基于深度學習的文本匹配研究綜述
2021-08-06 05:24:16曹帥
現代計算機 2021年16期
曹帥
(四川大學計算機學院,成都 610065)
0 引言
自然語言處理是人工智能領域的重要分支,其中包含了很多研究方向:文本分類、信息抽取、機器翻譯和問答系統等。其中文本匹配是基礎并重要的研究方向,其在問答系統、信息檢索和對話系統等很多領域都發揮著決定性的作用。文本匹配在不同場景下的含義略有不同,例如在內容推薦上實質的任務為長文本之間的語義匹配,在這種情況通過使用主題模型,來獲取到兩個長文本的主題分布,再通過衡量兩個多項式分布的距離去衡量它們之間的相似度;又比如在檢索式問答系統中,則是通過對比問題和答案之間的相似度來召回最為相關的答案返回給用戶。
文本匹配的發展經歷著從傳統方法到深度神經網絡方法的演變。傳統方法中主流的是BOW、TF-IDF、BM25等算法,它們在搜索引擎的原理中使用較為廣泛。這些算法多為解決詞匯層面的匹配問題,如BM25算法通過計算候選項對查詢字段的覆蓋程度來得到兩者之間的匹配得分,得分越高的網頁則匹配度越高。而類似TF-IDF這種方法,通過建立倒排索引可使查詢變得很快,但實際上解決的只是詞匯層面的相似度問題。這些方法實則上有很大的局限,解決不了更深層的語義或知識缺陷。而之后出現的基于深度學習的方法則在一定程度上開始解決這些問題。
研究者將介紹目前在深度學習中主流的三種文本匹配算法:基于向量相似度計算的方法、基于深度神經網絡匹配的方法和基于預訓練模型匹配的方法。研究者會詳細闡述這三種方法的實現方式和原理,并對其各自的優勢和局限性進行簡要的闡述。最后會在此基礎上總結目前亟待解決的問題和未來的研究趨勢。
1 基于向量相似度計算的算法
傳統方式中文本與文本之間的相似度計算有多種方式:BOW、TF-IDF和N-Gram等,這些算法通過對句子分詞之后得到每個詞語或詞塊的表示,之后再對所有表示取平均獲取到整個句子的表示。假設兩個句子分別為p1和p2,則通過以上方式獲取到兩個句子的句向量,再對兩個向量求余弦相似度則獲取到兩個文本的相似度:
如果在兩個句子中出現了同義詞,雖然它們字面不同,但其表達的意思是一樣的,傳統方法則不能解決這類問題。詞嵌入最早是出現于Bengio在2003年提出的NNLM[1]中,其將原始的one-hot向量通過嵌入一個線性的投影矩陣映射到一個稠密的連續向量中,并且通過建立一個語言模型的任務來學習這個向量的權重,而這個向量也就可以看作詞向量。后面在2013年出現的Word2Vec[2]以及其他更多的NLP模型都運用到了這種思想。在Word2Vec出現后,基于詞向量來做更多的NLP衍生任務也成為了一時的主流。Word2Vec中主要可以利用CBOW和Skip-Gram兩種模型來分別學習向量的權重,它們的本質實質上都是對NNLM模型的改進。如圖1所示,如果是用一個詞語作為輸入,來預測它的周圍的上下文,那這個模型叫做Skip-Gram模型;而如果是一個詞語的上下文作為輸入,去預測這個詞語本身,則是CBOW模型。

圖1 CBOW和Skip-Gram模型
