一種基于證據(jù)推理規(guī)則的集成學(xué)習(xí)方法
2021-08-24 06:53:16朱海龍曲媛媛楊文佳
小型微型計算機系統(tǒng) 2021年8期
朱海龍,徐 聰,曲媛媛,賀 維,3,楊文佳
1(哈爾濱師范大學(xué) 計算機科學(xué)與信息工程學(xué)院,哈爾濱 150500)
2(黑龍江農(nóng)業(yè)工程職業(yè)學(xué)院,哈爾濱 150500)
3(中國人民解放軍火箭軍工程大學(xué),西安 710025)
1 引 言
深度學(xué)習(xí)作為機器學(xué)習(xí)的一個分支,在數(shù)據(jù)挖掘、自然語言處理、推薦系統(tǒng)、目標(biāo)追蹤、圖像識別等多個領(lǐng)域都取得了顯著的成果,成為目前人工智能領(lǐng)域最受關(guān)注的技術(shù).然而深層神經(jīng)網(wǎng)絡(luò)算法(Deep neural network algorithm,DNN)、卷積神經(jīng)網(wǎng)絡(luò)算法(Convolutional neural network algorithm,CNN)、遞歸神經(jīng)網(wǎng)絡(luò)算法(Recursive neural network algorithm,RNN)等深度學(xué)習(xí)領(lǐng)域的典型算法,在實際運用時受限于數(shù)據(jù)集的規(guī)模,有時難以提取到高精度的特征,使得模型無法達到預(yù)期效果.這時便需要對模型進行優(yōu)化,當(dāng)數(shù)據(jù)擴充等方式達到優(yōu)化的瓶頸時,人們經(jīng)常采用集成學(xué)習(xí)算法合并多個分類器的結(jié)果,降低泛化誤差,提高最終模型的準(zhǔn)確率.
集成學(xué)習(xí)由于其良好的泛化性能,一直以來都是學(xué)者研究的熱點方向.文獻[1]提出Bagging算法,該方法先采用有放回抽樣的方式,產(chǎn)生多個數(shù)據(jù)集,之后通過基分類器訓(xùn)練模型,以簡單多數(shù)投票法作為結(jié)合策略,將多個模型集成得到最終結(jié)果,該方法作為集成學(xué)習(xí)領(lǐng)域的典型算法,為集成學(xué)習(xí)后續(xù)的發(fā)展奠定了堅實的基礎(chǔ).文獻[2]提出一種基于支持向量機的集成學(xué)習(xí)方法,該方法使用隨機欠抽樣與合成少數(shù)類過抽樣技術(shù)結(jié)合的方式對數(shù)據(jù)集進行處理,形成多個數(shù)據(jù)子集,之后使用Boosting算法訓(xùn)練出多個基支持向量機的強分類器模型,通過投票法集成得到最終結(jié)果,該方法具有良好的檢測性能.文獻[3]提出了一種用于軟件知識庫挖掘的,基于進化規(guī)劃的非對稱加權(quán)最小二乘支持向量機集成學(xué)習(xí)方法,相比于其他分類算法可以有效提高精度.文獻[4]提出了漸進式半監(jiān)督集成學(xué)習(xí)方法,該方法在大多數(shù)數(shù)據(jù)集上都可以取得良好的表現(xiàn),并在部分?jǐn)?shù)據(jù)集上表現(xiàn)優(yōu)越.文獻[5]針對不同的標(biāo)記源和非標(biāo)記源,提出了一種集成學(xué)習(xí)算法,這種算法對于大型信息源具有更強的可擴展性,對于帶噪聲數(shù)據(jù)的標(biāo)記源具有更強的魯棒性.文獻[6]在Bagging算法、AdaBoost算法、BRB(Belief Rule-Base)3者結(jié)合的基礎(chǔ)上提出了基于梯度下降法的BRB系統(tǒng)的集成學(xué)習(xí)方法,該算法比單個BRB系統(tǒng)更為合理有效.文獻[7]提出一種個性化加權(quán)的在線集成算法,該方法先將基分類器的權(quán)重與樣本集的相似性進行關(guān)聯(lián),計算數(shù)據(jù)塊之間的相似度,以該相似度為指標(biāo)確定數(shù)據(jù)塊對應(yīng)基分類器的投票權(quán)重,再進行集成,該方法以在線的形式與無線傳感器網(wǎng)絡(luò)數(shù)據(jù)流進行了響應(yīng),相比傳統(tǒng)的在線學(xué)習(xí)算法有更高的預(yù)測精度.以上文獻都是近年來較為新穎的集成學(xué)習(xí)方法,然而這些方法在集成時大多采用平均法、投票法等表決融合方式作為結(jié)合策略,無法有效挖掘分類器的內(nèi)部信息,不能明確地體現(xiàn)出各個分類器之間存在的關(guān)系,在多種分類器集成時無法將融合效果最大化.這種現(xiàn)象就像一個只能認(rèn)知世界的嬰兒,在擁有很多玩具時,無法通過自己的判斷獲得最好的搭配方案,需要大人的幫助進行決策.
