一種多粒度DNS隧道攻擊檢測方法
2021-08-07 10:26:54陳治昊
現(xiàn)代計算機 2021年17期
陳治昊
(四川大學網(wǎng)絡(luò)空間安全學院,成都 610065)
0 引言
DNS隧道攻擊是指利用DNS請求建立起隧道,繞過防火墻、入侵檢測系統(tǒng)等網(wǎng)絡(luò)安全策略,實現(xiàn)信息竊取、遠程命令執(zhí)行等網(wǎng)絡(luò)攻擊行為。攻擊者搭建一個含有惡意軟件的DNS權(quán)威服務(wù)器并注冊一個域名后,內(nèi)網(wǎng)中的受控主機能通過該域名將編碼后DNS請求發(fā)往攻擊者的服務(wù)器建立隧道并進行交互,建立隧道后服務(wù)器能夠?qū)?nèi)網(wǎng)主機發(fā)送的DNS請求數(shù)據(jù)包進行解碼獲取傳輸數(shù)據(jù),同時也能夠向受控主機發(fā)送編碼后的控制指令,達到遠程命令執(zhí)行的目的。根據(jù)RFC1034[1]和RFC1035[2]中定義的DNS格式,DNS除了通常解析域名所使用的A類型請求,還存在MX、TXT、CNAME等類型,允許填充任意類型的字符信息,這就使得攻擊者能夠使用DNS隧道進行信息竊取以及遠程命令執(zhí)行等攻擊。同時由于DNS協(xié)議受到的監(jiān)控力度較小,許多木馬、僵尸網(wǎng)絡(luò)和APT攻擊也使用了DNS隧道進行控制通信,保持攻擊服務(wù)器與內(nèi)網(wǎng)受控主機之間的連接。在2016年5月,在Palo Alto公開的一起APT攻擊事件中[3],攻擊團隊利用DNS請求應(yīng)答機制作為攻擊滲透的命令控制通道。
目前對于DNS隧道攻擊的檢測方法主要有兩類:基于載荷分析與基于行為檢測。
基于載荷是指將DNS請求與響應(yīng)數(shù)據(jù)包中的有效載荷進行分析。章航等通過請求載荷的域名長度、字符占比、隨機性特征和語義特征來檢測DNS隧道攻擊[4];Homem I等人分析了DNS隧道攻擊的內(nèi)部數(shù)據(jù)包結(jié)構(gòu),使用數(shù)據(jù)包內(nèi)容信息熵進行檢測[5];Lai C M等人使用每個DNS數(shù)據(jù)包的前512個字節(jié)進行檢測[6];Liu C等人將DNS數(shù)據(jù)包的內(nèi)容壓縮為一個字節(jié)大小的數(shù)據(jù),使用卷積神經(jīng)網(wǎng)絡(luò)進行訓練學習[7]。但是基于載荷分析的DNS隧道攻擊檢測方法有著很大的局限性,一些經(jīng)過URL Encoding編碼的合法域名長度較長并且不符合常規(guī)的語言習慣,容易產(chǎn)生誤報。
