活動社交網絡中活動推薦方法總結與展望
2021-08-24 06:53:14趙海燕孫俊松陳慶奎
小型微型計算機系統 2021年8期
趙海燕,孫俊松,陳慶奎,曹 健
1(上海市現代光學系統重點實驗室,光學儀器與系統教育部工程研究中心,上海理工大學光電信息與計算機工程學院,上海 200093)
2(上海交通大學 計算機科學與技術系,上海 200030)
1 引 言
近年來,隨著移動互聯網技術的普及,一種新型的活動社交網絡(Event-based Social Networks,簡稱EBSNs)紛紛出現,在近幾年獲得大量用戶的追捧.以Meetup(活動推薦平臺)為例,據官方數據統計,至2019年已經有超過44000000的會員,超過33萬的群組以及每周超過84000的活動數.用戶通過Meetup平臺尋找和建立社區團體,在真實世界中進行面對面的互動.任何人都可以組織小組或參加任何主題的活動,將興趣相似的人在現實中聯系起來.
由于活動社交網絡中有著大量的活動,用戶搜索感興趣的活動并不容易,因此,有必要主動為用戶進行活動推薦.活動推薦可以簡單的理解成向用戶個性化地推薦用戶可能喜歡的活動.作為推薦系統的一個分支,活動推薦已經成為新興的研究方向.
在EBSNs環境下,向用戶個性化推薦活動面臨一系列挑戰.冷啟動問題是推薦系統常見的問題,在缺乏用戶數據和評價的活動推薦中這一問題更為明顯.EBSNs上的許多活動生命周期短并且前期參與反饋較少,致使活動推薦必須要求系統能在有效時間內快速推薦,不然推薦會失去意義,因此,在推薦活動的過程中遇到了比物品推薦中更嚴重的冷啟動問題;其次,由于EBSNs中存在線上線下異構社交網絡[1],需要考慮兩者相互作用.相比于活動本身的屬性,社會因素對推薦的影響十分顯著,這也與物品推薦存在差異.
近年來,許多學者圍繞活動推薦進行了研究.現有的研究主要是利用EBSNs特性以及活動的特殊屬性等來緩解冷啟動問題.使用的算法主要有基于協同過濾的方法、基于圖的方法以及基于上下文感知的方法.深度學習在活動推薦中的文獻相比于傳統的方法較少.深度學習的使用在推薦中起到良好的作用,改善了特征提取并提升最終的推薦效果.同時,也有學者對于EBSNs下的活動參與率和活動組織問題進行多方位的研究.本文對EBSNs中的活動推薦的研究現狀進行了總結,并對未來的研究方向進行了展望.
2 EBSNs上活動的特性及其推薦問題
2.1 活動的定義及其特點
根據百度百科的定義,活動是由共同目的聯合起來并完成一定社會職能的動作的總和.活動由目的、動機、動作和共同性構成,具有完整的結構.活動的定義是寬泛的,對活動分類的方式也有很多種.研究者們探討了不同類型活動的推薦:在文獻[2]中,作者研究如何對于文娛活動進行推薦,同時也有學者對學術活動進行推薦[3]等.EBSNs下的活動推薦與一般的活動推薦有較大的差別.本文討論的是EBSNs上的活動推薦.
根據文獻[4]等的總結,EBSNs上的活動具有4個方面的主要特性:
1.生命周期:活動具有生命周期,具體是從活動的發起到活動結束的這段時間.
2.時效性:對于活動推薦來說,系統必須要在活動的生命周期內向用戶推薦,一旦活動的生命周期結束,再向用戶推薦該活動,是沒有任何意義的.
3.短暫性:EBSNs上的活動數量非常多,同時每天也有大量的活動完成和消失.這也意味推薦系統必須能應對大量活動的出現和消失,并在活動生命周期內向用戶準確推送.
4.反饋較少:一個活動在其剛發布時,用戶的參與意圖反饋較少,而大量的參與意圖發生在活動即將發生的時候.一個活動只有在即將發生的時候才能有更多參與者,考慮到活動時效性,向用戶推薦活動會變得很困難.
根據活動舉辦形式的不同,活動可以分為線上活動與線下活動.線上活動[5]主要是指通過互聯網舉辦的社交活動,這些活動對于時間地點的要求較低,用戶容易參與,而線下活動則恰好相反.文獻[1]中的研究表明在線社交網絡的活動頻率要高于線下活動.在EBSNs同時包含了線上活動和線下活動的信息.
按照活動的周期性,活動又可以被分為周期性活動與非周期性活動.這種分類在推薦的過程中,可以作為依據緩解推薦中碰到的問題.文獻[6]的研究表明EBSNs中存在大量的周期活動,這類活動是由某個小組長期組織的活動,對于一部分用戶來說參與這些活動已經成為慣例,不會受到其他因素的影響,同時,由于他們長期參與這類活動,所以在相同時間段內推薦同類型活動常常是無用的.因此,將周期性因素考慮進推薦過程,可以提升推薦效果.
同時在EBSNs上存在線上群組,這種群組類似于同好群,用戶可以通過自己興趣加入群組,并參與這些群組織的活動.群組的存在影響了用戶對活動的選擇[7].圖1為對上述活動分類的匯總.
