基于人工智能和隨機森林的心理健康分析方法研究
2021-08-15 11:36:08童歡歡
電子設(shè)計工程 2021年15期
童歡歡
(西安航空職業(yè)技術(shù)學(xué)院,陜西西安 710089)
隨著社會競爭、生活壓力的增大,不少人出現(xiàn)了焦慮、抑郁等心理疾病。近年來,心理疾病逐漸呈現(xiàn)年輕化趨勢,越來越多的年輕人出現(xiàn)心理健康問題,尤其是大學(xué)生[1-3]。然而人們對于心理健康的關(guān)注度較低,即使其已經(jīng)出現(xiàn)了一定程度的癥狀,仍然沒有意識到疾病的發(fā)生。心理疾病的出現(xiàn),嚴重影響著人們的工作和生活,開展對心理健康狀態(tài)分析方法的研究具有重要意義[4-7]。
傳統(tǒng)心理健康監(jiān)控方式相對被動、缺乏準確性,人們需要主動找心理醫(yī)生咨詢,并且進行檢測才能確定是否患有疾病[8]。而醫(yī)生主要采用的診療手段為溝通和問卷的形式,病情診斷結(jié)果在一定程度上受醫(yī)生主觀判斷的影響而有所差異。值得注意的是,傳統(tǒng)心理健康監(jiān)控方式在心理健康疾病預(yù)防方面的效果極大取決于人們對心理健康的關(guān)注程度,且對于心理疾病發(fā)展的程度、藥物的效果等缺乏合適的生物標(biāo)記來量化[9-11]。
隨著科技的發(fā)展,除了通過患者敘述自己的觀念和感受來確定病情外,越來越多的學(xué)者開始嘗試通過腦電波、心率以及皮電信號來研究心理健康是否出現(xiàn)了問題[12-13]。為了探尋更加高效、準確的心理健康判斷方法,人工智能技術(shù)在抑郁癥等心理疾病診斷方面的應(yīng)用越來越多,并取得了初步成果[14-16]。
文中著眼于大學(xué)生心理健康情況,分別從學(xué)生的生理和心理兩個角度進行心理健康分析。心率和體溫等生理信息的變化可以反映該學(xué)生的心理變化;同時,其社交平臺的言論也能反映出其心理狀態(tài)是否正常。文中使用人工智能來進行多源、異構(gòu)數(shù)據(jù)的特征提取;并使用隨機森林作為分類器來識別心理健康程度。
1 智能化心理健康分析模型
為了提高人們對心理健康的重視程度以及對自身心理健康情況的了解,文中進行了智能化心理健康分析方法研究。大學(xué)生心理健康劃分為焦慮、抑郁、恐懼、偏執(zhí)、敵對5 個維度。智能化心理健康分析方法主要是構(gòu)建智能化心理健康分析模型,模型具體框架如圖1 所示。該模型側(cè)重于心理健康的監(jiān)控、心理疾病的預(yù)判,依靠智能設(shè)備作為運行平臺和數(shù)據(jù)來源,通過對用戶的心跳速率、運動數(shù)據(jù)深度分析用戶行為信息;同時對用戶社交賬號的狀態(tài)、評論等進行關(guān)鍵詞提取,分析其情感狀態(tài)。通過多模態(tài)數(shù)據(jù)的信息挖掘可以全方面地檢測用戶心理狀態(tài)的變化,以便可以更好地預(yù)防心理疾病的出現(xiàn)。

圖1 智能化心理健康分析模型結(jié)構(gòu)框架
為了建立全方位、智能化的大學(xué)生心理健康評估模型,文中通過采集心率、社交文本等信息來構(gòu)建原始數(shù)據(jù)集并分別提取特征。然后,采用多特征融合的方式來進一步將特征向量降維。最后,利用融合后的特征向量作為訓(xùn)練樣本數(shù)據(jù)進行模型參數(shù)的優(yōu)化。文中使用人工智能的方法來確定生理信息和文本信息的特征向量。對于心理健康的分類判斷則采用了隨機森林算法。當(dāng)模型的識別精度滿足閾值時即代表模型參數(shù)已訓(xùn)練完成,可用于測試樣本數(shù)據(jù)的驗證。隨機森林算法以多次隨機采樣的方式來保障模型的多樣性,避免出現(xiàn)過飽和現(xiàn)象;同時將采樣信息輸入至多個弱分類器,來提高模型的復(fù)雜度。通過對每一個弱分類器的分類結(jié)果進行投票來確保整個模型具有較好的分類準確率以及泛化能力。
2 基于人工智能和隨機森林的分析方法
2.1 生理信息與心理健康
近年來,越來越多的學(xué)者開始關(guān)注心率與心理健康之間的聯(lián)系,試圖利用心率的變化來量化心理健康,從而建立基于心率變化的心理疾病預(yù)測模型。心率的變化,通常使用心率變異性來描述。心率變異性被定義為連續(xù)心跳之間的時間間隔長度的變化情況,通常正常人的心跳并不是保持相同的時間間隔,且當(dāng)人處于平靜、運動、焦慮時,心跳的速度也有所不同。因此,通過監(jiān)測正常人與心理疾病患者不同場景下的心率,可實現(xiàn)心理疾病的量化檢測。
心率數(shù)據(jù)通過智能可穿戴設(shè)備的傳感器采集,通常是一串時變、非穩(wěn)態(tài)的時序波形數(shù)據(jù),因此需要先進行時頻域特征值的計算,再進行數(shù)據(jù)統(tǒng)計特征計算。由于人在不同的狀態(tài)、不同的環(huán)境中心率跳動情況有所不同,因此在基于心率信息的心理健康分析模型中融入環(huán)境信息、體征狀態(tài)信息和行為信息會提高心理疾病的識別精度。環(huán)境信息主要包括測試者所在地的海拔、氣溫等;體征信息包括體溫、體表濕度;行為信息包括了步行數(shù)、步行數(shù)變化率等。
以上信息均為時序波形數(shù)據(jù),特征提取和分析過程如圖2 所示。首先分別將心率、環(huán)境、行為以及體感信息通過智能設(shè)備的傳感器采集,并進行不同頻率的離散化處理以便降低數(shù)據(jù)量、提高運算效率。然后再經(jīng)過去基和滑動窗口操作將數(shù)據(jù)中的白噪聲以及無意義數(shù)據(jù)剔除。最后分別就時域和頻域進行特征提取,并進行各個特征的數(shù)理統(tǒng)計計算。

