基于Spark的大數據清洗框架設計與實現
2021-08-16 11:17:28張菁楠
科學技術創新 2021年22期
張菁楠
(天津輕工職業技術學院,天津 300000)
大數據是目前學術和企業重點關注的問題,是指利用收集到的復雜數據信息從而創造出較為顯著的商業價值,充分的挖掘信息的潛在價值。一般來說,在大數據處理的過程中主要包含四個環節,數據采集--數據清洗--數據儲存--數據分析。數據清洗在大數據處理中起著非常關鍵的作用,隨著信息時代的到來,大量信息和海量數據引起了人們廣泛的關注,也由此加強了對數據清洗的深度研究和分析。傳統的數據清洗方法已經難以適應現代數據技術的發展,由此文章提出基于Spark的大數據清洗框架,通過組合和串聯的方式來完成數據清洗的過程,并實現數據清洗的優化。
1 Spark——ETL大數據清洗框架
1.1 框架介紹
Spark——ETL技術框架的核心是為了解決大數據清洗問題。即大數據清洗系統內包含多個大數據清洗操作單元,在數據清洗的過程中通過不同清洗單元的組合形成一套完成的清洗流水線,從而開展清洗工作。在Spark--ETL系統中清洗單元具有一定的獨立性,通過RDD的作用促進單元之間的聯系,實現數據信息的共享和傳遞,而單元的主要作用體現在原始數據從獲取到清潔直至存入大數據庫的過程。在大數據清洗流水線運行的過程中也包含多個步驟,如提取、轉化等等,在這些步驟當中包含以上或以上的大數據清晰操作單元。
Spark-ETL技術框架具有以下幾個方面的特征:
第一,高性能處理。Spark-ETL技術框架是以RDD為數據封裝對象,利用Spark的分布式計算能力實現數據清晰的系統,其性能較為高效。
第二,面對不同數據源和數據格式能夠做到兼容處理,有效的解決了數據的多樣性問題。
第三,具有較高的易用性和可擴展性,實現了不同數據單元的數據分享和傳遞,便于完成較為復雜的清洗任務。
1.2 框架原理
Spark-ETL框架的主要思路是利用清洗任務單元的組合形成較為完整的流水線進而完成數據的清洗工作。在Spark-ETL系統中具備Driver Program和Executor分離設計特性,相對于傳統的方式來說,Spark-ETL在保持原有構架的基礎上促進了Spark接口的擴展,從而更加的適合大數據的清晰。此外與原生框架進行對比,Spark-ETL實現了工作方式的轉變,在大數據清洗的過程中改變了傳統的清洗方式,通過串聯和組合的方式完成了大數據的清洗,在實際操作的過程中并不需要較為復雜的代碼編程,對相關技術人員的Spark編程能力也沒有較高的要求,就能夠完成大數據的清洗工作。除此之外是清洗流水線的設計,和普通的單線流水線進行對比,增加了多叉樹數據結構定義計算流,不僅能夠滿足Spark的內部計算模式要求,并且通過對計算過程中分支節點數據的緩存,還能夠有效的提升計算效率,為大數據清洗的優化打下了堅實的基礎。
2 相關技術分析
2.1 Spark Application提交邏輯分析
在Spark集群上Spark Application屬于獨立運行,每個Application都是相對獨立的,有屬于自己的Spark Context,彼此之間相互不影響,此外擁有Spark Context對象的程序也可以被稱之為Driver。
Spark集群有兩個部分組成,分別是Cluster Manager與Worker。在實際運行的過程中也有兩種模式,分別是Client與Cluster。Client模式是指在集群外部進行運行的Driver程序;Cluster模式與Client模式剛好相反,在其運行的過程中是在集群內部,由某個Worker啟動的Driver程序,在運行的過程中可以將結果在Web UI上進行顯示,或者是向某個接受者進行發送。在大數據清洗的過程中,更加側重于將Driver程序運行在集群外部自行管理,即Client模式,實際整個集群的模塊架構如圖1所示。
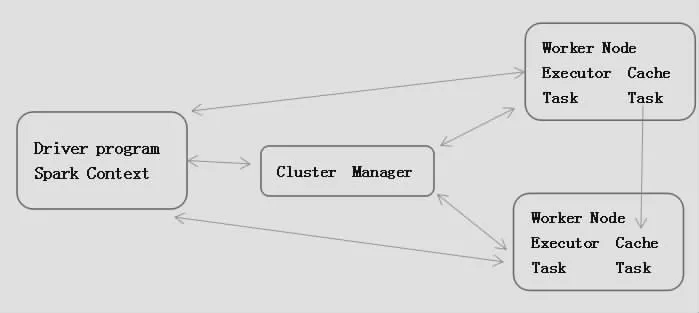
圖1 Spark集群架構圖
2.2 Spark實現ETL功能分析
目前,在大數據清洗的過程中多數的Hadoop-ETL都逐漸轉向Spark-ETL,其根本原因在于基于Spark的大數據清洗其效率更高,可擴展性更強,并且在實際操作的過程中較為簡捷。Spark SQL在Spark屬于獨立的一個模塊,其作用是處理結構化數據,為Spark-ETL系統提供了分布式查詢引擎和較為抽象的數據結構。除此之外在Spark SQL模塊中其數據接口也較為豐富,針對不同的數據來源和數據格式都能夠做好兼容和有效處理。另外基于Spark的大數據清洗還包含Spark Streaming,其為實時流數據處理接口提供了較高的可靠性設計。
3 清洗框架設計
3.1 框架架構設計