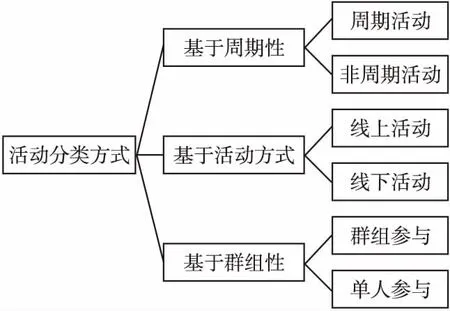
圖1 活動分類結構圖
2.2 EBSNs上的活動推薦
2.2.1 EBSNs 特性
EBSNs同時擁有在線社交和線下社交,它以活動為驅動,使人們通過線上組織,在線下進行社交活動.根據文獻[1,6]的研究,線上社交要比線下社交密集得多,兩者之間具有互相促進作用.EBSNs除網絡特性以外,還具有社會特性和時空特性.
EBSNs是一個特殊的社交網絡,其本身也是一個值得研究的課題.文獻[8]中對離線社交與在線社交的相互影響進行了研究,發現參與線下社交的人在線上社交更加地活躍,但同時對于那些未參與活動的用戶,他們的聯系會因此變弱.在文獻[9]中,作者研究了EBSNs中人員的關系,發現EBSNs成員的參與方式并不完全相同,并且他們在不同的情況下可能在不同的角色之間轉換.在文獻[10]中,作者對活動流行度進行了預測,并研究了如何提高EBSNs活動流行度問題.在文獻[11]中作者提出了活動之間的時間沖突問題.
文獻[1]的研究表明,EBSNs存在周期性特點,線下活動需要充足的時間,因此大部分活動的舉行都會選擇在休息日和節假日.在參與活動的位置選擇上,81.93%的用戶都選擇離家10英里以內的活動,活動的參與人數以及群組的人數都服從于長尾分布,參與的人數越多的活動其數量越少.由此可知,EBSNs上的活動推薦需要考慮時間、位置、在線離線社交網絡信息,在現有的研究中,這些因素也經常被用與緩解冷啟動問題.線上社交網絡中,基于位置的社交網絡中在線服務也會通過地理位置向用戶推薦活動.但不同的是,基于EBSNs的活動推薦更加復雜,它需要考慮到線上群組對于活動組織的影響.活動存在目的,動機,動作等構成部分,這與物品的定義不同,因此,活動相比于物品更為復雜,不能把傳統的對于物品的推薦方法簡單應用于活動推薦上.
用戶在EBSNs上通過RSVP(Reply,if you please,收到請回復,以下簡稱RSVP)對活動進行意圖反饋,RSVP信息一般只有參與和不參與兩個選項.通常用戶的反饋并不積極,且反饋大多數發生在活動即將舉行的時間段,導致了用戶的反饋稀疏問題.許多用戶在活動參加后對活動進行評分,此時,由于活動已經結束,評分只能影響推薦系統日后對于向用戶進行其他活動的推薦,顯然,缺乏顯式反饋也將影響活動推薦的效果.
2.2.2 數據集
在活動推薦研究中,多數學者基于Meetup的數據進行實驗,主要原因是Meetup提供的服務較為完善,用戶基數大,且每周都有大量活動更新.同時,也有一部分學者以豆瓣同城平臺作為研究對象.豆瓣有許多活動涉及到劇團或公司發布的活動與展覽等,其與一般的活動性質有所不同.研究人員可以從Meetup接口(1)www.meetup.com/meetup_api/以及豆瓣同城(2)www.douban.com/location/world/上直接爬取,兩個網站都有提供接口供用戶獲取數據,主要爬取用戶關系、活動文本以及地理信息.相比較而言,Meetup的接口提供較為完整,其中包含了群組及群組活動的各類詳細信息,也包括了組員的公開信息.
不同的EBSNs的數據集有不同的特點,例如Meetup的數據集中沒有活動的時間窗和活動時間長短這些信息,因此在活動行程的推薦中,系統無法判斷一個活動的持續時間,導致無法給用戶準確推薦下一個活動行程,而在文獻[12]中,作者利用了數據集DEvIR(3)www.github.com/ecafidid/DEvIR,該數據源自一個著名的大型分布式事件—圣地亞哥國際漫展,它包含了活動的時間信息,因此,漫展官方自2013年起提供了一種行程軟件用于規劃和記錄與會者行程.
2.2.3 評價指標
目前文獻中評價主要以離線測試為主,將數據集分為測試集與訓練集并通過測試集預測評分.相比于在線測試和問卷調查,離線實驗預測速度較快,花費較低.在離線實驗中使用較多的評測指標如下:
1.推薦準確度:準確度是指推薦系統預測用戶可能行為的能力,又可以具體分為評分預測和前n項預測(TopN).評分測定常常使用均方根誤差(RMSE).
(1)
TopN是活動推薦常用的方式中,經常以準確率(precision)、召回率(recall)、歸一化折損累計增益(NDCG,Normalized Discounted cumulative gain)以及AUC(ROC曲線下的面積)等.
在活動推薦中常用的準確率指標為P@n(Precision at Position n,位置n處的準確率)和mAP(Mean Average Precision,平均準確率均值),是將所有用戶的平均準確率取均值.
(2)

(3)
(4)
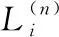
召回率(Recall)能衡量一個推薦系統是否只有頂部的部分物品被推薦.
