一種新的選取K-means初始聚類中心算法
2021-08-06 08:26:08張嘉龍
現代計算機 2021年18期
關鍵詞:實驗
張嘉龍
(華南農業大學數學與信息學院,廣州510642)
0 引言
機器學習是目前非常熱門的一門學科,它包含多種快捷實用的算法,給人們帶來了極大的便利,其中包含的聚類算法是一種無監督的學習算法,K-means算法則是最常用的聚類算法之一。
K-means算法目前廣泛應用[1-4]于聚類劃分,是一種經典的聚類算法,但由于該算法選取初始聚類中心的隨機性,經常出現數據聚類不穩定的結果,且結果容易陷入局部最優。因此,研究一種具有穩定聚類效果和有較高準確率以及低迭代次數的聚類算法具有重要意義。
針對傳統的K-means聚類算法的初始聚類中心選取問題,本文借鑒文獻[5-7]所提出的相異度及相異度矩陣的概念,通過建立相異度矩陣,并計算總體平均相異度以及行平均相異度,同時構造集合S,通過類似Dijkstra算法的思想,隨相異度增長趨勢不斷遴選合適的樣本點進入集合S,最終通過對S內對應樣本點的屬性求平均得到K-means算法的初始聚類中心,隨后在數據集中刪除集合S內包含的樣本點,利用得到的新數據集重新執行算法,最終可以得到K個初始聚類中心,隨之采用K-means算法得到聚類結果。實驗表明,相比于傳統聚類算法,新的算法擁有穩定的聚類效果,且有較高的聚類準確率和較少的迭代次數,同時對比于文獻[8]和文獻[9]的算法所得結果,新算法在保持聚類結果準確率不變的情況下,迭代次數大幅下降。
1 新的初始聚類中心選擇算法
1.1 算法相關概念

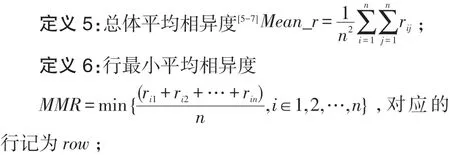
定義7:集合S={c1,c2,…,cn},表示遴選的第ci個樣本點的下標集合,i∈{1,2,…,n},其中ci為小于n的任意正整數,且集合中任意兩個元素之間互不相等,記RS為S中已選樣本點所對應的相異度矩陣的行組成的矩陣。

1.2 算法思想
設需要聚類的類別數為K,本文算法通過計算樣本點間的相異度,然后根據相異度建立相異度矩陣。同時,為了得到最密集的一群樣本點,首先計算相異度矩陣中每一行的平均值,并選取平均值最小的一行,將該行對應的樣本點作為起點,尋找離該樣本點最近的另外一個樣本點,即尋找相異度矩陣中該行非對角線上元素(對角線為該樣本點本身的相異度)的最小值,將該最小值對應的樣本點與最初的一個樣本點所對應的下標加入集合S。