之前的NNLM模型其實存在比較嚴重的問題,就是訓練太慢了。即便是在百萬量級的數據集上,借助了40個CPU訓練,NNLM也需要數周才能給出一個稍微靠譜的結果。Word2Vec中引入了兩種優化算法:層次Softmax和負采樣來加速訓練,兩者的本質分別是將N分類問題轉變成log(N)次二分類和預測總體類別的一個子集。在詞嵌入領域,除了Word2Vec之外,還有基于共現矩陣分解的Glove[3]等詞嵌入方法。鑒于詞語是NLP任務中最細粒的表達,所以詞向量的運用很廣泛,不僅可以執行詞語層面的任務,也可以作為很多模型的輸入,執行句子層面的任務。
使用Word2Vec這種詞向量作為每個單詞的表示之后,能夠更好地解決之前所說的同義詞問題。這種對每個詞語取平均的方式是獲取句子向量的最簡單方式,但實質上其并沒有很好地解決句子主題含義相似的問題,雖然兩個句子字面可能很相似,但主題意思卻完全相反。之后出現的很多研究人員提出了例如Sentence2vec和Doc2vec之類的方法,也有像Sentence-Bert[4]這樣結合孿生網絡和預訓練模型獲取句子向量的方式。由于目前神經網絡的參數越來越多,在每次推測的過程中通過神經網絡會消耗很多時間,而在實時性要求很高的情況下例如搜索引擎,將候選項文本都轉化為向量存儲起來,再做向量之間的相似度計算,并不會消耗很多的時間,所以怎么在這個方向提高效果是研究人員一直都在努力的方向。
2 基于深度神經網絡匹配的方法
隨著深度學習在近幾年的蓬勃發展,很多研究開始致力于將深度神經網絡模型應用于自然語言處理任務中。利用詞向量來進行文本匹配計算,簡潔且快速,但是其只是利用無標注數據訓練得到,在效果上和主題模型技術相差不大,本質上都是基于共現信息的訓練。為了解決短語、句子的語義表示問題,和文本匹配上的非對稱問題,陸續出現了很多基于神經網絡的深度文本匹配模型。一般來說,它們主要分為兩種:表示型和交互型,下面將一一探討。
2.1 表示型深度文本匹配模型
表示型匹配模型更側重于對文本表示層的構建,會在表示層就將文本轉化成一個唯一的整體表示向量,其思路基于孿生網絡,會利用多層神經網絡提取文本整體語義之后再進行匹配。其中表示層編碼可使用常見的全連接神經網絡、卷積神經網絡、循環神經網絡或者基于注意力機制的模型等,而匹配層交互計算也有多種方式:使用點積、余弦矩陣、高斯距離、全連接神經網絡或者相似度矩陣等。一般會根據不同的任務類型和數據情況,選擇不同的方式。
開創表示型匹配模型先河的是微軟所提出的DSSM[5],它的原理是通過搜索引擎中的問題和標題之間的海量點擊曝光日志,用深度神經網絡將兩者表達為低維的語義向量之后,再利用余弦距離來計算兩個語義向量的相似度,最終訓練出語義相似度的模型。這個模型不僅可以用來預測兩個句子的語義相似度,又可以獲得某個句子的低維語義向量表達。之后在DSSM的基礎上又出現了一系列的模型,例如CDSSM[6]、MV-LSTM[7]和ARC-I[8]等,這些模型大體上的結構都是圖2所示,只是將表達層或者匹配層換成了更復雜、效果更好的模型結構。
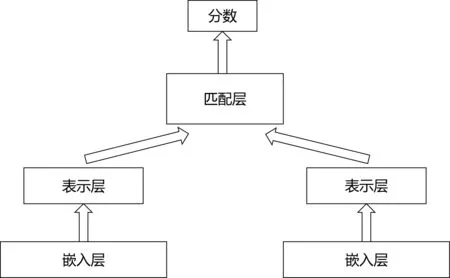
圖2 表示型匹配模型
