低照度場景下的時(shí)空頻域視頻去噪算法
2021-08-07 10:26:54鮮連義康明
現(xiàn)代計(jì)算機(jī) 2021年17期
關(guān)鍵詞:效果
鮮連義,康明
(1.上海交通大學(xué)微納電子學(xué)系,上海 200240;2.格科微電子(上海)有限公司,上海 201203)
0 引言
數(shù)字圖像以及視頻噪聲的抑制起步較早,早期經(jīng)典的去噪算法如:均值濾波、中值濾波、高斯濾波、維納濾波[1]等在提出時(shí)都成為主流的優(yōu)秀算法。伴隨著圖像去噪技術(shù)的不斷發(fā)展,越來越多更加先進(jìn)的算法被提出來,目前普遍的傳統(tǒng)圖像以及視頻去噪方法包含空間域去噪[1]、變換域去噪[2-4]、時(shí)間域去噪[5-6]等等。
空間域去噪算法[1]的原理是利用二維圖像空間直接采用相關(guān)操作如取平均等去除像素中的噪聲,常見的操作方法基本是對具體像素點(diǎn)進(jìn)行代數(shù)運(yùn)算等,因而此類算法的復(fù)雜度較低,運(yùn)算時(shí)間較快。變換域去噪[2-4]又叫頻域去噪,不同于空間域去噪在二維圖像空間內(nèi)進(jìn)行像素點(diǎn)的處理,它的主要思路是通過特定的變換規(guī)則如傅里葉變換等,將二維的圖像矩陣數(shù)據(jù)轉(zhuǎn)換到變換域內(nèi),以便于更容易的區(qū)分圖像真值與噪聲,將噪聲過濾掉。圖像從空間域轉(zhuǎn)換到變換域的方法很多,其中最具代表性的有傅里葉變換、離散余弦變換[2]、多尺度幾何分析方法[3]以及小波變換[4]等。但是這些方法[1-4]在處理過程中不可避免的會(huì)造成圖像的平滑和細(xì)節(jié)的缺失。時(shí)間域去噪[5-6]主要的應(yīng)用是多幀降噪算法,伴隨BM3D[5]算法提出的同時(shí)針對視頻降噪所提的VBM3D[6]算法,將時(shí)域的冗余信息加入視頻去噪算法當(dāng)中。在此之后不斷有新的結(jié)合時(shí)間域去噪的算法例如VBM4D[7]算法等出現(xiàn)。但是這類的時(shí)間域去噪算法[5-7]往往需要進(jìn)行多次塊匹配,計(jì)算復(fù)雜度高,處理時(shí)間長。2018年Jana Ehmann等人提出了一種基于金字塔結(jié)構(gòu)的視頻去噪算法[8],可以實(shí)現(xiàn)高分辨率圖像在Pixel2手機(jī)上30fps的去噪處理速度,基本滿足了高分辨率圖像實(shí)時(shí)性要求,但是去噪效果還有提升的空間。