(5)
di(L)表示推薦列表Li在top-n位置時用戶i參與的活動數量,|Hi|表示用戶i參與活動數量.
接受者操作特性曲線(ROC,receiver operating characteristic curve)橫坐標為假陽性率,縱軸為真陽性率.公式中AUC(Area Under Curve,曲線下面積)代表ROC曲線下面積,表示分類器給正樣本打分高于負樣本的可能性.
(6)

折損累計增益(DCG)能將推薦結果相關性分值累加后作為整個推薦列表的得分,而nDCG則是對DCG做歸一化處理,方法是將DCG除以理想最大折損累計增益(IDCG).
(7)
其中,DCGP是位置p折損累計增益,IDCGp是位置p的理想最大折損累計增益.
2.覆蓋率:指推薦對象占整個推薦池的比例,它描述了一個推薦系統對長尾對象的挖掘能力.
3.多樣性:推薦系統的多樣性衡量推薦結果是否能夠覆蓋用戶的不同的興趣愛好,在推薦系統中直接體現是被推薦物品的不相似性,因此通常使用漢明距離作為評測指標測量這種差異性.
4.新穎性:通過新穎性,系統可以向用戶推薦一些非熱門活動.
推薦系統除了以上4種推薦指標,還有公平性,健壯性等指標.但是在活動推薦的文獻中較為常見的為第一種推薦指標.
活動推薦屬于單類推薦,同時在實際推薦過程中往往會生成一個以時間為順序的列表向用戶進行推薦或是在活動下方推薦相似活動.在文獻中一般都是采取TopN預測,并計算相應的準確率和召回率.P@n、mAP、NDCG與AUC都是文獻較中為常見的評價指標.
3 面向EBSNs的活動推薦模型
3.1 活動推薦模型中考慮的因素
EBSNs上的活動推薦有很多模型,其中有基于協同過濾,基于圖,基于上下文感知等.在大部分模型中,考慮到的因素可以分成兩部分,一是考慮EBSNs本身的特性,二是考慮活動相關的因素,如圖2所示.
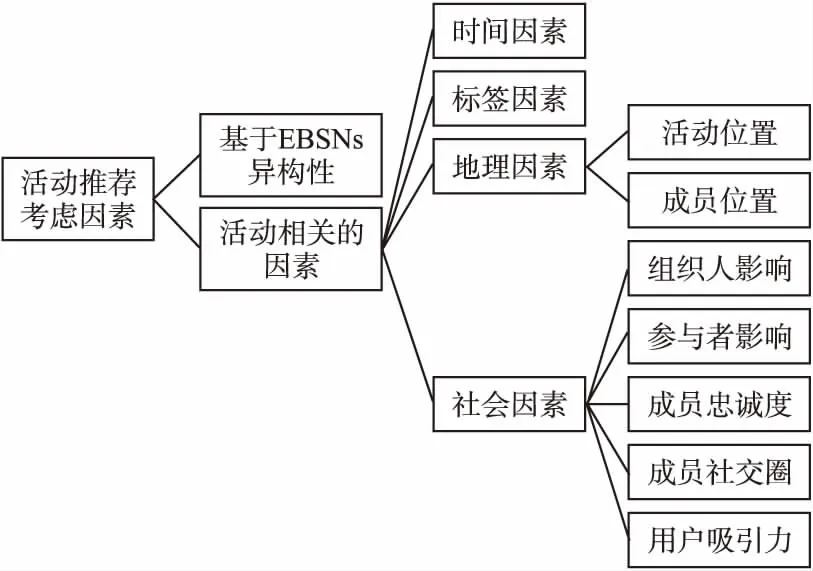
圖2 活動推薦模型考慮的因素
大部分推薦模型中都考慮了活動的屬性,其中較為常見的有時間、標簽、地理和社會因素.時間與地理因素主要是指活動具體時間,活動的舉辦位置和成員所在位置,它們的影響是顯性的,例如,活動位置與參與者距離過遠或者時間安排在工作日,勢必會影響其參與積極性.社會因素又涉及到了多個方面.EBSNs上的活動大多數屬于社交類活動,社會與人的影響對于活動相當重要.文獻[13]中作者通過分析線上網絡的用戶行為來識別用戶的社交圈與用戶之間的友誼,從而推薦熟人相關的活動.現有的參與者對于尚未參與者的決定會產生影響,文獻[14]將參與者影響分為3個部分,包括施加影響的用戶、受到影響的用戶和目標事件.作者通過泊松分布對含有參與者影響的數據建模,獲得了一個概率泊松分解模型(probabilistic Poisson factorization model).
文獻[15]中,作者將活動組織者作為因素加入討論.在文獻[16,17]中討論的是用戶的吸引力,當用戶發布或組織活動后,用戶將會提升自身的影響力,并會提升吸引其他用戶參與相同活動的能力.通過對吸引力的計算能更好地表示活動之中人與人間的聯系.文獻[18]中,作者探討了忠誠度對于推薦的影響,并表明穩定且繁榮的群體擁有更多的忠實用戶.與推薦用戶喜歡的活動不同,文獻[19]中作者考慮的是哪些活動與用戶是存在沖突因而不能參與的,以此分配最適合的活動給用戶.
