分片Lorenz混沌軌道堆棧聚集變密度振蕩搜索算法
2021-08-24 07:24:36林之博劉媛華
小型微型計算機系統 2021年8期
林之博,劉媛華
(上海理工大學 管理學院,上海 200093)
1 引 言
復雜連續函數極值問題是一類常見的優化難題,對特定的復雜函數,通常可以通過求導的方法找出精確極值解.但實際情況中存在維度較高、求解域廣泛、全局最優解在微搜索域褶皺中難以定位的復雜函數,精確求解方法往往無效,只能用啟發式算法嘗試求出滿意解.目前有學者提出改進混合粒子群算法[1],針對特定工程應用問題有一定的效果;另有研究使用改進的水波優化求解優化問題,在水波優化算法基礎上融合了單純型法和簡單Logistic混沌特性,能夠有限提升算法性能[2];此外常見的優化過的遺傳算法、蟻群算法、粒子群算法等也具有求解中等復雜連續函數極值的能力,但收斂時間容易過長[3].上述算法雖能對某些問題取得較好求解效果,但普遍容易陷入局部最優后無法跳出.
混沌優化算法最早是由李兵等人于1997年提出的一類智能優化算法[4],該算法理論上具有很強的跳出能力,可以規避蟻群算法、遺傳算法等陷入局部最優無法跳出的情況[4].通常在該算法中引入Logistic混沌系統[5,6],利用混沌映射的遍歷性、初值敏感性等特征產生混沌序列作為搜索最優解的軌道[1,4].沿該軌道對解空間進行搜索,有更大的可能性找到目標最優解[4,6].混沌優化算法自提出后常被用于結合改善其他算法,例如結合混沌系統構成新型混沌粒子群算法[1]、混沌鯨魚算法[5]、以及混沌煙花算法[7]用于解決多維復雜單目標連續函數極值問題.
雖然現有混沌優化算法具有較好跳出局優的能力,但Logistic系統模型在數據仿真實驗中展現出明顯的過度邊緣游走現象[8],導致同等算力下算法對解空間中心區域的搜索過于稀疏,落入局部最優可能增大,在李金屏等人的仿真測試結果[8]中可得到佐證.故以Logistic為混沌內核的算法往往帶有這類特性.王德成等人改進了Logistic混沌[9],利用反三角Logistic映射產生混沌軌道,以達到等概率搜索的目的,但經過點分布檢測仿真實驗發現其均勻度魯棒性欠佳,且算法不均衡,收斂性較弱;官國榮等人提出的改進Lorenz系統所得新模型能夠產生更復雜的混沌行為[10],但軌道形狀難以規范到指定區間.此外,原始的混沌優化算法和基于隨機過程的智能進化算法容易落入微搜索域褶皺上的局部最優值,典型例子是在解決高維Griewank函數極值優化問題時,很難找出全局最優,在解決“大海撈針問題”一類函數時也非常容易落入包圍式局部極值點,通常增加混沌軌道長度能緩解該問題,但會導致混沌軌道過于密集,浪費計算能力的同時也造成了運算時間增長[11].
故考慮改進設計一種新的混沌映射系統,使得混沌軌道均勻度與魯棒性盡可能高;同時,基于新模型設計一套混沌優化算法,一定程度上增強跳出局部最優的能力并提高算法收斂效率.對新模型進行混沌分布檢測和算例測試對比,以證明該算法具有更好的優化性能[11].
2 模型性質與改進
2.1 混沌系統性質
混沌系統是一類具有運動狀態長期不可預測且對系統初始狀態極端敏感的動力系統[4].這類系統一般由狀態參量與控制參量共同組成,其中狀態參量表示系統在狀態空間里的運動過程中所處的位置[12];而控制參量可對系統的運行狀態產生顯著影響.從某一時刻的初始系統狀態出發,使系統按照混沌方程式進行演化,產生的軌跡局部上完全雜亂無章,但全局來看卻具有其規律性(例如Lorenz混沌)[13].混沌系統常被應用于通信加密、工程控制領域,根據不同需求可用特定手段產生或消減混沌.所有混沌系統運動普遍具有共同特征,此處對研究所需的幾種性質做出簡單描述.