基于行為的檢測方法主要是針對網(wǎng)絡(luò)中DNS流量的變化情況與整體特征。羅友強等對DNS會話進行重組,提取了7種DNS隧道攻擊行為特征組成特征向量進行檢測[8];單康康等人混合了三種常用分類算法并加權(quán)求優(yōu),構(gòu)建了基于通信行為的檢測模型[9];Liu J等人提取了時間間隔、請求數(shù)據(jù)包大小、DNS類型和子域名熵四種行為特征進行檢測[10];Ishikura N等人提出根據(jù)DNS請求命中緩存的情況來判斷是否為隧道攻擊[11];Pomorova等人使用了域名長度、與域名相關(guān)的IP數(shù)量、TTL值、DNS查詢成功標志等多種行為特征來檢測隧道攻擊行為[12]。多種行為特征組成特征向量,能很好地表現(xiàn)出攻擊流量與正常流量之間的差異性,降低基于載荷方法中因編碼導致的誤報情況,但是正常網(wǎng)絡(luò)通信環(huán)境中,DNS隧道攻擊流量出現(xiàn)頻率會遠小于正常流量出現(xiàn)的頻率,若對每個DNS會話進行重組、計算特征與檢測,會消耗大量的計算資源,從而導致檢測效率不高。
1 DNS隧道攻擊特征提取
針對DNS隧道攻擊特征提取,分析了現(xiàn)有研究在特征提取與選擇上存在的問題,提出了DNS流量行為的粗粒度特征與細粒度特征,并且使用兩種特征相結(jié)合對DNS流量進行分類判斷。粗粒度與細粒度特征相結(jié)合的方式如圖1所示,首先將通信流量按時間片劃分,使用粗粒度特征判斷存在DNS隧道攻擊的時間片,再將可疑時間片中的DNS會話進行重組,通過細粒度特征檢測出DNS隧道會話流量。
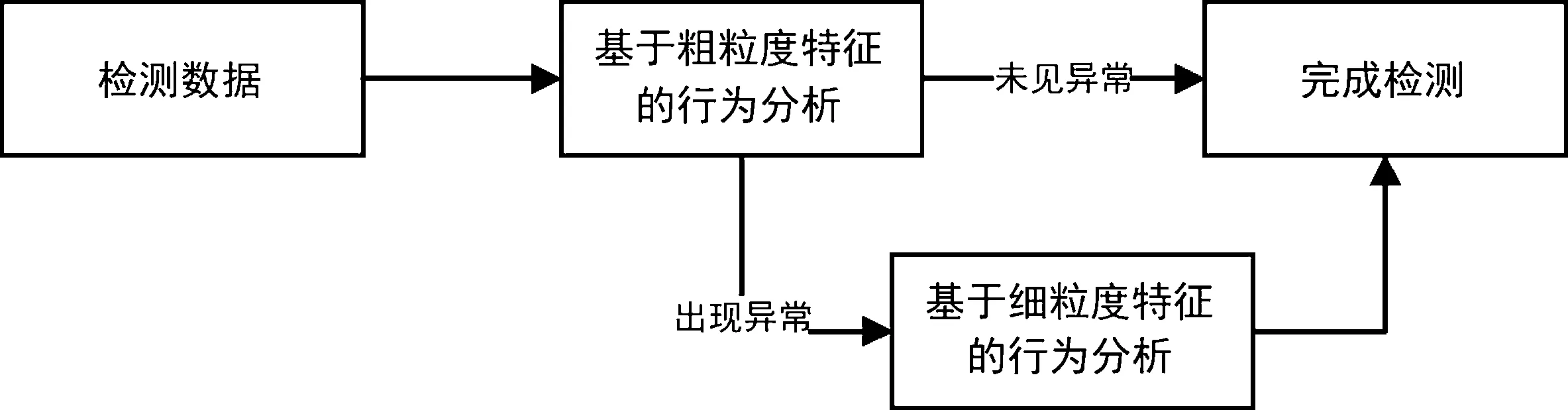
圖1 粗細粒度結(jié)合方式
1.1 粗粒度特征
由于對每條DNS會話進行重組、計算特征與檢測會導致檢測效率低下,因此提出了粗細粒度相結(jié)合的檢測方法。粗粒度特征針對一段時間片內(nèi)所有的DNS流量,用于判斷當前時間片內(nèi)的DNS流量是否存在異常,而無需重組并定位具體的DNS會話流量。針對時間片內(nèi)DNS流量,本文選取了7種粗粒度特征,如表1所示。
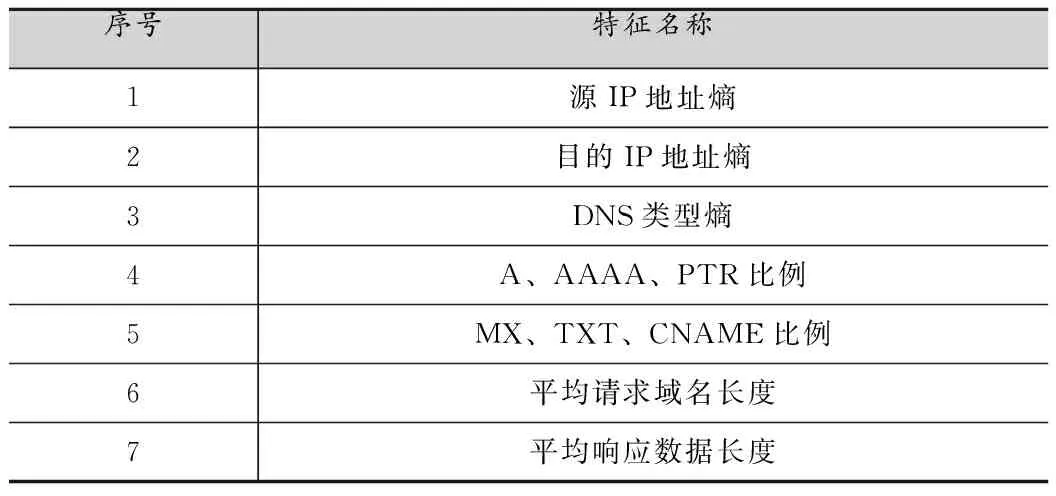
表1 粗粒度特征
(1)熵值計算方法
以源IP地址熵為例,源IP地址熵是使用時間片中不同源IP的數(shù)量占總的網(wǎng)絡(luò)流數(shù)量比值來計算信息熵,采用向量X=(x1,x2,…,xn)表示單位時間片中的數(shù)據(jù)流有n個不同的源IP地址,針對其中任一取值xi,設(shè)時間片中存在ki條網(wǎng)絡(luò)流的源IP地址為xi,主機在該時間窗口中的源IP地址熵H(X)計算公式為式1所示。其中S對應(yīng)不同源IP地址出現(xiàn)個數(shù),如式2所示。
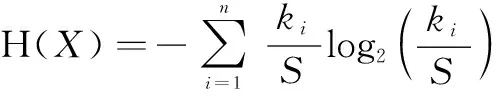
(1)
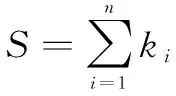
(2)
(2)源IP地址熵
