基于雙層樹狀支持向量機的觀點挖掘與傾向分析
2021-08-09 10:27:12孫紅黎銓祺趙娜
智能計算機與應用 2021年3期
關鍵詞:數據挖掘
孫紅 黎銓祺 趙娜


摘 要: 本文通過進行大量預處理工作,將經過詞袋模型和Word2Vec兩種不同向量化方法處理后的文本數據分別輸入到SVM和LSTM模型中,訓練出可以識別文本情感傾向的模型。進而對新產生的評論進行分類。根據實際數據量的傾斜狀況,基于傳統機器學習算法支持向量機(SVM),本文提出雙層支持向量機,采用2種不同的方法分別訓練模型并預測。最后再使用深度學習算法長短時記憶模型(LSTM)再次訓練并預測,并對這3種方法做出比較和總結。結果顯示,雙層SVM比單層SVM的準確度提高了8個百分點;而LSTM比單層SVM低了2個百分點,比雙層SVM低了接近10個百分點。
關鍵詞: 商品評論; 網絡爬蟲; SVM; LSTM; 情感分類; 數據挖掘
文章編號: 2095-2163(2021)03-0044-04 中圖分類號:TP181 文獻標志碼:A
【Abstract】In this paper, a large amount of preprocessing work is carried out, and the text data processed by the following two different vectorization methods as ?the word bag model and Word2Vec are input into the SVM and LSTM models, respectively to train a model that can recognize the emotional tendency of the text. Further the newly generated comments are classified. According to the tilt of the actual data volume, based on ?support vector machine (SVM) that is the traditional machine learning algorithm,this paper proposes a two-layer support vector machine,using two different methods to train the model and predict. Thus,the deep learning algorithm long-term memory model (LSTM) is used to train and predict again, and the three methods are compared and summarized. The results show that the accuracy of the two-layer SVM is 8 percentage points higher than that of the single-layer SVM; while the LSTM is two percentage points lower than the single-layer SVM, which is nearly 10 percentage points lower than the double-layer SVM.
【Key words】 product reviews; Web crawler; SVM; LSTM; emotion classification; data mining
0 引 言
根據2020年9月第47次的《中國互聯網絡發展狀況統計報告》[1]顯示,截至2020年6月,國內網民規模達9.40億,相較于上半年增長了3 625萬,普及率達67.0%,較2020年上半年提升2.5個百分點。互聯網時代,人們普遍喜歡通過社交網絡分享自己的生活和表達自己的觀點,比如在朋友圈中表達日常生活中的快樂或者憂郁等情緒;在某個新聞App上發表自己對某件事情的看法;在購物網站上發表對某物品的使用感受。因此,在互聯網中每天都會產生大量的用戶評論,并且儲存在互聯網數據庫中。如果能夠充分地利用并挖掘這些信息,必然可以實現多種有效目的。但是,如果僅通過人工來對這些數據進行瀏覽和分析,則無疑會耗費大量人力資源,并且不能保證結果的準確性和可用性。這時就可以利用計算機強大的計算能力來幫助人們快速并準確地從這些海量主觀性文本中分析出有用的信息,這就是文本的情感分析技術。