在表示型模型上做研究,主要基于以下兩個方向:①加強編碼表示層的模型結構,獲取到更好的文本表示。②加強匹配層的計算方式。而基于第一點則出現了各種各樣的模型。表示型模型可以對文本預處理后,先構建索引,這樣就可以大幅度地降低在推理時候的計算耗時,但是其缺點也是顯而易見:因為需要對兩個句子分別進行編碼表示,這樣就會失去語義的焦點,從而難以衡量兩個句子之間的上下文重要性。
2.2 交互型深度文本匹配模型
如圖3所示,交互型模型和表達型模型是不同的思路,其擯棄了先編碼后匹配的思路,在輸入層就對文本先進行匹配,并將匹配了的結果再進行后續的建模。交互型模型的思想是先捕捉到兩個文本之間的匹配信息,將字詞之間的匹配信息再作為灰度圖,然后進行后續的建模抽象,獲取到最后它們的相關性評價。其中交互層主要是通過以注意力機制為代表的結構來對兩段文本進行不同粒度的交互,然后再將各個粒度的匹配結果給聚合起來,得到一個表示這種信息的特征矩陣。而這里可采用的注意力方式也有很多,根據不同的注意力機制可得到相應的效果。之后的表示層則負責對得到的特征矩陣進行抽象表征,也就是對兩個語句之間得到的匹配信息再進行抽象。

圖3 交互型匹配模型
基于交互型的經典匹配模型有:MatchPyramid[9]、DRMM[10]和ESIM[11]等。之后的一些基于注意力機制的模型,在將模型變得更深同時交互層變得更復雜外,其實很多模型都只是在一兩個數據集上搜索結構將分數提升了上去,導致這些模型在某個場景效果很好,但是到了另外的場景就效果不佳了。
交互型的文本匹配模型很好地把握了語義焦點,隨著更深的結構和更復雜的交互出現,也能捕捉到更深層的語義信息,能對上下文重要性更好的建模。但也像上文所說,其實在預訓練模型出現的很多復雜的交互型匹配模型,雖然結構復雜,也用到了很多復雜的注意力機制,但實質上在很多普遍的場景下,其實最簡單的基于卷積神經網絡或者循環神經網絡的結構就能得到可靠的結果。交互型模型的缺點是其忽視了句法、句間對照等全局性的信息,從而無法由局部信息刻畫出全局的匹配信息。
3 基于預訓練模型匹配的方法
2018年谷歌公司所推出的BERT[12]模型大放異彩,在11項自然語言處理任務上都達到了最好的效果,并且遠遠地甩掉了之前的模型,從而將自然語言處理的研究帶入了預訓練模型時代。自注意力機制提出后,加入了注意力機制的自然語言處理模型在很多任務都得到了提升,之后Vaswani等人提出的Transformer模型,用全注意力的結構代替了傳統的LSTM,在翻譯任務上取到了更好的成績。而BERT模型就是基于Transformer的,它主要創新點都在預訓練的方法上,即用了Masked LM和Next Sentence Prediction兩種方法去分別捕捉詞語和句子級別的表達,并且在大規模的無監督語料下進行訓練,從而得到訓練好的模型。之后再利用預訓練好的語言模型,在特定的場景和數據下去完成具體的NLP下游任務,由于Next Sentence Prediction這個訓練任務是句子與句子之間構成的問題,所以利用BERT來做文本匹配是有天然的優勢。
如圖4,利用BERT來完成文本匹配任務的話,首先是需要將在首部加入[CLS],在兩個句子之間加入[SEP]作為分隔。然后,對BERT最后一層輸出取[CLS]的向量并通過MLP即可完成多分類任務。使用預訓練好的BERT模型在很多文本匹配任務例如MNLI、QQP、MRPC、QNLI等上都達到了SOTA效果。