性質1.混沌系統具有初值敏感性[4].對任意一個混沌系統的初始條件給予極其輕微的擾動,都可以造成系統運行軌跡完全改變.例如Logistic混沌系統中,給予初始Xn大小為10-6的擾動,可導致系統運動到n=24時,整體偏離值達到0.8719.因此,在優化領域可利用該性質產生長度相等但差異巨大的序列用于生成搜索軌道,即待優化函數的可行解集[6].
性質2.混沌系統具有隨機性,即任何混沌系統狀態的改變長期難以預測,近乎隨機[6].例如Lorenz混沌系統從吸引子某一葉上發生跳轉的行為都是隨機產生的,但這種隨機行為發自系統非線性因素[14].該性質在合理增強后,有助于加快對解空間的均衡搜索.
性質3.混沌系統具有遍歷性,只要給予足夠長的時間,混沌系統能在某范圍內永不重復地游走、經過該空間中所有的系統狀態.利用該性質有助于規避局部最優[9].
性質4.對于混沌動力學系統,其Lyapunove指數與軌道或其等效的映射的表示形式無關[15].即對于線性變換,Lyapunove指數不會發生變化,也不會改變系統的混沌行為.因此對混沌軌道進行縮放操作不改變系統混沌特性[16,17].
2.2 改進混沌系統
原Logistic混沌的方程式如式(1)所示[4,6],其中X為狀態參量,μ為控制參量,當μ取值為4時,系統進入完全混沌態;式(2)為王德成等人提出的反三角變換方程式[9].
Xn+1=μXn(1-Xn)
(1)
(2)
對原Logistic混沌與反三角Logistic系統進行對照分析檢驗.利用Logistic、反三角Logistic混沌系統各產生兩條長度為1000的序列,歸一化到[0,1]區間構成XOY上的分布.設XOY面上混沌區域中心為(x0,y0),計算從中心開始逐步等面積間隔擴大統計范圍對應的橫縱坐標增量,公式如下:
(3)
其中,UpB為坐標軸上限,DownB為坐標軸下限.分別統計軌道上落在公式(4)所示區間上的點數,記為序列Counter.
(4)
若一個混沌系統軌道分布均勻度較高,則Counter曲線線性表現越明顯.計算Counter中所有元素間差值C[k]-C[k-1],記為E序列.則混沌軌道均勻度可通過公式(5)計算:
(5)
依該方法計算得出原混沌優化中Logistic模型、反三角函數Logistic混沌軌道分布均勻度指標如表1所示.

表1 Logistic與反三角Logistic混沌100次采樣均勻度對比
作出兩個混沌系統的Counter序列曲線與混沌分布對比如圖1所示,圖1(c)所示Logistic混沌邊緣搜索導致的Counter曲線指數型上翹;而圖1(b)展示的反三角Logistic混沌比圖1(a)所示Logistic混沌分布更加均勻,結合圖1(d)和表1可見反三角函數Logistic混沌系統均勻度確實優于原Logistic混沌,但該混沌系統均勻度并不穩定,時大時小,魯棒性欠佳.

圖1 混沌分布與Counter曲線對照
為了更好地避免引入Logistic邊緣游走效應的影響、并提高混沌軌道均勻度魯棒性,考慮基于Lorenz混沌系統改進設計新混沌模型.Lorenz混沌是Lorenz于1963年研究天氣演化時提出的簡化描述方程,其模型[10]如式(6)-式(8)所示.其中,Xn+1、Yn+1、Zn+1都為Lorenz混沌系統的狀態參量,a、b、c都是Lorenz混沌系統的控制參量,通常取a=10、b=28、c=8/3.Lorenz系統在空間中呈現蝴蝶翅膀形狀的兩個混沌吸引子,因此又被稱為“蝴蝶混沌”[10].