人工智能是在研究模擬人類智能的基礎(chǔ)上,衍生出的一門新的技術(shù)學(xué)科,集成學(xué)習(xí)作為該學(xué)科中重要的一個分支,也是在模擬人類思維方式的基礎(chǔ)上建立起來的,它的集成過程便相當(dāng)于人類的決策過程,因此也可以從決策的角度對集成學(xué)習(xí)的集成過程進行優(yōu)化.Dempster-Shafer(D-S)證據(jù)理論作為智能決策領(lǐng)域的重要組成部分,利用Dempster規(guī)則進行證據(jù)融合,實現(xiàn)不確定性推理,具有很強的靈活性.然而該算法無法解決沖突證據(jù),且存在指數(shù)爆炸等問題[8-10].
2013年,Yang等人建立了考慮證據(jù)權(quán)重和證據(jù)可靠度的ER規(guī)則,它明確區(qū)分了證據(jù)的可靠性和重要性,構(gòu)成了一個通用的聯(lián)合概率推理過程,可以有效地解決D-S證據(jù)推理中存在的問題[11,12].ER規(guī)則作為D-S理論的進一步發(fā)展,已經(jīng)成為非經(jīng)典推理領(lǐng)域的重要組成元素,并被成功應(yīng)用于現(xiàn)代社會的各個行業(yè)中.文獻[13]給出了基于ER規(guī)則的故障診斷方法,并使用該方法來解決不確定性故障特征信息的融合決策問題,該方法繼承了D-S證據(jù)理論的優(yōu)點,并克服了其無法區(qū)分證據(jù)可靠性和重要性的不足,可以使獲得的診斷證據(jù)更為客觀.文獻[14]通過研究ER規(guī)則中證據(jù)權(quán)重歸一化對合成結(jié)果的影響及ER規(guī)則與證據(jù)折扣方法之間的聯(lián)系,在證據(jù)的重要性與可靠性表示上提出了一種改進方法.文獻[15]提出了一種應(yīng)用ER推理規(guī)則的多指標(biāo)醫(yī)學(xué)質(zhì)量評價框架,將數(shù)據(jù)指標(biāo)轉(zhuǎn)換為定性等級,提高了不確定性條件下模型的魯棒性.文獻[16]提出一種基于數(shù)據(jù)可靠性和區(qū)間證據(jù)推理的故障檢測方法,將專家知識與考慮可靠性的監(jiān)測數(shù)據(jù)進行融合,提高了故障檢測的準(zhǔn)確性.文獻[17]提出了一種擾動系數(shù)來表征ER規(guī)則的性能指標(biāo),分析了ER規(guī)則的魯棒性和穩(wěn)定性,為ER規(guī)則的研究運用提供理論依據(jù)和技術(shù)支持.