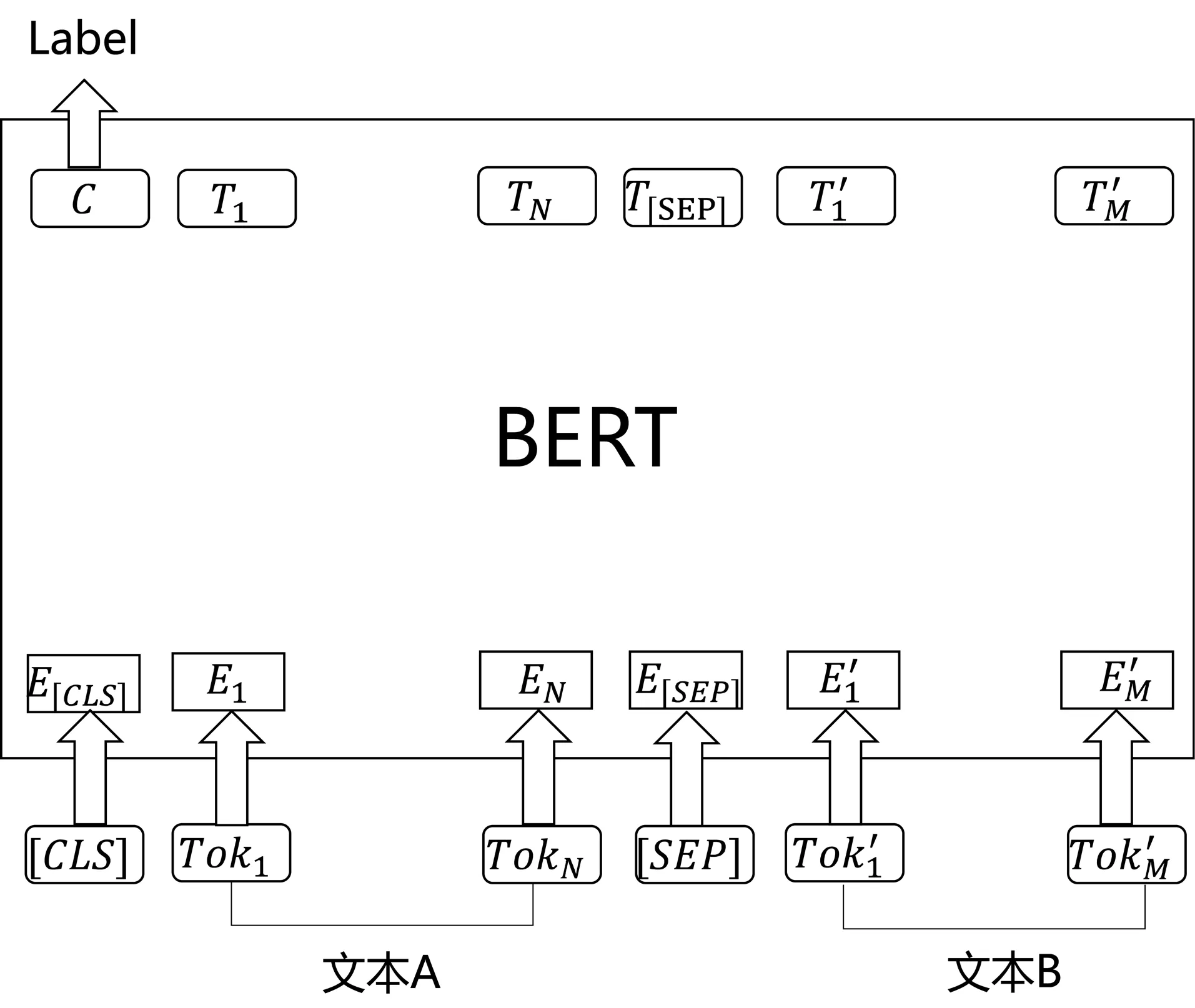
圖4 使用BERT進行文本匹配
預訓練好的BERT模型也可以直接拿來取最后一層輸出作為句向量,但這樣的效果甚至不如詞向量,直接拿[CLS]特征的效果最差,可見BERT模型暫時只適合在特定的任務下微調,之后使用微調后的BERT模型來預測,這樣才能得到最佳的效果。后續出現的Sentence-BERT,利用孿生網絡的優勢,可以利用訓練后的BERT取的效果較好的句子特征,但依然沒有直接使用微調后的BERT效果好。
BERT是最新的自然語言處理SOTA模型,后續也出現了很多類似于BERT或者在BERT上改進的預訓練模型,其拋棄了傳統的RNN結構,全面使用Transformer,可以并行訓練,加快了訓練速度,同時也能捕捉到更長距離的依賴信息。之前也出現過GPT[13]這樣的預訓練模型,但BERT捕捉到了真正意義上的雙向上下文信息。當然BERT也有一些缺陷:例如超多的參數和超深的網絡,導致BERT在預測時候其實速度很慢,對于實時性要求較高的文本匹配任務稍顯吃力,BERT之后研究者們也在這方面做了很多工作。同時BERT在預訓練中[MASK]標記在實際預測中不會出現,所以訓練時用過多的[MASK]其實會影響到模型的實際表現。
4 結語
研究者探討了深度學習時代以來出現過的可用于文本匹配的算法。基于向量相似度計算的方法是最為高效的方式,在以毫秒級嚴格要求的工業界,也是最容易被廣泛運用的一種方法。但是如何將語句的語義含義、主題意義等更深于字面的信息嵌入到向量表示中,目前看來還是一個大研究方向。而基于深度神經網絡的匹配方法,不管是基于表示型還是基于匹配型,其簡單的思想和復雜的結構也對應了自然語言處理的發展趨勢,但是目前很多模型其實都只是在一兩個數據集上表現好,而在普遍的任務上泛化能力還不強,同理復雜的參數也是讓想要應用這些模型到實際應用中的研究者望而卻步,實際上工業界用到最多的還是最先提出的基于DSSM的改進模型,因為其簡單、速度快,而且在大規模數據上訓練之后效果也還不錯。
隨著BERT模型的出現,基于預訓練模型的文本匹配算法也開始逐漸走上大舞臺。這些預訓練模型由于在超大規模的無監督語料上訓練,同時擁有著千萬級的學習參數,所以效果也遠遠地超過了之前的一些模型。但同樣的問題是如何將這些大模型運用到實際生活中,也是一項很大的挑戰。所以最近,已經有很多研究者開始不再糾結于去提高預訓練模型的效果,而是研究如何蒸餾模型,讓小模型也能學到同樣多的知識。同時,BERT之類的預訓練模型雖然能夠利用已經學到的東西,去判斷兩個文本間的匹配度,但是對于一些外部知識卻無法解決,所以一些研究者也開始嘗試將諸如知識圖譜之類的外部知識引入到預訓練模型中。
文本匹配是自然語言處理中的一項重要任務,這三類算法也是研究者們在探索的長河中提出的重要代表而已,相信不久的將來將會有新的算法來將這項任務推到更高的高度。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
電子制作(2018年18期)2018-11-14 01:48:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
