領(lǐng)域獲得了巨大成功[1],在智能駕駛和目標追蹤等領(lǐng)域得到了廣泛應(yīng)用。然而,隨著檢測性能的提升,檢測網(wǎng)絡(luò)的層數(shù),參數(shù)規(guī)模和計算復雜度大幅增加。這對硬件的計算性能和存儲開銷提出了新的挑戰(zhàn)。在實時性要求更高的應(yīng)用中,傳統(tǒng)中央處理器的計算架構(gòu)無法滿足實時計算的需求,需要硬件加速器加速計算,從而降低延時。
圖形處理器具有更高吞吐性能[2],但功耗較大甚至達到100 W以上[3]。專用集成電路具有更高的能效,例如寒武紀Cambricon-x[4]芯片只需954 mW就能實現(xiàn)544 GOPS的性能。但專用集成電路研發(fā)成本高,研發(fā)周期長,實現(xiàn)后難以修改,難以適應(yīng)快速更新的神經(jīng)網(wǎng)絡(luò)算法。而現(xiàn)場可編程門陣列(Field Programmable Gate Array,F(xiàn)PGA)則以其可重構(gòu)、較高的能效比、較低的開發(fā)成本成為神經(jīng)網(wǎng)絡(luò)加速器的最佳選擇[5-6]。
現(xiàn)有神經(jīng)網(wǎng)路硬件加速器主要從網(wǎng)絡(luò)模型和硬件結(jié)構(gòu)設(shè)計等方面進行優(yōu)化設(shè)計。定點量化是網(wǎng)絡(luò)模型設(shè)計的常用方法[7],但對YOLO等新穎的復雜深度網(wǎng)絡(luò)算法而言,過小的位寬量化容易造成較大的性能損失[8]。在硬件設(shè)計方面,采用稀疏計算結(jié)構(gòu)的STICKER[9]架構(gòu)能夠支持多種稀疏度的自動匹配,從而實現(xiàn)高能效的電路設(shè)計。然而該架構(gòu)采用編碼的結(jié)構(gòu)實現(xiàn)零值過濾,具有較大的分布式存儲開銷,限制了數(shù)據(jù)的并行計算。DNNBuilder[10]則是采用了一種多計算引擎的架構(gòu)設(shè)計,并通過設(shè)計空間探索優(yōu)化FPGA的資源分配,但這種多計算引擎架構(gòu)的延時會隨著網(wǎng)絡(luò)層數(shù)的增加而增加,更適合小規(guī)模網(wǎng)絡(luò)實現(xiàn)。
盡管現(xiàn)有設(shè)計通過降低計算復雜度和提高硬件利用率等方式提高了神經(jīng)網(wǎng)絡(luò)加速器的能效,但當前研究對延時的關(guān)注較少。然而對于實時性要求高的應(yīng)用,低延時也是需要考量的重要指標。為此本文提出了一種基于高并行卷積稀疏計算的低延時神經(jīng)網(wǎng)絡(luò)加速器架構(gòu),能夠以更高的面積效率實現(xiàn)低延時的目標檢測網(wǎng)絡(luò)加速。
1 目標檢測網(wǎng)絡(luò)及卷積稀疏計算分析
1.1 目標檢測網(wǎng)絡(luò)