Xn+1=Xn+a·(Yn-Xn)·Δs
(6)
Yn+1=Yn+(b·Xn-Xn·Zn-Yn)·Δs
(7)
Zn+1=Zn+(Xn·Yn-c·Zn)·Δs
(8)
由于該系統具有不同于Logistic離散系統的連續混沌特性,在狀態空間中進行更均勻的遍歷,故減少類似Logistic系統邊緣游走的效果更加良好.
對系統產生的Z軸序列做模運算和信號變換操作如公式(9)所示,可獲得分布較均勻的混沌軌道Zsn+1,并規避細微擾動時混沌軌道間偏移過小的情況.
Zsn+1=Zn+1·IMODGear
(9)
I為信號放大控制參量,不妨取15或16;Gear用于調控序列分片模式,當Gear=10或Gear=10I時,軌道都會喪失隨機,經仿真實驗認為取Gear=10I/3時效果最佳.
使用公式(3)-公式(5)計算改進模型的分布均勻度如表2所示,其二維分布如圖2所示.可知改進后模型相對反三角Logistic混沌系統模型產生的混沌軌道具有更高的分布均勻度和更好的魯棒性.

表2 分片Lorenz混沌100次采樣均勻度
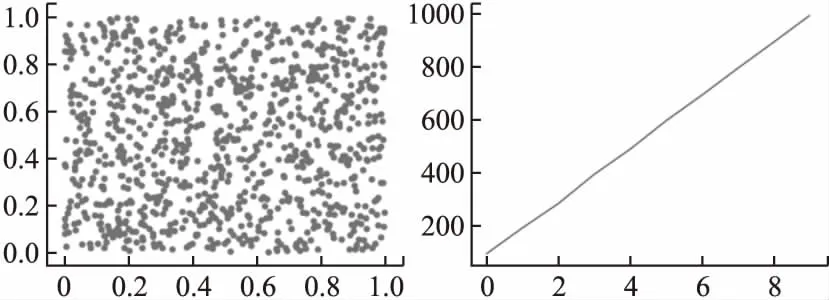
圖2 改進Lorenz混沌分布與Counter曲線對照
故根據性質2,理論上基于新設計的混沌系統模型開發新型混沌優化算法會具有更高的搜索效率.為便于描述,后文統一將基于改進模型的新型算法簡稱為“MLC”算法.
3 算法設計
3.1 MLC搜索算法框架
設計MLC算法總體框架如圖3所示,算法由4項子算法、載波控制器、混沌擾動模塊和停機控制器構成.
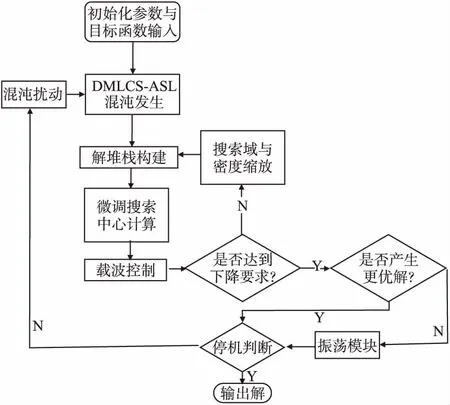
圖3 算法總框架
算法開始需設定初始化參數,例如混沌系統狀態參量和初始可行解等,并指定待優化目標函數和優化方向.開始子迭代過程,運行混沌發生子算法,由性質1:基于2.2設計的改進模型通過隨機微小擾動可產生規定大小的均勻混沌搜索軌道(即可行解集).將產生的軌道輸入到解堆棧子算法中,構造解堆棧;由性質3可知當軌道足夠長或擾動次數足夠多時,堆棧中一定包含滿意解.將堆棧放入聚集出棧子算法,根據堆棧中的解計算搜索中心.