此外,有一些推薦模型對EBSNs的本身特性進行建模.文獻[16]中考慮了EBSNs的異構性,所提出的模型針對EBSNs擁有線上線下兩種社交網絡的特性進行推薦.文獻[20]中提出了一種名為HeSi的模型,在模型中綜合考慮了異構性和區域傾向性,在5個地區的測試數據集上,該模型的AUC要高于傳統矩陣分解方法.在文獻[21]中,作者利用了EBSNs的信息,并結合地理位置以及用戶評分,構造了一個貝葉斯潛在因子模型.文獻[22,23]使用核密度估計(KDE)為每個用戶的個性化二維位置分布建模(經緯度坐標),來學習活動的地理影響.
3.2 傳統推薦模型的應用
傳統推薦模型有3種,主要是基于內容的推薦算法,基于協同過濾的推薦算法以及兩者結合的混合推薦算法.這些方法在活動推薦中都有應用.
3.2.1 基于內容的活動推薦
基于內容的方法是指對于用戶喜歡的物品的描述和屬性進行分析,為其推薦與這些物品的描述和屬性相似的物品.該方法通常包括物品特征挖掘,用戶偏好計算,物品相似度計算,排序等步驟.其中,物品的相似度根據物品的特征進行計算.為了做到這一點,需要有一個內容分析器,它通過關鍵字匹配或通過TF-IDF(term frequency-inverse document frequency,詞頻-逆文本頻率指數)來提取物品的相關特征.
文獻[24]中,作者使用LDA(Latent Dirichlet Allocation,文檔主題生成模型)在每個活動和用戶上生成主題分布,基于活動內容相似性和用戶興趣主題進行推薦,在該模型中同時也將社交好友以及出勤歷史信息放入算法中,結果發現這兩種屬性可以提高推薦系統的準確率.在文獻[25]中,作者對于用戶近期歷史記錄,通過LDA主題模型獲取其特征向量,并結合行為權重和時間衰減生成用戶長短興趣模型,使用戶偏好預測更準確,也能更好的結合基于內容的方法進行推薦.文獻[15]中,通過分析用戶參與的活動的內容來獲取用戶偏好,同時結合組織者影響,地理特征影響,提出了一個整合用戶興趣、組織者影響和地理偏好的活動推薦模型,針對數據稀疏問題,作者提出了一個綜合考慮用戶偏好和組織者偏好流行感知的概率矩陣分解方法(Popularity-aware Probabilistic Matrix Factorization,PPMF)來推斷缺失值.
基于內容的推薦方法可以避免活動的冷啟動問題,但是它對內容表示的要求較高,而且單純的基于內容的推薦方法忽略了社會關系的影響,而這一點恰恰是EBSNs的一個特點.
3.2.2 基于協同過濾的活動推薦
基于協同過濾的方法可分為基于用戶的協同過濾算法和基于項目的協同過濾算法,其主要思想是“物以類聚、人以群分”.
文獻[26]中采取了基于項目的協同過濾方法,通過項目之間的相似性預測結果,這種方法在用戶個性化需求強烈的領域能應對用戶不同的需求,但缺點是基于項目的協同過濾中相似矩陣計算代價過大.
矩陣分解在基于模型的協同過濾推薦算法中普遍使用.文獻[27]中,作者提出了一種基于事件用戶鄰域的集合矩陣分解(Collective Matrix Factorization with Event-User Neighborhood,CMF-EUN)模型將基于活動和用戶的鄰域方法結合到矩陣分解模型中,在該模型中綜合了用戶在活動內容,活動地點,活動時間上的相似度來計算用戶之間的相似度,實驗結果表明,該方法要遠好于傳統的奇異值分解.文獻[28]中提出了通過活動參與歷史信息來表達用戶偏好,通過協同過濾來推薦個性化活動的方法.在推薦過程中,利用用戶評價信息可以提高推薦系統的準確性,而沒有評價信息則對推薦系統性能造成影響.該方法通過矩陣分解預測特征值.為了考慮用戶的潛在偏好,作者通過在有參與類似活動的用戶之間進行協同過濾來選擇候選用戶.實驗結果表明,這種方法要好于現有的基于地理特性的方法.文獻[29]中,作者則使用貝葉斯概率模型對EBSNs的社會異構性進行建模.文獻[21]中,作者把用戶的RSVP(收到請回復)數據作為用戶評分,將它與EBSNs異構性和活動的地理特征綜合考慮,結合貝葉斯因子模型提出HESIG模型(Heterogenous Social Information and Geographical information,異構社會信息與地理信息模型),其AUC在Meetup休斯頓數據集上達到0.729,但是這種方法沒有充分考慮推薦的冷啟動問題,同時也忽略了活動的內容和組織者信息.在文獻[30]中,作者進一步考慮活動的內容信息,通過LDA進行主題建模.在文獻[4]中,作者提出了集合成對矩陣分解模型(Collective Pairwise Matrix Factorization Model)對EBSNs中用戶的成對偏好和多重交互進行建模,并為模型學習設計了一種有效的隨機梯度下降算法.在活動推薦中用戶、活動和用戶群組/位置之間存在三角交互.以用戶、群組和活動為例,用戶可以加入組,組可以組織活動,用戶可以參與任意活動.而作者將上述信息的三角交互建模,同時把交互矩陣推廣為整數矩陣,使用正、負、零值表示用戶的偏好,使這種偏好更具層次.其在與HESIG[21]和基于上下文感知的MCLRE[31](Multi-Contextual Learning to Rank method,多語境學習排序法算法)比較中,取得更好的推薦效果.