本文從智能決策的角度,采用ER規(guī)則作為集成學(xué)習(xí)中集成多種分類器時的結(jié)合策略,在集成過程中考慮了各個分類器之間實際存在的關(guān)聯(lián),克服了只考慮分類器數(shù)據(jù)間數(shù)值關(guān)系的集成學(xué)習(xí)算法的不足,并進一步提高了模型的準(zhǔn)確率.在模型建模過程中,將分類器的預(yù)測結(jié)果視做ER規(guī)則中的證據(jù),利用統(tǒng)計分析的方法設(shè)置證據(jù)的可靠度,運用熵權(quán)法代替專家知識來確定證據(jù)的權(quán)重,進一步增強模型參數(shù)設(shè)置的科學(xué)性.
文章結(jié)構(gòu)如下:第1章對文章所解決問題的背景進行了概況描述;第2章從人的思維角度對集成學(xué)習(xí)的過程進行了分析與描述;第3章構(gòu)建基于ER規(guī)則的集成學(xué)習(xí)模型,給出模型中證據(jù)的權(quán)重和可靠度的計算方法,并定義了模型的集成學(xué)習(xí)過程;第4章通過案例分析,驗證了模型的有效性:第5章對全文進行了總結(jié)并提出今后工作的展望.
2 問題描述
人工智能是對人的意識、思維的一種延伸,它通過模擬人類基于智能創(chuàng)造出的理論、方法、技術(shù),使得機器可以對客觀世界產(chǎn)生類似于人類智能的反應(yīng),并對這種反應(yīng)進行進一步的擴展[18].人工智能模擬人類行為的過程主要包括以下3個階段:感知,認(rèn)知,決策[19].具體實現(xiàn)如下:
1)智能感知階段:機器設(shè)備智能感知外界事物,形成可以被算法處理的數(shù)據(jù),將數(shù)據(jù)進行整理,形成數(shù)據(jù)集.假設(shè)v表示外界事物信息轉(zhuǎn)換形成的數(shù)據(jù)集,例如圖像、文本等類型數(shù)據(jù).
2)智能認(rèn)知階段:數(shù)據(jù)集通過K種深度學(xué)習(xí)算法,形成K種分類器,稱為智能認(rèn)知模型.假設(shè)u(k)表示第k(k=1,…,K)種智能認(rèn)知模型的認(rèn)知結(jié)果.這個過程能夠被描述為:
u(k)=fk(v,α)
(1)
其中,fk(·)表示第k種深度學(xué)習(xí)算法的認(rèn)知過程,α表示認(rèn)知過程中的參數(shù)集合.
3)智能決策階段:將智能認(rèn)知模型的認(rèn)知結(jié)果通過相關(guān)策略進行集成,得到智能決策結(jié)果.假設(shè)u表示智能決策結(jié)果.這個過程能夠被描述為:
u=g(u(k),β)
(2)
其中,g(·)表示智能決策的過程,β表示在決策過程中的參數(shù)集合.
集成學(xué)習(xí)可以認(rèn)為是對問題的決策,通過對不同分類器的輸出進行分析,獲取最優(yōu)輸出結(jié)果.基于以上思想,通過人工智能模擬人類行為的過程來構(gòu)建集成學(xué)習(xí)模型需要解決以下問題:
問題1.在構(gòu)建集成學(xué)習(xí)方法時,從人類智能的角度描述集成學(xué)習(xí)過程.
問題2.在構(gòu)建集成學(xué)習(xí)方法時,有效挖掘分類器內(nèi)部和分類器之間的有效信息,進一步提高集成學(xué)習(xí)模型效果.
基于以上挑戰(zhàn),本文提出一種基于ER規(guī)則的集成學(xué)習(xí)方法.如圖1所示.
