深度學(xué)習(xí)在影像中的算法研究
2021-08-09 11:50:30肖行
智能計(jì)算機(jī)與應(yīng)用 2021年3期
關(guān)鍵詞:深度學(xué)習(xí)
肖行
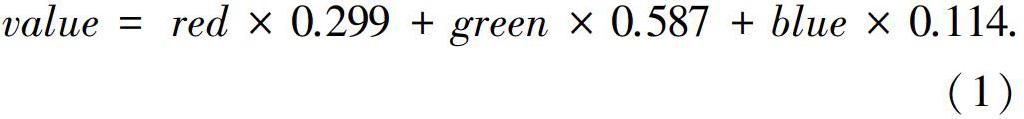
摘 要: 深度學(xué)習(xí)技術(shù)的運(yùn)用正日趨廣泛,深度學(xué)習(xí)自身的高效性和智能性受到研究者的青睞。通過(guò)對(duì)深度學(xué)習(xí)影像分類的剖析,進(jìn)一步探究深度學(xué)習(xí)在影像識(shí)別方向的應(yīng)用,介紹了主要用于影像分類識(shí)別的基于深度學(xué)習(xí)的醫(yī)療影像檢測(cè)算法,可作為開展深度學(xué)習(xí)技術(shù)運(yùn)用于醫(yī)學(xué)影像檢測(cè)研究工作的有益參考。
關(guān)鍵詞: 深度學(xué)習(xí); 影像分類; 影像識(shí)別
文章編號(hào): 2095-2163(2021)03-0215-03 中圖分類號(hào): TP391.41 文獻(xiàn)標(biāo)志碼:A
【Abstract】The use of deep learning technology is becoming more widespread, and the efficiency and intelligence of deep learning itself are favored by researchers.Through the analysis of deep learning image classification, the paper further explores the application of deep learning in the direction of image recognition, introduces the medical image detection algorithm based on deep learning, which is mainly used for image classification and recognition. The fruits could be used as a beneficial reference for the application of deep learning technology to medical imaging detection research work.
【Key words】 deep learning; image classification; image recognition
0 引 言
在復(fù)雜的背景中,一幅圖像會(huì)具有許多對(duì)象。如何識(shí)別這些對(duì)象,辨識(shí)其中的主要對(duì)象,并理解主對(duì)象與其他對(duì)象之間的關(guān)系已然成為目前的研究熱點(diǎn)。對(duì)象識(shí)別有多種方法,但大部分都不能標(biāo)記圖像的主要對(duì)象。研究可知,可以運(yùn)用改進(jìn)的RCNN[1]網(wǎng)絡(luò)來(lái)檢測(cè)和識(shí)別圖像中的多個(gè)對(duì)象,由此即提出了增強(qiáng)型的目標(biāo)評(píng)分系統(tǒng)來(lái)標(biāo)記圖像的主要對(duì)象。實(shí)驗(yàn)結(jié)果表明,該算法不僅保持了RCNN的優(yōu)越性,而且能檢測(cè)到圖像的主要對(duì)象。