本文主要研究的是網購商品評論的情感分析技術,即從用戶評論中通過文本挖掘技術提取信息。如果用戶可以快速方便地從海量的主觀文本中找尋到自己所需要的信息來指導自己的消費,那么對于用戶的購物體驗將會得到提升。
1 相關研究綜述
1.1 國內外研究現狀
情感分析最早由Nasukawa等人[2]提出。而文本的情感分析也叫文本意見挖掘或文本觀點挖掘。更嚴格來說,兩者的側重點并不相同,文本意見挖掘根據給定的一段話中的文字或符號來判斷這段話是趨向正面、還是負面。而文本觀點挖掘更加偏重于理解這段文本真正的內在含義。
1.2 情感分析研究現狀
本文最終定為文本意見挖掘,即判斷目標文本表達了哪種情緒,分析后將情緒分為褒義、貶義兩類;此外,一些比較復雜的分析則可以根據人的一般情緒來做區分,但從本質上來說都屬于文本分類的任務。根據訓練方式的不同,文本分類又可以分為有監督學習和無監督學習,對此擬做闡釋分述如下。
(1)無監督學習。最大的特點在于不需要具有標簽的數據集。所以,無監督學習可以減少大量繁瑣的標注工作。Turney[3]根據文本中的形容詞或副詞短語的平均語義傾向,對來自4個不同領域的文本進行聚類。陶婭芝[4]使用基于Word2Vec的無監督方法對某個品牌手機的評論進行分類,避免大量的標注工作。
(2)有監督學習。需要大量已經標注好的數據,并且需要建立數學模型在這些標注好的數據中自動學習出數據的內在規律,從而根據這些內在規律完成情感分析任務。Pang 等人[5] 將樸素貝葉斯、最大熵分類和支持向量機用于電影評論的情感分類。
有監督學習往往需要用到已有標注好的語料進行訓練,但是標注數據的獲取卻是一個較為繁瑣的過程。而社交媒體網站就是一個天然的標注語料庫,社交網絡上的語料往往帶有強烈的感情傾向,Bermingham等人[6]通過監測分析社交網絡上公眾對選舉候選人的評論來預測政治選舉的最終結果。韓萍等人[7]使用一種基于自注意力機制的模型E-DiSAN來對社交網絡評論文本的情感進行分類。但是,社交網站上通常沒有用戶的打分,只是一些帶有感情色彩的主觀性文本。而在這些文本中一般都夾雜著表達用戶心情的特殊表情符號。崔安頎[8]把特殊情感符號加入情感候選詞庫,作為其中一類情緒來進行情感分析。當然,如果采用這樣的標注方法往往會伴隨著許多噪聲, Go等人[9]及Pak等人[10]在遠程監督的模型框架下,通過多重數據預處理,達到了去除噪聲的效果。王義真等人[11]利用n-gram的特性、詞聚類的特征、詞性標注的特征及否定的特征等構建出基于SVM的高維度混合特征算法模型,將其運用到短文本情感分類后,準確率得到了較大的提升。此外,還有許多應用于情感分析的方法,如SVM[12]、依存句法[13]、卷積神經網絡[14]、情感詞典[15]等。
2 數據預處理
從目標網站中爬取到的數據并不能直接放入模型中,需要對數據進行清洗與預處理。過程包括獲取目標網站URL、獲取對應Jason頁面、編寫正則表達式、編寫網絡爬蟲、循環爬取評論數據等。并將爬取得到的數據轉化為可以輸入模型的數據,具體步驟可分述如下。
步驟1 替換和去除特殊符號。如果某個特殊符號與文本內容無關,則將其剔除;若其與文本內容有一定的關聯,則選擇一個通用詞進行代替,比如遇到“666”、“6”、“耐斯”等詞匯則使用“好”字將其代替。
步驟2 繁轉簡。針對每個用戶的輸入法和地區的不同,某些評論可能會出現繁體字。
步驟3 長句截斷。由于傳統支持向量機無法對超長句進行分析,這里將長句截斷成短句。
步驟4 中文分詞。對上一個步驟截取的短句進行分詞,并創建自定義詞典。進行多次分詞并篩選錯誤詞匯加入自定義詞表,最終得出一組比較完整的中文詞。
步驟5 將步驟4得到的詞匯進行篩選,剔除出現次數不超過5次的詞匯,保留剩余詞匯作為詞袋。詞袋中根據每個詞出現的次數將詞按高到低進行,從1開始給每個詞做上數字標記。
步驟6 創建評論向量numpy矩陣,將步驟4得到的每條評論的詞條與詞袋中的詞進行匹配,如果能匹配到,則用詞袋詞匯對應的數字編號來替代。最終得到一條條數字串評論向量,將所有的數字串評論向量進行拼接,限定長度,不足長度補0,求得一個數字串評論向量組成的numpy矩陣。
