帶語義分割的輕量化車道線檢測算法
2021-08-24 03:06:46陳正斌葉東毅
小型微型計算機系統 2021年9期
陳正斌,葉東毅
(福州大學 數學與計算機科學學院,福州 350108)
1 引 言
隨著高精度光學傳感器和電子傳感器,以及計算機視覺和深度學習算法的迅猛發展,對實時駕駛場景的設想也逐步成為現實.來自學術界和工業界的諸多研究團隊針對無人駕駛系統或高級輔助駕駛系統(ADAS)的算法研究已經投入了大量資源[1].為了擺脫復雜駕駛環境對于汽車駕駛安全的問題,智能駕駛系統基于實時交通信息協助駕駛員進行決策[2].其中,在環境感知的各種研究主題中,實時高效的車道線檢測技術對于車道線偏離預警系統(LDWS)和車道保持系統(LKS)都至關重要,能夠顯著提高汽車行駛的安全性[3,4].
傳統的車道線檢測方法[5-9]依賴于高度專業化的特征選擇和啟發式方法組合.其中,常用的特征包括:顏色[10]、結構張量[11]、邊緣檢測[12]等,這些特征可以與霍夫變換[13]、粒子或卡爾曼濾波器[14,15]結合,在確定車道線后,采用后處理的技術篩選出誤檢的部分,并將車道線特征點進行分組確定最后的車道.這類基于特征和啟發式的方法具有較快的運行速度,可以運行在計算資源有限的嵌入式設備中[16],但是由于道路場景變化,該類方法的魯棒性較差,遇到光照變化、外界遮擋或者車道線破損的情況,易出現誤識別或無法識別的問題.
近些年來,越來越多的研究者采用深度學習算法替代傳統手工制作的特征檢測器實現精度更高的車道線檢測.Kim和Lee[17]將卷積神經網絡(CNN)與RANSAC[18]算法結合起來,以檢測從圖像邊緣開始的車道線,但該方法中的CNN主要是用于復雜道路場景中的圖像增強而非直接用于車道線檢測.文獻[19]展示了在高速公路場景中如何成功將現有的CNN模型用于車道線檢測和分類任務中.Li等人[20]展示了多任務網絡如何在惡劣天氣和低照度條件下同時處理車道線和道路目標的檢測和識別.Neven等人[21]提出了一種端到端的車道線檢測算法,簡化算法的處理復雜度.
通過以上分析,盡管深度學習車道線檢測算法在魯棒性上要高于傳統圖像處理算法,但是由于算法的參數規模較大,導致檢測算法存在實時性不足的問題,尤其是在計算資源有限的車載嵌入式設備中.所以在本文的車道線檢測算法評估中將計算成本作為總體性能的關鍵指標之一[22].
基于上述分析,本文研究的車道線檢測問題是輔助駕駛系統乃至自動駕駛中環境感知的一個重要組成部分,對于自動駕駛系統的行車安全具有重要的意義.為了滿足在計算資源有限的車載嵌入式設備中對復雜駕駛場景中的車道線進行實時、精確檢測的需求,本文提出了一種帶語義分割的輕量化車道線檢測算法(簡稱SegLaneNet).該算法充分利用語義分割過程中提取的大量的中間特征信息[23],通過簡化并聯的空洞卷積支路,增加跳躍連接結構,提出新的空洞空間金字塔池化模塊(ASPP-tiny);定義模型的多尺度輸入、融合跳躍連接中的淺層特征與深層特征、融合并聯的不同采樣率的空洞卷積特征;對自編碼器中的上采樣與下采樣卷積進行剪枝操作.最后在TuSimple數據上進行實驗驗證本文提出的算法在實時性和準確性的優勢.