為了克服上述一些方法[2-8]模糊圖像細(xì)節(jié)[1-4]、計(jì)算復(fù)雜度高[5-7]、去噪效果受限[8]等的缺點(diǎn)和劣勢,本文提出了TSF算法。TSF算法結(jié)合了時(shí)空域降噪的算法和頻域降噪的原理,首先建立包含數(shù)字增益的低照度圖像噪聲模型,然后針對原始視頻中的相鄰前后兩幀圖像,基于光流法[9]完成圖像配準(zhǔn)得到位移圖,在時(shí)空域?qū)Ω哳l圖像進(jìn)行去噪和重構(gòu),進(jìn)而結(jié)合后續(xù)噪聲圖像實(shí)現(xiàn)無限脈沖響應(yīng)處理(Infinite Impulse Response,IIR),同時(shí)在空域進(jìn)行降噪,輸出后一幀去噪圖像。所提TSF算法比實(shí)時(shí)視頻去噪[8]算法具有更好的圖像質(zhì)量和紋理保持效果,與VBM4D去噪[7]算法相比,有效降低了運(yùn)行時(shí)間。
1 低照度場景下的視頻去噪算法
本文提出的低照度場景下的視頻去噪算法處理流程如圖1所示,從上到下的三個(gè)虛線框依次代表三個(gè)步驟:
(1)視頻流前后幀的配準(zhǔn)。
(2)視頻流前后殘差圖像的融合和圖像重構(gòu)傳播。
(3)對于融合和重構(gòu)生成的低噪圖像進(jìn)行空間域去噪處理,得到輸出結(jié)果。
配準(zhǔn)步驟計(jì)算兩個(gè)連續(xù)幀的位移圖,融合步驟融合輸入幀和前一幀圖像的重構(gòu)圖像,最后空間域去噪處理得到當(dāng)前幀的去噪結(jié)果。結(jié)合圖1的詳細(xì)流程,t和t+1時(shí)刻的圖像分解為高斯和拉普拉斯金字塔。原始圖像用于配準(zhǔn),拉普拉斯金字塔用于融合。融合金字塔經(jīng)過重構(gòu)生成與t+2時(shí)刻繼續(xù)執(zhí)行IIR處理的中間幀,該重構(gòu)結(jié)果作為下一幀(t+2幀)融合步驟t+1時(shí)刻的輸入,這樣可以盡量保證空間域去噪造成的細(xì)節(jié)平滑不會(huì)傳播到t+2幀的處理當(dāng)中。同時(shí)低照度場景下的去噪當(dāng)中僅僅采用時(shí)間域的去噪處理達(dá)不到最理想的處理效果,因此在本文的算法當(dāng)中加入了空間域?yàn)V波的去噪處理模塊。重構(gòu)結(jié)果經(jīng)過空間域去噪處理之后作為t+1時(shí)刻的最終去噪結(jié)果。
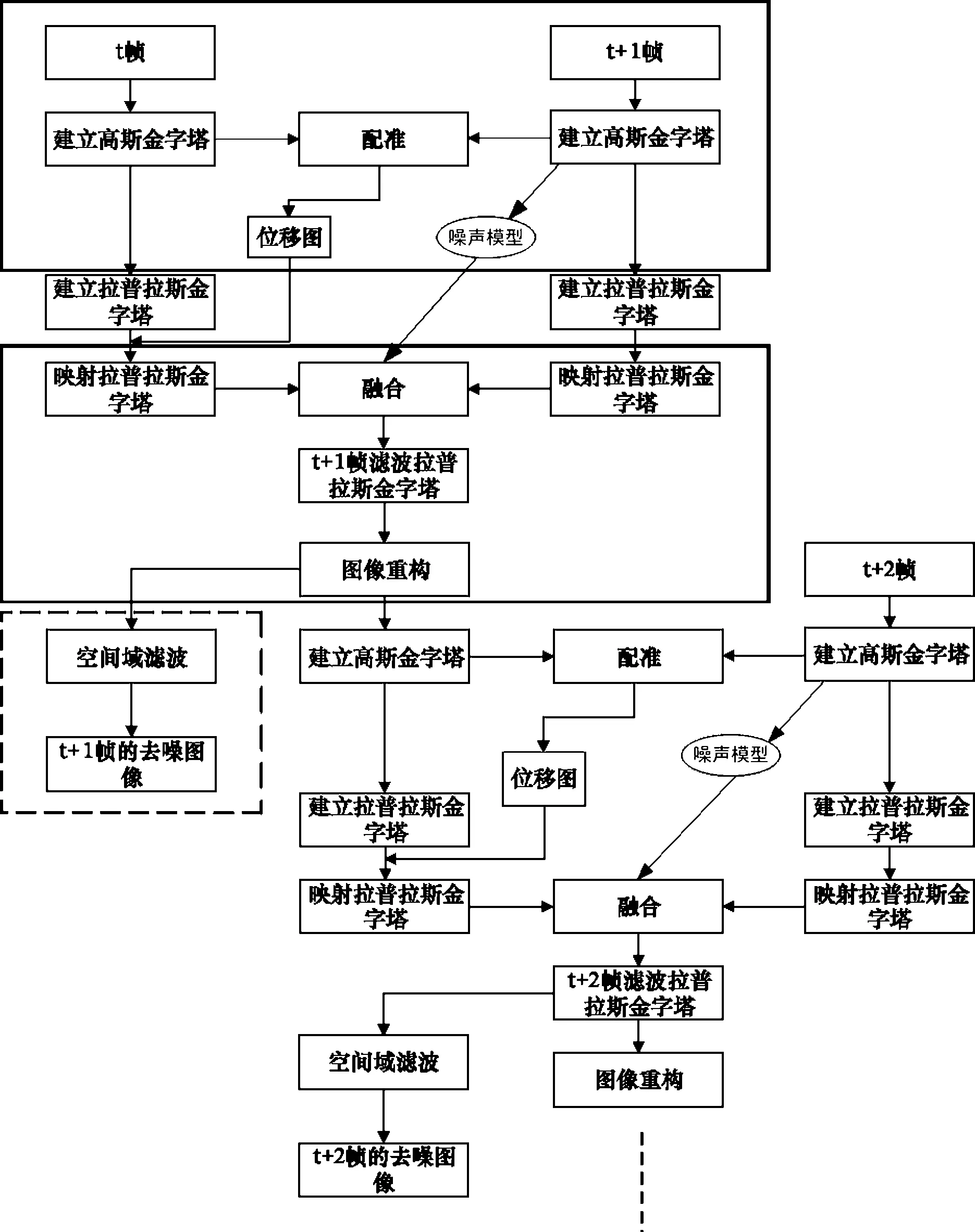
圖1 本文算法流程
1.1 圖像配準(zhǔn)