正常內(nèi)網(wǎng)環(huán)境中,大部分DNS會話數(shù)據(jù)包數(shù)量較少,每臺主機在正常網(wǎng)絡(luò)連接中都會產(chǎn)生一些長度相似DNS會話,因此時間片內(nèi)源IP地址熵值會較高。基于UDP的DNS協(xié)議限制載荷最大為512字節(jié),因此DNS隧道攻擊發(fā)送的數(shù)據(jù)會被切分為很多DNS請求數(shù)據(jù)包,因此當有主機與DNS隧道攻擊服務(wù)器進行交互時,單位時間內(nèi)該主機產(chǎn)生的DNS請求數(shù)量會遠大于其他主機,因此時間片內(nèi)源IP地址熵值會降低。
(3)目的IP地址熵
選取此特征原因類似于源IP地址熵,在內(nèi)網(wǎng)各個主機沒有制定相同的DNS服務(wù)器地址時,對存在攻擊行為的時間片會有較好的檢測效果。
(4)DNS類型熵
正常網(wǎng)絡(luò)環(huán)境中DNS協(xié)議是用于域名解析,大部分DNS請求與響應(yīng)數(shù)據(jù)包都是A類型(解析為IPv4地址)與AAAA類型(解析為IPv6地址),因此時間片內(nèi)DNS類型熵值較小。若時間片內(nèi)存在攻擊流量,有大量其他類型的DNS請求時,DNS類型熵值會提高。
(5)A、AAAA、PTR比例
正常DNS請求多為A、AAAA、PTR三種類型,用于返回解析后的IP地址信息,因其載荷小而不適應(yīng)于作為DNS隧道攻擊的類型,DNS隧道攻擊使用這三種協(xié)議會導致分片過多影響傳輸速度且容易被偵測到,因此當內(nèi)網(wǎng)中有主機與DNS隧道攻擊服務(wù)器進行交互,該時間片內(nèi)此比例較低。
(6)MX、TXT、CNAME比例
MX、TXT、CNAME為DNS隧道攻擊常用的類型,因其載荷較大且可以存儲任意字符而易于傳輸隱蔽數(shù)據(jù)信息,因此內(nèi)網(wǎng)中如果有主機與DNS隧道攻擊服務(wù)器進行交互,大量的MX、TXT、CNAME類型DNS流量會使得時間片內(nèi)此比例較高。
(7)平均請求域名長度
DNS隧道攻擊會將通信的內(nèi)容編碼后作為請求域名的子域名進行傳輸,因此與DNS隧道攻擊服務(wù)器進行交互時發(fā)出的DNS請求中域名長度較長。內(nèi)網(wǎng)中如果有主機與DNS隧道攻擊服務(wù)器進行交互,在通信時間片內(nèi)會產(chǎn)生大量長域名請求,從而導致平均請求域名長度會大于正常網(wǎng)絡(luò)請求時間片。
(8)平均響應(yīng)數(shù)據(jù)長度
進行DNS隧道攻擊時,DNS隧道攻擊服務(wù)器會將響應(yīng)控制信息編碼進行回傳,而正常DNS相應(yīng)多為解析域名后返回的IP地址信息,因此DNS隧道攻擊的響應(yīng)數(shù)據(jù)包會大于正常DNS服務(wù)器響應(yīng)數(shù)據(jù)包。