由于EBSNs上數據的稀疏性,往往難以找到相似用戶或者相似活動,導致單純的協同過濾推薦算法往往效果不佳.事實上,上述介紹的方法中,在計算用戶的相似性或者活動的相似性時也利用了活動的相關特征,因此已經不是純粹的協同過濾方法.
3.2.3 混合推薦
文獻[32]中的實驗表明,單純的矩陣分解方法在該問題上效果欠佳.由于單一的推薦系統有各自的弊端,因此結合各種模型的優勢的混合模型得到了應用.
混合推薦方法如文獻[33,34],將基于內容的方法和基于協同過濾的方法相結合:傳統的協同過濾方法在數據缺失時有嚴重用戶冷啟動問題,而基于內容的方法則有利于克服這個問題.例如文獻[35]一文中,將基于活動和基于用戶的鄰域方法結合到矩陣分解中,提出了一種混合的協同過濾模型,即活動用戶鄰域的矩陣分解(Matrix Factorization with Event-User Neighborhood,MF-EUN)模型.該模型首先考慮了用戶特征信息和活動特征信息,以此發現它們的鄰域.再將其與矩陣分解的方法相結合來提高準確率.鄰域發現的推薦中,更重視與其相近的鄰居,而忽略全局.基于矩陣分解的方法則恰好相反,兩者結合可以互相補足.
文獻[36]中Simon Dooms等人基于用戶的實際評測從準確性、新穎性、多樣性、滿意度和信任度這5點進行了推薦模型效果的研究,發現混合算法要比單純的協同過濾或者基于內容的方法要優秀,這說明混合推薦在該問題上的優越性.
3.3 基于圖的活動推薦模型
在活動推薦的研究中,近年來出現了許多基于圖的推薦模型.基于圖的推薦方法中將數據用圖模型表示,其中的節點代表了EBSNs中的實體,連接代表了實體的各種關系.
文獻[37]較早將基于圖的方法引入活動推薦,作者構建了一個異構圖來刻畫EBSNs,將推薦看作一個鄰近節點的查詢問題,文中提出了一個通用的基于圖的推薦模型HeteRS(Heterogeneous graph-based Recommendation System model),并通過數據自動學習多元馬爾可夫鏈(multivariate Markov chain,MMC)的參數.該模型能夠完成活動推薦中的3種推薦任務:向用戶推薦線上活動,向用戶推薦線上群組以及向群組推薦活動標簽.然而文獻[37]中的方法只考慮到EBSNs中顯性關聯.在文獻[38]中發現,只考慮顯性關聯會產生許多懸掛節點,這些節點影響了圖的連通性以及隨機游走的展開,因此作者提出了不同于異構圖的混合圖模型,將原先異構圖中活動與屬性的顯性關聯轉化為活動與活動間的隱式關聯,以減少圖中節點.作者發現這樣的做法不能區分不同類型的關系的優先級,于是進一步提出使用基于內容的重排序算法,從圖隨機游動所選擇的候選活動中獲得最終的活動推薦列表.
EBSNs中有大量實體和具有唯一性的活動,如果使用所有的信息會增加計算負擔,十分耗時.文獻[39]中提出了一種改進的基于演化圖的連續推薦(evolving graph-based successive recommendation,EGSR)算法解決這種問題.在EGSR中利用一個長度可調的滑動窗口機制構造演化圖.它將時間線劃分為長度相等的連續槽,然后通過一個滑動窗口的最新的信息構造圖.同時,作者提出了一個基于圖熵的方法用以調整窗口長度,并對每個歷史時間塊進行加權.文獻[40]中,作者提出一種反向的帶重啟的隨機游動(Reverse Random walk with Restart,RRWR)方法,也使用滑動窗口機制來構造演化圖,以連續地為每個用戶推薦新活動.一些不組織活動的群組被稱為懸掛組節點,在隨機游走遇到這些節點會對結果產生偏差.RRWR中的懸掛節點比帶重啟的隨機游動中的懸掛節點接收到的傳輸概率更小,導致更可靠的穩態概率,從而解決了懸掛節點的問題.
文獻[41]一文中考慮了活動的社會屬性,將活動推薦的重點放在向用戶推薦活動伙伴上,為此,提出了一個通用圖的嵌入模型(generic graph-based embedding model,GEM)將用戶、活動、位置、時間和文本內容間的關系嵌入到一個共享的低維空間中,以解決冷啟動的問題.在文獻[42]中提出了基于圖熵的連續活動推薦(successive event recommendationbased on graph entropy,SERGE)構建了一個主圖來尋找不同實體間的關系,此外還構建了一張用戶反饋圖,通過在兩張圖上應用帶重啟的隨機游走算法獲得兩組用戶活動相似度得分,生成最終的推薦列表,其基本思想是在利用帶重啟的隨機游動(RWR,Random walk with Restart)來對即將發生的活動進行排序,然后應用主題分析技術來分析活動文本建立每個用戶的興趣模型,并計算活動內容和用戶興趣之間的相似度作為每個圖的邊緣權重.