圖像配準(zhǔn)是將多幀的圖像對齊。如圖1所示,建立t幀和t+1幀的高斯和拉普拉斯金字塔實(shí)現(xiàn)高頻殘差圖像的提取,并且依據(jù)光流法進(jìn)行圖像配準(zhǔn)得到位移圖。在圖像配準(zhǔn)時(shí)使用快速的迭代逆光流法[9]加快處理速度。同時(shí)為了進(jìn)一步減少處理時(shí)間,進(jìn)行光流匹配時(shí)在除了原始圖像這一金字塔層級以外的其他層級,采用整數(shù)級別的運(yùn)動(dòng)矢量來估計(jì)像素的運(yùn)動(dòng)。
1.2 圖像融合
本算法的關(guān)鍵在于圖像融合,融合效果相當(dāng)程度上決定了最終的去噪質(zhì)量。融合之后重構(gòu)的圖像用于IIR處理,即采用上一幀重構(gòu)后的圖像而不是未經(jīng)處理的圖像進(jìn)行下一幀的處理。IIR處理對于去噪有很好的效果但是有潛在的偽影傳播等缺點(diǎn),本文設(shè)計(jì)的插值算法對配準(zhǔn)錯(cuò)誤有很好的健壯性,降低了偽影傳播的影響。
首先利用位移圖和前一幀的金字塔Lp建立重新映射的金字塔La,于是有:

(1)
其中上標(biāo)l代表圖像金字塔的級數(shù),Al(p)代表位移圖。
最終得到的圖像金字塔是t+1幀拉普拉斯金字塔Lc與t幀拉普拉斯金字塔經(jīng)過重新映射得到的圖像Lp的融合,也即是:

(2)
其中Ic(p)和Ip(p)是與像素位置、像素值以及噪聲強(qiáng)度有關(guān)的插值函數(shù)。
為了更好地解釋本文插值算法的設(shè)計(jì)原理,設(shè)Ldelta(p)=Lc(p)-La(p)作為像素值的差,通過與公式(2)比較得:

(3)
公式(3)當(dāng)中的插值算子wc和wp分別是Ic的最小值和Ip的最大值,I是決定當(dāng)前和之前像素的最終權(quán)重的插值因子。
1.2.1 建立低照度場景下的噪聲模型
低照度場景下圖像當(dāng)中的信息很少,相應(yīng)的噪聲比例也就越大,因此需要針對低照度的場景建立相應(yīng)的噪聲模型用于輔助圖像融合。本文的數(shù)據(jù)集是基于當(dāng)前手機(jī)主流圖像傳感器在低照度場景下建立的數(shù)據(jù)集。噪聲建模結(jié)合了文獻(xiàn)[10-11]高斯-泊松噪聲模型的方法,采用純時(shí)域疊加的方式得到參考圖像,比較噪聲圖像與參考圖像的差異得到高斯-泊松噪聲模型。需要注意的是低照度場景下數(shù)字增益也會(huì)影響圖像和噪聲數(shù)據(jù),因此為了提升噪聲模型的泛化性能,本文將數(shù)字增益也列入噪聲模型當(dāng)中,具體的噪聲模型滿足公式(4):

(4)
p為圖像像素值,g代表數(shù)字增益,n(p)代表圖像像素的標(biāo)準(zhǔn)差,a、b為曲線擬合參數(shù)。