然后借鑒Dijkstra算法的思想,再尋找離集合S中對應樣本點距離之和最近的下一個樣本點,同時為了讓集合S中的最終樣本點數量取得合適的值,該樣本點需與集合S中對應的任一樣本點的相異度不能超過總體平均相異度。按如上方法不斷遴選樣本點,最后得到飽和的集合S,將S中對應的所有樣本點的屬性取平均,該平均值即作為第一個初始聚類中心。
隨之將集合S內對應的樣本點從數據集X中刪除,得到新的數據集,根據新的數據集重新建立相異度矩陣,按相同的方法得到剩余的初始聚類中心,直到初始聚類中心個數達到K,然后采用K-means算法得到聚類結果。
1.3 算法步驟
遴選K個初始聚類中心的方法步驟:
(1)已選初始聚類中心個數記為num,num初始化為0;
(2)根據樣本集X建立相異度矩陣R,同時構造空集S;
(3)根據R計算總體平均相異度Mean_r以及各行平均相異度,找到行最小平均相異度MMR,并記錄其所在的行row;
(4)將R中對角線上的元素賦值為無窮;
(5)在Rrow中找到最小值rrowj,將下標row和j加入集合S,同時將R中的rrowj和rjrow兩個元素賦值為無窮,根據R和S建立矩陣RS;
(6)對RS中的每列,若該列任一元素的值均小于Mean_r,則對該列進行求和,若任一列中的任意一個值均不小于Mean_r或者S中的元素個數等于n,進入(7),否則,在所有進行求和的列當中找到和最小的列k,將k加入集合S,同時將R中的rxk和rkx均賦值為無窮,其中x∈S,根據R和S重建矩陣RS,重新執行(6);
(7)計算集合S中所有對應樣本點屬性的平均值,將該平均值作為下一個初始聚類中心,同時令num=num+1,若此時num==K,結束遴選算法,否則進入(8);
(8)將集合S中所對應的所有樣本點從數據集X中刪除,重新執行(2)。
根據以上方法步驟,可以得到K個初始聚類中心,然后調用K-means算法,得到聚類結果。
1.4 K-means算法思想
首先選取K個初始聚類中心(本文采用上述算法得到的初始聚類中心),計算每個樣本點到每個聚類中心的距離,將樣本點分到距離最近的聚類中心,形成K個簇。在每個簇當中,計算該簇中所有樣本點的平均值,以該值作為新的聚類中心,重新計算樣本點到新的聚類中心的距離并重新分配,直到新的初始聚類中心位置不再變化或變化小于某個閾值時停止算法,最終得到分類最佳的K類樣本點。