目標檢測對系統(tǒng)實時性和算法檢測的準確性都具有更高要求。為了達到更好的檢測分類效果,YOLOv3采用了DarkNet-53網(wǎng)絡(luò)作為基準網(wǎng)絡(luò),整體架構(gòu)如圖1所示。相比傳統(tǒng)的目標檢測網(wǎng)絡(luò)結(jié)構(gòu),YOLOv3增加了殘差結(jié)構(gòu)加強其特征提取能力,并引入跨層連接結(jié)構(gòu)加強深層網(wǎng)絡(luò)與淺層網(wǎng)絡(luò)的數(shù)據(jù)依賴關(guān)系。
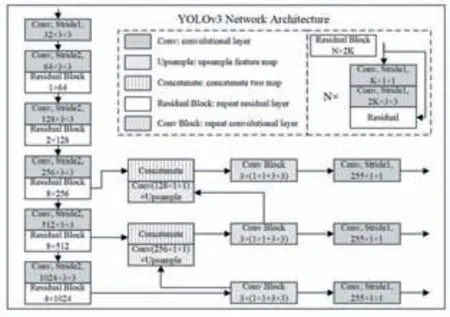
圖1 YOLOv3網(wǎng)絡(luò)結(jié)構(gòu)
YOLOv3是一個全卷積網(wǎng)絡(luò),采用了步長不為1的卷積網(wǎng)絡(luò)來代替池化層,既起到降采樣的效果,又降低了池化層帶來的梯度負面影響。而且,YOLOv3實現(xiàn)了多尺度融合的類別預(yù)測,通過上采樣和特征圖拼接等方法,共進行了三次不同尺度的檢測。在網(wǎng)絡(luò)中使用上采樣的原因是網(wǎng)絡(luò)越深,特征提取和表達效果越好,進而能夠有效解決小目標識別準確度低的問題。YOLOv3整個網(wǎng)絡(luò)包括75個卷積層,2次上采樣,2次張量拼接,2次跨層連接,23個殘差結(jié)構(gòu),激活層、歸一化層和檢測層,最終輸出分別對應(yīng)小尺寸目標、中尺寸目標、大尺寸目標,三級輸出之間通過跨層張量拼接和上采樣層進行連接。
1.2 卷積稀疏計算的資源平衡問題
為了實現(xiàn)卷積的稀疏計算,很多額外的硬件單元會配合乘法器進行零值的過濾以及有導向性的數(shù)據(jù)傳輸。表1展示了現(xiàn)有支持卷積稀疏計算的硬件加速器實現(xiàn)結(jié)果,從中可以看出單純的乘法計算單元并不是現(xiàn)有加速器實現(xiàn)的主要組成,反而是稀疏數(shù)據(jù)的判斷分發(fā)以及存儲單元占據(jù)了核心處理單元(Processing Element,PE)的主要開銷。
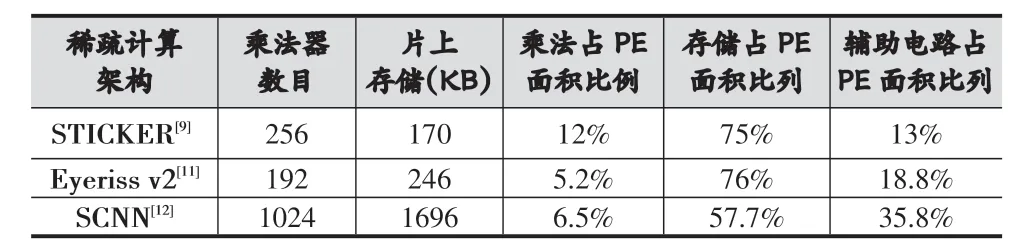
表1 不同稀疏計算架構(gòu)的面積比較
針對片上存儲,為了滿足稀疏計算的計算需求,現(xiàn)有設(shè)計通常會為每個乘法器設(shè)置分布式的緩存結(jié)構(gòu)。這種分布式存儲結(jié)構(gòu)并不利于FPGA的硬件實現(xiàn)。因為FPGA使用BRAM這種塊狀存儲結(jié)構(gòu),而BRAM數(shù)量有限且有位寬限制,這造成了傳統(tǒng)稀疏計算實現(xiàn)中,單一乘法器甚至需要多塊BRAM支持其稀疏計算。以VCU118開發(fā)板為例,該開發(fā)板僅含有6840個DSP計算資源和2160個36 Kb的BRAM存儲,兩者數(shù)量并不匹配,這限制了稀疏計算在FPGA上的高并行設(shè)計。