圖2 生理信息的特征提取、分析示意圖
考慮到智能可穿戴設(shè)備中加速度計和陀螺儀所帶來的噪聲信號等干擾,需要將傳感器采集到的原始數(shù)據(jù)利用滑動窗口和去基的操作方法進行預(yù)處理。原則上,滑動窗口的大小應(yīng)設(shè)定為傳感器采樣頻率的2 倍,但為了保證快速傅里葉函數(shù)的計算,實際窗口的大小被定義為:

考慮到測試者并不是全時處于運動狀態(tài),采集到的數(shù)據(jù)中,靜態(tài)數(shù)據(jù)占據(jù)了較大的比例,為了降低靜態(tài)數(shù)據(jù)特征提取的計算量,文中采用去基操作進行靜態(tài)數(shù)據(jù)預(yù)處理。具體操作為:首先使測試者處于完全靜止的環(huán)境中,保持放松的狀態(tài)進行各項數(shù)據(jù)采集,并提取各項特征作為基準值。當(dāng)在其他環(huán)境和用戶狀態(tài)下,即可使用數(shù)據(jù)樣本減去基準值,從而有效降低環(huán)境、狀態(tài)所帶來的影響,提高計算效率。
時域特征主要有平均值、標(biāo)準差、最指、中位數(shù)等;頻域特征有直流分量、信號幅度面積和幅度統(tǒng)計特征。其中信號的幅度面積可用下式描述:

該指標(biāo)被定義為離散數(shù)據(jù)與時間軸所圍成面積的和,用于區(qū)分靜態(tài)數(shù)據(jù)和動態(tài)數(shù)據(jù)。
在進行運動狀態(tài)的數(shù)據(jù)采集時,提取特征既要保證精準度,同時也要避免計算量過大。因此,文中采用式(3)和式(4)進行時域和頻域特征值的計算,式中,i表示第i條加速度計和陀螺儀的數(shù)值,ai表示的是合成后的加速度,wi表示的是合成后的角速度。
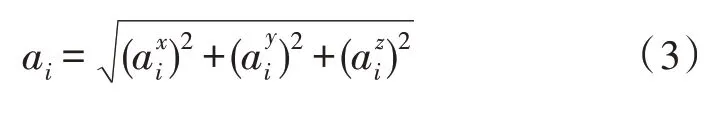

2.2 文本信息與心理健康
心率等生理指標(biāo)是人身體狀態(tài)的表現(xiàn),而人所說的話、寫下的文字則是其內(nèi)心狀態(tài)的反應(yīng)。當(dāng)人出現(xiàn)心理疾病時,其思想與正常人相比具有一定的消極性,利用其在社交平臺上的文本信息進行心理健康評估的框圖如圖3 所示。

圖3 融合了LIWC詞典的文本信息的特征向量的提取
首先進行文本特征的提取。文中采用詞袋模型來分解文本、提取特征向量。詞袋模型的關(guān)鍵在于詞典的構(gòu)建以及各個特征詞的權(quán)重計算。文中使用LIWC 詞典作為基本詞典,LIWC 詞典包含了大量的心理過程詞、社會過程詞以及語言過程詞。通過將用戶在社交論壇上的文本信息進行分詞,剔除停用詞后再與LIWC 詞典比對,由此得出文本信息中各個詞對該用戶心理健康的區(qū)分能力。
由于不同類別的詞匯作用不同,文中主要集中關(guān)注人稱代詞、否定詞、認知過程詞匯等,并對這幾類詞匯進行權(quán)重計算,具體過程如下:
1)首先統(tǒng)計LIWC 詞典中各個詞類在相關(guān)主題中出現(xiàn)的次數(shù)。
2)對上述詞頻,計算標(biāo)準差al,i并對最大值進行歸一化處理。標(biāo)準差的數(shù)值越大,表明該類詞匯越有利于區(qū)分文本信息所體現(xiàn)的情感傾向與心理健康程度。
3)確定每個詞的權(quán)重。通過判別該詞匯屬于LIWC 詞典的哪一個分類來調(diào)整該詞在甄別文本情感傾向時的權(quán)重。具體公式如式(5)所示。