2 相關工作
圖像語義分割是計算機視覺任務中圖像理解的重要環節之一,再學術界的影響日益凸顯,現已成為學術界的重要研究課題之一,在自動駕駛、醫學圖像診斷等領域均有應用[24].隨著深度學習的發展,越來越多的研究者致力于在提高算法精度的同時提高算法的運行速度.首先,He等人[25]提出的殘差網絡結構(ResNet)解決了深度神經網絡難以訓練的問題,在圖像處理領域取得突破性的進展;其次,Long等人[26]提出的基于全卷積神經網絡(Fully Convolutional Networks for semantic segmentation,FCN)的圖像分割技術,在像素級的圖像語義分割領域為研究人員提供了一種全新的思路和探索的方向,使得語義分割的精度得到提高;再有,為了解決深度神經網絡在特征提取階段為增大感受野而減小特征圖尺寸時存在信息丟失的問題,Yu等人[27]提出了空洞卷積的結構能夠在保證感受野不變的前提下,同時又能夠提高對于圖像語義分割的辨識度以及運算速度.
2.1 空洞空間金字塔池化(ASPP)
池化層作為卷積神經網絡的基礎結構,主要用于減少網絡計算參數,保持特征圖的尺度不變性,并增加特征圖的感受野大小[28].通常情況在中等規模的網絡中,使用最大或者平均池化的方式,例如VGG[29]和GoogLeNet[30]等網絡.而在大規模的網絡中常使用帶步長的卷積方式增大特征圖的感受野,例如ResNet和DenseNet[31]等網絡.由于以上兩種方法都是對特征圖進行下采樣操作,會造成特征圖的上下文語義信息丟失,從而降低算法的準確率,所以He等人[32]提出將空間金字塔池化(Spatial Pyramid Pooling,SPP)應用到卷積神經網絡中,通過獲取特征圖的多層金字塔信息,再將這些信息拼接用于全連接層的計算.實驗結果證明SPP-Net 能夠提高1%-2%的準確率,且算法總開銷與未采用SPP算法相差無幾.在SPP的基礎上Chen等人[33]引入空洞卷積,提出了空洞空間金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)模塊使特征映射更精確,能捕獲長跨度的上下文語義信息,同時還能夠實現不同采樣率的空洞卷積并行處理加快運算速度.如圖1所示為并行的ASPP模塊在圖像特征提取網絡的應用.
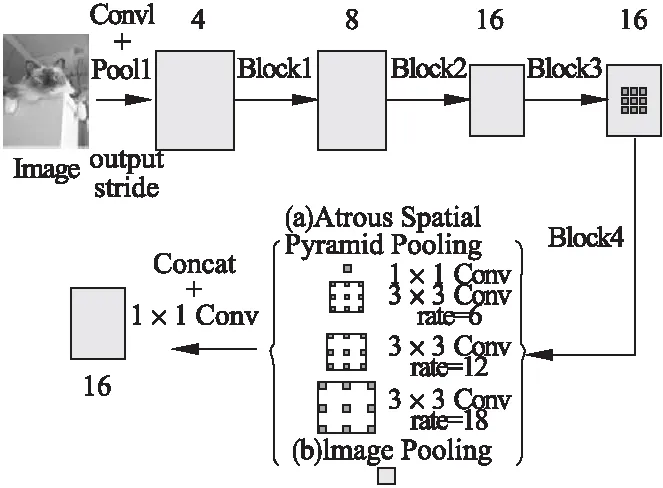
圖1 圖像特征提取網絡中的ASPP模塊示意圖
2.2 U-Net圖像語義分割網絡
U-Net是 Ronneberger 等人[34]在2015年參加ISBI(IEEE International Symposium on Biomedical Imaging)競賽時提出的一種圖像分割網絡.該網絡是基于FCN圖像分割技術,類U型的結構實現自編碼的過程,在上采樣過程中采用了融合多尺度特征的方式,能夠較好地保留圖像的細節特征,同時其網絡結構小,不但可以適應訓練集規模小的應用(例如:醫學領域),而且網絡訓練和預測的速度都比較快.