對于新產生的搜索中心,使用載波控制器計算當前解下降是否達到目標精度;若未達到,運行搜索域密度縮放子算法縮小搜索的區域和搜索密度后,轉回混沌發生子算法繼續進行該子迭代;否則,當子迭代產生更優解時,進入停機判斷,若子迭代產生解非更優,則用振蕩模塊修改子迭代初始搜索上下限后再進入停機判斷.
接下來對各項子算法給出詳細描述.
3.2 混沌發生子算法
設F(X)為待優化目標函數,其中X={xi}為函數的i個變量;另有參數up、down分別表示由X中各個變量的區間上限和下限構成的向量;z0為混沌系統的初始Z取值;step為狀態轉移步長,研究過程中取值為0.01;times為設定混沌軌道總長;aband為混沌系統初始演化軌道上刪去的長度,用于保證獲得的混沌軌道完全處于混沌狀態中,一般取100.設XLorenz(up,down,Z0,step,T,aband)為分片Lorenz混沌模型在第T次移動時產生的混沌Z軸值;取信號放大參量I=1016,分片參數Gear=105.混沌發生子過程如下:
Input:input={up,down,Z0,step,T,aband};
Output:TrackMat;
Step 1.初始化Lorenz混沌狀態參量X、Y、Z,設置a=10,b=28,c=8/3;設置系統初始空間位置為x=1,y=1,z=Z0;
Step 2.給予z=1一個10-4級別的隨機擾動,按照給定的軌道長度T利用分片Lorenz混沌系統模型產生混沌軌道;
Step 3.若混沌軌道數量未達到待求解問題維度,返回Step 2;否則轉到Step 4;
Step 4.使用最大最小映射法方法,將混沌軌道壓縮到當前搜索域;
Step 5.將混沌軌道作為一個數據矩陣TrackMat輸出.
該算法根據輸入up、down序列的長度i產生和返回i個混沌序列構成的可行解集矩陣TrackMat;在輸入變量中引入隨機過程來增加算法的不確定性,每個變量對應的混沌序列是通過z加一個極小的隨機數作為初值擾動后輸入算法中得到的.故有產生更多完全不同的可行解集的能力,使算法得以多次進行泛化運行測試.
3.3 解堆棧子算法
解堆棧子算法可以最快的速度從TrackMat中確定一組逐漸逼近最優的解.該算法按照替代優化和漸進禁忌法則依次將混沌搜索軌道上找出的漸進優化解壓入堆棧中,在子算法結束時棧頂元素必定為本次迭代搜索到的最優解.運算過程下:
輸入:TrackMat,order;
輸出:Solution;
Step 1.在搜索域中隨機選取初始解向量,作為臨時棧底解;
Step 2.按照順序提取TrackMat中的解,并計算解值;
Step 3.比較該解和棧頂解,當order要求求解最大值時,若當前解對應解值比棧頂解解值大,則將該解壓入棧中,否則拋棄;若order要求求解最小值時,若當前解對應解值比棧頂解解值小,則將該解壓入棧中,否則拋棄;
Step 4.若軌道中所有解向量都被遍歷到,轉Step 5;否則轉回Step 2;
Step 5.輸出堆棧Solution;
算法在搜索域中隨機生成臨時棧底解,這一隨機過程使得有多種解堆棧的可能性,由于混沌軌道解值完全隨機排列,有很大可能在較早的搜索過程中就遇到較優解,使得漸進禁忌標準迅速逼近最優解值,從而縮減解堆棧的高度;替換優化過程則反復更替擬采用解,進一步逼近全局最優可能存在的域.通過解堆棧算法構造的堆棧一般情況規模較小,能減少出棧時的計算量.
3.4 聚集出棧子算法
在子迭代前期的大搜索域中取得解堆棧后,如果直接使用棧頂元素作為下次縮放搜索中心,有較大可能性導致最終收斂到局部最優解,尤其是類似于如圖4所示SCHAFFER N.2函數微搜索域褶皺上的局部最優解.