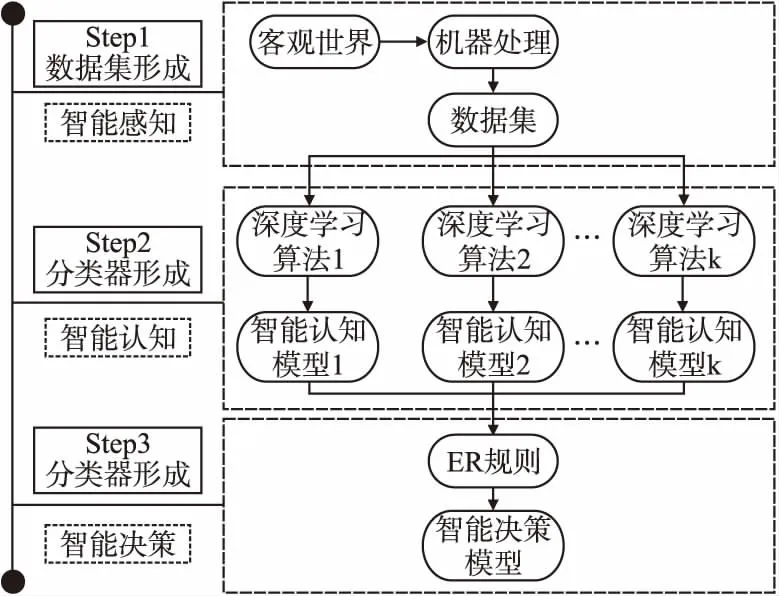
圖1 基于證據(jù)推理的集成學(xué)習(xí)模型
3 基于ER規(guī)則的集成學(xué)習(xí)模型
ER規(guī)則作為一種優(yōu)秀的智能決策算法,在ER算法的基礎(chǔ)上,新增了證據(jù)的可靠度屬性,并融合到證據(jù)的置信分布中,通過ER規(guī)則可以更好地解決實際工程問題.
本文通過深度學(xué)習(xí)算法對機器感知世界形成的數(shù)據(jù)集進行處理,建立智能認(rèn)知模型.將智能認(rèn)知模型對于數(shù)據(jù)認(rèn)知的結(jié)果作為證據(jù),運用ER規(guī)則進行證據(jù)融合,構(gòu)建智能決策模型,得到智能決策結(jié)果.在構(gòu)建過程中,利用熵權(quán)法確定不同證據(jù)的權(quán)重,利用數(shù)理統(tǒng)計確定不同證據(jù)的可靠度.建模過程如圖2所示.

圖2 集成學(xué)習(xí)模型的建模過程
3.1 集成模型的前期準(zhǔn)備
通過傳感器、攝像頭等智能認(rèn)知設(shè)備,將客觀世界的信息轉(zhuǎn)換成圖片、文本等計算機可以處理的數(shù)據(jù),將數(shù)據(jù)整理作為輸入數(shù)據(jù)集,通過不同的深度學(xué)習(xí)算法提取數(shù)據(jù)的特征,經(jīng)過訓(xùn)練得到智能認(rèn)知模型.在訓(xùn)練過程中不斷調(diào)整所使用的深度學(xué)習(xí)算法參數(shù),提高智能認(rèn)知模型的能力.
3.2 集成模型的構(gòu)建
以智能認(rèn)知結(jié)果為輸入證據(jù),通過ER規(guī)則進行融合,建立智能決策模型,在融合過程中通過熵權(quán)法等客觀方法確定證據(jù)權(quán)重和證據(jù)可靠度,提高模型的決策能力.
3.2.1 證據(jù)權(quán)重
在傳統(tǒng)的ER規(guī)則中,證據(jù)權(quán)重的設(shè)定通常由專家知識直接給出,然而專家知識具有主觀性,且系統(tǒng)結(jié)構(gòu)復(fù)雜時,無法給出精確的結(jié)果,這些問題同時也限制了ER規(guī)則在一些場景中的使用.