1.2 細粒度特征
細粒度特征用于粗粒度特征之后,用來定位具體的隧道攻擊會話。將時間片內(nèi)的DNS會話進行重組后,為了保證能夠準確定位具體的DNS隧道攻擊會話,因此針對每一條DNS會話,本文提取了17種細粒度特征,如表2所示。
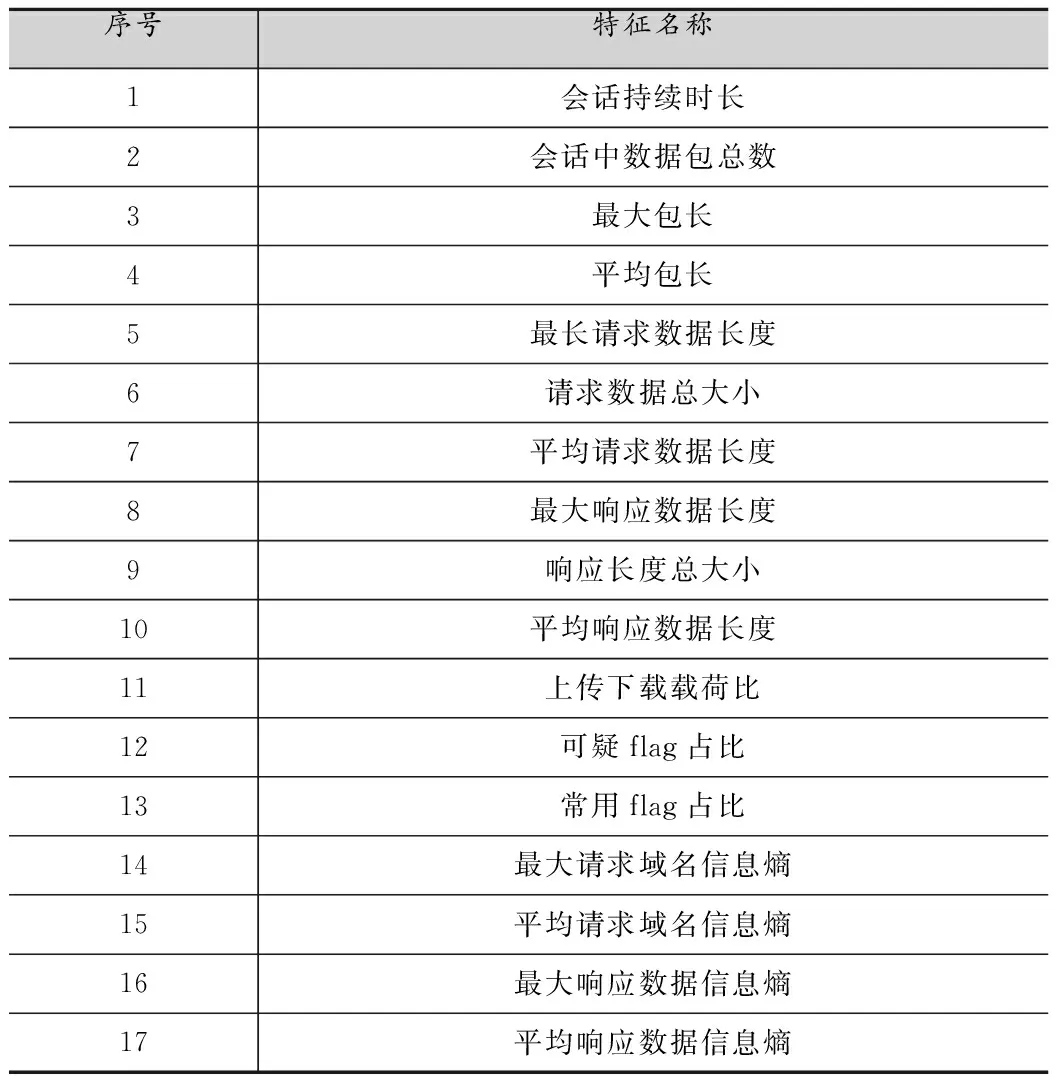
表2 細粒度特征
(1)DNS會話時長與會話中數(shù)據(jù)包總數(shù)
不同于基于TCP協(xié)議的會話在通信過程中存在三次握手與四次揮手行為,DNS基于無連接的UDP協(xié)議,因此DNS沒有嚴格意義上會話時長的定義。本文將在一次會話中最后一條DNS報文與第一條DNS報文時間的差值作為會話時長的定義。正常情況下的DNS請求,是由請求域名解析的主機在本地開啟一個任意端口,向域名服務(wù)器的53端口發(fā)出請求,服務(wù)器響應(yīng)之后DNS解析過程就結(jié)束了,客戶機創(chuàng)建的套接字也會在一段時間內(nèi)關(guān)閉。因此DNS隧道攻擊會話與正常DNS請求相比,會話時長更長,會話中數(shù)據(jù)包總數(shù)更大。
(2)最大包長與平均包長
在DNS隧道攻擊流程中,會存在內(nèi)網(wǎng)主機向外部攻擊服務(wù)器發(fā)送信息以及外部攻擊服務(wù)器向內(nèi)網(wǎng)主機發(fā)送指令信息的情況,在傳輸信息或指令時,通常是將其編碼再由DNS協(xié)議作為載體傳輸,因此此時的DNS會話的UDP數(shù)據(jù)包會較長。
(3)請求數(shù)據(jù)長度、響應(yīng)數(shù)據(jù)長度與上傳下載載荷比
對于會話中請求數(shù)據(jù)長度與響應(yīng)數(shù)據(jù)長度,分別計算了其最大值、平均值與總大小。若DNS隧道用于內(nèi)網(wǎng)信息竊取,則請求數(shù)據(jù)的長度相比于正常DNS會話會較長;若DNS隧道用于外部遠程命令執(zhí)行攻擊,則響應(yīng)數(shù)據(jù)的長度相比于正常DNS會話會較長。這種情況下,上傳下載載荷比也會與正常DNS會話不同。
(4)可疑flag與常用flag占比
正常DNS請求主要是A、AAAA、PTR類型的DNS報文,而DNS隧道攻擊為了提高傳輸效率,會更多使用TXT、MX、CNAME類型的DNS報文。
(5)域名信息熵
與正常DNS請求的域名信息不同,DNS隧道攻擊會采用多種編碼方式對傳輸數(shù)據(jù)進行編碼,因此請求的域名信息熵值會偏高,整個DNS隧道攻擊會話中最大與平均域名信息熵會比正常DNS會話要高。
2 多粒度DNS隧道攻擊檢測方法
基于第1.2小節(jié)分析的粗細粒度的特征,可以從DNS會話中提取出兩類特征構(gòu)建兩種評估向量。為了減少會話重組與提取過多特征并聚類導致的計算資源消耗,提高檢測效率,本文提出了一種多粒度DNS隧道攻擊檢測方法,使用粗粒度與細粒度特征相結(jié)合,在保證檢測準確率的同時能夠提升特征提取與檢測效率。同時根據(jù)DNS隧道攻擊檢測的特性,選擇了基于層次的聚類算法BIRCH算法進行聚類分析。