圖4 SCHAFFER N.2褶皺上的局部最優
因此設計聚集出棧子算法,在一定程度上,控制搜索中心在搜索域縮減到不可逆之前向適應度相近的其他鄰域的方向偏移,并在搜索軌道運行到微搜索域時逐漸減少干涉,使落入局部最優的機會偏小.設Pk為堆棧Solution中第k行解向量,P0為棧底解,Pn-1為棧頂暫定最優解;將棧中元素依次出棧,并通過公式(10)-公式(13)計算出棧元素與已出棧元素的歐氏距離矩陣S:
(10)
(11)
(12)

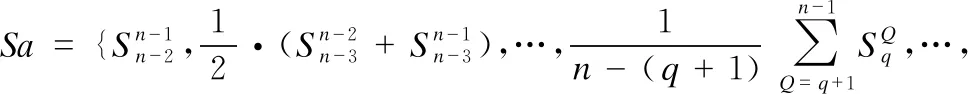
(13)
即可判斷應將哪些解納入用于搜索中心計算的聚集組.計算流程如下:
輸入:Solution;
輸出:Track;
Step 1.利用公式(10)-公式(13)通過輸入的Solution計算得到Sa序列;
Step 2.將Track暫時賦值為棧頂解向量;令k=1;
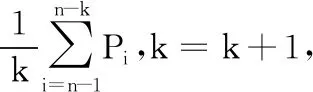
Step 4.當k+2≠n-1時,重復Step 3;否則轉Step 5;
Step 5.輸出Track;
該子算法在子迭代前期發揮作用,搜索域逐漸收縮之后,由于此時的偏移調整量極小,幾乎可以忽略不計,故算法逐漸自動退化,等效于取棧頂解,避免了大幅調整造成的發散解.
3.5 搜索域密度縮放與振蕩模塊
搜索域密度縮放主要針對子迭代的解空間,而振蕩模塊主要對主迭代解空間范圍更新.3.4中找出更適合作為縮放搜索中心的解向量Track后,若經過載波控制器檢測尚未達到精度,則需要重新確定以Track為中心的搜索區域.劃定新區域時,需保證新區域不躍出初始搜索域造成解發散,并隨搜索域收縮控制混沌軌道長度以減少低效計算量.
設算法當前主迭代解優化次數為epoch;Oup、Odown分別表示初始的up與down序列,Scope=Oup-Odown表示MLC算法初始時設定的搜索域中各個變量的取值尺度;store為最低保留軌道長度;設置搜索域收縮速度為Speed.則對搜索域進行變換后的搜索上下界計算公式如公式(14)、公式(15)所示,其中index表示第index個變量.
newup=Track[index]+Scope[index]·Speed(1+epoch)
(14)
newdown=Track[index]-Scope[index]·Speed(1+epoch)
(15)
搜索域與密度更新的算法如下:
輸入:Track;epoch;up;down;times;Scope;Oup;Odown;store;
Step 1.按照變量順序讀取下一個變量搜索域取值;
Step 2.若對于當前變量取值范圍[up,down],根據公式(14)-公式(15)計算newup、newdown.
Step 3.若[newup,newdown]沒有超出原始搜索范圍Scope=[Oup,Odown],則取之作為新搜索域邊界;否則,將超出的一邊的初始邊界作為下次迭代的邊界;
Step 4.若所有變量的新邊界都已計算完畢,轉到Step 5;否則,轉回Step 1;
Step 5.計算新的軌道長度times=「timesspeed+store?;
Speed、store參數根據不同問題可以手動調整.此處為研究方便起見取Speed=0.5,store=500.該算法使搜索域收縮的同時,混沌解規模也隨之縮減為原來的一半以節省算力和時間,且由性質4可知混沌系統的特性不會在搜索域收縮后發生改變.