1.3 稀疏計算的硬件結(jié)構(gòu)和數(shù)據(jù)復用分析
現(xiàn)有稀疏計算實現(xiàn)大多都是基于編碼的數(shù)據(jù)方式,然而編碼的數(shù)據(jù)方式并不利于高并行的硬件設(shè)計。首先,編碼的結(jié)構(gòu)導致了PE存儲中開銷較大的分布式存儲結(jié)構(gòu)。其次,編碼結(jié)構(gòu)所需的PE輔助電路更加復雜。PE計算結(jié)構(gòu)在進行稀疏計算時,除了輸入非零數(shù)據(jù)還需要輸入數(shù)據(jù)對應(yīng)坐標,用于計算乘法輸出的數(shù)據(jù)對應(yīng)坐標。而且,編碼結(jié)構(gòu)需要實時的對輸出結(jié)果做非零值編碼,且編解碼的電路開銷隨乘法器數(shù)目增多而增多,這并不利于提高計算并行性。還有,編碼的方式對于步長不為1的卷積計算并不友好。最后,編碼的方式因為存在隨機性和網(wǎng)絡(luò)特異性,在存儲和數(shù)據(jù)傳遞上不一定存在優(yōu)勢。例如YOLOv3網(wǎng)絡(luò)的權(quán)重參數(shù)在剪枝后有30%稀疏度。假設(shè)采用神經(jīng)網(wǎng)絡(luò)常用的8 bit量化以及4 bit坐標,原來數(shù)據(jù)需要8N bit存儲,N為數(shù)據(jù)數(shù)目;編碼后需要( )
8+4×0.7N=8.4N bit存儲,存儲甚至有所增大,實際編碼開銷只會更大。
不同的卷積數(shù)據(jù)復用方式,對應(yīng)不同的卷積循環(huán)展開方式,最終決定了計算PE陣列的結(jié)構(gòu)。本文設(shè)計的數(shù)據(jù)復用包括權(quán)重復用,特征圖行方向數(shù)據(jù)復用以及特征圖列方向數(shù)據(jù)復用。尤其是特征圖的復用更能夠匹配不同規(guī)模的網(wǎng)絡(luò)層結(jié)構(gòu),利于數(shù)據(jù)并行。除此之外,還設(shè)置了輸入通道方向的計算并行。計算陣列的形式和數(shù)據(jù)復用方式如圖2所示。
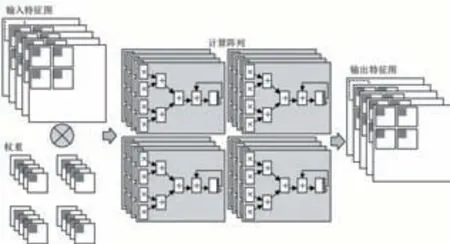
圖2 本文采用的數(shù)據(jù)復用和計算陣列排布
綜上,本文不會采用編碼的方式作為特征圖輸入及權(quán)重在存儲、數(shù)據(jù)傳輸以及卷積計算時的數(shù)據(jù)形式。該方式能夠簡化PE結(jié)構(gòu),支持更高并行的稀疏計算,并且通過設(shè)置大量數(shù)據(jù)復用,降低高并行數(shù)據(jù)計算所需要的高訪存位寬。
2 面向低延時目標檢測的加速器架構(gòu)設(shè)計
2.1 基于稀疏計算的低延時加速器整體架構(gòu)