2.1 檢測框架
本文提出的多粒度DNS隧道攻擊檢測方法的基本流程如圖2所示。
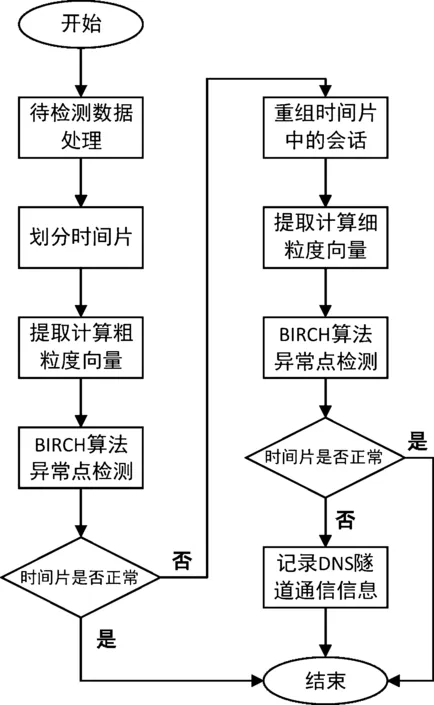
圖2 基于網(wǎng)絡(luò)行為的多粒度DNS隧道檢測方法的基本流程
與其他直接重組所有DNS會話,并同時提取所有特征進行檢測的方法不同,本方法整體流程分主要分為粗粒度檢測與細粒度檢測兩部分。如圖2所示,傳入待檢測的數(shù)據(jù)包后,首先進入粗粒度檢測階段,此階段不會進行重組DNS會話這一耗費大量計算資源的行為,而是先將數(shù)據(jù)包按時間片切分,對切分后的每一時間片內(nèi)的數(shù)據(jù)提取粗粒度特征構(gòu)建特征向量,使用BIRCH算法對異常時間片進行檢測,正常時間片內(nèi)的數(shù)據(jù)包放行,不做下一步檢測,若發(fā)現(xiàn)異常時間片,記錄異常時間片內(nèi)的數(shù)據(jù)包進行下一檢測階段,因此在粗粒度檢測階段需要保證較低的漏報率,確保異常時間片都能進入下一檢測階段;進入細粒度的檢測階段后,先對異常時間片內(nèi)的各個DNS會話進行重組,提取更多的細粒度特征構(gòu)建向量,進而更準確地定位DNS隧道攻擊會話。由于通常網(wǎng)絡(luò)環(huán)境中,正常DNS會話數(shù)量遠大于DNS隧道攻擊數(shù)量,因此采用了多粒度檢測方法后,絕大多數(shù)DNS數(shù)據(jù)包在粗粒度階段判斷為正常被放行,減少了大量重組會話與提取特征并聚類的時間;同時相較于其他行為檢測方法,能夠?qū)崿F(xiàn)細粒度階段提取更多特征而不降低檢測效率的效果,為較好地集成到實時入侵檢測系統(tǒng)提供了可能。
2.2 方法實現(xiàn)
根據(jù)處理的先后順序以及對數(shù)據(jù)包的處理方法,整個流程分為粗粒度與細粒度兩個模塊。
2.2.1 粗粒度檢測模塊
粗粒度檢測模塊輸入為從網(wǎng)絡(luò)環(huán)境中獲取的數(shù)據(jù)包文件,輸出為存在DNS隧道攻擊的時間片信息。具體實現(xiàn)步驟如下:
①提取pcap格式數(shù)據(jù)包中所需的數(shù)據(jù)。此步驟僅從輸入的pcap數(shù)據(jù)包中按條提取出所需要的基本數(shù)據(jù)并記錄,例如數(shù)據(jù)包時間戳、源目的地址與端口、數(shù)據(jù)包長度、分片標志位、遞歸標志位和TTL值等數(shù)據(jù),特征的計算過程交由后續(xù)步驟處理以縮短時間;