為提高決策模型的科學(xué)性,擴大其使用范圍,本文采用熵權(quán)法代替專家知識來確定權(quán)重,熵權(quán)法作為一種基于數(shù)據(jù)的客觀賦值方法,在系統(tǒng)情況復(fù)雜時,仍然可以通過數(shù)理分析的方法確定出精準(zhǔn)的權(quán)重結(jié)果[20],已經(jīng)被廣泛運用于各個領(lǐng)域.在熵權(quán)法中,某個指標(biāo)的信息熵EJ越大,它的離散程度越小,在綜合評價中所起到的作用也越小,權(quán)重也越小[21].確定證據(jù)權(quán)重的過程如圖3所示,步驟如下:
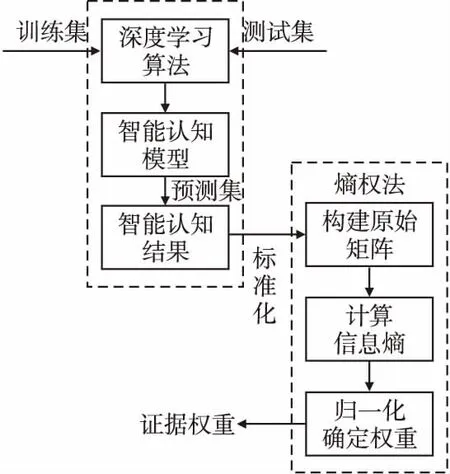
圖3 證據(jù)權(quán)重計算過程
1)數(shù)據(jù)標(biāo)準(zhǔn)化
將機器感知信息形成的數(shù)據(jù)集v劃分為訓(xùn)練集、測試集、預(yù)測集3部分.
以訓(xùn)練集與測試集為輸入數(shù)據(jù),通過深度學(xué)習(xí)算法建立智能認(rèn)知模型u(k),以預(yù)測集為輸入數(shù)據(jù),通過智能認(rèn)知模型得到智能認(rèn)知結(jié)果x,作為原始指標(biāo)矩陣中各個指標(biāo)的數(shù)據(jù),并進行標(biāo)準(zhǔn)化處理.假設(shè)有p個樣本,K個智能認(rèn)知模型,T種情況,則存在KT個指標(biāo)X1,X2,…,XKT,其中Xj={x1j,x2j,……,xPj},xij為第i個樣本的第j個指標(biāo)數(shù)值(i=1,…,p;j=1,…,KT);本文中所使用的指標(biāo)均為正向指標(biāo),通過Min-Max標(biāo)準(zhǔn)化得到:
(3)
2)計算上述正向指標(biāo)的信息熵
第j個指標(biāo)的信息熵為:
(4)
其中,
(5)
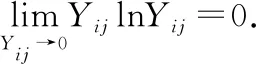
3)歸一化確定上述正向指標(biāo)的權(quán)重
由式(4)計算得出各組數(shù)據(jù)的信息熵為:
E1,E2,…,EKT
通過信息熵計算得:
(6)
(7)
其中,wkt為第kt個指標(biāo)的權(quán)重,wk為第k個智能認(rèn)知模型認(rèn)知結(jié)果的權(quán)重,即ER規(guī)則中第k個證據(jù)的權(quán)重.
3.2.2 證據(jù)可靠度
證據(jù)可靠度由智能認(rèn)知結(jié)果對應(yīng)給出,如圖4所示,流程如下:

圖4 證據(jù)可靠度計算過程
以數(shù)據(jù)集v中的訓(xùn)練集與測試集為輸入數(shù)據(jù),通過深度學(xué)習(xí)算法建立智能認(rèn)知模型u(k),以預(yù)測集為輸入數(shù)據(jù),通過智能認(rèn)知模型得到智能認(rèn)知結(jié)果,最終通過數(shù)理統(tǒng)計將智能認(rèn)知結(jié)果轉(zhuǎn)化為概率形式,作為該認(rèn)知結(jié)果的證據(jù)可靠度,即ER規(guī)則中第k個證據(jù)的可靠度.
3.2.3 證據(jù)推理過程
1)假設(shè)集成過程中每個智能認(rèn)知模型的認(rèn)知結(jié)果為一個獨立的證據(jù),則共有K條獨立證據(jù)ek(k=1,…,K).證據(jù)推理過程如圖5所示.