在算法的精度上,從早期文獻中實驗的準確率在0.2以下,到文獻[42]一文中SERGE模型準確率接近0.3,表明基于圖的方法有助于提高推薦性能.但在文獻[38]一文中,作者同時對上海北京兩地的數據建模,最后的準確率差距十分巨大,這也體現模型仍有不足的地方需要去改進.
基于圖的方法能很好地表示關系,同時也存在很多局限性.基于圖的方法聚合過去的交互歷史,但會隨著數據量的增加性能急劇下降.
3.4 上下文感知的活動推薦模型
上下文是用于描述實體狀態的任何信息.在推薦系統中上下文定義十分寬泛.上下文可以是文本主題,時間,位置等.通過上下文感知能夠獲得大量有用的信息有助于緩解冷啟動現象,因此,在活動推薦中,也有大量關于上下文感知活動推薦的研究.
文獻[43]中,作者深度剖析了活動主持人和群體成員的社會影響,利用活動主持人和群組成員的社會影響力以及上下文(如時間、內容和位置)的影響進行推薦,提出了一種基于活動主持人的活動推薦模型,在實驗中發現活動主持人和群體成員的社會影響力比活動的時間信息更為重要.在文獻[31]中提出了一個混合推薦方法,利用多個上下文感知的推薦模型學習活動排序,除了基于活動描述的信息和來自用戶的RSVP(收到請回復)的信號外,還利用了基于組成員身份的社會信息、基于用戶地理偏好的位置信息和用戶時間偏好.文獻[44]中,作者將隱式反饋和各種上下文信息結合進行建模,在實驗中發現,活動、用戶、時間等語境特征的信息量最大,其次是社會、空間語境特征,而將它們結合在一起的方法有更高的準確率.
文獻[45]關注本地冷啟動活動推薦任務.作者提出集體貝葉斯泊松因式分解(collective Bayesian Poisson factorization,CBPF)模型結合貝葉斯泊松分解和集合矩陣分解的優點,首先通過貝葉斯泊松分解(Bayesian Poisson factorization,BPF)分別對社會關系、用戶對活動的響應和活動內容文本進行建模.泊松分解是一種概率矩陣分解的變體,其中每個用戶和物品的權重都為正,并且用泊松分布代替高斯分布.在基礎的數據分布外,作者還將Gamma先驗放在潛在屬性和潛在偏好上,從而使得模型趨向于用戶和項目的稀疏表示.此外,作者對用戶和項目特定的速率參數設置了額外的優先級,以控制表示的平均大小.這種層次結構能更好地捕捉用戶多樣性.作者稱此為層次泊松分解(hierarchical Poisson factorization,HPF),而BPF是將HPF中所有用戶和項的速率參數固定為同一對超參數,屬于HPF的一種子類.貝葉斯泊松分解方法結合了貝葉斯學習與泊松分解,能夠很好地處理稀疏數據,并且對過擬合問題具有更強的魯棒性.在建模完成后再通過集體矩陣分解(Collective Matrix Factorization,CMF)將上述各個單元聯系起來.
文獻[46]中作者發現組織者和活動的文本內容之間的相關性,同一組織者舉辦的活動往往有更多相似的內容,通過組織者與活動內容之間的關聯可以緩解活動文本內容的稀疏性,從而更準確地提取出對活動的群體興趣.文獻[47]中,作者提出了一種基于語義增強和上下文感知的混合協同過濾的活動推薦方法,將語義內容分析和上下文影響相結合,用于用戶的近鄰選擇,試驗表明,應用活動描述語義來建立用戶的興趣模型是有用的,但也需要活動文本對于用戶興趣建模的時間衰減.
3.5 算法參數比較與分析
在各類算法中,許多使用了時間,位置等上下文信息等進行綜合計算,在這些算法中,涉及到對信息以及由這些信息帶來的對結果的影響的合成.經常用超參數來控制合成的方式,而由于算法中考慮的上下文不同,各個算法中的超參數也有所不同.在文獻[24]中,作者將用戶與活動的語義相似度,用戶關系以及用戶歷史信息進行綜合后推薦.在實驗中,對這3者的權重設置了3組值(0.2,0.3,0.5;0.5,0.2,0.3;0.3,0.5,0.2),其中第一種權重設置的精度是最高的.而在利用LDA主題建模對語義進行獲取的過程中,主題數從25個增加到150個時,這時的性能相對穩定.
另外,許多模型中在目標函數中加入多種誤差的權重,以及模型的正則項,它們的系數也需要確定.同時,對于迭代優化過程,需要設置學習速率和迭代參數.目前這些系數通過經驗和實驗進行設置.如在文獻[31]中,在考慮用戶、群組以及活動間的多關系模型中,目標函數為:
(8)
其中,L是所考慮關系的重建誤差的損失函數,α、β、γ是所考慮關系的損失的特定權重和λU、λG、λE正則化參數.對于權重值,作者分別設為0.1,0.22和0.68.作者使用了MRBPR(Multi-Relational Factorization withBayesian Personalized Ranking,貝葉斯個性化排序的多關系分解)進行算法的比較.其對于隱因子參數k設置為200,學習速率為0.1,迭代次數600.而文章作者介紹了一種結合位置信息,時間信息,群組信息等通過坐標上升法優化的基于上下文信息推薦算法MCLRE[31].同樣的,在文獻[44]中研究中,其將學習速率設為0.1,正則化參數設為0.01.經過實驗也發現潛在因子維數k對模型性能的影響較小,在作者自己的模型中維數選擇為100.