②劃分時間片并計算粗粒度特征。根據(jù)預設(shè)的時間窗口大小與數(shù)據(jù)包的時間戳,將數(shù)據(jù)包數(shù)據(jù)按照切分成多個時間片,對于每一個時間片計算出2.1小節(jié)中選取的粗粒度特征,提取出所有時間片的粗粒度特征后進行歸一化處理并進入下一步驟;
③選取適合的算法進行檢測并記錄異常時間片。此步驟選取了BIRCH算法進行聚類,將少數(shù)存在攻擊行為的異常時間片作為異常點進行檢測,標記異常時間片并將其基本數(shù)據(jù)送入細粒度檢測模塊進行下一步檢測。
2.2.2 細粒度檢測模塊
細粒度檢測模塊輸入為異常時間片中數(shù)據(jù)包的基本信息,輸出為DNS隧道攻擊信息。具體實現(xiàn)步驟如下:
①將時間片中的數(shù)據(jù)包按會話進行重組。根據(jù)預設(shè)的會話延時時間與四元組信息,將時間片內(nèi)的數(shù)據(jù)包重組成多組會話,每組會話中包含多條數(shù)據(jù)包的信息,每個時間片以三維矩陣的形式記錄;
②計算細粒度特征。對于時間片中的每一組會話計算出2.2小節(jié)中選取的細粒度特征,提取出所有會話的細粒度特征后進行歸一化處理并進入下一步驟;
③選取適合的算法進行檢測并記錄DNS隧道攻擊信息。此步驟同樣選取了BIRCH算法進行聚類,將少數(shù)DNS隧道攻擊會話作為異常點進行檢測,記錄下其信息完成DNS隧道攻擊檢測。
2.2.3 算法選擇
對于上述模塊第三步中算法的選擇,分析了本方法的整個檢測流程后,總結(jié)出了以下幾個特點:
①正常DNS請求行為單一,提取特征聚類輪廓近似球形;
②只抓取了DNS流量,噪聲數(shù)據(jù)或突發(fā)情況較少;
③提升粗細粒度檢測速度,算法效率盡可能高;
④正常樣本與DNS隧道數(shù)量差別過大,可以將正常樣本聚類成簇、將隧道樣本作為異常點進行檢測。
針對以上特點,本文選取了BIRCH算法作為檢測算法,BIRCH算法雖然抗干擾性不佳,但其有著聚類形狀為球形、算法效率高、能夠?qū)崿F(xiàn)無監(jiān)督異常點檢測的特點,能夠較好地滿足本方法的要求。
BIRCH算法是一種基于層次的聚類算法,其使用了一個樹型結(jié)構(gòu)來快速聚類,這個樹型結(jié)構(gòu)類似于B+樹,稱為聚類特征樹,樹的每一個節(jié)點都是若干個聚類特征(CF),內(nèi)部節(jié)點的CF的指針指向其孩子節(jié)點,所有的葉子節(jié)點用一個雙向鏈表鏈接起來。其構(gòu)建過程也類似于B+樹的構(gòu)建,每個節(jié)點中CF數(shù)需設(shè)定上限,達到上限該節(jié)點進行分裂,因此BIRCH算法的訓練過程就是建立聚類特征樹的過程[14]。
BIRCH算法的CF是一個三元組,用(N,LS,SS)表示,其中N代表了這個CF中擁有樣本點的數(shù)量,LS代表了這個CF中擁有的樣本點各特征維度的和向量,SS代表了這個CF中擁有的樣本點各特征維度的平方和。若聚類特征中有N個D維數(shù)據(jù)點如式(3)所示,則LS與SS的計算方法分別為式(4)和式(5)。