在Spark-ETL框架中其核心目標是提供大數據ETL系統充分的滿足大規模數據處理的需求。因此在Spark-ETL進行框架設計的時候其設計底層是以Spark為基礎,其設計思路為用戶通過實際操作的過程配合平臺在Spark集群內完成數據的清洗工作。Spark-ETL后臺服務系統是以Jar、Context、Job為核心,將Spark Context與實際的Job內容分離,由Server直接管理Spark Context,將提高Jar包,設計成Algorithms的程序,動態擴展到整體平臺的大數據處理功能[1]。Spark-ETL框架如圖2所示,共分為五部分,分別是Spark-ETL Web Client、Spark-ETL Job Server、Algorithms、Spark SQL、Spark ETL SDK。其中Spark-ETL Web Client與Spark-ETL Job Server屬于Web Service平臺,Algorithms代表了擴展的大數據清洗任務單元庫,通過Web Service平臺添加需要的清洗單元,并執行算法任務。Spark SQL則代表了Spark集群,此處用Spark SQL進行標識其目的是為了大數據在清洗處理的過程中主要是依賴于Spark SQL進行完成,進行Spark SQL的標識能夠更加的明確,但是在實際過程中Spark SQL所代表的是整個后臺計算服務的集群。Spark SQL、Spark-ETL Web Client、Spark-ETL Job Server所代表的是Spark-ETL中最為基礎的部分-清洗平臺Server系統。Spark ETL SDK模塊在實際運行中需要借助Algorithms模塊通過SDK接口在Job Server模塊完成提交。最后流水線配置設計涵蓋在Algorithms單元內[2]。

圖2 Spark ETL模塊架構圖
3.2 Spark-ETL Server設計
Spark-ETL Server可以將其分為三部分。Web Client為前端界面,一方面根據后臺的服務來滿足設計的需求,另一方面通過運行完善后臺服務。在Job Server設計的過程其結構模式參考了Spark-ETL Server的結構設計理念,以Jar、Context、Job為核心完成架構的設計。與此同時Spark SQL模塊在Context中實現與Job Server的連接,Spark SQL模塊屬于Spark集群,Spark是由Spark Context將Job分布到各個計算節點完成運算處理[3]。
3.3 Spark-ETL SDK設計
Spark-ETL SDK連 接 了Spark-ETL Job Server與Algorithms兩個模塊,將Spark Context由Job Server傳入到Algorithm程序內,使其完成Spark Application。在實際操作的過程中無需對原有的平臺架構進行改變,并在此基礎上提高了便捷性,增強了拓展性[4]。
在Spark-ETL SDK設計的過程中可以將其分為兩部分組成。一是Spark Job的接口定義,將清洗單元與Job Server有效的連接在一起;二是連通Spark Job,利用RDD實現了不同清洗單元的連接,促進了數據的分享[5]。
3.3.1 Spark-ETL Spark Job接口
圖3為SDK Spark Job接口設計圖,SDK Spark Job運行的主要目的是能夠支持不同類型的Context,以Spark JobBase特質為基類,其他的特質定義繼承Spark JobBase并且定義其中的類型C,一般為Spark Context或者是SQL Context。
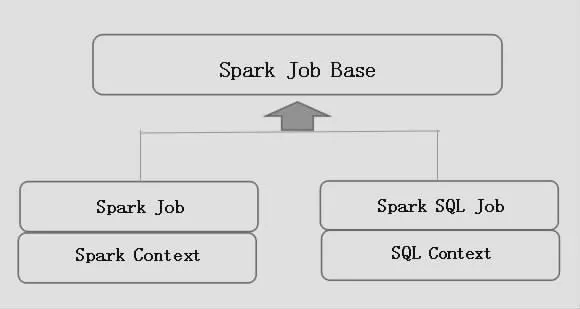
圖3 SDK接口關系圖
3.3.2 Spark-ETL Share RDD接口
RDD數據共享是指在不同的Spark Job之間可以共享RDD數據,上一個運行的Job結果可以作為下一個Job繼續使用,使得數據處理工具之間能夠協作完成任務[6]。在之前的設計當中,Spark Job繼承了Spark Job的特質,而在本文中提出了一種個更為簡單的共享RDD的設計方法-依賴Context管理的方法,整體的結構設計方式如下:

圖4 RDD數據共享設計類圖
結束語
總的來說,在信息技術快速發展的背景下,Spark的產品也會越來越高,Spark-ETL系統框架的設計通過清洗單元的組合形成大數據流水線從而完成數據的清洗,促使數據清洗工作變得更加高效,在未來的發展中將不斷完善Spark-ETL系統框架,為大數據技術的發展做出了卓越貢獻。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
藝術啟蒙(2018年7期)2018-08-23 09:14:18
家庭影院技術(2017年9期)2017-09-26 03:41:45
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