3 建立分析模型與訓練
3.1 支持向量機
支持向量機(Support Vector Machine,SVM)是 Cortes 等人[16]在 20 世紀提出的用于解決分類問題的一種算法。SVM的應用非常廣泛,并已在多個領域取得研究成果。石強強等人[17]通過增加情感詞典的種類、提高系統對網絡新興詞匯和特殊表情符號的識別,使用支持向量機模型對某些酒店的網站評論進行情感分類。郝曉燕等人[18]分別使用支持向量機算法、KNN算法和最大熵模型進行了基于特征詞布爾值的中文文本分類實驗。
一個普通的 SVM 就是一條普通直線,這條直線用來完美劃分線性可分問題的2個類別,如圖 1所示。
通過引入核技巧將低維數據映射到高維空間可以提升模型的效果。類似于這種將某個特征空間的向量映射到另一個特征空間的函數就稱為核函數[16],由于在 SVM 優化中,所有的運算表達都是內積,所以,這里可以把內積運算過程替換成核函數,從而不必做優化運算。
3.2 雙層樹狀SVM
對單層普通的支持向量機,結果顯示分類效果并不明顯。對數據進行分析得出,原因是數據傾斜非常嚴重,爬取的數據包含的正、負、中性評論分布嚴重不均勻。正向評論數量為12 000條,中性評論數量為2 000條,負向評論數量為6 000條。
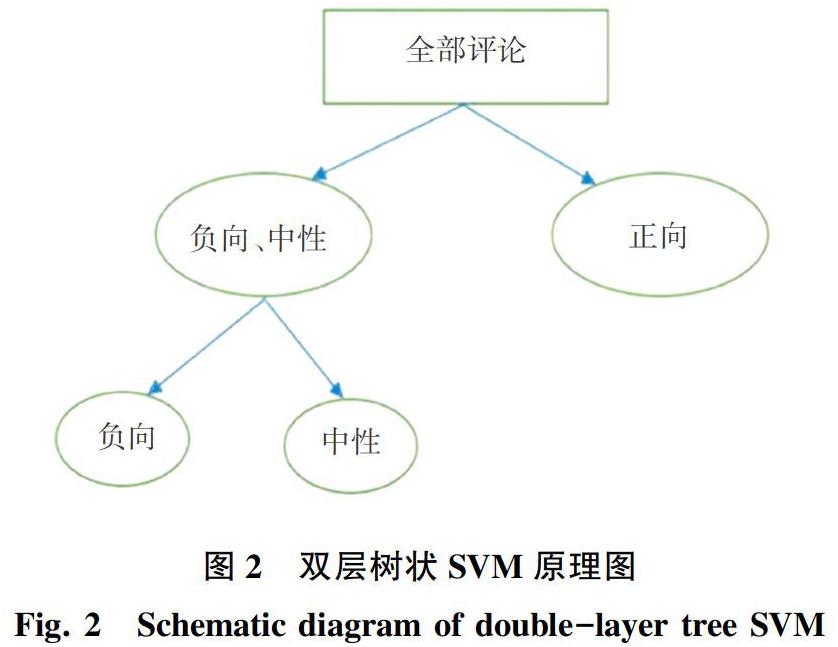
為了能夠有效緩解數據傾斜所帶來的問題,本文提出雙層支持向量機的方法,原理如圖2所示。
圖2中,首先將中性和負向評論作為一類,與正向評論進行劃分。再對中性和負向評論進行劃分。這樣在理論上就將數據傾斜帶來的誤差降低到最小。
先將中性和負向評論的標簽置為0,與正向評論的標簽1相區分。處理好的數據作為總的數據輸入,步驟同單層支持向量機,引入KFold劃分數據,訓練模型,驗證模型。
4 結果對比與分析
設置好超參數后,使用之前分批處理過的京東商城和淘寶網的評論語料文本分別進行訓練和測試,得到數據見表1。
由表1的結果可以看出:雙層Tree-SVM表現效果最好,目前熱門的循環神經網絡的表現要遜色于普通SVM。究其原因,分析后可知:
首先,普通SVM在分類性能上已經相對比較成熟,對于這些特征明顯,特征數量眾多的文本,則能做出很好的區分。
其次,雙層Tree-SVM是專門針對這個實驗數據集的特征(三分類數據分布不均,正向評論數量遠遠大于負向和中性評論的數量)而產生的。所以,能在普通SVM的基礎上,更好地切合這個數據集,從而表現出更佳的性能。
5 結束語
本文首先分析了Web 2.0 時代的到來對當今社會產生的沖擊,以及網絡數據的發展態勢。然后,提出核心技術:情感分析技術。簡單介紹了部分經典以及當下流行的幾種情感分析的算法模型。進而,分析數據獲取的方式,提出網絡爬蟲的概念,介紹幾種不同的網絡爬蟲框架,并分析爬取過程中可能出現的問題以及解決方法;根據實際情況編寫2套分別適用京東和天貓的網絡爬蟲,循環爬取網站評論數據,進行分批式存儲。在此基礎上,分析爬取的數據,總結規律,根據實際數據情況,提出方法:普通支持向量機、雙層樹狀支持向量機(Tree-SVM)和長短時記憶模型(LSTM)。最后清洗數據,主要包括中文分詞、去停用詞、文本向量化等,將數據輸入進算法模型進行訓練并驗證。通過多次訓練和驗證,雙層樹狀SVM在準確率上表現為89.78%,與普通SVM相比高出8個百分點;而LSTM的準確率僅為79.46%,但這并不能表示LSTM在性能上就不如傳統機器學習方法,分析原因可能是數據量的不足,造成神經網絡未能有效訓練。
關于分詞方面,本文使用結巴分詞默認的通用詞典,而對于一些手機評論中特有的詞語,比如“吃雞”、“打王者”、“王者榮耀”等則需要自行手動添加進去,由于研究時間有限,難免會有遺漏,而結巴分詞的新詞識別功能也只對2個字的詞語有效果。需要構建出一個針對電子產品的用戶字典,更加準確地分詞。再比如一些網絡上最近才出現的新興詞匯:“馬甲”、“水友”、“水軍”、“帶躺”、“躺贏”等等,這些詞往往具有很強的情感傾向,在今后的分析中可以做更進一步改進。
參考文獻
[1]中國互聯網絡信息中心. 第46 次中國互聯網絡發展狀況統計報告[R]. 北京:中共中央網絡安全和信息化委員會辦公室,2020.