近年來(lái),基于計(jì)算機(jī)的圖像識(shí)別技術(shù)獲得迅猛的發(fā)展。與之相適應(yīng),在醫(yī)學(xué)領(lǐng)域就已對(duì)人工神經(jīng)網(wǎng)絡(luò)的影像學(xué)識(shí)別展開大量研究。例如,在糖尿病視網(wǎng)膜病變的診斷中,有較高的診斷預(yù)測(cè)能力。在乳腺癌的診斷中,在乳腺癌中淋巴結(jié)轉(zhuǎn)移的病理診斷中,在胸部X射線的分類中,在食管胃十二指腸鏡檢查中分類等[2],均取得了可觀成果。需要指出的是,盡管人工智能技術(shù)被應(yīng)用于預(yù)測(cè)manikins的氣道圖像的glottic開放,但在臨床實(shí)踐中獲得的患者的喉部圖像的語(yǔ)言開放或語(yǔ)言位置的研究卻仍不多見。
氣管插管是一項(xiàng)重要的醫(yī)療程序,在自發(fā)性呼吸、氣道維護(hù)上存在困難,究其原因就是麻醉、全身麻醉和心肺問(wèn)題。氣管插管是一種生命保存的程序,可在心臟、呼吸阻塞等情況下進(jìn)行,具體來(lái)說(shuō)就是當(dāng)病患處于高危的呼吸、缺氧、通風(fēng)不足、氣道阻塞的情況下。glottis是2個(gè)聲帶間的一個(gè)開口。在執(zhí)行插管時(shí),應(yīng)將塑料插管插入氣管中。然而,氣管導(dǎo)管有時(shí)插入不適當(dāng)?shù)慕Y(jié)構(gòu),如食道,而不是glottis。如果氣管插管插入結(jié)構(gòu)出現(xiàn)錯(cuò)誤,就會(huì)導(dǎo)致嚴(yán)重的并發(fā)癥,如低氧血癥和心臟驟停[3]。因此,在插管時(shí)準(zhǔn)確地識(shí)別glottis的位置是非常重要的。
視頻喉鏡是一種將相機(jī)插入刀片的較為尖端的技術(shù)方法。視頻喉鏡可提高glottic的視覺化,減少食管插管突發(fā)事件的發(fā)生概率。關(guān)于視頻喉鏡檢查是否會(huì)增加第一次嘗試成功率,不同的研究結(jié)果仍存在差異。當(dāng)前的一項(xiàng)研究中顯示,在視頻喉鏡檢查時(shí),使用前醫(yī)院插管的成功率較低。此外,即使在視頻喉鏡檢查時(shí),食管插管也會(huì)發(fā)生。單食管插管增加了脫氣、吸氣和心臟驟停的風(fēng)險(xiǎn)。
1 ANNs的深度學(xué)習(xí)算法與反向傳播的區(qū)別
在使用ANNs的臨床實(shí)踐中,嘗試探究了在此應(yīng)用中去獲得氣道圖像的理論位置的預(yù)測(cè)模型。一個(gè)模仿動(dòng)物神經(jīng)元結(jié)構(gòu)的ANN可應(yīng)用于實(shí)現(xiàn)類似于大腦的功能。動(dòng)物的實(shí)際學(xué)習(xí)過(guò)程永遠(yuǎn)不會(huì)是非自然的數(shù)學(xué)理論,即如在反向傳播方法中一樣,也會(huì)有類似基于trial-and-error過(guò)程的生物進(jìn)化的技術(shù)內(nèi)容。因此,在本次研究中開發(fā)并應(yīng)用了基于蒙特卡羅模擬的ANNs的一種新的深度學(xué)習(xí)算法。ANN包含了成千上萬(wàn)個(gè)或更多的未知變量、權(quán)重因子和偏置值。這個(gè)新的深度學(xué)習(xí)算法是應(yīng)用蒙特卡羅模擬的優(yōu)化過(guò)程,用來(lái)確定權(quán)重因子和偏差值,使學(xué)習(xí)數(shù)據(jù)的平均訓(xùn)練誤差最小化[4]。
對(duì)于反向傳播方法,采用梯度下降方法,通過(guò)多次使用全部或部分學(xué)習(xí)數(shù)據(jù)來(lái)確定結(jié)果數(shù)值,直到根據(jù)給定的學(xué)習(xí)速率訓(xùn)練誤差達(dá)到最小為止。在此條件下,節(jié)點(diǎn)的偏壓值作為節(jié)點(diǎn)的附加權(quán)重因子,將其輸入值設(shè)定為1.0,而并不考慮偏差值是否為負(fù)的變化機(jī)制。本次研究的新算法具有與反向傳播方法完全不同的結(jié)構(gòu)。