如圖2所示,U-Net語義分割網絡具有以下特點:
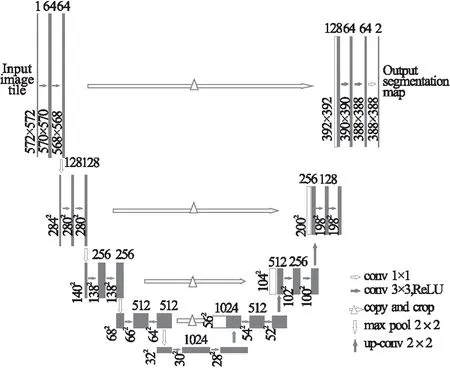
圖2 U-Net圖像語義分割網絡結構
1)基于全卷積神經網絡(FCN)的圖像分割技術,類U型的結構實現自編碼的過程,實現像素級的圖像語義分割;
2)采用跳躍連接結構將淺層的圖像特征與深層的語義特征進行拼接,獲得更加豐富的多尺度特性信息.
3 本文算法研究
針對現有的車道線檢測算法在計算資源有限的車載嵌入式設備中存在實時性差、精度不高的問題,本文在像素級語義分割網絡U-Net的基礎上,提出了一種帶語義分割的輕量化車道線檢測算法(簡稱SegLaneNet),該算法采用輕量化的全卷積語義分割網絡結構實現像素級的車道線檢測,引入改進后的空洞空間金字塔池化(簡稱ASPP-tiny)模塊減少上下文語義信息的丟失,同時采用多種多尺度特征融合的方法提高輕量化模型的算法準確率.
3.1 改進的空洞空間金字塔池化
計算資源有限的車載嵌入式設備中對算法的實時性要求極高.為了在提高算法準確性的同時加快算法的運行速度,本文在空洞空間金字塔池化(ASPP)模塊的基礎上對該結構進行輕量化處理提出了ASPP-tiny模塊.將此模塊引入到全卷積語義分割網絡中減少上下文語義信息的丟失,以提高輕量化檢測算法的性能.
如圖3所示,ASPP-tiny模塊引入殘差模塊的跳躍連接結構,移除圖像特征池化分支,簡化空洞卷積操作,選用空洞卷積采樣率分別為2、4和8的卷積層,其對應的感受野尺寸為7×7、15×15和31×31.輕量化后的ASPP-tiny模塊能夠減少網絡的計算參數從而達到算法加速的目的,同時空洞空間金字塔池化減少上下文語義信息的丟失,并且引入殘差模塊的跳層連接還能有效提高算法的收斂速度和準確率.
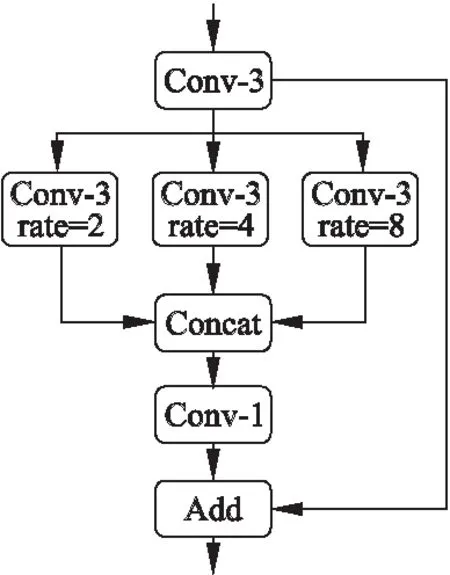
圖3 ASPP-tiny模塊網絡結構圖
3.2 融合多尺度特征的車道線檢測算法
本文在像素級語義分割網絡U-Net的基礎上,簡化特征提取的下采樣與特征解碼的上采樣卷積操作,充分利用語義分割過程中提取的大量的中間特征信息,提出了一種帶語義分割的輕量化車道線檢測算法(簡稱SegLaneNet).SegLaneNet 算法基于FCN技術實現像素級的語義分割,以ResNet Block作為特征提取的基礎模塊提高模型的收斂速度,采用多種多尺度特征融合的方法提高輕量化算法的準確率,并在跳層連接上增加ASPP-tiny模塊減少上下文語義信息的丟失、提高算法的運行速度.算法簡化了U-Net的結構,以輕量化的結構滿足在車載嵌入式平臺實時檢測的需求.具體的SegLaneNet算法結構如圖4所示.