2 實驗結果
本文采用UCI數據集中的三種數據集進行實驗,分別為Iris、Wine、Seeds,其對應的屬性描述如表1所示。同時將新算法得到的實驗結果與傳統K-means算法、文獻[8]算法以及文獻[9]的算法得到的結果進行比較。
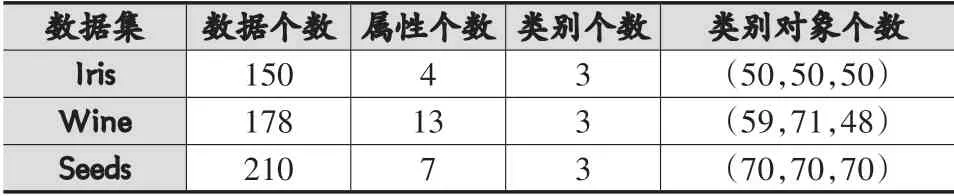
表1 數據集描述
由于K-means算法的不穩定性,本文實驗中將對其運行五次得到的結果取平均,以此與其他算法得到的結果進行比較。
運用不同的算法進行實驗,得到的實驗結果如表2-表4所示。
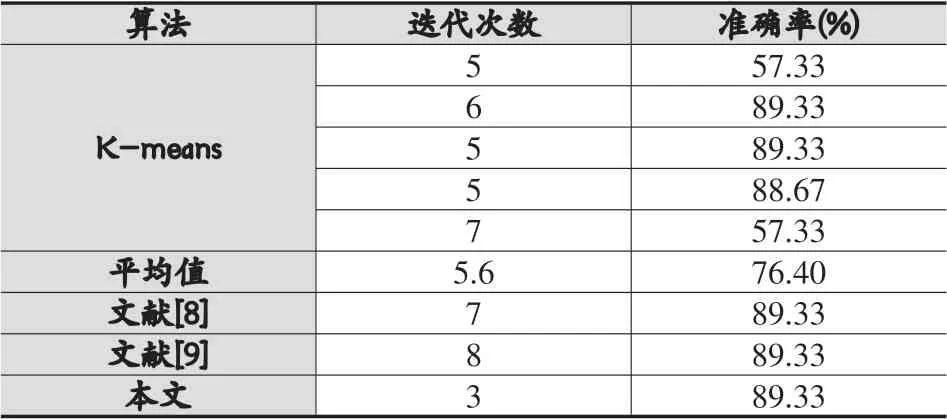
表2 Iris數據集實驗結果對比
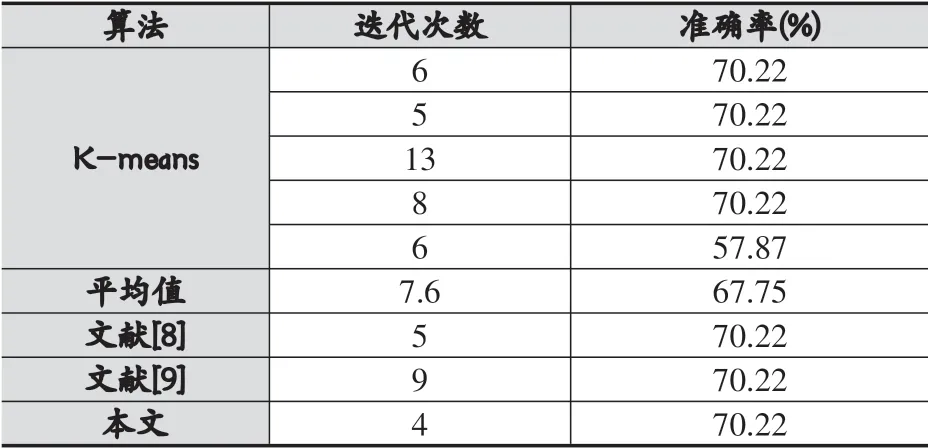
表3 Wine數據集實驗結果對比
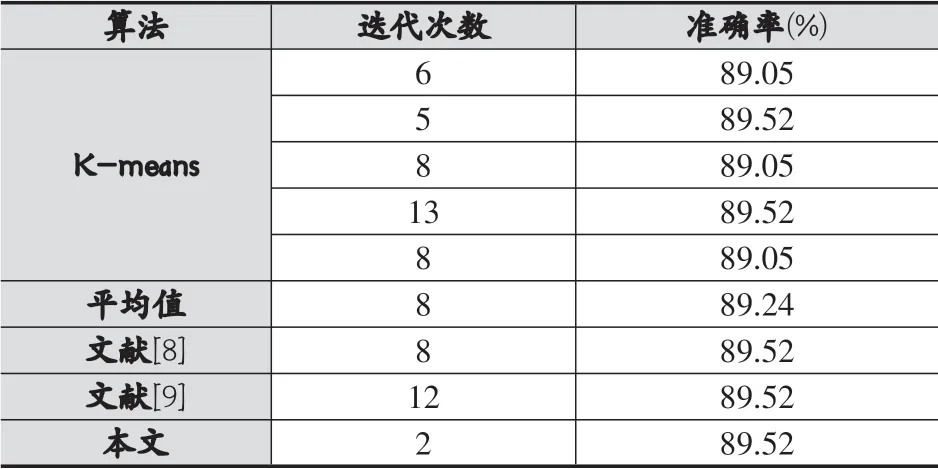
表4 Seeds數據集實驗結果對比
由表2-表4可以看出,相比于傳統的K-means算法,本文算法能夠得到穩定的聚類結果,同時在迭代次數上有明顯的下降,且準確率也較高,在Iris數據集中,迭代次數平均下降2.6次,準確率平均提高12.93%。在Wine數據集中,迭代次數平均下降3.6次,準確率提高2.47%。而在Seeds數據集中,平均迭代次數下降最多,為6次,且準確率也提升了0.28%。
而對比于文獻[8]和文獻[9]的算法,本文算法在保持準確率的情況下,迭代次數有較大的下降,特別是在Iris數據集和Seeds數據集上,對于Iris數據集,由原來的7次和8次下降到3次,而對于Seeds數據集,由原來的8次和12次下降到2次,下降的程度較大。
3 結語
本文針對傳統K-means算法聚類不穩定的缺陷,提出了一種新的算法,通過建立相異度矩陣,利用MM R和R E得到K個初始聚類中心。實驗結果表明,新的算法具有穩定的聚類效果,且有較高的分類準確率,同時迭代次數有明顯的下降。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