本文設(shè)計的低延時神經(jīng)網(wǎng)絡(luò)加速器如圖3所示。其中,計算陣列是核心計算單元,由一系列能夠支持稀疏計算的PE基本單元組成。每個PE單元都會包含零值檢測單元,非零數(shù)據(jù)的先進先出存儲器(First Input First Output,F(xiàn)IFO),稀疏計算的負載平衡單元,卷積乘累加單元,數(shù)據(jù)截斷單元以及激活函數(shù)等硬件結(jié)構(gòu)。片上存儲分為特征圖和權(quán)重兩部分,都采用了多緩存塊的結(jié)構(gòu),從而保證能夠同時訪問計算陣列所需的并行數(shù)據(jù)。對內(nèi)數(shù)據(jù)交互單元和對外交互單元會控制數(shù)據(jù)的讀寫和搬運,根據(jù)卷積步長,卷積核尺寸,不同計算順序等因素對網(wǎng)絡(luò)計算進行控制。
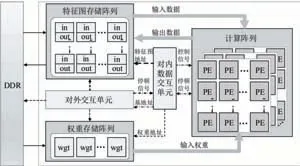
圖3 神經(jīng)網(wǎng)絡(luò)加速器頂層架構(gòu)
上述電路能夠支持不同尺寸,不同步長的卷積網(wǎng)絡(luò)運算。同時能夠支持殘差網(wǎng)絡(luò),特征圖拼接的跨層結(jié)構(gòu)、升采樣、激活函數(shù)、高并行稀疏計算等結(jié)構(gòu)。另外,模塊存在一定擴展性,可以根據(jù)算法需求增加和減少部分結(jié)構(gòu),從而適應(yīng)不同網(wǎng)絡(luò)結(jié)構(gòu)。
2.2 低存儲開銷的稀疏計算PE設(shè)計
設(shè)計的PE主要包含用于支持稀疏計算的零值檢測,替代分布式存儲結(jié)構(gòu)的小規(guī)模FIFO存儲以及計算單元,如圖4展示了沿著輸入特征圖單通道方向上計算PE。圖中輸入數(shù)據(jù)的數(shù)量是特征圖通道方向上并行傳遞數(shù)據(jù)的數(shù)量,同時也是PE中對應(yīng)輸入通道上設(shè)置并行乘法器數(shù)量的兩倍。在FIFO寫一側(cè),每個周期至少會有一個FIFO被寫入該周期接受到的非零值,如果非零值較多則會存儲多余的非零值等待下次傳遞的輸入,當非零值數(shù)量累計達到或超過兩個FIFO位寬時會一個周期同時寫兩個FIFO。如果FIFO滿則會暫停從存儲陣列中取數(shù)。通過以上結(jié)構(gòu)實現(xiàn)了非零元素的檢測和過濾,進而實現(xiàn)稀疏計算。
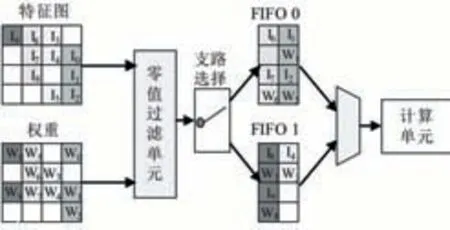
圖4 支持稀疏計算的PE結(jié)構(gòu)
在FIFO數(shù)據(jù)讀取側(cè),每兩個FIFO交替提供一個計算單元所需的非零數(shù)據(jù)。因為稀疏計算,不同計算單元在同一批次計算中,計算次數(shù)不同,主要體現(xiàn)在前置FIFO排空數(shù)據(jù)的時間不同。為了更高效地利用這些計算單元,當計算單元前置FIFO為空時,會自動從相鄰計算單元的前置FIFO取數(shù),幫助加速計算,如圖5所示。
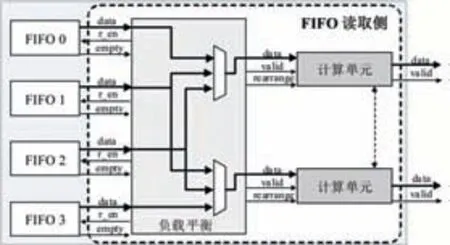
圖5 負載平衡模塊