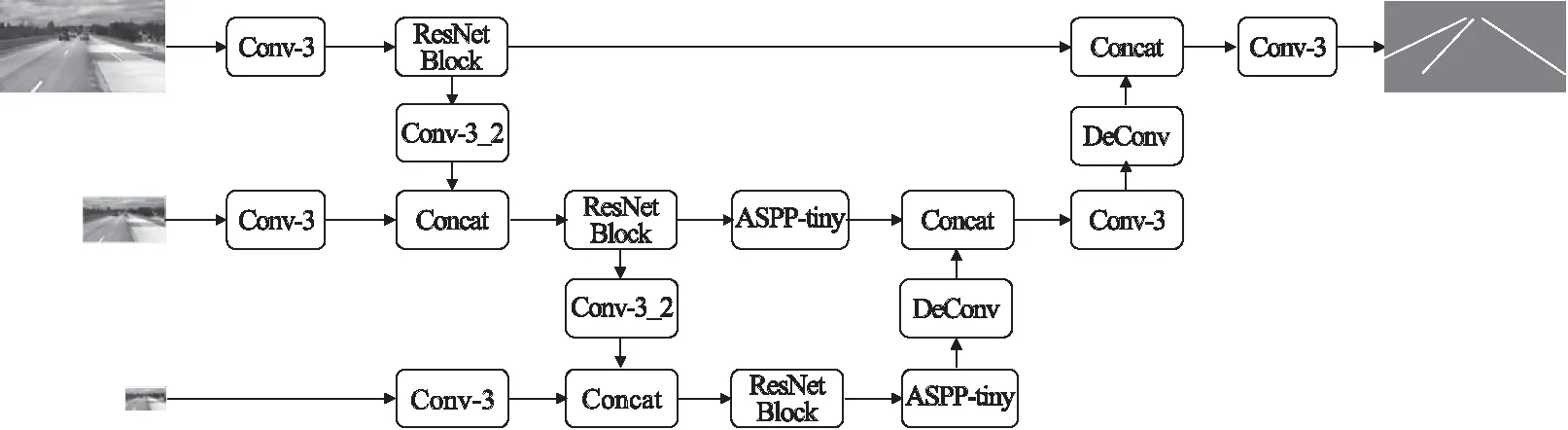
圖4 SegLaneNet網絡結構圖
作為輕量化的算法,SegLaneNet采用多尺度特征融合的方法提高算法的檢測準確率,其中的多尺度特征融合的操作包括:
1)采用多尺度的圖像輸入:采用3個分辨率的圖像作為網絡的輸入;
2)串行多尺度特征融合:采用跳躍連接結構,將淺層特性與深層特征進行融合;
3)并行多尺度特征融合:在改進后的空洞空間金字塔池化(ASPP-tiny)中,融合3個并行分支的特征信息.
其中,多尺度輸入的圖像尺寸分別為256×512像素、128×256像素和64×128像素,輸出尺寸為256×512像素.算法的操作流程為:首先在多尺度輸入上使用3×3的卷積核進行特征預提取,接著通過ResNet Block進行深度編碼,使用大小為3×3,步長為2的卷積核進行下采樣卷積操作,隨后對多尺度的特性信息進行融合,對融合后的特征圖使用ASPP-tiny模塊擴大其感受野并進行深度特征提取,最后使用反卷積操作進行特征解碼,恢復特征圖并輸出像素級語義分割后的結果.
4 實驗分析
本文采用圖森(TuSimple)(1)https://github.com/TuSimple/tusimple-benchmark/tree/master/doc/lane_detection#tusimple-lane-detection-challenge/車道線檢測挑戰數據集訓練SegLaneNet算法并測試算法的實時性和準確率,其中TuSimple數據集由自動駕駛公司圖森發布,是第一個提供針對車道線檢測基準的數據集,其主要包括:直線道路、曲線道路、光線良好道路、破損道路、外部設施干擾道路以及陰影遮擋道路等情況的3626張訓練圖像和2782張測試圖像,包括在白天不同時間采集的公路圖像數據.
為了進一步驗證算法在復雜的城市街景道路中的檢測性能,通過增加實驗室采集數據并采用數據擴增技術進行擴大數據規模,包括:水平鏡像、對比度增強方法,最后生成一個擁有10904張訓練圖像,4737張測試圖像的車道線檢測數據集用于算法實驗評估.