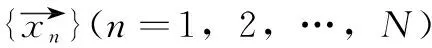
(3)

(4)

(5)
可以發(fā)現(xiàn)CF滿足線性關(guān)系,從而在聚類特征樹中,父節(jié)點CF是由其所有子節(jié)點CF線性相加所得到的,因此BIRCH算法能夠很好地表示成一個層次樹型結(jié)構(gòu)。
在構(gòu)建BIRCH算法模型時我們需要調(diào)整的參數(shù)為內(nèi)部節(jié)點的最大CF數(shù)B、葉子節(jié)點的最大CF數(shù)L、葉節(jié)點每個CF的最大樣本半徑閾值T,讀入讓樣本點時根據(jù)T值決定是否聚為同一個CF,再根據(jù)B與L值決定該節(jié)點是否分裂。
從BIRCH的定義我們就能看出此算法的特性:聚類速度快,只需要一遍掃描訓練集就可以建立CF Tree,CF Tree的增刪改都很快;聚類結(jié)果分布簇為超球體;BIRCH除了聚類還可以做一些異常點檢測和數(shù)據(jù)初步按類別規(guī)約的預處理[15]。因此能夠較好的滿足本方法的要求。
3 實驗與分析
為驗證此方法能夠有效地檢測出DNS隧道攻擊會話,以及驗證使用粗細粒度相結(jié)合的方法后能夠提高檢測效率,設(shè)計了兩組實驗來對本文提出方法的有效性與檢測效率進行試驗。第一組實驗為使用多種聚類算法來驗證本方法的有效性,并驗證BRICH算法為最適用于此類情景的算法;第二組實驗對比了重組所有DNS會話并同時提取特征與使用多粒度模型進行檢測的時間消耗,驗證使用多粒度模型對檢測效率提升的效果。
3.1 實驗數(shù)據(jù)
本次實現(xiàn)所使用的DNS數(shù)據(jù)為四川大學某實驗室內(nèi)部網(wǎng)絡(luò)拓撲下的收集的實驗數(shù)據(jù)。在實驗室內(nèi)部網(wǎng)絡(luò)中的兩臺主機上分別使用dns2tcp、iodine搭建環(huán)境,不定期與搭建在外部阿里云服務(wù)器上的DNS隧道攻擊服務(wù)器進行交互,期間實驗室內(nèi)網(wǎng)絡(luò)通信正常使用,使用Tcpdump在出口網(wǎng)關(guān)上抓取流出與流入的所有數(shù)據(jù)包,過濾其余協(xié)議只保留DNS協(xié)議數(shù)據(jù)包,最后收集了包含隧道攻擊流量的DNS數(shù)據(jù)包共計1,007,883條。
3.2 評價標準
為了驗證該方法在具有較好檢測效果的同時能夠提高檢測效率,將召回率、誤報率以及檢測時長作為衡量實驗結(jié)果的指標。召回率、誤報率具體計算公式如式(6)與式(7)所示。檢測時長為從劃分時間片開始到輸出結(jié)果的總時長。

(6)
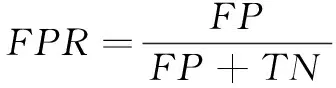
(7)