對主迭代中初始搜索域設置振蕩縮放過程,防止搜索域收縮過快使全局最優在被發現前被排除,具體如下:
Step1.當發現更優解時,按照公式(14)、公式(15)更新每次子迭代初始的搜索域,轉Step 3;否則,轉Step 2;
Step2.產生一個隨機數,當隨機數落在指定收縮概率區間時,按照公式(14)、公式(15)更新每次子迭代初始的搜索域;當隨機數落入指定擴張概率區間時,則將公式(14)、公式(15)中Speed的指數改為log2(1+epoch)后按新式子更新每次子迭代初始的搜索域使搜索域回彈.轉Step 3;當隨機數落入兩區間之外,則直接轉Step 3;
Step3. 將超出邊界的上下限移動到初始邊界,主迭代結束,進入停機判斷.
如此模擬出低頻的搜索域振蕩效果,增加全局最優解的發現可能,同時也保持搜索空間的對數型持續收縮.
3.6 載波控制器
載波控制器主要任務為監測每次子迭代構建的解堆棧求得的解值是否達到精度要求并控制重載波.故在每次子迭代末期,停機控制器需要對本次求解得到的解和解值做好記錄,以備下次監測使用.評估辦法基于解值的差分:
ΔF*=F[(Trackk)-F(Trackk-1)]2
(16)
當檢測到ΔF*小于或等于要求的精度值(一般取10-w,w為正整數),則終止載波和子迭代過程,根據解的優化情況更新搜索域后,進入停機控制器;否則,運行搜索域密度收縮子算法,并向混沌擾動模塊輸入重載波參數,給予微小擾動后開始新的子迭代.
3.7 停機控制器與混沌擾動模塊
停機控制器用于在達到最大迭代次數時終止算法.由于混沌優化算法每次迭代結果都具有隨機性,沒有有效的解監測辦法,故只能用最大迭代次數作為控制因素.
混沌擾動模塊通過在混沌系統控制參量上施加10-4的擾動實現對混沌軌道的擾動,即加減一個10-4級的隨機數即可.
4 實驗分析
4.1 求解性能對比測試
為了驗明3中設計的MLC算法是否具有更好的全局最優求解能力,使用了單目標優化常用的測試函數SCHAFFER函數式(17)和“大海撈針”函數式(18)進行算法測試.兩個函數在定義域內的圖像如圖5所示,兩個函數都具有被局部最優解包圍全局最優解、且全局最優解值與局部最優解值差異較小的特點.
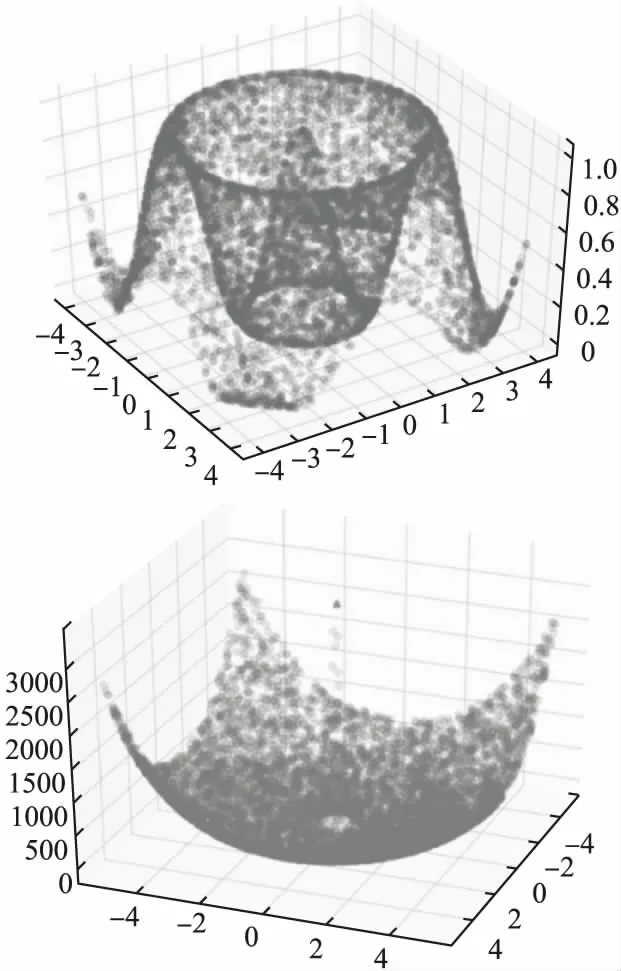
圖5 SCHAFFER函數(上)和“大海撈針”函數(下)
(17)
(18)
其中,SCHAFFER函數全局最優解為(0,0),對應函數值為1,圓環上的局部最優為0.9903,外部的4個局部最優解為0.6468.