在新的深度學(xué)習(xí)算法的情況下,當(dāng)前ANN的所有學(xué)習(xí)數(shù)據(jù)的平均訓(xùn)練誤差都是在訓(xùn)練誤差達(dá)到最小的情況下反復(fù)計(jì)算的結(jié)果,而隨機(jī)選擇的權(quán)重因子和ANN的偏差值正在根據(jù)給定范圍內(nèi)隨機(jī)選擇的delts值進(jìn)行調(diào)整。當(dāng)然,該算法無(wú)需計(jì)算訓(xùn)練錯(cuò)誤的梯度,或者在訓(xùn)練階段使用所有或一部分學(xué)習(xí)數(shù)據(jù)的權(quán)重因素和偏差值來(lái)做調(diào)整,按小隨機(jī)量調(diào)整一個(gè)ANN的權(quán)重因子和偏壓值,而不是通過(guò)計(jì)算密集型梯度下降法分別應(yīng)用于所有權(quán)重因子,是與反向傳播方法中在訓(xùn)練期間的主要差異。因此,該算法簡(jiǎn)單而高效,對(duì)計(jì)算資源的要求也不高。
2 算法原理與實(shí)現(xiàn)
ANN是一個(gè)連接的簡(jiǎn)單計(jì)算元素集,稱為節(jié)點(diǎn)。通常,是一個(gè)多層的組織。總地來(lái)說(shuō),可分為:一個(gè)輸入層、多個(gè)隱藏層和一個(gè)輸出層。對(duì)于深度學(xué)習(xí)方法而言,就代表著有些ANNs可能還會(huì)包括數(shù)百個(gè)或更多的隱藏層。輸入層中的每個(gè)節(jié)點(diǎn),即輸入節(jié)點(diǎn),將接收來(lái)自外部的輸入,并將其傳送給第一個(gè)隱藏層的所有節(jié)點(diǎn)。在本次研究中,考慮到氣道圖像大小和縱橫比的不同,先把圖像轉(zhuǎn)換成正方形,再將其分辨率降到100 × 100、70 × 70、50 × 50、45 × 45、40 × 40、35 × 35、30 × 30和 25 × 25像素,并且每組應(yīng)用于ANN模型的輸入結(jié)構(gòu)。ANN的輸入節(jié)點(diǎn)的數(shù)量就等于原始?xì)獾缊D像減少分辨率后的總數(shù)。每個(gè)輸入節(jié)點(diǎn)的輸入值是相應(yīng)的像素值,即減少分辨率的氣道圖像。可以通過(guò)計(jì)算來(lái)獲得黑白彩色轉(zhuǎn)換過(guò)程中的像素值,此處會(huì)用到的數(shù)學(xué)公式可寫為:
在此基礎(chǔ)上,將該值除以最大值255,即將其轉(zhuǎn)換為0~1.0之間的值。相同的過(guò)程應(yīng)用于標(biāo)記氣道的圖像,以獲得像素值,再將圖像分為7個(gè)橫截面和7個(gè)垂直截面。該分區(qū)共生成了49個(gè)具有標(biāo)記氣道圖像的單元格。這些圖像被分為49個(gè)單元格,用來(lái)預(yù)測(cè)在氣道圖像中49個(gè)glottic的位置。
3 實(shí)驗(yàn)結(jié)果
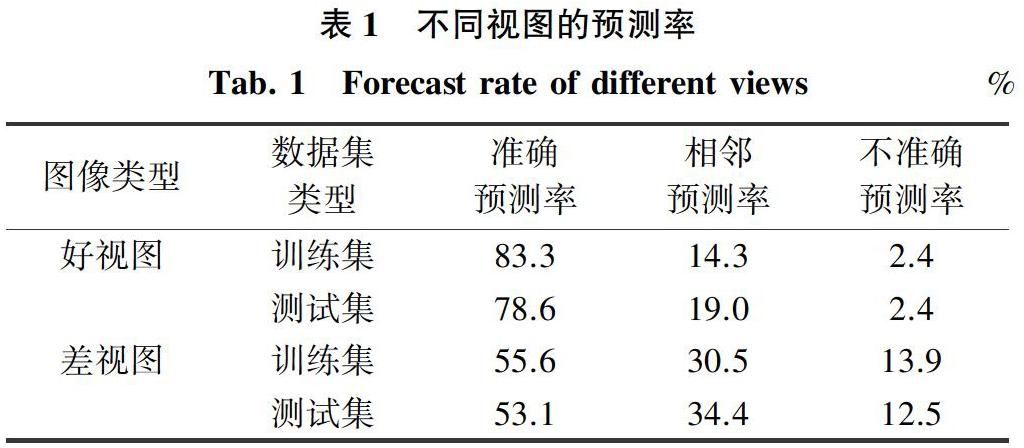
通過(guò)將訓(xùn)練集和測(cè)試集劃分為2種類型的視圖:好視圖和差視圖,以預(yù)測(cè)選擇模型的氣道位置的訓(xùn)練和測(cè)試精度,實(shí)驗(yàn)結(jié)果見表1。
表1中,準(zhǔn)確預(yù)測(cè)率表示被預(yù)測(cè)的位置與glottis重疊;相鄰預(yù)測(cè)率表示8個(gè)相鄰的相等大小的正方形,被預(yù)測(cè)的位置與glottis重疊;不準(zhǔn)確預(yù)測(cè)率表示被預(yù)測(cè)的位置與glottis不相鄰。