依據(jù)公式(4)計(jì)算進(jìn)而得到每一個(gè)像素的噪聲水平nl(p)。由于算法的處理是在圖像金字塔上實(shí)現(xiàn)的,因此針對于不同的圖像金字塔層級l需要建立不同的噪聲模型,應(yīng)用到當(dāng)前場景的算法流程當(dāng)中進(jìn)行算法下一步的處理。
1.2.2 自適應(yīng)插值算子wc和wp
wc和wp分別代表當(dāng)前圖像和前一幀圖像融合時(shí)的整體權(quán)重,對應(yīng)地決定了去噪強(qiáng)度的下限和上限。wc越小,wp越大,去噪強(qiáng)度越大,相應(yīng)的引入偽影也更多;wc越大,wp越小,引入的偽影會(huì)變少,但是去噪強(qiáng)度變小。算子在圖像融合過程中起到平衡去噪強(qiáng)度和偽影的作用。同時(shí)圖像金字塔的層級對應(yīng)了不同的圖像信號頻率,在不同層級選擇不同的算子,根據(jù)最終圖像去噪質(zhì)量的客觀指標(biāo)和主觀評價(jià)得到最佳的算子搭配,這樣就能得到圖像質(zhì)量更好,偽影更少的圖像。
由于本文的去噪處理是針對視頻而言的,某一幀圖像插值算子的權(quán)重并不能適用于視頻內(nèi)的全部圖像。如果在視頻流當(dāng)中采用恒定的插值算子wc和wp,當(dāng)前幀所占整體權(quán)重維持不變,即相當(dāng)于在視頻處理的后續(xù)幀當(dāng)中弱化了去噪性能,甚至引入了噪聲。這樣得到的去噪效果在視頻流的前半部分提升了,后半部分卻下降了,不能維持去噪效果的提升,因此需要在IIR處理過程當(dāng)中不斷的調(diào)整wc和wp。本文在視頻流去噪處理當(dāng)中設(shè)計(jì)動(dòng)態(tài)的插值算子wc和wp,使得處理結(jié)果不僅能夠?qū)崿F(xiàn)圖像去噪效果的提升,而且能夠維持整個(gè)視頻去噪效果提升的穩(wěn)定性,具體的設(shè)計(jì)思想和方式如下文所述。
所提出的TSF算法基于IIR處理,處理的是重構(gòu)后的前一幀圖像和當(dāng)前幀,重構(gòu)后的圖像是經(jīng)過去噪處理的圖像,噪聲強(qiáng)度是減小的,因此在避免引入偽影的同時(shí)應(yīng)當(dāng)逐漸增大重構(gòu)后圖像的整體權(quán)重wp。本文采用有限脈沖響應(yīng)(Finite Impulse Response,F(xiàn)IR)多幀降噪的算法思想來具體地改變wc和wp:即假設(shè)光流法得到的運(yùn)動(dòng)矢量結(jié)果是準(zhǔn)確的,不包含塊匹配錯(cuò)誤,得到去噪圖像也就是計(jì)算若干張?jiān)肼晥D像配準(zhǔn)之后的融合結(jié)果。將FIR處理的思想應(yīng)用到IIR處理當(dāng)中得到動(dòng)態(tài)的插值算子wc以及wp如公式(5)、(6)所示:

(5)
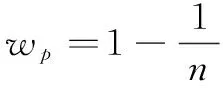
(6)
公式當(dāng)中的n表示視頻流處理的幀序。
隨著視頻流的輸入,當(dāng)前幀所占的比重在處理過程中不斷降低,可以保證在視頻流處理后期不會(huì)引入過多的噪聲,穩(wěn)定已有的去噪效果。
1.2.3 插值因子I的設(shè)計(jì)
插值因子I的選擇是圖像融合步驟的關(guān)鍵因素。wc和wp僅僅代表當(dāng)前圖像和前一幀圖像融合時(shí)的的整體權(quán)重,而插值因子I則決定了融合步驟圖像每一個(gè)像素的具體權(quán)重。在設(shè)計(jì)插值因子I時(shí)要考慮到不同的時(shí)空域處理對圖像的影響,以在最少的偽影條件下得到更好的去噪效果。同時(shí)要考慮到在視頻前期去噪處理過程中由于配準(zhǔn)錯(cuò)誤沒有得到很好的配準(zhǔn)效果時(shí),算法處理需要更加保守以免在當(dāng)前幀引入偽影。
對于I采用了文獻(xiàn)[8]基于噪聲改變和像素差異的插值算子的改進(jìn)方法,以sigmod函數(shù)形式實(shí)現(xiàn)插值因子改進(jìn)。
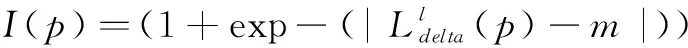
(7)
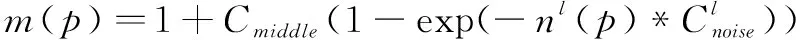
(8)
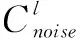
不同的噪聲等級和像素值會(huì)令插值因子I有所差異,在不同的取值區(qū)間也會(huì)使I有不同的變化速度。在高噪聲等級條件下盡管由于配準(zhǔn)錯(cuò)誤造成的像素值差異依然產(chǎn)生,此時(shí)的I依然可以靈敏的調(diào)節(jié),通過令插值因子在接近0的過程有更大的波動(dòng)范圍,得到既能阻止來自之前幀的圖像成分以減少偽影,又能取得更強(qiáng)去噪效果的處理結(jié)果。
為了防止偽影的過度傳播,在對于I> 0.5的像素位置算法設(shè)置了一鍵關(guān)閉時(shí)域去噪效果的設(shè)計(jì),此時(shí)使用空間域的雙邊濾波處理配準(zhǔn)錯(cuò)誤的區(qū)域,達(dá)到時(shí)空域聯(lián)合去噪的處理效果。
1.3 空間域?yàn)V波處理