實驗表明使用Lingo軟件求解SCHAFFER所得解值為0.6468488,而使用Matlab可解出解值為0.9903;使用原Logistic混沌優化算法需經過1092次迭代才能得到全局最優解[18],而使用混沌遺傳算法則需迭代458次.“大海撈針”函數全局最優解為(0,0),對應最優解值為3600,4個角上分別存在4個局部最優解,對應解值都為2748.78;Lingo和Matlab運算出現局部最優概率高達95%,遺傳算法也需迭代300代才有60%可能找到最優解.
設置MLC算法初始參數:目標下降精度0.0001,收縮速度0.5,產生混沌軌道長定義為500,最大迭代次數為50次;設振蕩收縮概率區間為[0.075,0.01],擴張概率區間為[0,0.075].分別對兩個待優化函數運行10次MLC算法.結果對于兩個問題的求解都在3次迭代以內找出都找到了全局最優解,且二者分別進行的10次實驗中都有9次都收斂到全局最優解,可粗略認為有接近90%的概率一次計算得到全局最優.
4.2 中等復雜問題求解能力綜合測試
為進一步測試MLC算法是否有能力對中等復雜單目標函數進行最優化求解,選擇了Ackley函數和Griewank函數作為測試用例,兩個函數基本式如公式(19)、公式(20)所示.其中,Ackley函數二維形態如圖6所示;Griewank二維形態從[-1000,1000]到[-5,5]區間縮放效果如圖7所示,可知Ackley具有頂峰局部最優特性;而Griewank函數同時具有微搜索域褶皺豐富、局部最優與全局最優解值差異極端微弱的特性,搜索域較大時,只能大致判別出最優解在0點附近,但當搜索域縮減后,函數圖像上出現大量褶皺,且波峰波谷差距極其微小.這類特性使得二維情況的求解都已經非常困難.分別構造10維Ackley函數和10維Griewank函數,設公式(19)中的d為10,a為20,b為0.2,設公式(20)中的d為10;分別設定Ackley函數變量取值范圍為[-50,50],Griewank函數取值范圍為[-1000,1000].此處10維Ackley函數的解空間規模為10010;而10維Griewank函數的解空間規模為200010.已知兩函數最優解都為[0,0,0,0,0,0,0,0,0,0],對應解值0.
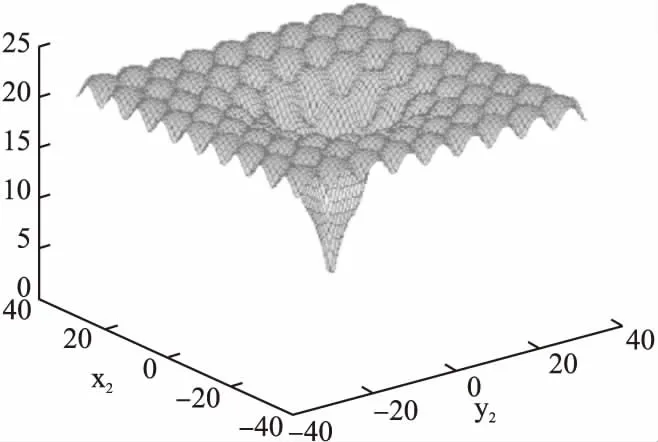
圖6 2D Ackley函數
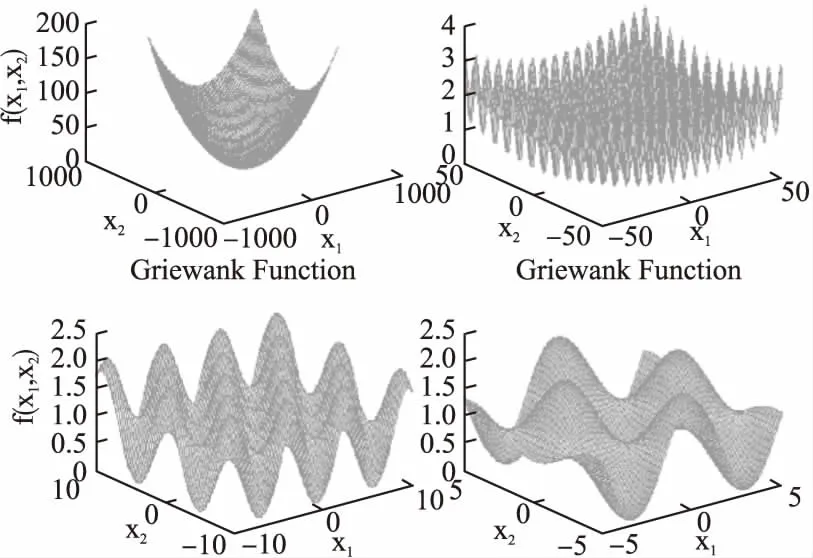
圖7 2D Griewank函數