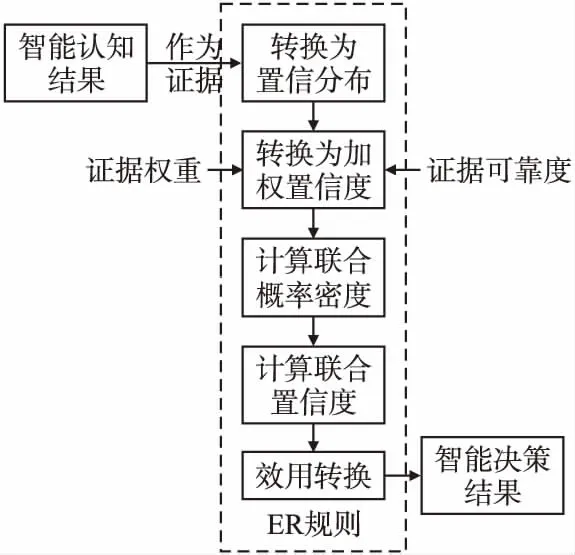
圖5 證據(jù)推理過程
先將證據(jù)表示為置信分布,即第k個智能認(rèn)知模型的認(rèn)知結(jié)果ek可以被表示為:
ek={(θn,pn,k),n=1,…,N;(Θ,pΘ,k)}
(8)
其中θn(n=1,…,N)是評估等級.pn,k表示該評估方案在證據(jù)ek下被評估為θn的置信度,N為評估等級的個數(shù).Θ={θ1,…,θN}為辨識框架,pΘ,k表示全局無知.
2)獨立證據(jù)ek的權(quán)重為wk由3.2.1得出,可靠度為rk由3.2.2得出.帶有可靠性的第k條證據(jù)的加權(quán)置信分布為:
(9)
其中,
(10)
(11)

3)K條獨立證據(jù)ek(k=1,…,K),對命題θ的Pθ,e(b)可以通過迭代下式得到:
∑A∩B=θmA,e(b-1)mB,b,?θ?Θ
(12)
(13)
(14)
(15)
其中,k=1,…,L,mθ,e(1)=mθ,1,mP(Θ),e(1)=mP(Θ),1,mθ,e(b)為b條證據(jù)的聯(lián)合概率密度,pθ,e(b)為b條證據(jù)的聯(lián)合置信度.
4)設(shè)評估等級θn的效用為u(θn),決策模型的期望效用為:
(16)
4 案例分析
4.1 基于氣象識別數(shù)據(jù)集的實驗
本次實驗所使用的數(shù)據(jù)集為GitHub平臺上提供的天氣圖像公共數(shù)據(jù)包,內(nèi)容為智能交通領(lǐng)域中某道路在不同天氣情況下拍攝到的圖片,按天氣分為clear(484張)、cloudy(816張)、rain(648張)、snow(90張)4種情況,總計2038張圖片.對于數(shù)據(jù)集中的每張圖片采用Densenet、InceptionV3、Vgg16、Alexnet 4種深度學(xué)習(xí)算法進行預(yù)測分類,建立智能認(rèn)知模型與智能決策模型,通過不同模型之間準(zhǔn)確率的比較,驗證該集成學(xué)習(xí)方法的有效性.具體實驗步驟如下:
1)將數(shù)據(jù)集按6∶2∶2的比例劃分為訓(xùn)練集、測試集、預(yù)測集,以訓(xùn)練集、測試集為輸入數(shù)據(jù)導(dǎo)入到4種深度學(xué)習(xí)算法中,迭代優(yōu)化產(chǎn)生4種智能認(rèn)知模型.
2)將預(yù)測集導(dǎo)入到4種建立好的智能認(rèn)知模型中,得出預(yù)測集中每張圖片分別屬于4種天氣情況的概率,作為各智能認(rèn)知模型的智能認(rèn)知結(jié)果.
3)標(biāo)準(zhǔn)化智能認(rèn)知結(jié)果,形成原始指標(biāo)矩陣,通過熵權(quán)法計算得出證據(jù)權(quán)重.
4)對智能認(rèn)知結(jié)果進行統(tǒng)計分析,得到各個智能認(rèn)知模型的認(rèn)知準(zhǔn)確率,將準(zhǔn)確率作為證據(jù)可靠度.
5)以智能認(rèn)知結(jié)果為證據(jù),以ER規(guī)則為結(jié)合策略,將4種智能認(rèn)知模型的智能認(rèn)知結(jié)果進行融合,形成決策模型,通過效用轉(zhuǎn)換,計算準(zhǔn)確率,即為智能決策結(jié)果.