本文處理的圖像是基于低照度場景下的噪聲視頻圖像,因此單純的時(shí)間域去噪處理并不能達(dá)到最理想的去噪效果。雖然在本算法融合步驟的處理之中包含了空間域去噪的處理,但是圖像配準(zhǔn)錯(cuò)誤的區(qū)域并不占據(jù)很多的成分,導(dǎo)致空間域去噪占比也相當(dāng)有限。因此在得到當(dāng)前幀的重構(gòu)圖像之后,在該圖像上進(jìn)行空間域去噪的處理,例如雙邊濾波、引導(dǎo)濾波[12]、非局部均值算法[13-15]等可以繼續(xù)提升圖像質(zhì)量。所提出的TSF算法采用了與BM3D[7]算法當(dāng)中“兩步估計(jì)”類似的思想,先得到相對噪聲較小的圖像,再在此圖像之上實(shí)現(xiàn)接下來的空間域去噪處理,得到峰值信噪比和結(jié)構(gòu)相似度更好的去噪圖像。為了降低復(fù)雜度,本文采用雙邊濾波空間域去噪處理。同時(shí)為了防止視頻流處理過程中空間域?yàn)V波平滑效果的傳播,如圖1所示,算法在進(jìn)行空間域雙邊濾波之前就將t+1時(shí)刻的重構(gòu)圖像去與t+2時(shí)刻圖像重復(fù)執(zhí)行配準(zhǔn)和融合等IIR處理,這樣可以在達(dá)到更好的去噪效果的同時(shí)有效地防止細(xì)節(jié)平滑的傳播。
2 實(shí)驗(yàn)結(jié)果與對比
2.1 數(shù)據(jù)集的選擇與處理
當(dāng)前的數(shù)據(jù)集采用當(dāng)前手機(jī)主流4800萬像素圖像傳感器在低照度場景下獲取。數(shù)據(jù)集包含了36種場景,光照條件包含0.32lux、0.8lux和1.5lux;曝光時(shí)間包含1/15秒和1/30秒;場景包含靜態(tài)、動(dòng)態(tài)(大運(yùn)動(dòng)和小運(yùn)動(dòng))、色卡、手持、窗戶六個(gè)場景,每個(gè)場景拍攝60幀圖片(色卡場景除外),共計(jì)1848張圖片,數(shù)據(jù)集大小17.4G。由該圖像原始數(shù)據(jù)經(jīng)過去黑電平,合并的圖像讀出方式等預(yù)處理得到灰度圖像數(shù)據(jù),進(jìn)行下一步去噪處理。
2.2 結(jié)果對比與分析
本文算法的處理是在Intel Core i7 10750H 64位操作系統(tǒng),16G內(nèi)存,Visual Studio 2015平臺下進(jìn)行的。所提出的TSF算法在0.8lux光照,曝光速度30f條件下的視頻流處理效果折線圖以及各個(gè)場景下與VBM4D[7]、實(shí)時(shí)視頻去噪[8]等方法的結(jié)果數(shù)據(jù)對比如圖5和表1到表6所示。
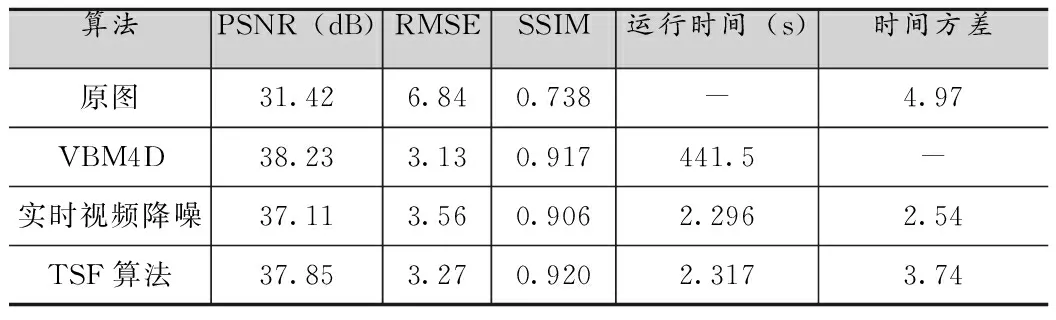
表1 0.32lux光照,曝光頻率30f的靜止場景處理結(jié)果對比
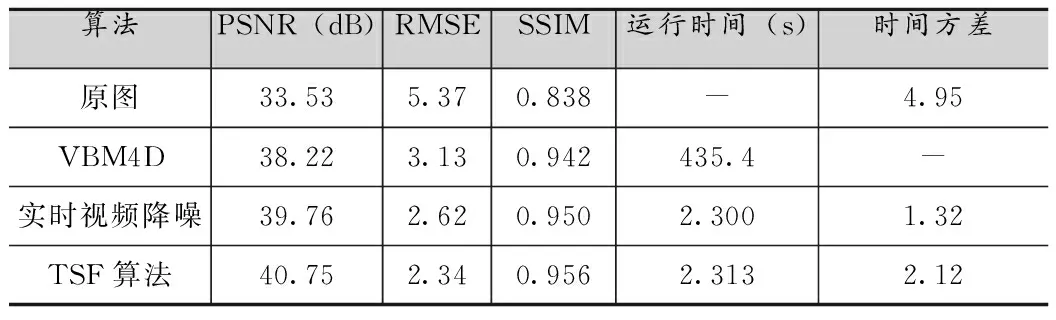
表2 0.32lux光照,曝光頻率15f的靜止場景處理結(jié)果對比