[2] YI J,NASUKAWA T,BUNESCU R,et al. Sentiment analyzer: extracting sentiments about a given topic using natural language processing techniques [C]//Third IEEE International Conference on Data Mining. Melbourne, FL, USA: IEEE,2003: 427-434.
[3] TURNEY P D. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews [C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA,USA:Association for Computational Linguistics,2002:417-424 .
[4] 陶婭芝. 基于word2vec和自訓練的無監督情感分類方法[J]. 科技風, 2019(12):92-93.
[5] PANG B,LEE L,VAITHYANATHAN S. Thumbs up? Sentiment classification using machine learning techniques [C]// Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing-Volume 10. Association for Computational Linguistics. ?New York: Association for Computational Linguistics,2002: 79-86.
[6] BERMINGHAM A,SMEATON A. On using Twitter to monitor political sentiment and predict election results[C]// Proceedings of the Workshop on Sentiment Analysis where AI meets Psychology (SAAIP 2011). Chiang Mai, Thailand:Asian Federation of Natural Language Processing,2011:2-10.
[7] 韓萍,孫佳慧,方澄,等. 基于情感融合和多維自注意力機制的微博文本情感分析 [J]. 計算機應用,2019,39 (S1): 75-78.
[8] 崔安頎. 微博熱點事件的公眾情感分析研究[D]. 北京:清華大學,2013.
[9] GO A, BHAYANI R, HUANG L. Twitter sentiment classification using distant supervision[R]. CS224n Project Report, Stanford: ?Digital Library Technologies Project,2009.
[10]PAK A, PAROUBEK P. Twitter as a corpus for sentiment analysis and opinion mining[C]// International Conference on Language Resources and Evaluation(Lrec 2010). Valletta, Malta:dblp, 2010:1320-1326.
[11]王義真,鄭嘯,后盾,等. 基于SVM的高維混合特征短文本情感分類[J]. 計算機技術與發展,2018,28 (2):88-93.
[12]鄧君, 孫紹丹, 王阮,等. 基于Word2Vec和SVM的微博輿情情感演化分析[J]. 情報理論與實踐, 2020,43(8):112-119.
[13]梁曉敏,徐健. 輿情事件中評論對象的情感分析及其關系網絡研究 [J]. 情報科學,2018,36 (2) : 37-42.
[14]陸敬筠, 龔玉. 基于自注意力的擴展卷積神經網絡情感分類[J]. 計算機工程與設計, 2020,41(6):1645-1651.
[15]安璐,吳林. 融合主題與情感特征的突發事件微博輿情演化分析 [J]. 圖書情報工作,2017 (15) : 120-129.
[16]BENNETTK, DENIRIZ A. semi-supervised support vector machines[C]//Advances in Neural Information processing systems. Denver,Colo,USA:The MIT Press, 1999,2: 368-374.
[17]石強強,趙應丁,楊紅云. 基于SVM的酒店客戶評論情感分析[J]. 計算機與現代化,2017,17(3): 117-121.
[18]郝曉燕,常曉明. 中文文本分類研究[J]. 太原理工大學學報,2006, 37(6): 710-713.
[19]HUANG Chenghui, YIN Jian, HOU Fang. A text similarity measurement combining word semantic information with TF-IDF method[J]. Chinese Journal of Computers, 2011, 34(5):856-864.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