本次實驗所使用的4種深度學(xué)習(xí)算法在卷積層均采用RELU激活函數(shù),并以全連接層接softmax函數(shù)作為輸出層,在訓(xùn)練過程的超參數(shù)設(shè)置如表1所示.
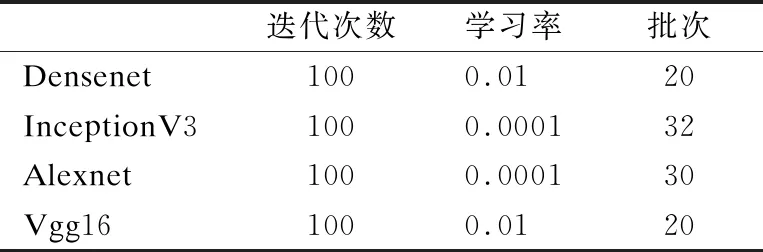
表1 各模型的超參數(shù)
將預(yù)測集按clear、cloudy、rain、snow4種天氣情況分類后,作為輸入數(shù)據(jù)導(dǎo)入到智能認(rèn)知模型與智能決策模型中,分別計算模型對不同天氣情況下數(shù)據(jù)的預(yù)測準(zhǔn)確率.
如表2及圖6所示.基于ER規(guī)則的集成學(xué)習(xí)模型相比于單一的深度學(xué)習(xí)算法,在準(zhǔn)確率方面有了明顯的提升.
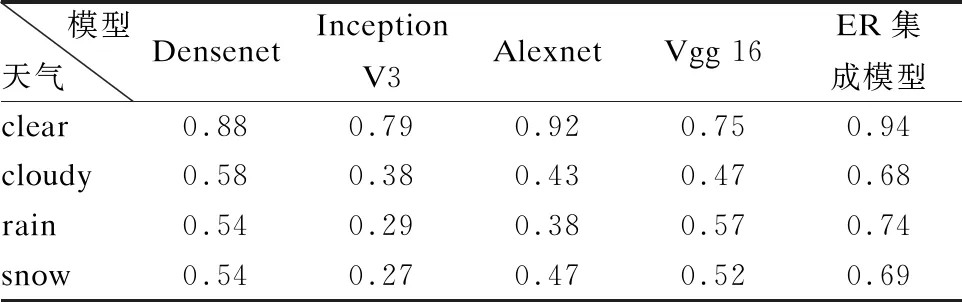
表2 不同天氣情況下各模型準(zhǔn)確率結(jié)果
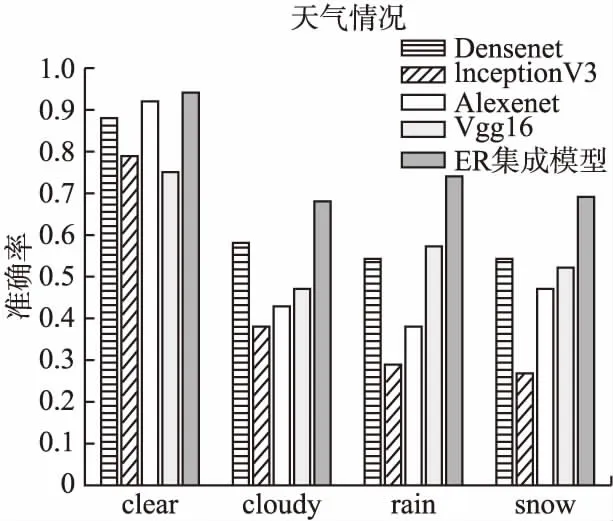
圖6 不同天氣情況下各模型準(zhǔn)確率對比
將數(shù)據(jù)集直接導(dǎo)入到不同模型中,得到總情況下各模型的準(zhǔn)確率,如表3所示.在總體情況下,由ER規(guī)則進行集成后的集成模型比效果最好的深度學(xué)習(xí)算法在準(zhǔn)確率方面依舊有2%-3%的有效提升.