表3 0.8lux光照,曝光頻率30f的靜止場景處理結(jié)果對比
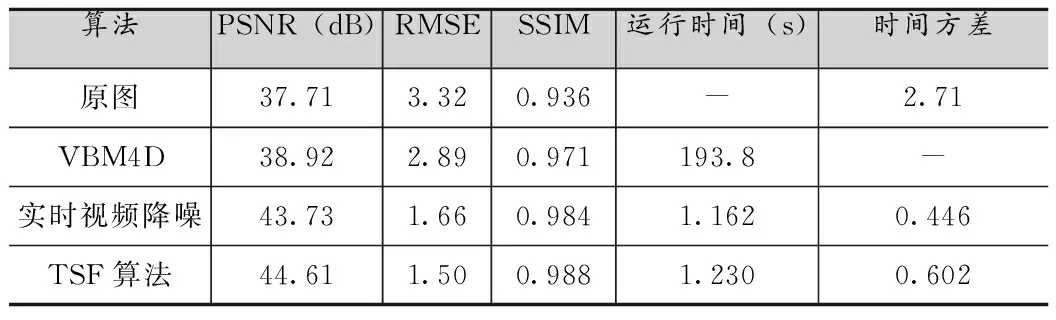
表4 0.8lux光照,曝光頻率15f的靜止場景處理結(jié)果對比

表5 1.5lux光照,曝光頻率30f的靜止場景處理結(jié)果對比

表6 1.5lux光照,曝光頻率15f的靜止場景處理結(jié)果對比
由圖2和表1到表6可知,所提出的TSF算法在峰值信噪比(PSNR)、均方根誤差(RMSE)、結(jié)構(gòu)相似度(SSIM)和視頻流處理穩(wěn)定性方面(圖2)得到了更好的客觀指標(biāo),但是由于添加了空間域去噪的處理,相應(yīng)的處理時(shí)間延長約0.01-0.02s,時(shí)間方差也依據(jù)具體環(huán)境有所上升。以表2為例,在光照為0.32lux,曝光速度15f條件下,TSF算法比實(shí)時(shí)視頻降噪[8]算法PSNR提高了0.99dB,RMSE降低了0.28,SSIM也有所提升,相比而言處理時(shí)間僅僅延長了0.013s,時(shí)間方差也只提高了0.8左右。這是因?yàn)門SF算法采用了低照度場景下的噪聲建模方式,同時(shí)針對該場景利用時(shí)空域相結(jié)合的去噪方式,對于采用的數(shù)據(jù)集產(chǎn)生了更好的去噪效果,顯著提高了圖像的質(zhì)量,相比于實(shí)時(shí)視頻去噪算法[8]提升效果明顯,和一些其他如VBM4D[7]這種離線復(fù)雜度很高的算法也有很好的可比性。
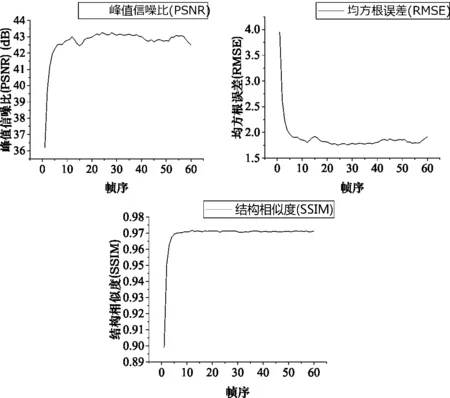
圖2 (a)、(b)、(c)分別為0.8lux光照,曝光速度為30f的場景下視頻流處理PSNR、RMSE、SSIM結(jié)果
2.3 主觀評價(jià)對比與分析
2.3.1 靜態(tài)場景比較
由圖3可以看出VBM4D[7]算法由于包含多次的塊匹配,因此對于圖像的周期紋理去噪效果最好,但是考慮到處理時(shí)間可以知道它的復(fù)雜度很難實(shí)現(xiàn)實(shí)時(shí)化處理。本文的算法處理結(jié)果在主觀去噪效果上與VBM4D[7]算法相近,并且明顯優(yōu)于實(shí)時(shí)視頻去噪[8]算法。算法沒有采用塊匹配的策略,并且針對低照度場景做了相應(yīng)的噪聲建模和插值算子優(yōu)化,添加了空間域?yàn)V波的算法處理,獲得了相比于VBM4D[7]算法處理時(shí)間的優(yōu)化和比實(shí)時(shí)視頻降噪[8]算法更好的主觀去噪效果。

(a)(b)
2.3.2 動(dòng)態(tài)場景比較