4.1 評價指標
實驗采用的準確率指標為計算預測圖像中正確車道線像素點數在標簽圖像中的占比,具體公式如下:
(1)
其中,Cim是預測圖像中正確車道線的像素點數,Sim是標簽圖像中真正車道線的像素點數.需要通過以下步驟獲得:首先計算預測圖像中車道線像素點與標簽圖像中在同Y軸高度的所有車道線像素點在X軸方向上的差值;然后若預測圖像上某像素點存在差值小于閾值的情況則認為該點預測正確的,否則預測錯誤;最后遍歷所有預測像素點即可確定預測正確的像素點數.本文還進行假陽性(FP)、假陰性(FN)分析,FP表示預測圖像中預測錯誤的車道線像素點占所有預測像素點的比例;FN為標簽圖像中未被預測的像素點占標簽圖像中所有像素點的比例.公式如下:
(2)
(3)
其中,Fpred是預測圖像中預測錯誤的車道線像素點數,Npred為預測圖像中所有預測的車道線像素點數,Mpred為標簽圖像中未被預測的車道線像素點數,Ngt為標簽圖像中所有的車道線像素點數.
4.2 實驗參數設置
本文的SegLaneNet算法使用Tensorflow[35]架構實現,實驗采用交叉熵損失函數,訓練選用動量為0.9的動量優化器,設置初始學習率為0.005,每100個epochs后衰減2次,并且權重衰減為0.0005.設置實驗輸入圖像大小為512×256像素,并采用雙線性插值進行下采樣獲得其余兩個尺度的圖像數據.實驗服務器的配置參數如下:Intel(R)Xeon(R)Gold 6132 CPU @ 2.60GHz處理器、128 GB內存、16 GB NVIDIA RTS-2080 GPU、Ubuntu 16.04.3操作系統,測試嵌入式設備為帶有NVIDIA Pascal架構GPU的NVIDIA Jetson TX2(2)https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-tx2/.
4.3 網絡訓練
網絡訓練Sim設置迭代次數為80000次,每一個批次輸入8張圖像進行訓練.按照設置好的實驗參數,將預處理好的訓練集輸入網絡中進行模型的訓練,通過對模型參數的80000次迭代更新,最后保存訓練好的網絡模型用于測試.如圖5所示,網絡訓練過程中記錄模型的準確率與損失值的變化趨勢圖,分別見圖5(a)、圖5(b).由圖5所示,模型訓練在迭代10000次左右開始收斂,用時約30分鐘.此后準確率在0.96左右變動,損失值在0.1左右變動.最終完成80000次訓練,總時間約為4個小時.

圖5 網絡訓練準確率與損失值變化趨勢圖
4.4 實驗結果分析
首先,對本文提出的ASPP-tiny模塊進行實驗評估,本文設置帶有ASPP-tiny模塊和無ASPP-tiny模塊的對比實驗,實驗結果如表1所示.通過表1的實驗結果表明,本文提出的ASPP-tiny模塊能夠很好的保留特征圖的上下文信息,在輕量型網絡結構中有利于提高算法的準確率.

表1 ASPP-tiny模塊測試結果
更進一步,如圖6所示ASPP-tiny模塊對算法的性能有所提高.圖6(a)為輸入圖像;圖6(b)為無ASPP-tiny模塊的車道線輸出圖像,盡管輸出結果能夠區分車道線輪廓,但存在分割不連續以及存在誤識別的問題;圖6(c)為帶有ASPP-tiny模塊的車道線輸出圖像,輸出的車道線連續且存在的干擾較少,檢測準確率較高.特別在輸入圖像中車道線位置存在嚴重干擾時也能夠精準的分割;圖6(d)為帶有ASPP-tiny模塊的SegLaneNet算法在輸入圖像上擬合的車道線示意圖;圖6(e)為輸入圖像對應的標簽圖,由圖6對比可知SegLaneNet檢測的車道線與原圖車道線基本重合.