對(duì)于訓(xùn)練集,好視圖圖像數(shù)量是813,占81.3%;差視圖的圖像數(shù)量是187,占18.7%。對(duì)于測(cè)試集,好視圖的圖像數(shù)量為168,占84.0%;差視圖的圖像數(shù)量為32,占16.0%。對(duì)于好視圖而言,仿真得到的測(cè)試集的精確預(yù)測(cè)率為83.3%,測(cè)試集的預(yù)測(cè)率為78.6%。對(duì)于差視圖來(lái)說(shuō),測(cè)試集的準(zhǔn)確預(yù)測(cè)率為55.6%,測(cè)試集的準(zhǔn)確預(yù)測(cè)率為53.1%。
4 結(jié)束語(yǔ)
提出了一種新的基于人工神經(jīng)網(wǎng)絡(luò)(ANNs)的深度學(xué)習(xí)算法。該方法與反向傳播方法完全不同。研究中隨機(jī)選擇一個(gè)ANN的權(quán)重因子和偏置值,并在訓(xùn)練期間通過(guò)小隨機(jī)數(shù)來(lái)調(diào)整相應(yīng)數(shù)值,不需要計(jì)算訓(xùn)練誤差的梯度來(lái)調(diào)整權(quán)重因子。該算法應(yīng)用于通過(guò)視頻氣道裝置獲得的氣道圖像中g(shù)lottis的位置。在1 200個(gè)氣道圖像中,使用GlideScope R和纖維鏡檢查。對(duì)于隨機(jī)選取的1 000個(gè)訓(xùn)練集數(shù)據(jù), 利用上述算法訓(xùn)練了84個(gè)ANN模型。尋求一個(gè)ANN模型,通過(guò)減少輸入圖像分辨率,將所有訓(xùn)練設(shè)置的平均訓(xùn)練誤差最小化。隨著分辨率的降低,平均訓(xùn)練誤差降低到30×30像素的最低水平。最終,研究得到9-98-49 ANN有著最低訓(xùn)練誤差,將其作為glottis位置的預(yù)測(cè)模型,得到了最高的學(xué)習(xí)速率。選定預(yù)測(cè)模型應(yīng)用于剩余200個(gè)測(cè)試集數(shù)據(jù),以獲取測(cè)試精度,仿真后得到的準(zhǔn)確預(yù)測(cè)和相鄰預(yù)測(cè)率分別為74.5%和21.5%。將輸入圖像分辨率降低到適當(dāng)水平,能更好地預(yù)測(cè)氣道圖像中的glottis位置。本文研發(fā)的ANN模型可以幫助臨床醫(yī)生通過(guò)顯示glottis的預(yù)測(cè)位置來(lái)進(jìn)行插管。
參考文獻(xiàn)
[1]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA:IEEE,2014:580-587.
[2] 段琳琳. 基于深度學(xué)習(xí)的遙感影像分類研究[D]. 開封:河南大學(xué),2018.
[3] 左艷,黃鋼,聶生東. 深度學(xué)習(xí)在醫(yī)學(xué)影像智能處理中的應(yīng)用與挑戰(zhàn)[J]. 中國(guó)圖象圖形學(xué)報(bào),2021,26(2):305-315.
[4] 張卡,宿東,王蓬勃,等. 深度學(xué)習(xí)技術(shù)在影像密集匹配方面的進(jìn)展與應(yīng)用[J]. 科學(xué)技術(shù)與工程,2020,20(30):12268-12278.
猜你喜歡
中國(guó)教育技術(shù)裝備(2016年19期)2016-12-27 19:23:52
中國(guó)遠(yuǎn)程教育(2016年11期)2016-12-27 18:07:31
現(xiàn)代商貿(mào)工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:36:29
現(xiàn)代情報(bào)(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時(shí)代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(huì)(2016年32期)2016-12-01 15:25:53
軟件導(dǎo)刊(2016年9期)2016-11-07 22:20:49