2.3 高并行的存儲陣列結(jié)構(gòu)設(shè)計
高并行稀疏計算的另一重要組成部分是集中式片上存儲陣列結(jié)構(gòu)。存儲陣列結(jié)構(gòu)的設(shè)計是,高并行稀疏計算所需的高存儲位寬和FPGA相對集中式的BRAM存儲結(jié)構(gòu),兩者折中的結(jié)果。圖6展示了特征圖數(shù)據(jù)和權(quán)重參數(shù)在存儲陣列中的排布順序。
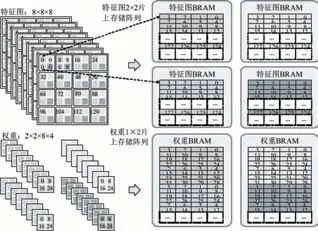
圖6 特征圖和權(quán)重在存儲陣列中的數(shù)據(jù)排布
在這種存儲形式下,數(shù)據(jù)交互需要提取出每個周期用到的特征圖數(shù)據(jù)并傳遞到指定位置的PE。圖7展示了3×3二維卷積網(wǎng)絡(luò)的實現(xiàn),設(shè)定網(wǎng)絡(luò)輸入10×10的特征圖,片上存儲陣列規(guī)模為5×5,每個存儲單元都存儲了4個數(shù)據(jù)。當卷積窗在滑動時,提供各PE所需數(shù)據(jù)的存儲地址,從存儲陣列中不同存儲地址取出對應(yīng)數(shù)據(jù),并按照PE計算的累加需求進行數(shù)據(jù)的重新排列和發(fā)送。利用存儲陣列的結(jié)構(gòu)能夠高效地對特征圖進行卷積窗滑動的計算。
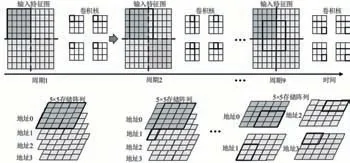
圖7 輸入特征圖數(shù)據(jù)的提取和重新排布示意圖
3 實驗結(jié)果
3.1 稀疏計算PE的資源開銷分析
為了驗證本文設(shè)計的稀疏計算PE資源開銷,利用文獻[13]FPGA歸一化資源開銷(Normalized Resource Consumption,NRC)評估方法,歸一化面積如(1)所示。
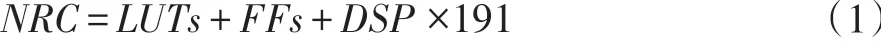
本設(shè)計PE的綜合結(jié)果如表2所示。表中FIFO采用分布式LUT存儲實現(xiàn)。可以看出,計算單元占據(jù)了設(shè)計PE的主要組成,比例達到了45.4%,存儲開銷僅有12.8%。這是因為在PE設(shè)計中大幅減小了分布式存儲開銷,更有利于FPGA資源調(diào)用和并行設(shè)計。
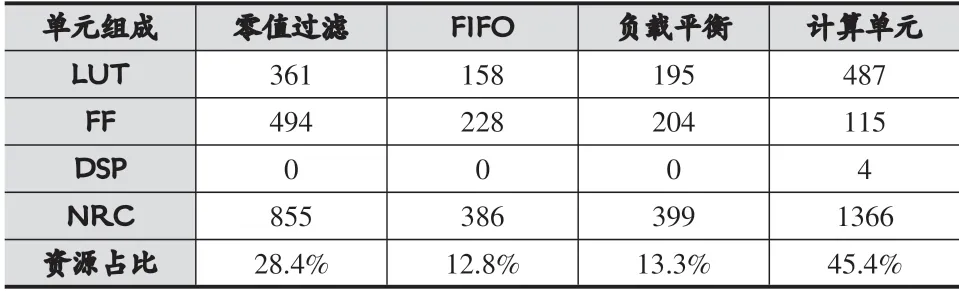
表2 本文提出的稀疏計算PE資源開銷
對比不同稀疏卷積設(shè)計實現(xiàn)的PE單元,結(jié)果如表3所示。其中,乘法占PE面積比例僅僅考慮了計算單元中的乘法單元面積,不考慮加法樹累加等結(jié)構(gòu)。相比其他稀疏架構(gòu),本文提出的PE單元有效提升了乘法的面積比例,縮小了PE使用的分布式存儲開銷,更有利于FPGA實現(xiàn)高并行的稀疏計算。
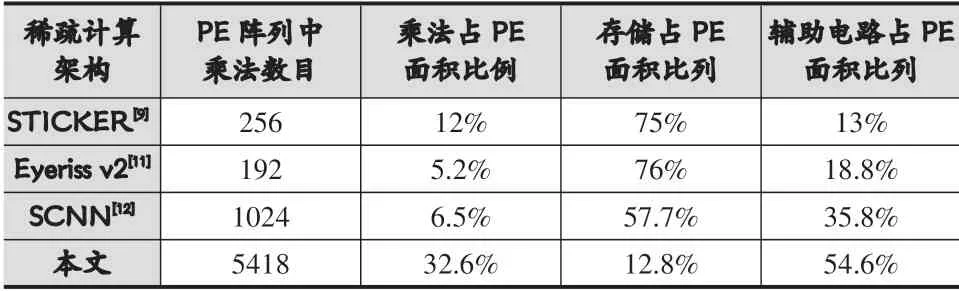
表3 稀疏計算PE的資源開銷對比
3.2 面向目標檢測網(wǎng)絡(luò)的實現(xiàn)和對比