MCLRE模型是基于上下文信息活動推薦模型中有代表性的算法,它融合了文本內容、時間、位置和群組信息.該模型在活動描述上使用經典的詞袋模型,每個用戶被表示為從用戶參加的過去活動中提取的單詞的TF-IDF向量,用戶u的形式定義:
(9)

很多研究工作[4,22,43,44,46]對其進行比較與借鑒,這些算法中對信息使用上不少依舊采用MCLRE中的方法.例如在文獻[43]中對上下文信息的使用上對MCLRE中的超參數進行了一定的保留與改進.其中時間衰減因子α為{0.005,0.01,0.5},其余超參數相同.文獻[44]對于在群組偏好的計算:
(10)
g(e,ei)=δ·I(u∈ge)+(1-δ)·I(ge∈gei)
(11)
其中,gp(u,e)表示當用戶參加活動時的群組偏好,ge是主辦活動e的群組,I(u∈ge)表示u是否是ge的成員,舉辦事件e和ei的組是否是同一組.,Sim()是余弦相似度.δ權重設置為0.5.
從相關研究中可以看出,每個模型都具有自己的超參數,目前的超參數取值還是采用了基于經驗和基于實驗的方法.如何能夠更好地設置模型中的超參數,還是一個具有挑戰性的問題.特別是在活動推薦中,許多模型融合多方面的信息,這就必然會帶來較多的超參數,這就使得這一問題更具有挑戰性.
4 基于深度學習的活動推薦模型
4.1 深度學習在推薦系統的作用和意義
深度學習近幾年十分流行.在文獻[48]中,作者對于深度學習在推薦系統中應用進行了綜述,文章主要寫了深度學習如何改進傳統推薦算法例如協同過濾等以及介紹了深度學習方法對于推薦系統的改進.深度學習主要可以改進推薦系統的特征提取與特征表示,使系統學習到更好的用戶和項目的隱向量.嵌入(embedding)技術是深度學習得到目標的低維表示.進一步,循環神經網絡可以對序列數據建模.
根據文獻[49]的研究,深度學習的技術可以增加協同過濾的能力,主要的方法是通過某種形式的深度學習來代替矩陣分解.文獻[50]中提出一種新的上下文感知推薦模型卷積矩陣分解(convolutional matrix factorization,ConvMF),該模型將卷積神經網絡與概率矩陣分解(probabilistic matrix factorization,PMF)相結合,ConvMF能更好捕捉上下文信息并提高預測準確性.文獻[51]中提出了一個層次貝葉斯模型,稱為協同深度學習(collaborative deep learning,CDL),它融合了內容信息的深度表示學習和基于評分矩陣的協同過濾.文獻[52]中的研究表明,協同過濾可以轉化為序列預測問題,因此遞歸神經網絡可以起到作用.
圖神經網絡是深度學習在圖上一種新應用,主要分為遞歸圖形神經網絡、卷積圖形神經網絡、圖形自動編碼器和時空圖形神經網絡[53].圖神經網絡作為一種能夠自然地集成節點信息和拓撲結構的網絡,在圖數據的學習中有很好的效果,已經被用于推薦系統[54].
4.2 活動推薦中深度學習的應用
文獻[55]中提出了基于用戶深度建模框架的活動推薦(Deep User Modeling framework for Event Recommendation,DUMER),通過挖掘用戶參與活動的上下文信息來刻畫用戶的偏好,并利用卷積神經網絡和詞嵌入技術來深入捕捉用戶感興趣活動的上下文信息,并為每個用戶建立用戶潛在模型,再將用戶潛在模型引入概率矩陣分解模型,提高推薦精度,在實驗中與另外兩種基于深度學習模型ConvMF[50]和CDL[51]比較,該模型在RMSE與召回率表現更優.實驗也表明,嵌入與bag-of-word模型對比,使用嵌入能更好地捕獲活動的上下文信息.文獻[56]中,研究了一種基于卷積神經網絡的用戶和活動聯合表示方法,以減輕冷啟動影響:在第一階段,進行聯合表示學習,同時建立活動模型和用戶模型,對于兩個模型通過卷積神經網絡進行數據預處理,將任何給定的用戶和活動投影到同一個潛在空間中,實現高效和準確的匹配;第二階段,將匹配結果作為一個特征,與其他標準特征一起,輸入到基于梯度增強決策樹(Gradient Boosting Decision Tree,GBDT)的組合器模型中.
深度學習除了對于特征提取上對于活動推薦有所助益,在對預測上也有很大的提升,利用循環神經網絡對序列建模,可以更好地反映用戶興趣.