文本詞向量的提取及文本信息情感傾向識別,則采用了基于隨機森林和卷積神經(jīng)網(wǎng)絡(luò)的文本信息情感傾向識別模型,具體結(jié)構(gòu)如圖4 所示。首先將上文生成的特征向量以詞向量矩陣的形式輸入至輸入層。在Attention 層中,可計算出不同詞類的標(biāo)準差,標(biāo)準差越大,表明該詞類在識別心理健康方面具有更顯著的作用。在卷積層中,利用不同大小的滑動窗口來選擇文本中的局部詞向量,進而拼接得到新的矩陣。池化層通過選擇合適的池化函數(shù)來選擇區(qū)分文本情感最有效的特征值。將全連接層中已經(jīng)完成上述處理的特征矩陣傳輸至隨機森林中進行分類。值得注意的是隨機森林中一顆決策樹的平均泛化誤差PE 與回歸函數(shù)有關(guān),具體公式如式(6)所示。

圖4 基于隨機森林和卷積神經(jīng)網(wǎng)絡(luò)的文本信息情感傾向識別模型結(jié)構(gòu)示意圖
在利用訓(xùn)練樣本進行模型訓(xùn)練時,通過反向傳播的方式來最小化交叉熵損失函數(shù),同時對各個神經(jīng)元的權(quán)重系數(shù)L2 進行正則化處理,以避免過度擬合。

3 實驗測試與數(shù)據(jù)分析
為了驗證文中所提方法的正確性,使用某大學(xué)本科生、研究生以及博士生的真實數(shù)據(jù)集作為研究對象,其年級和性別如表1 所示。為了保證模型訓(xùn)練充分、且結(jié)果有效,隨機抽取85%的樣本數(shù)據(jù)作為模型訓(xùn)練數(shù)據(jù);其余數(shù)據(jù)作為檢測數(shù)據(jù)。通過設(shè)置對照組來測試文中所述方案的性能。對照組分別采用前饋神經(jīng)網(wǎng)絡(luò)和支持向量機兩種分類器。由于隨機森林算法決策樹的數(shù)量影響著分類準確率,首先進行決策樹數(shù)量的選擇。測試結(jié)果如圖5 所示。從圖中可以看出,隨著決策樹數(shù)量的增多,分類準確率逐漸增加并趨于固定值。

表1 研究對象年級、性別統(tǒng)計情況

圖5 不同決策樹個數(shù)對分類準確率的影響
圖6 以某個研究對象的數(shù)據(jù)為例,分別使用專家評判、隨機森林、支持向量機、前饋神經(jīng)網(wǎng)絡(luò)四種方式進行心理健康程度的測試。圖中橫軸“1,2,3,4,5”分別代表焦慮、抑郁、恐懼、偏執(zhí)、敵對這五類心理健康維度。在各個維度中越靠近專家評判,表明該算法識別準確率越高。從圖中可以清晰看出,隨機森林算法作為分類器識別結(jié)果更接近專家評判。綜合所有樣本數(shù)據(jù),統(tǒng)計結(jié)果如表2 所示。文中所述方案在訓(xùn)練樣本時識別結(jié)果準確率為81.8%;測試樣本識別準確率為80.4%。兩者數(shù)值均高于支持向量機和前饋神經(jīng)網(wǎng)絡(luò)算法。

圖6 某個研究對象五類心理健康維度實驗組和對照組識別結(jié)果對比

表2 實驗組與對照組心理健康識別結(jié)果對比
4 結(jié)束語
文中使用人工智能中的卷積神經(jīng)網(wǎng)絡(luò)和隨機森林算法進行了大學(xué)生心理健康分析技術(shù)的研究。使用心率等生理信息和社交文本信息可增加判斷心理健康的數(shù)據(jù)維度,提供多層次的心理健康判斷模型。卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用使得樣本數(shù)據(jù)的特征提取更快速和準確;同時采用隨機森林算法作為分類器。經(jīng)過測試和數(shù)據(jù)分析,文中所述方案在大學(xué)生心理健康的分析、識別方面具有80.4%的準確率,與支持向量機和前饋神經(jīng)網(wǎng)絡(luò)算法相比,其具有更高的識別準確率。
猜你喜歡
品牌研究(2022年9期)2022-04-06 02:41:56
品牌研究(2022年8期)2022-03-23 06:49:06
品牌研究(2022年6期)2022-03-23 05:25:50
品牌研究(2022年1期)2022-03-18 02:01:10
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