與靜態(tài)場景相比,動(dòng)態(tài)場景的去噪效果更能反映算法的有效性和應(yīng)用性。圖4為0.8lux光照強(qiáng)度,曝光速度每秒30幀的動(dòng)態(tài)場景下視頻流部分連續(xù)幀去噪結(jié)果,比較可以看出先經(jīng)過頻域分隔處理的時(shí)空域去噪,然后通過空間域去噪處理之后,算法的去噪效果明顯,并且在本文設(shè)計(jì)的動(dòng)態(tài)插值算子調(diào)節(jié)下盡量避免了產(chǎn)生偽影、撕裂等缺陷,反映出本文動(dòng)態(tài)插值算子設(shè)計(jì)的有效性。

(a)(b)
3 結(jié)語
對于傳統(tǒng)視頻去噪方法處理低照度場景視頻的去噪效果有限,并且塊匹配方法計(jì)算復(fù)雜度過高,處理時(shí)間過長等問題,本文提出了一種相對快速的視頻去噪方法。所提出的TSF算法建立包含數(shù)字增益的低照度圖像噪聲模型,結(jié)合了時(shí)空域的降噪方法,同時(shí)利用高斯和拉普拉斯金字塔實(shí)現(xiàn)了頻域的處理,相比于實(shí)時(shí)視頻去噪算法[8]在客觀的評價(jià)指標(biāo)PSNR、RMSE、SSIM等方面得到了較高的提升,達(dá)到了優(yōu)秀的去噪效果,同時(shí)并沒有引起很大的額外時(shí)間處理開銷。在主觀評價(jià)方面也得到了很強(qiáng)的圖像去噪增強(qiáng)的感受。算法的不足之處在于還沒有實(shí)現(xiàn)實(shí)時(shí)處理,因此在接下來的工作當(dāng)中要在保持去噪效果的同時(shí)優(yōu)化處理時(shí)間,進(jìn)一步優(yōu)化算法和降低算法的復(fù)雜度。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
好日子(2021年8期)2021-11-04 09:02:46
小學(xué)生學(xué)習(xí)指導(dǎo)(爆笑校園)(2020年6期)2020-07-03 10:01:10
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
攝影之友(影像視覺)(2018年12期)2019-01-28 09:01:02
攝影之友(影像視覺)(2018年12期)2019-01-28 09:01:02
中華詩詞(2018年11期)2018-03-26 06:41:34
小學(xué)生學(xué)習(xí)指導(dǎo)(低年級)(2017年11期)2017-10-23 01:32:36
Coco薇(2016年8期)2016-10-09 02:11:50
中國醫(yī)藥科學(xué)(2015年19期)2015-02-27 12:33:11