文獻[57]中,提出了一種循環神經網絡模型來解決時間異構反饋推薦,時間異構反饋推薦的任務是決定用戶將來可能感興趣的項目,而反饋的順序反映了用戶偏好的變化.在文獻[58]中,作者提出了一個共同進化的潛在特征過程模型,該模型能夠準確地捕捉用戶和項目特征的共同進化性質,使用循環神經網絡來自動學習來自用戶和項目特征的漂移、進化和協同進化的影響的表示.文獻[59]中運用了一個3層長短期記憶網絡(LSTM,Long Short-Term Memory)的結構,在第1層中,將活動的上下文信息以非線性的方式轉化為潛在的嵌入向量;在第2層中,考慮用戶在不同組中的出勤行為來編碼用戶不斷變化的獨特偏好;第3層中,對用戶的順序偏好進行編碼,以捕獲出勤模式的時間演化特性,并與前兩層生成的嵌入向量進行交互,生成語義嵌入偏好向量的多維編碼,最后,輸入到多層感知器(Multilayer Perceptron,MLP)中,用于預測每個用戶的活動出席率.而文獻[60]中,作者提出了一個基于LSTM模型DeepVenue,用于推薦舉辦Meetup活動的場館.
文獻[61]中,作者對神經網絡RankNet進行了改進,建立了一個學習排序算法來揭示每個特征的重要性,其性能與基于多特征評分模型的MHF[62]和基于上下文感知的MCLRE[31]等算法相比,表現要更好.文獻[63]中,作者提出了一個混合式深度神經網絡協同過濾架構(HDNN-CF,Hybrid Deep Neural Networks CollaborativeFiltering).這是一個生成模型,它將協同訓練一個堆疊降噪自動編碼器(SDAE,Stacked Denoising Auto Encoder)以深度表示語義信息和一個用于表示隱式反饋的PAutoRec模型.PAutoRec是AutoRec[64](autoencoder framework for collaborative filtering,基于自動編碼器的協同過濾模型)的擴展,它引入了自適應先驗,通過合適的先驗能自動控制模型的容量.實驗結果顯示,HDNN-CF在前30名推薦的召回率上比現有方法有10%以上的顯著提高.
綜合看來,深度學習在活動推薦中方興未艾.兩者的結合應用上還有很大的研究空間.表1所示為文章歸納的文獻分類.

表1 活動推薦的方法分類
5 研究展望
1)更豐富的數據集支持更多的推薦場景
目前的許多研究工作都是基于Meetup的數據,但是Meetup數據集本身也存在一定的不足,例如其缺乏活動持續時間.如果數據集中包含更多信息,則可以支持更為豐富的推薦場景.例如文獻[12]提出的展會數據集,由于展會密集的活動行程、活動沖突和充足的時間信息,能更好對分布式活動以及活動行程進行推薦.雖然該數據集的作用和本文著重討論的EBSNs下的活動推薦有所出入,但活動行程推薦能很好幫助用戶規劃自己行程,尤其是在活動密集的會議和展覽中效果顯著,值得進一步的探索.
2)融合用戶更詳細的信息
現有的研究將大部分注意力都集中在活動的社會性方面,包括成員影響力,成員社交圈等.研究證明這些因素確實影響活動推薦的準確率,然而關于活動成員以及用戶的研究仍可以細化與深入.目前研究的維度主要是活動與其他參與者對用戶的影響,卻很少有文章從用戶自身因素做研究,例如用戶的個人信息、經濟能力等.
3)考慮平臺和地點差異性
文獻[38]的實驗中,北京與上海兩地預測的準確率差距說明了地理信息不同對于活動推薦的影響也不盡相同.這說明,在不同的地域中,用戶對活動的偏好可能有所不同.進一步,在不同的平臺上,用戶群體也有差別,這使得某一平臺上的模型并不能簡單遷移到另一平臺上.如何考慮由于地點、平臺差別帶來的異構性,是一個值得探討的問題.
4)推薦中考慮更多的目標
目前對活動推薦很少有對于推薦公平性、多樣性等測定,這是目前研究中存在的不足,也是未來研究中值得考慮的問題.
5)深度學習在活動推薦中的應用
深度學習在活動推薦中應用的文獻較少,但是深度學習在推薦系統領域已經取得了很大的進展,可以預計深度學習對于活動推薦一定有所幫助,考慮到圖模型在活動推薦廣泛的應用,圖神經網絡可能是深度學習在活動推薦中一個比較好的研究方向.
6 總 結
隨著Meetup、豆瓣同城等網站的流行,EBSNs上的活動推薦成為了一個熱門的領域.本文對EBSNs環境以及活動特性進行描述,總結了其對活動推薦產生的影響,指出了由于活動缺乏反饋信息等而引起的嚴重冷啟動問題以及活動屬性極大地影響了用戶對于活動的選擇.這些問題直接導致傳統的推薦方法在活動推薦中應用難以取得滿意的結果.在活動推薦中較為常見評價指標是AUC、P@n以及nDCG,而活動推薦的數據集一般由作者自行在meetup等活動推薦網站爬取,文中通過分析活動推薦考慮的因素維度和活動推薦模型闡述了活動推薦的研究進展.現有的推薦模型大多是混合方法.其中,基于圖的方法能很好地對EBSNs異構關系進行建模,但是圖方法需要大量的數據以及計算量.基于上下文感知的推薦算法在推薦中能擴展數據,并且時間,位置以及主辦人信息等能緩解冷啟動問題.深度學習能夠自動學習活動、用戶的深度表示,一方面能夠緩解冷啟動問題,另一方面也能對復雜關系進行建模,在活動推薦中具有良好的應用前景.
猜你喜歡
少先隊活動(2022年5期)2022-06-06 03:45:04
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
中老年保健(2021年2期)2021-08-22 07:31:10
海峽姐妹(2018年3期)2018-05-09 08:20:40
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