圖6 ASPP-tiny實驗對比圖
接著,在TuSimple 測試數據集上將本文提出的SegLaneNet算法與現有車道線檢測算法及Baseline算法進行對比,實驗結果如表2所示,其中文獻[37]與Baseline未提供算法運行幀率.與Baseline相比,本文算法在測試集上的準確率提高了約2%,FP減少了3%以上,FN減少了約2%.與現有的算法對比,SegLaneNet在檢測準確率、FP和FN指標上較為接近,但是算法運行幀率上要遠高于其他算法,達到165FPS.

表2 TuSimple測試數據集對比實驗結果
如圖7為SegLaneNet與文獻[21]在TuSimple數據集上的實驗對比,其中圖7(a)為輸入圖像,圖7(b)為文獻[21]的輸出結果,圖7(c)為SegLaneNet的輸出結果,圖7(d)為SegLaneNet在輸入圖像上擬合的車道線示意圖,圖7(e)為輸入圖像對應的標簽圖.對比圖7(b)與圖7(c)可知,在車道線存在明顯干擾時,圖7(b)中存在誤識別的情況,而本文算法可以準確識別出正確的車道線,如圖7(c)所示.因此,本文的SegLaneNet檢測準確率要高于文獻[21]而誤檢率(FP)指標低于文獻[21].

圖7 SegLaneNet實驗對比圖
然后,將本文提出的SegLaneNet在實驗室采集的道路圖像上進行效果測試.通過安裝在車輛上的行車記錄儀采集的圖像數據,該數據為國內城市街景道路,具有場景復雜、非車道線干擾多(車輛、陰影、護欄、積水等)、車道線不明顯等特點.如圖8所示為實驗結果展示圖,圖8(a)為原始輸入圖像,圖8(b)為SegLaneNet分割輸出圖像,圖8(c)為分割輸出擬合車道線輸出圖像.由圖8可知,SegLaneNet算法在復雜的城市街景道路也具有較好的效果,達到車道線檢測的目的.

圖8 國內城市街景道路測試效果圖
更進一步,如表3所示為算法權重文件大小的數據對比,本文的SegLaneNet相較于其他算法擁有更加輕量化的模型,其權重大小約為文獻[21]的1/4,而各項性能指標都要優于文獻[21].

表3 不同算法的權重文件大小
最后,將本文提出的SegLaneNet算法分別在不同設備上進行運算速度測試,測試設備包括:NVIDIA RTX 2080 GPU服務器、Intel(R)Core(TM)i5-8400 CPU臺式機、NVIDIA Jetson TX2嵌入式設備,實驗結果如表4所示.由實驗結果可知,本文的算法在GPU服務器上運行幀率達到165FPS,在嵌入式設備中運行幀率達到16FPS,能夠滿足嵌入式設備實時檢測的要求.

表4 不同設備實驗對比圖
5 結 論
本文研究的車道線檢測問題是輔助駕駛系統乃至自動駕駛中環境感知的一個重要組成部分,對于自動駕駛系統的行車安全具有重要的意義.提出的一種帶語義分割的輕量化車道線檢測算法SegLaneNet,首先通過簡化并聯的空洞卷積支路,增加跳躍連接結構,提出新的空洞空間金字塔池化模塊(ASPP-tiny),該模塊采用并行的不同采樣率的空洞卷積進行特征提取與融合以減少上下文語義信息的丟失;接著定義模型的多尺度輸入、融合跳躍連接中的淺層特征與深層特征、融合并聯的不同采樣率的空洞卷積特征;再有對自編碼器中的上采樣與下采樣卷積進行剪枝操作;最后由圖森(TuSimple)數據集上的對比實驗可知,與Baseline相比本文的SegLaneNet算法在測試集上的準確率提高了約2%,假正例(FP)減少了3%以上,假負例(FN)減少了約2%,在GPU服務器上運行速度達165幀/秒(FPS),同時在嵌入式設備中運算速度達到16幀/秒(FPS).測試結果表明帶語義分割的輕量化車道線檢測算法能夠滿足車載嵌入式設備實時、準確的車道線檢測工作.同時,本文提出的基于嵌入式平臺的輕量化深度學習算法模型對于深度學習算法在車道線檢測的應用落地提供一種新的可行的技術解決方案.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
海峽科技與產業(2016年3期)2016-05-17 04:32:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