+a+exp(1),xi∈[-50,50]
(19)
(20)
使用原Logistic混沌優化算法迭代1000次,實驗10次,其中有2次分別在632次迭代和944次迭代求得Ackley函數全局最優解;但始終沒有找出Griwank函數全局最優解.使用遺傳算法、螞蟻算法測試,都始終無法求出10維Griwank函數的全局最優解.
調整MLC算法參數,設置最大迭代500次,混沌軌道長度為5000,其余參數不變,分別對兩個函數運行算法15次.
對于Ackley函數,15次實驗都在第1次迭代中就找到全局最優解.對于Griewank函數,15次測試的結果如表3所示,除了6號實驗外,其余所有實驗都在300次迭代內找到全局最優解,且解值精度達到99.9999%.其中有7次都在100次迭代內找出全局最優解.兩輪測試都能夠在較500次迭代內有效找到全局最優解,證明MLC算法對于中等連續復雜單目標函數據具有較好的極值求解能力.

表3 10維Griewank函數±1000范圍內最小化求解結果
5 總 結
針對常用的遺傳算法、蟻群算法一類復雜連續函數求解方法存在的難以跳出局部最優、收斂時間過長等問題,以及基于Logistic混沌系統設計的優化算法存在的邊緣過度搜索缺陷,改進Lorenz混沌映射系統設計了一套新的混沌映射系統模型,并基于該模型設計了分片Lorenz混沌堆棧聚集變密度振蕩搜索算法(簡稱MLC算法).通過系統仿真分布統計實驗和多輪求解能力測試,達成了以下目標:
1)驗證了改進后的混沌模型具有優于Logistic系列混沌的分布均勻度與隨機性,更適合作為改進混沌優化算法的搜索軌道發生核心;
2)相對經典優化算法,新算法在解決單目標復雜連續函數極值問題方面具備速度快、性能穩定、局部跳出能力強等優勢,能夠以較高且穩定的概率直接找出簡單函數全局最優解,綜合性能優于對比組的各項經典算法和現有軟件.
利用MLC算法的優勢,可以考慮其應用于工程優化領域,例如計算化工領域復雜化學反應有效產出最大化或廢料最小化的原料配置問題;或者用于解決非線性復雜管理科學工程問題,例如對復雜博弈投資組合問題計算投資產出最優方案等;在生物運動信號處理方面,對該算法進行改進還可以用于九軸運動傳感器校準.
由于MLC算法框架針對復雜連續函數優化的特異性,該算法尚不可直接用于解決組合優化問題.此外,算法的收斂策略缺乏非線性過程,這使得算法搜索不均衡;解空間的收縮則使算法放棄了邊界外的區域.上述不足之處有待后續研究.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