表3 總情況下各模型準(zhǔn)確率結(jié)果
仍以Densenet、InceptionV3、Alexnet、Vgg16這4種深度學(xué)習(xí)算法作為基分類器,采用不同的結(jié)合策略,對其形成的智能認(rèn)知模型進行集成,準(zhǔn)確率對比結(jié)果如表5所示.由ER規(guī)則作為結(jié)合策略的集成學(xué)習(xí)模型相比于其它集成學(xué)習(xí)模型有更高的準(zhǔn)確率,基于熵權(quán)法的ER集成模型與基于專家知識的ER集成模型在準(zhǔn)確率方面相近,但基于樣本確定權(quán)重的熵權(quán)ER規(guī)則在融合多種分類器時,所設(shè)置的權(quán)重(如表4所示)更具科學(xué)性.

表4 不同ER規(guī)則的權(quán)重對比

表5 總情況下不同結(jié)合策略的集成模型準(zhǔn)確率結(jié)果
4.2 基于花卉識別數(shù)據(jù)集的實驗
本次實驗所使用的數(shù)據(jù)集為百度AI Studio平臺提供的公開數(shù)據(jù)集Flower中的部分?jǐn)?shù)據(jù)集,包括daisy(633張)、dandelion(898張)、roses(641)、sunflowers(699張)4種,共計2871張圖片,按訓(xùn)練集、測試集、預(yù)測集按6:2:2的比例進行劃分.
將劃分好的預(yù)測集作為輸入數(shù)據(jù),導(dǎo)入到InceptionV2、InceptionV3、Alexnet、Vgg16這4種深度學(xué)習(xí)算法建立的智能認(rèn)知模型與ER集成模型中,預(yù)測準(zhǔn)確率如表6所示.經(jīng)過集成后的ER決策模型,相比單個模型,在準(zhǔn)確率方面,有了一定的提高.

表6 各模型準(zhǔn)確率結(jié)果
采用不同的結(jié)合策略對上述4種模型進行集成,集成后模型的準(zhǔn)確率如表7所示,以ER規(guī)則為結(jié)合策略的集成模型相較其他方法效果更為優(yōu)秀.

表7 不同結(jié)合策略的集成模型準(zhǔn)確率結(jié)果
本文所用的方法,首先通過不同的深度學(xué)習(xí)算法分析訓(xùn)練數(shù)據(jù),建立對應(yīng)的智能認(rèn)知模型,然后通過基于熵權(quán)法的ER規(guī)則將不同的智能認(rèn)知模型進行集成形成智能決策模型,該方法符合人對事物的認(rèn)知過程,最后將該方法分別運用于智能交通領(lǐng)域的氣象識別及經(jīng)典花卉識別任務(wù)中,通過準(zhǔn)確率的提升證明了實驗方法的有效性,并證明了該方法的泛化性能.
5 總結(jié)及展望
本文提出了一種基于ER規(guī)則的集成學(xué)習(xí)方法,豐富了集成學(xué)習(xí)領(lǐng)域的結(jié)合策略,并得到以下結(jié)論:
1)以ER規(guī)則作為結(jié)合策略的集成學(xué)習(xí)方法相比于使用其它結(jié)合策略的集成學(xué)習(xí)方法,其集成過程清晰透明,結(jié)果可追溯,并在準(zhǔn)確率方面有了一定的提升.但該方法在基分類器為抽象級或排序級輸出時,實用性還有待論證.
2)由熵權(quán)法設(shè)定權(quán)重的ER規(guī)則與由專家知識設(shè)定權(quán)重的ER規(guī)則相比,提供了精確的權(quán)重,不僅可以從統(tǒng)計分析的角度解釋權(quán)重設(shè)立的合理性,提高模型的科學(xué)性,還可以應(yīng)用于一些復(fù)雜情況中.此外,對于證據(jù)權(quán)重的設(shè)置還存在許多可以優(yōu)化的地方,使其更為合理.
3)該方法適用于多種領(lǐng)域的分類任務(wù),但在回歸任務(wù)、目標(biāo)追蹤等方面的效果還有待驗證.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學(xué)報(哲學(xué)社會科學(xué)版)(2016年9期)2017-01-15 13:52:02
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