在實驗中由于DNS隧道攻擊流量為檢測主體部分,所以隧道攻擊流量為正樣本,正常流量為負樣本。因此召回率能夠很好地反映從大量正常DNS會話中檢測出少量隧道會話的能力。
3.3 實驗結(jié)果
本文實驗采用Python sklearn模塊對數(shù)據(jù)集進行聚類分析,設(shè)定粗粒度時間片間隔為300秒,分別使用BIRCH算法、DBSCAN算法、K-means算法進行聚類,驗證其召回率、誤報率與處理時間;同時采用BIRCH算法,比較使用多粒度模型與不使用多粒度模型的召回率、誤報率與處理時間對差異。
將含有DNS隧道流量的數(shù)據(jù)包按日期分成五份,使用多粒度模型,BIRCH算法、DBSCAN算法、K-means算法的召回率、誤報率與處理時長如表3所示。其中時長為劃分時間片、重組DNS回話以及檢測的總時長,單位為秒。

表3 三種算法檢測效果對比
因為DBSCAN算法與K-means算法在粗粒度檢測階段誤報率略高,因此更多的時間片被用于細粒度檢測,導致檢測時長增加。
為了更好地對比,其召回率、誤報率與時長如圖3、圖4與圖5所示。
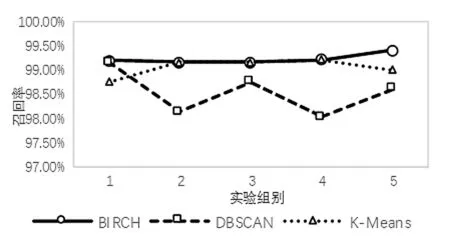
圖3 三種算法召回率對比
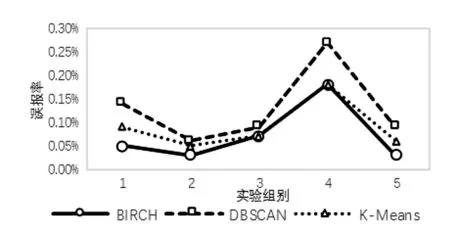
圖4 三種算法誤報率對比
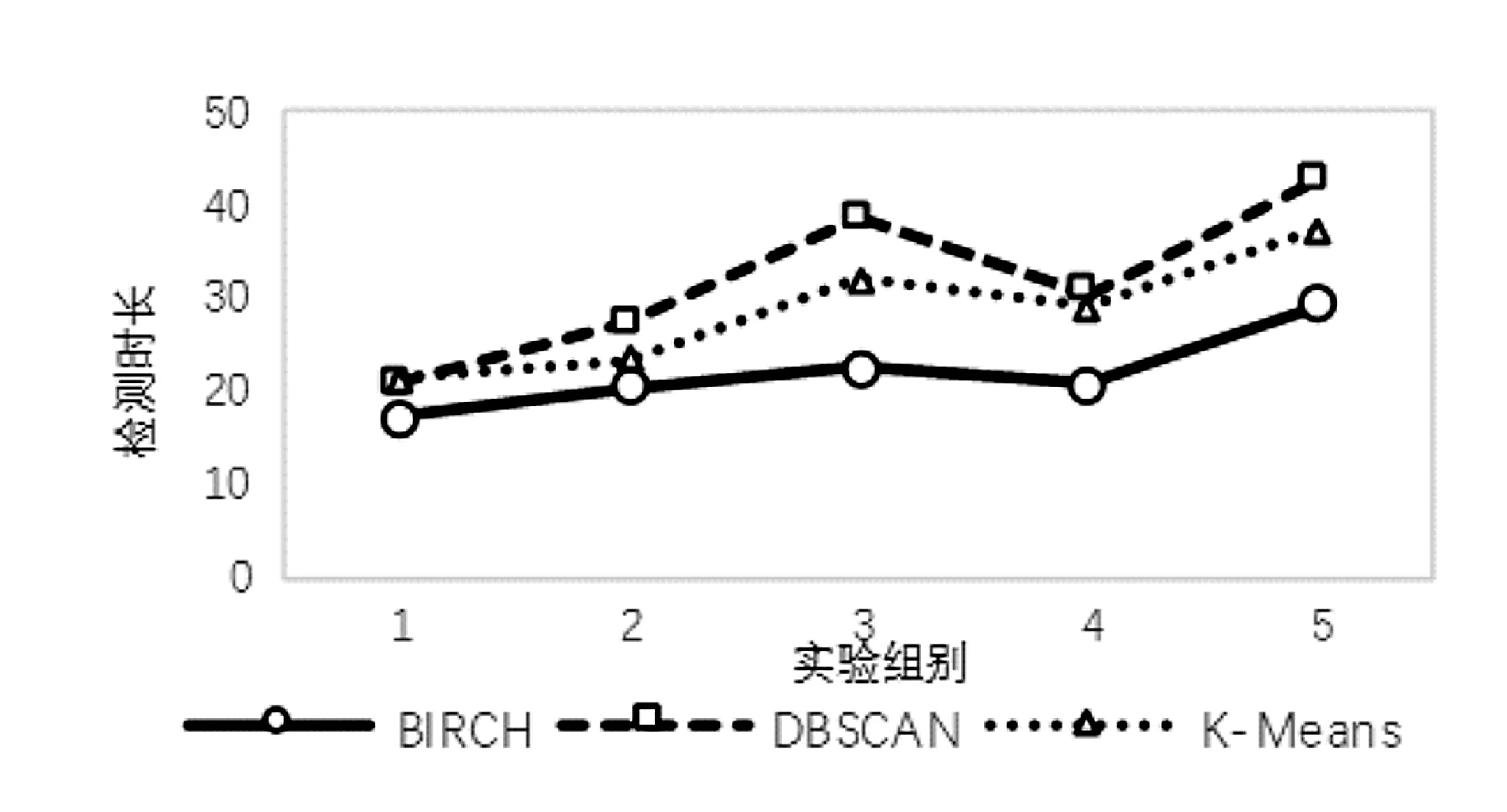
圖5 三種算法檢測時長對比
對于BIRCH算法,不使用多粒度模型對每個DNS會話進行檢測,與使用多粒度模型進行檢測的實驗結(jié)果如表4所示。其中時長為劃分時間片、重組DNS回話以及檢測的總時長,單位為秒。
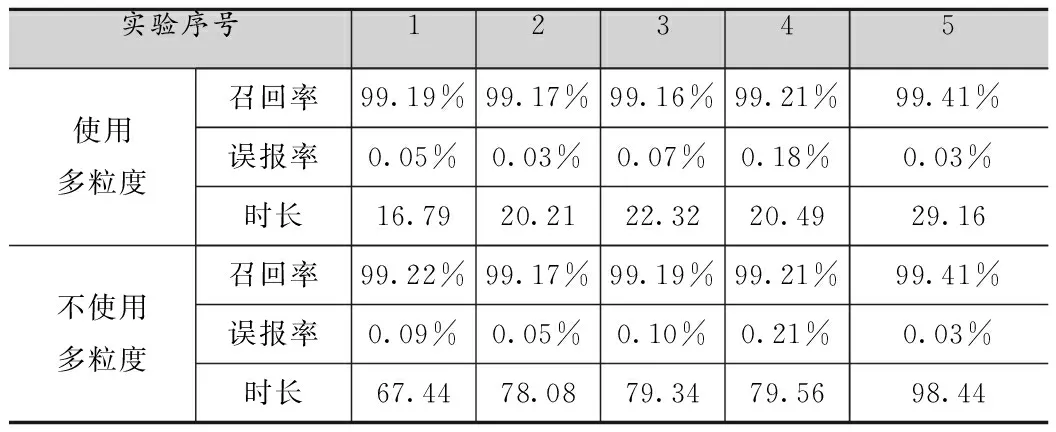
表4 使用與不使用多粒度識別效果對比
為了更好地對比,其檢測時長如圖6所示。
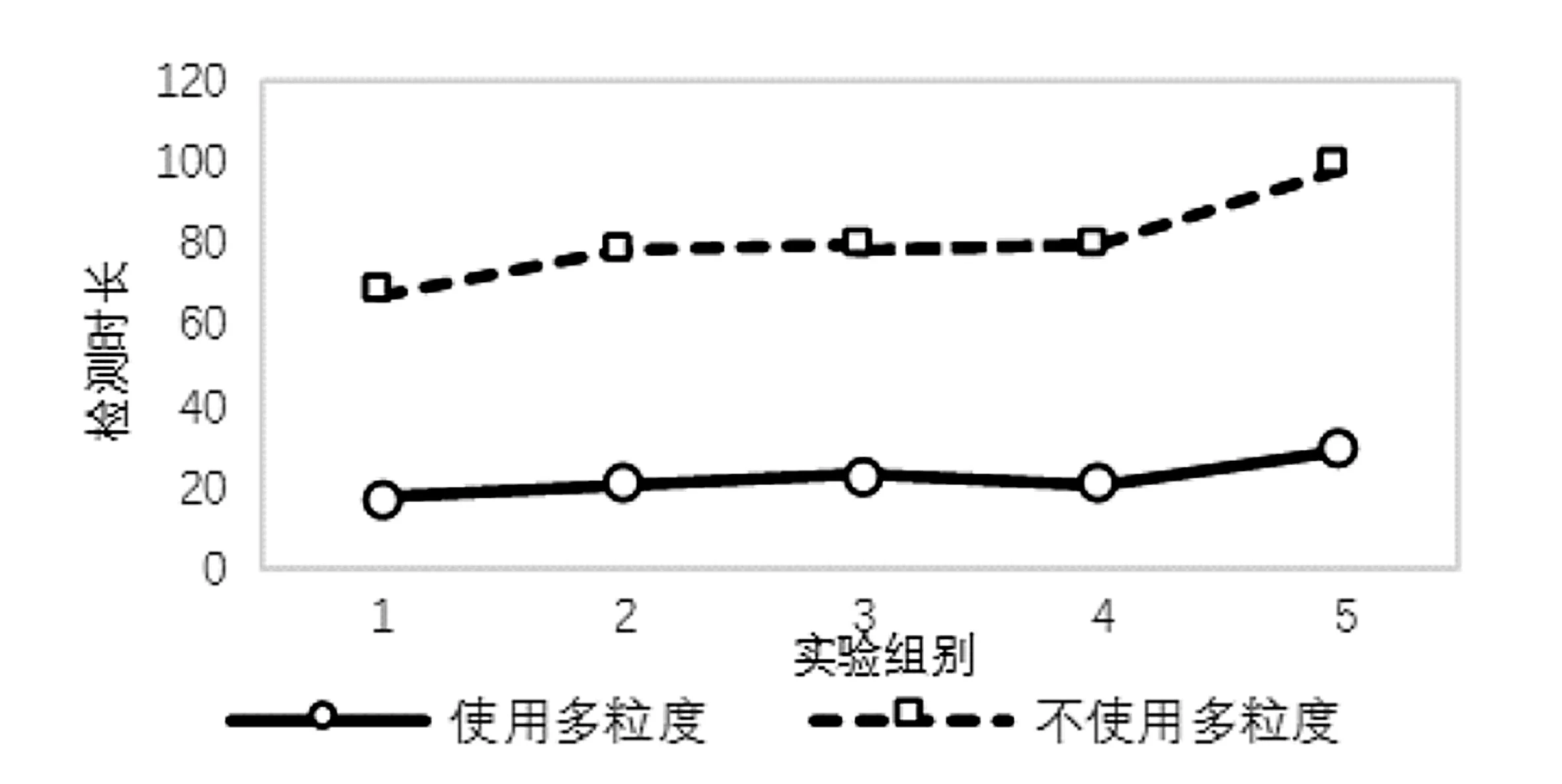
圖6 使用與不使用多粒度模型檢測時間對比
通過表3的實驗結(jié)果可以看出,對于從大量正常DNS會話中檢測出少量隧道攻擊流量,使用多粒度模型進行檢測能夠取得較高的召回率以及較低的誤報率,并且對于DNS這一種單一類別的協(xié)議進行檢測,BIRCH算法在檢測時長上較有優(yōu)勢,與之前分析相符。
同時從圖6可以發(fā)現(xiàn),采用了多粒度模型后,能夠減少大量DNS會話重組與細粒度特征提取的次數(shù),節(jié)省計算資源,能夠在不降低檢測準確率的情況下,極大提高檢測速度。
4 結(jié)語
本文提出的方法在保持良好的檢出率的情況下,檢測效率有了很大的提升,為較好地集成到實時入侵檢測系統(tǒng)提供了可能。進一步挖掘可用于DNS隧道檢測的新特征、改進算法性能、應(yīng)用于實時入侵檢測系統(tǒng)將是下一步的研究重點。
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