考慮16bits×16bits的有符號數(shù)乘法器實現(xiàn)需要280個LUT[13]
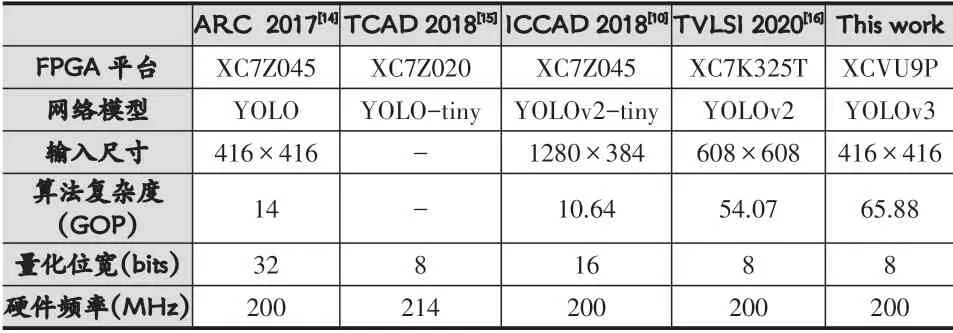
表4 YOLO網(wǎng)絡(luò)的FPGA實現(xiàn)對比
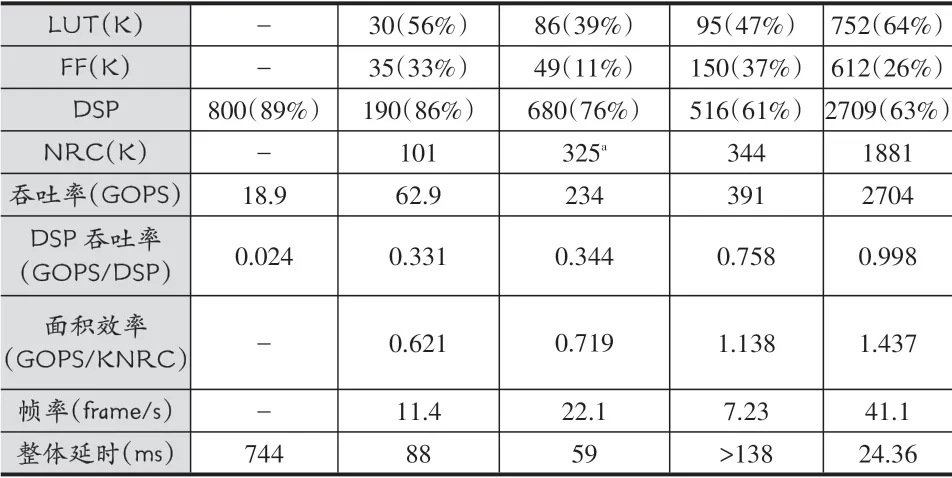
續(xù)表
本文基于Xilinx VCU118開發(fā)板實現(xiàn)YOLOv3網(wǎng)絡(luò),并配合軟件提取的權(quán)重以及每層網(wǎng)絡(luò)的指令進行測試。測試結(jié)果和權(quán)威會議及期刊上發(fā)表設(shè)計的對例如表4所示。從表中可以看出,多數(shù)設(shè)計采用了深度不深,結(jié)構(gòu)更為簡單的YOLO、YOLOv2甚至簡化的YOLO-tiny系列網(wǎng)絡(luò),而本設(shè)計針對深度更深,結(jié)構(gòu)更復雜,準確率更高的YOLOv3網(wǎng)絡(luò)進行了實現(xiàn)。相比其他設(shè)計,本設(shè)計提出的加速器硬件架構(gòu),能夠有效支持更大規(guī)模的卷積數(shù)據(jù)并行計算以及稀疏計算,也因此獲得了更高的吞吐性能和面積效率。通過增加數(shù)據(jù)復用以及稀疏計算有效提升了單DSP的吞吐性能。在歸一化面積效率方面,本設(shè)計相比文獻[10,15,16]分別有2.32、2.01、1.27倍增益。而文獻[10]采用的量化比特是16比特,當網(wǎng)絡(luò)量化為8比特時,其吞吐性能會有所提升。但是文獻[10]采用的是批處理的方式來提升其吞吐性能,對于8比特量化結(jié)果其延時性能不會有所提升。且文獻[10]采用的是多引擎加速架構(gòu),難以支持更多的層數(shù)和跨層連接的結(jié)構(gòu)。
4 結(jié)語
本文提出了一種面向低延時目標檢測的FPGA神經(jīng)網(wǎng)絡(luò)加速器架構(gòu)。通過更多的數(shù)據(jù)復用和優(yōu)化的高并行卷積稀疏計算,降低了稀疏計算PE中的分布式存儲開銷,提高計算的并行。通過設(shè)計集中式存儲陣列結(jié)構(gòu),支持高并行的卷積計算,能夠?qū)崿F(xiàn)存儲陣列和計算陣列之間非一一對應(yīng)的數(shù)據(jù)交互。FPGA實現(xiàn)結(jié)果顯示,與當前目標檢測的神經(jīng)網(wǎng)絡(luò)加速器設(shè)計相比,本文的加速器架構(gòu)能夠支持更復雜的YOLOv3網(wǎng)絡(luò),且具有1.27-2.32的歸一化面積效率提升以及更好的延時特性。
猜你喜歡
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
藝術(shù)啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
